
LeetCode刷题实战94:二叉树的中序遍历
算法的重要性,我就不多说了吧,想去大厂,就必须要经过基础知识和业务逻辑面试+算法面试。所以,为了提高大家的算法能力,这个公众号后续每天带大家做一道算法题,题目就从LeetCode上面选 !
今天和大家聊的问题叫做 二叉树的中序遍历,我们先来看题面:
https://leetcode-cn.com/problems/binary-tree-inorder-traversal/
Given the root of a binary tree, return the inorder traversal of its nodes' values.
题意
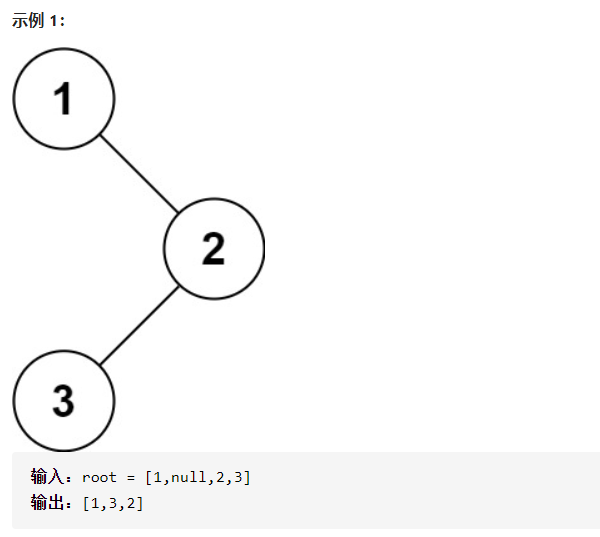
解题
# 先序
def dfs(u):
visited.append(u)
dfs(u.left)
dfs(u.right)
# 中序
def dfs(u):
dfs(u.left)
visited.append(u)
dfs(u.right)
# 后序
def dfs(u):
dfs(u.left)
dfs(u.right)
visited.append(u)
class Solution:
def inorderTraversal(self, root: TreeNode) -> List[int]:
ret = []
stack = []
stack.append(root)
while len(stack) > 0:
# 获取栈顶顶点
cur = stack[-1]
if cur is None:
stack.pop()
continue
# 如果左孩子存在,那么优先遍历左孩子
if cur.left is not None:
stack.append(cur.left)
# 把左指针置为空,防止死循环
# 这里也可以用set来维护
cur.left = None
continue
# 左边遍历结束之后加入序列
ret.append(cur.val)
stack.pop()
if cur.right is not None:
stack.append(cur.right)
return ret
上期推文: