
50年长盛不衰,SQL为什么如此成功?
点上方“菜鸟编程大本营”,选择“星标”
重磅干货,第一时间送达

1971 年 3 月,英特尔推出世界上第一款通用微处理器——英特尔 4004。它有约 2300 个晶体管,售价 60 美元。
https://spectrum.ieee.org/tech-history/silicon-revolution/chip-hall-of-fame-intel-4004-microprocessor
时间快进到 50 年后,最新的 iPhone 有将近 120 亿个晶体管(但价格仅为 60 美元多一点)。
我们今天使用的许多编程语言直到 90 年代才推出(Java 是在 1996 年推出的)。不过,有一种编程语言现在仍然像近 50 年前推出时一样流行:SQL。本文将讨论关系型数据库产生的背景、SQL 为什么越来越流行,以及我们可以从它的成功中学到什么。

1962 年,查尔斯·w·巴赫曼(与埃利希·巴赫曼没有关系)是通用电气一个小团队的一员。一年后,巴赫曼团队推出了后来被公认为第一个数据库管理系统的集成数据存储系统(IDS)。
10 年后,巴赫曼获得图灵奖(通常被称为计算机科学领域的诺贝尔奖),以表彰他对 IDS 计算的贡献。
在 20 世纪 60 年代早期,计算机科学刚开始成为一个学术领域。ASCII 直到 1963 年才推出。
要理解 IDS,我们必须首先理解促成其发展的两大驱动力:
磁盘存储的推出
向高级编程语言的迁移
磁盘存储

移动一台 RAMAC 305
1956 年,IBM 推出第一款商用硬盘驱动器——RAMAC 305。磁盘驱动器的引入使得程序员可以直接跳转到磁盘上的某个位置进行数据检索和更新。与其前身磁带驱动器相比,这是一个巨大的改进,后者需要在磁带上顺序移动来检索特定的数据片段。
但是现在,开发人员必须找出记录在磁盘上存储的位置。由于早期操作系统中文件管理系统的局限性,这是一项只有有经验的程序员才能完成的高级任务。开发人员需要一种解决方案来简化磁盘驱动器的使用。
https://medium.com/@princeabhishek410/understanding-file-management-system-in-operating-system-4c7fbfc306f2
高级编程
与此同时,在采用曲线上,计算机科学开始从创新者转变为早期采用者。像汇编这样的低级编程语言早期在学术界很流行,但是出于易用性考虑,普通程序员开始转向高级编程语言,比如 COBOL。
https://en.wikipedia.org/wiki/Diffusion_of_innovations
那么什么是 IDS 呢?IDS 解决了磁盘存储和高级编程问题。IDS 允许开发人员使用高级编程语言(如 COBOL)来构建从磁盘存储输入和检索数据的应用程序。由于这个功能,IDS 获得了第一个数据库管理系统的殊荣。
1969 年,数据系统语言委员会(CODASYL)发布了一份报告,提出一个数据库管理标准。巴赫曼是委员会的一员,该报告主要参照了 IDS。
CODASYL 数据模型引入了许多我们今天使用的数据库管理系统的核心特性:
模式
数据定义语言(DDL)
数据操作语言(DML)
最重要的是,IDS 和 CODASYL 引入了一种新的数据建模方法,这种方法影响了 SQL 的最终开发——网络数据模型。
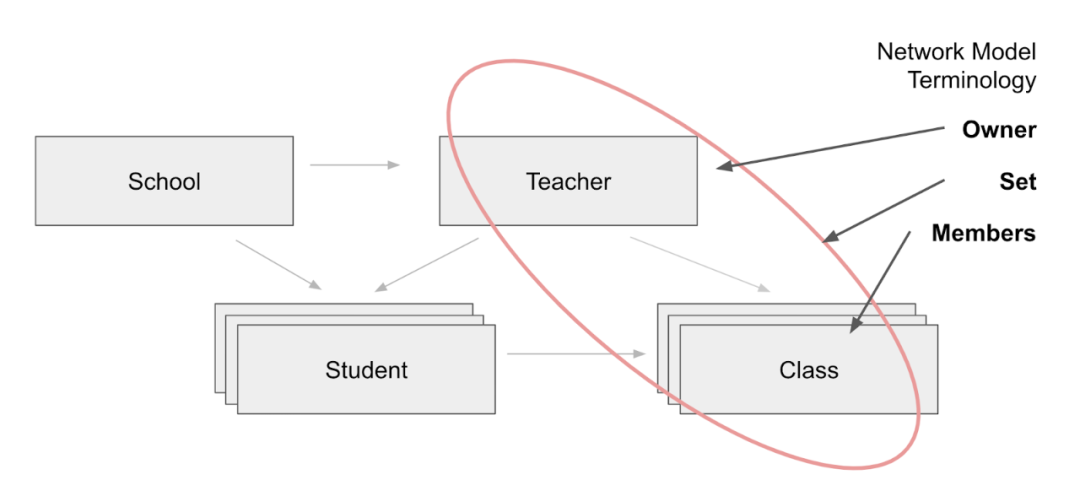
网络模型示例
数据模型是一种描述(模型)世界(数据)的标准化方法。
前面的层次数据模型使用树型结构来描述数据,但是这些树型结构仅限于一对多的关系。新的网络模型允许记录有多条父记录,从而创建一个图结构。通过支持多个父节点,网络模型能够对多对一和多对多关系进行建模。
在网络模型中,表之间的关系存储在集合中。每个集合都有一个所有者(即教师)和一个或多个成员(即班级和学生)。
网络模型的其中一个主要好处是,集合中的相关记录是通过指针直接连接的。集合是使用 next、prior 和 owner 指针实现的,这样就可以像链表一样轻松遍历。
网络数据模型的低级特性提供了性能优势,但也付出了代价。网络数据模型增加了存储成本,因为每个记录都必须额外存储指向前一条记录和父记录的指针。
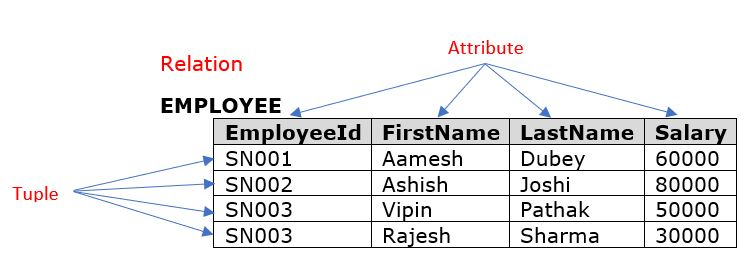
关系模型示例
1970 年,在 IDS 诞生 8 年后,Edgar F. Codd 在他的开创性论文《A relational model of Data for Large Shared Data Banks》中引入关系模型(这也为他赢得了图灵奖)。
https://www.seas.upenn.edu/~zives/03f/cis550/codd.pdf
Codd 指出,数据库中的所有数据都可以用元组(SQL 中的行)表示,这些元组被分组成关系(SQL 中的表)。为描述数据库查询,他发明了一种一阶谓词逻辑的形式,称为元组关系演算。
元组关系演算引入了一种声明性语言用于查询数据。使用声明性编程语言,程序员只需说明他们想做什么,而不必描述如何做。
对开发人员来说,这种新的声明性语言更容易使用。关系模型公开了所有数据。开发人员可以用一条命令,从一个表中检索所有数据或者读取一行数据。
在指针迷宫中查找数据的日子已经一去不复返了。
关系型数据库通过数据规范化降低了网络型数据库的高昂存储成本。规范化是一个分解表以消除冗余的过程,可以减少磁盘占用。
然而,关系型数据库增加了 CPU 成本。为了处理规范化数据,关系型数据库必须将表加载到内存中,并使用计算能力将表“连接”在一起。让我们通过一个例子来看下这个过程:在一个关系模型中,给定老师,查找所有的班级和学生。
首先,数据库系统执行一个操作来检索所有相关的班级。然后,它将执行第二个操作来检索学生数据。所有这些数据都将存储在内存中,在返回结果前,它将运行第三个操作来合并数据。
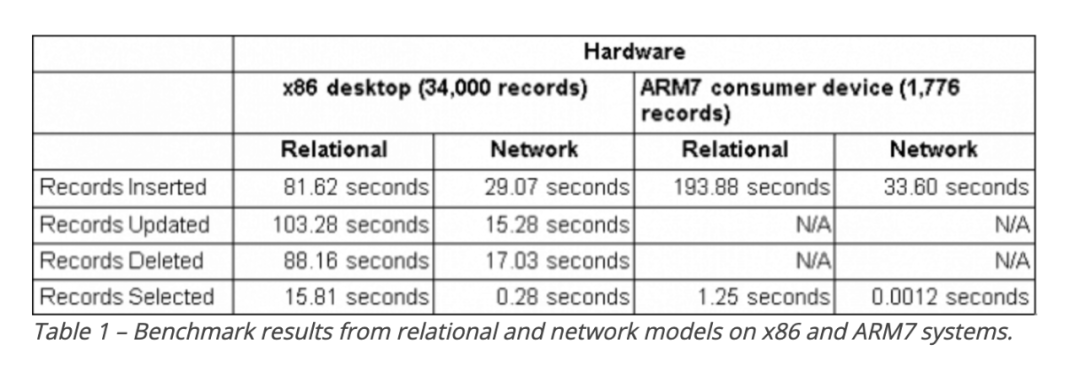 关系模型和网络模型的性能对比
关系模型和网络模型的性能对比
在一个使用真实数据的性能案例研究中,Raima 发现,网络数据库模型的插入性能好 23 倍,查询性能快 123 倍。
https://raima.com/network-model-vs-relational-model/
那么为什么关系型数据库会成为领先的数据库解决方案?
易用性
关系模型更容易修改,它的声明性语法简化了程序员的工作。
摩尔定律在背后发挥了神奇作用。计算成本持续下降,最终,生产力的提高抵消了关系模型所增加的计算成本。
快进 50 年,现在,数据中心中最昂贵的资源是 CPU。

最后,我们迎来了大家都喜欢的 SQL。
在 Codd 的论文发表 4 年后,Donald Chamberlin 和 Raymond Boyce 发表了《SEQUEL: A Structured English Query Language》。
https://dl.acm.org/doi/10.1145/800296.811515
他们将 SEQUEL 描述为“一组关于表格结构的简单操作,[…] 和一阶谓词演算同样强大。”IBM 看到其潜力,并在 20 世纪 70 年代早期迅速开发出 SEQUEL 的第一个版本,作为其 System R 项目的一部分。
由于与英国 Hawker Siddeley 飞机公司的商标问题,其名称后来改为 SQL。
https://en.wikipedia.org/wiki/SQL
SQL 的下一个大发展是在近十年后。1986 年,美国国家标准协会(ANSI)和国际标准化组织(ISO)发布第一个官方 SQL 标准:SQL-86。该标准将 SQL 分为以下几个部分:
数据定义语言(DDL):此类命令用于定义和修改模式及关系;
数据操作语言(DML):此类命令用于查询、插入和删除数据库信息;
事务控制:此类命令用于指定事务的时间;
完整性:此类命令用于对数据库信息设置约束;
视图:此类命令用于定义视图;
授权:此类命令用于指定可以访问的用户;
嵌入式 SQL:此类命令用于具体说明如何将 SQL 嵌入其他语言。
从 1974 年到今天,有许多竞争者试图从 SQL 统治的查询语言市场中抢占市场份额。通常,这些新语法是针对特定的新技术:
Lisp ->CLSQL
.NET ->LINQ
Ruby on Rails ->ActiveRecord
35 年过去了,在数据库中,SQL 仍然无处不在。SQL 作为一种查询语言是如何保持统治地位的?我们可以从它的故事中学到什么?
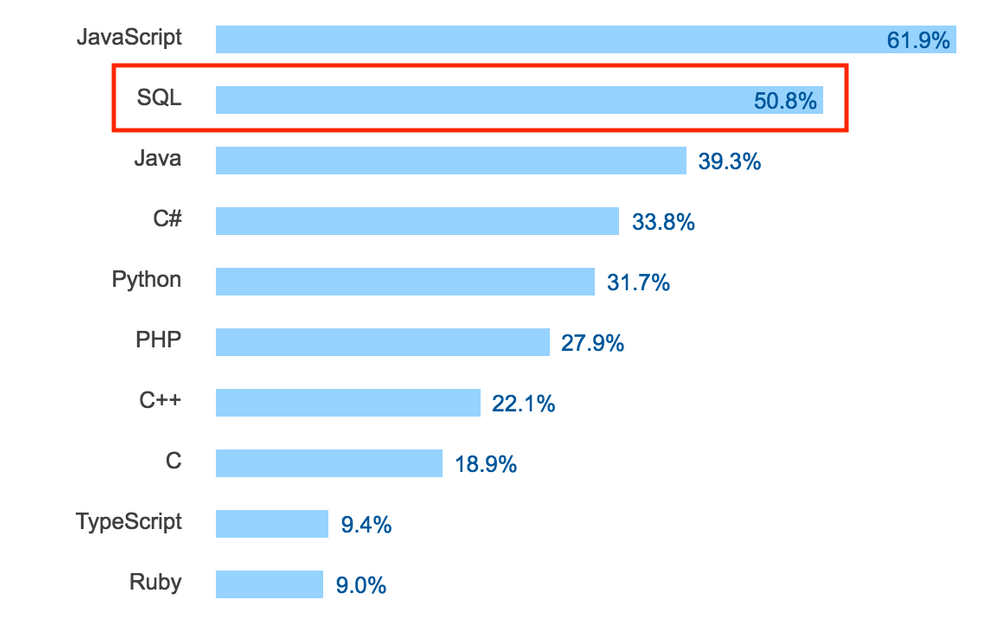
Stack Overflow 开发者调查,2017
在文章开头,我们首先介绍了巴赫曼推出的第一个数据库管理系统 IDS。我们讨论了为什么磁盘存储和高级编程需要一种处理数据的新方法。然后,CODASYL 来了,规范了数据库管理。IDS 和 CODASYL 引入了新的网络数据模型,而最终,Codd 投下了关系模型。
这个过程持续了 8 年。
SQL 是如何在接下来的 50 年里坚持下去的呢?我认为主要有四个原因:
基于第一性原则构建
布什内尔定律
倾听和调整
采用 API
第一性原则是一个基本命题,它不能从任何其他命题或假设中推导出来。例如,将碳氢化合物与氧气结合,产生化学反应。这仍然是驱动每一辆车的内燃机原理。
1970 年,Codd 为数据库创建了一个新的第一性原则:元组关系演算。这个新创建的逻辑引出了关系模型,然后引出 SQL。元组关系演算是化学反应,关系模型是内燃机,SQL 是汽车。
仅仅建立在第一性原则上并不能保证其成功。汇编是程序员所能做到的最接近输入 1 和 0 的程序,但它仍然被 COBOL(后来是 C)所取代。
它缺少的一个关键要素是可用性。
从网络模型到关系模型的转换,我们看到同样的情况。网络模型性能更好,但是现在每个公司都在使用关系型数据库,因为它很容易(入手)。
最好的游戏易于学习而难于精通。——Atari 创始人诺兰·布什内尔
诺兰·布什内尔知道如何让人们使用新产品。但遗憾的是,汇编既难学又难精通。
SQL 找到了完美的平衡。10 个左右的 SQL 命令,任何人都可以学会其中的 20%,并完成 80% 的工作。但是要想精通,需要经过长期的积累,具备丰富的索引、视图和优化经验。
查询语言不是一块永恒的巨石,而是一组随时间变化的自适应标准。随着时间的推移,SQL 标准一直在不断调整,并加入了来自用户的反馈。
从概念最初提出开始,我们看到了 10 种不同的 SQL 标准,它们都有重要的更新。以下是三项比较大的:
SQL:1999:添加了正则表达式匹配、递归查询(例如传递闭包)、触发器、对过程语句和流控制语句的支持、非标量类型(数组)和一些面向对象的特性(例如结构化类型)。支持在 Java 中嵌入 SQL(SQL/OLB),反之亦然(SQL/JRT)。
SQL:2003:引入了与 XML 相关的特性(SQL/XML)、窗口函数、标准化序列和自动生成值的列(包括标识列)。
SQL:2016:添加行模式匹配、多态表函数、JSON。
SQL 语法不是强制性的,它只是提供了一个数据库标准,每种数据库都可以创建它们自己的实现(T-SQL、MySQL、PSQL 等)。
SQL 成功的最后一个秘密是应用程序编程接口(API)的兴起。API 通过抽象底层实现,只公开开发人员需要的对象或操作,简化了编程。
API 让 SQL 可以使用专门的语法适应新技术的发展。2006 年,Hadoop 引入分布式文件系统(HDFS),SQL 语法最初是无法访问该系统的。然后,在 2013 年,Apache 创建了 Apache Impala,它允许开发人员使用 SQL 查询 HDFS 数据库。
SQL 是当今最普遍的编程语言之一,但我们经常忘记它的历史有多久了。它的旅程开始于现代计算机的黎明,由 2 位图灵奖获得者赋予了它生命。对于为什么 SQL 能够保持其主导地位,我已经分享了我的看法:第一性原则、布什内尔定律、调整和 API。您认为促成 SQL 成功的主要因素是什么?
还有一项 50 年来都没有改变的技术。
SQL 编辑器
随着越来越多的人学习 SQL,数据库使用越来越需要协作。如今,开发人员可能会与营销团队的成员一起分析用户数据,或者与数据科学家一起调试查询。
原文链接:https://blog.arctype.com/sql-50-years

往期爆款:
点这里,直达菜鸟学PythonB站!!
