
Scrapy 源码剖析:架构概览
介绍
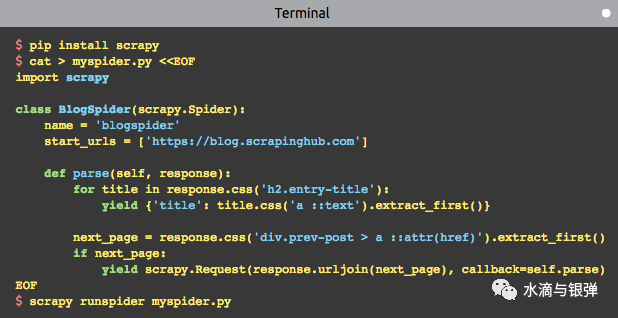
使用 scrapy startproject命令创建一个爬虫模板,或自己按模板编写爬虫代码定义一个爬虫类,并继承 scrapy.Spider,然后重写parse方法parse方法里编写网页解析逻辑,以及抓取路径使用 scrapy runspider运行这个爬虫
架构
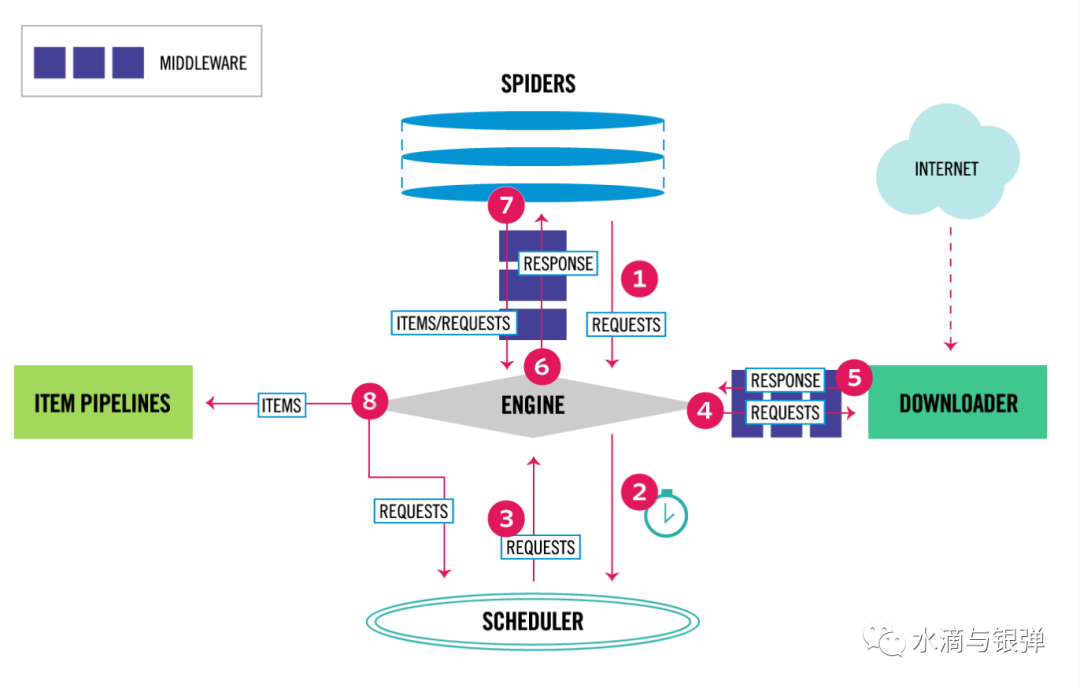
核心模块
Scrapy Engine:核心引擎,负责控制和调度各个组件,保证数据流转;Scheduler:负责管理任务、过滤任务、输出任务的调度器,存储、去重任务都在此控制;Downloader:下载器,负责在网络上下载数据,输入待下载的 URL,输出下载结果;Spiders:我们自己编写的爬虫逻辑,定义抓取意图;Item Pipeline:负责输出结构化数据,可自定义格式和输出的位置;
Downloader middlewares:介于引擎和下载器之间,可以在网页在下载前、后进行逻辑处理;Spider middlewares:介于引擎和爬虫之间,在向爬虫输入下载结果前,和爬虫输出请求 / 数据后进行逻辑处理;
运行流程
引擎从自定义爬虫中获取初始化请求(也叫种子 URL); 引擎把该请求放入调度器中,同时调度器向引擎获取待下载的请求; 调度器把待下载的请求发给引擎; 引擎发送请求给下载器,中间会经过一系列下载器中间件; 这个请求通过下载器下载完成后,生成一个响应对象,返回给引擎,这中间会再次经过一系列下载器中间件; 引擎接收到下载器返回的响应后,发送给爬虫,中间会经过一系列爬虫中间件,最后执行爬虫自定义的解析逻辑; 爬虫执行完自定义的解析逻辑后,生成结果对象或新的请求对象给引擎,再次经过一系列爬虫中间件; 引擎把爬虫返回的结果对象交由结果处理器处理,把新的请求通过引擎再交给调度器; 重复执行1-8,直到调度器中没有新的请求处理,任务结束;
核心模块的协作
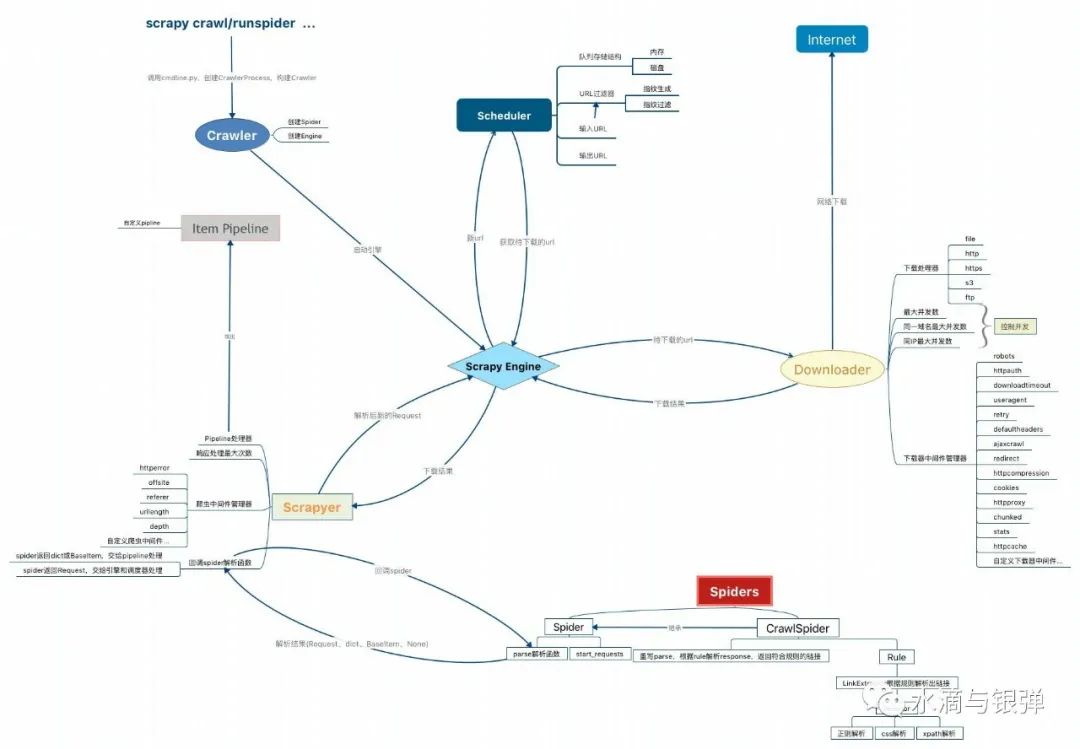
Scrapyer 模块,其实这也是 Scrapy 的一个核心模块,但官方的架构图中没有展示出来。这个模块其实是处于 Engine、Spiders、Pipeline 之间,是连接这 3 个模块的桥梁,我会在后面的源码分析文章中具体讲到。核心类图
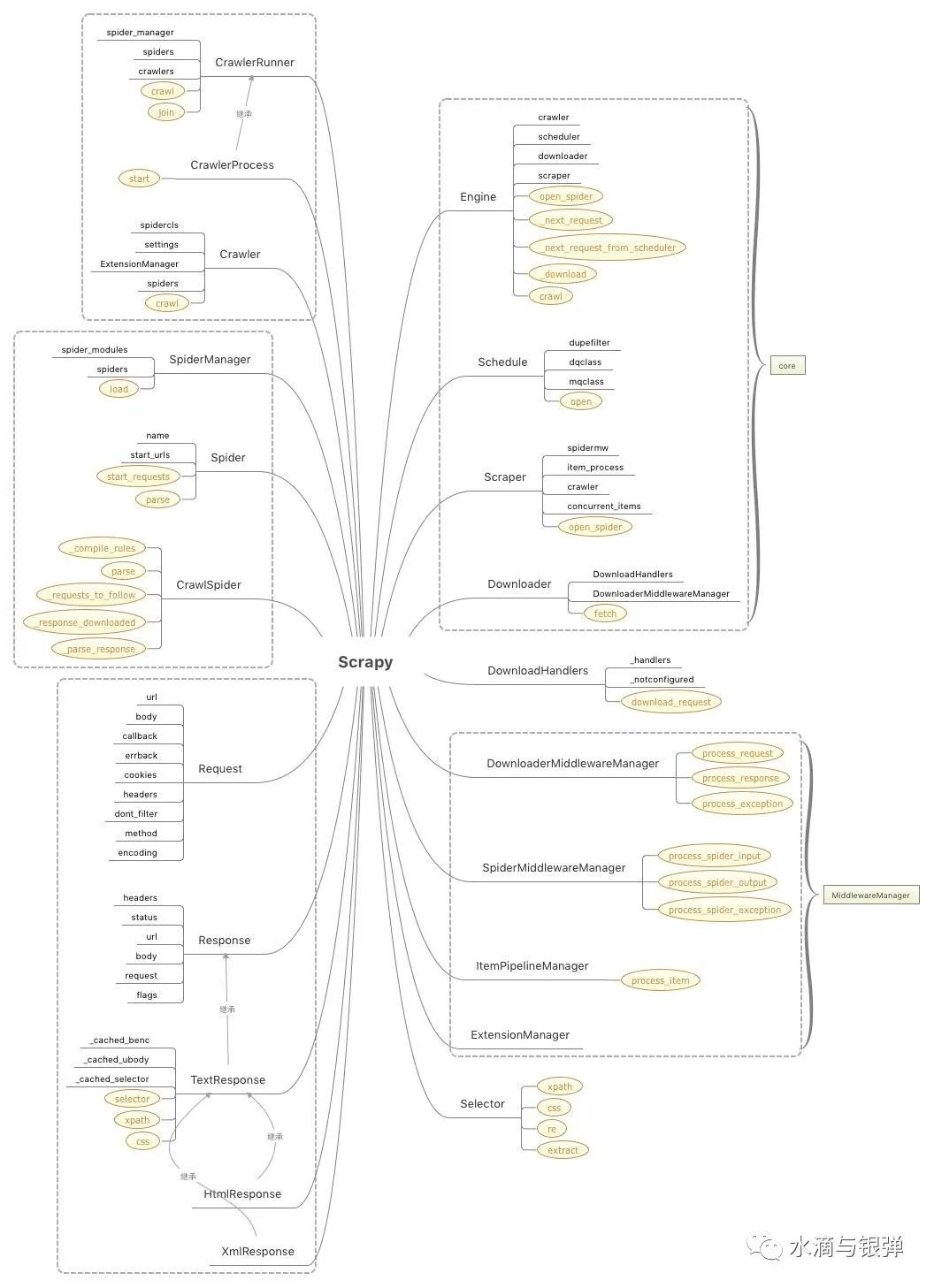
没有样式的黑色文字是类的核心属性; 标有黄色样式的高亮文字是类的核心方法;
五大核心类: Scrapy Engine、Scheduler、Downloader、Spiders、Item Pipeline四个中间件管理器类: DownloaderMiddlewareManager、SpiderMiddlewareManager、ItemPipelineMiddlewareManager、ExtensionManager其他辅助类: Request、Response、Selector
更多阅读
特别推荐

点击下方阅读原文加入社区会员
评论