
一键智能抠图-原理与实现
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


一键智能抠图-原理实现
cvpy.net最近新上的一键智能抠图和换背景的功能,智能判断前景并自动抠图,效果还是挺惊艳的,放几张图看看效果:
请注意看这位喵星人右侧性感的胡须,抠的可谓是非常精细了。
有人说了,这张图片的的背景是简单的纯色背景,体现不出难度来。
那我换一张我在路边拍的一朵不知名的花(恕我孤陋寡闻...)的图片,看看抠图的效果,顺便换个蓝色的背景:

可以看到,模型成功识别出了前景区域,而且边缘等细节识别的非常好。
再来看一张人物照的抠图效果:
注意看左手指缝和肩膀后面的那一缕头发,称得上丝丝入扣了吧。
https://cvpy.net/studio/cv/func/DeepLearning/matting/matting/page/前往体验区体验。Pattern Recognition 2020论文《U^2-Net: Going Deeper with Nested U-Structure for Salient Object Detection》提出的U^2-Net。值得一提的是,最近外网很火的增强现实应用【隔空移物(AR Cut & Paste)】和 Object CutAPI都是基于CVPR2019的BASNet。而U^2-Net和BASNet的作者为同一位大佬-秦雪彬。
作者认为,目前显著性目标检测有两种主流思路,一为多层次深层特征集成(multi-level deep feature integration),一为多尺度特征提取(Multi-scale feature extraction)。多层次深层特征集成方法主要集中在开发更好的多层次特征聚合策略上。而多尺度特征提取这一类方法旨在设计更新的模块,从主干网获取的特征中同时提取局部和全局信息。而几乎所有上述方法,都是为了更好地利用现有的图像分类的Backbones生成的特征映射。而作者另辟蹊径,提出了一种新颖而简单的结构,它直接逐级提取多尺度特征,用于显著目标检测,而不是利用这些主干的特征来开发和添加更复杂的模块和策略。
作者首先介绍了提出的Residual U-blocks,然后介绍了基于Residual U-blocks构建的嵌套U型网络结构。
3.1 Residual U-blocks
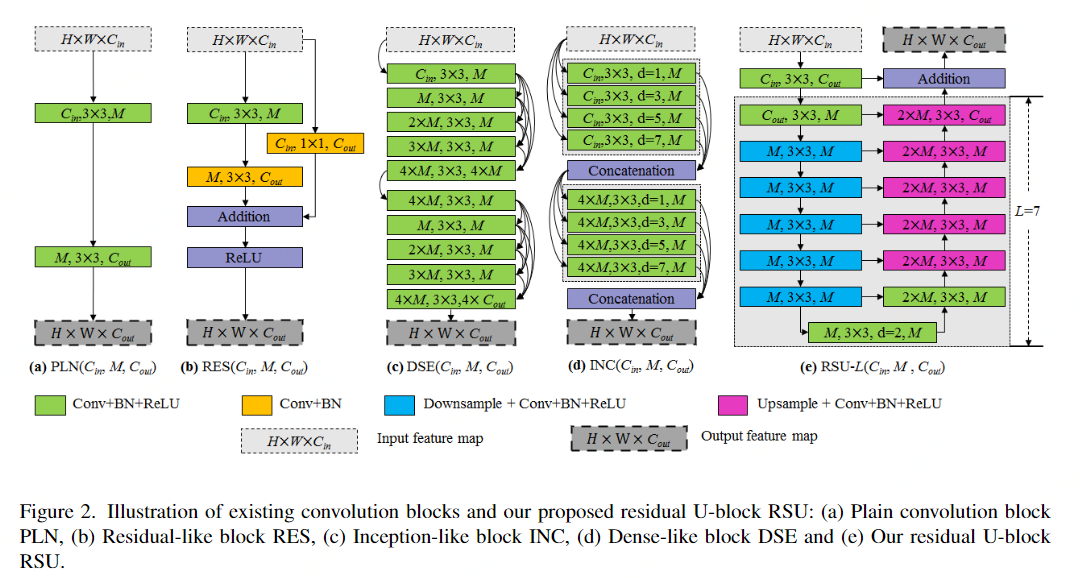
上图为普通卷积block,Res-like block,Inception-like block,Dense-like block和Residual U-blocks的对比图,明显可以看出Residual U-blocks是受了U-Net的启发。
Residual U-blocks由以下三部分组成:
一个输入卷积层,它将输入的 feature map x (H × W × C_in)转换成中间feature map F_1(x),F_1(x)通道数为C_out。这是一个用于局部特征提取的普通卷积层。一个 U-like的对称的encoder-decoder结构,高度为L,以中间feature map F_1(x)为输入,去学习提取和编码多尺度文本信息U(F_1(x))。U表示类U-Net结构。更大L会得到更深层的U-block(RSU),更多的池操作,更大的感受野和更丰富的局部和全局特征。配置此参数允许从具有任意空间分辨率的输入特征图中提取多尺度特征。从逐渐降采样特征映射中提取多尺度特征,并通过渐进上采样、合并和卷积等方法将其编码到高分辨率的特征图中。这一过程减少了大尺度直接上采样造成的细节损失。一种残差连接,它通过求和来融合局部特征和多尺度特征: F_1(x) + U(F_1(x))。
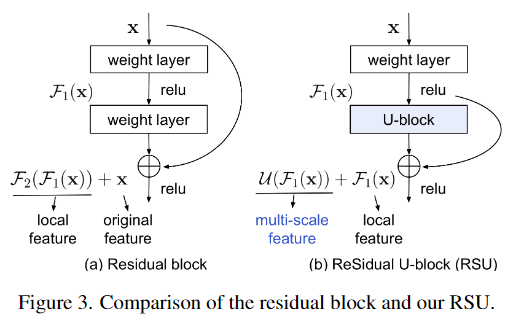
RSU与Res block的主要设计区别在于RSU用U-Net结构代替了普通的单流卷积,用一个权重层(weight layer)形成的局部特征来代替原始特征。这种设计的变更使网络能够从多个尺度直接从每个残差块提取特征。更值得注意的是,U结构的计算开销很小,因为大多数操作都是在下采样的特征映射上进行的。
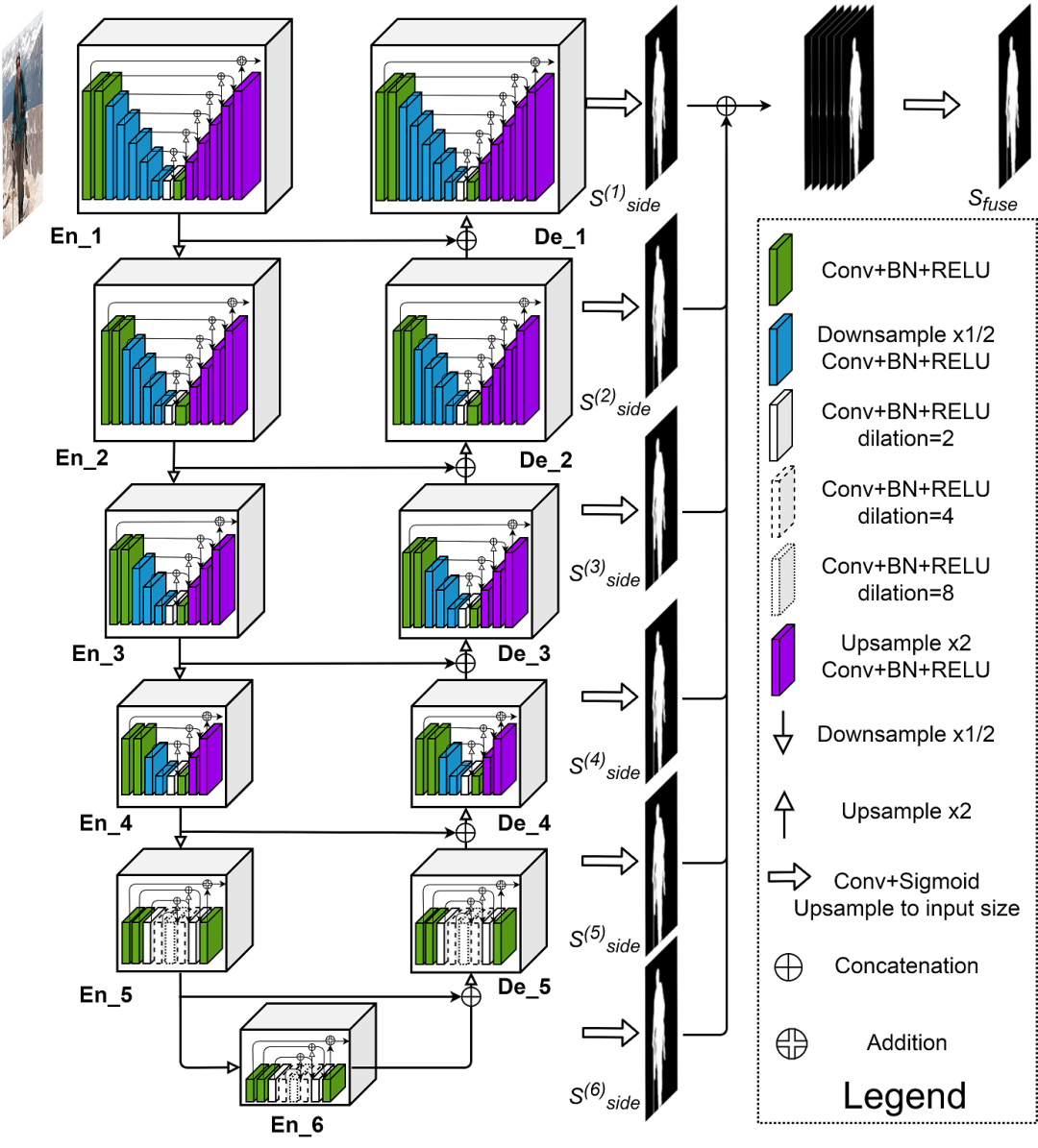
3.2 U^2-Net的结构
U^2-Net的网络结构如下:
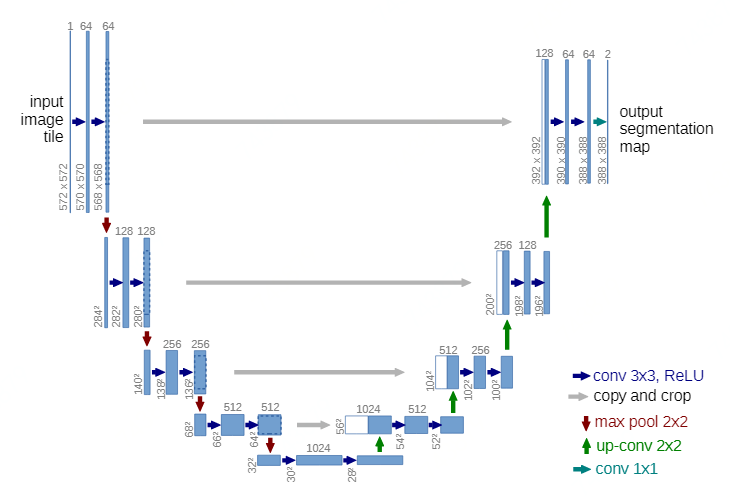
与U-Net的网络结构做一个对比:
直观上可以发现,U^2-Net的每一个Block都是一个U-Net结构的模块,即上述Residual U-blocks。当然,你也可以继续Going Deeper, 每个Block里面的U-Net的子Block仍然可以是一个U-Net结构,命名为U^3-Net。然后同理继续...,正所谓:子又生孙,孙又生子;子又有子,子又有孙;子子孙孙无穷匮也!
DUTS-TR数据集进行训练,该数据集包含大约10000个样本图像,并使用标准数据增强技术进行扩充。研究人员在6个用于突出目标检测的基准数据集上评估了该模型:DUT-OMRON、DUTS-TE、HKU-IS、ECSSD、PASCAL-S和SOD。评价结果表明,在这6个基准点上,新模型与现有方法具有相当好的性能。U^2-Net的实现是开源的,并为两种不同的方法提供了预训练的模型:U^2-Net(176.3M的较大模型,在GTX 1080Ti GPU上为30 FPS)和一个仅为4.7mb的较小的U^2-Net版本,最高可达到40 FPS。
代码和预训练模型都可以在Github找到:
https://github.com/NathanUA/U-2-Net。交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~