
为了解决这个 RTT 过长的问题,我祭出了大招!
今天给大家分享一个这两天排查成功的案例,相信对大家会有些帮助。
大多数人应该听过一道经典的面试题:请详细地说出从浏览器地址栏输入 url 到最终呈现出结果的过程,越详细越好,为什么面试官这么喜欢问这道题呢,因为这个题涉及的面非常广,知识点非常多,如果你能完全吃透,非常有助于排查一些疑难杂症,今天我要分享的这个 case 就是个典型,废话不多说,进入正题。
问题描述
前端同学发现新开发的项目接口有 1/3 概率出现 RTT(请求往返时间)大于 3 s 的情况,以登录接口为例,Chrome 请求所花时间如下

正常的 RTT 在几十 ms 左右,所以 3s 这个时延肯定不正常,于是着手排查,由于每个接口都可能超过 3s,所以下文皆以登录接口分析为例,因为登录接口逻辑相对比较简单。
排查思路
1. 排除浏览器本身的问题
估计大家看到这种问题马上就断定是 server 的问题,立马开始着手排查 server 的问题,不急,我们要先把浏览器本身可能导致请求缓慢的问题给排除了,浏览器本身可能因为「请求最大并发数量限制」,「更高优先级的请求插队,低优先级的任务被延后」等原因导致请求缓慢
所以为了排除浏览器本身造成的网络请求过慢,我们最好找一个其它的浏览器比如 Safari 或者终端 curl 请求来再重试下这个请求,看下请求是否依然缓慢,这里我两个方法都试了,用 Safari 也重现了 RTT 大于 3s 的情况,并且我用 curl 在终端请求也发现了 RTT 大于 3s 的情况,如何使用 curl 请求呢,这里提醒一下,大家千万不要傻傻地去构建一个 curl 请求,浏览器的网络请求本身可以导出成 curl 的形式的,在「network」中点击网络请求,选中「Copy as cURL」,就可获取此请求的 curl 表示方式
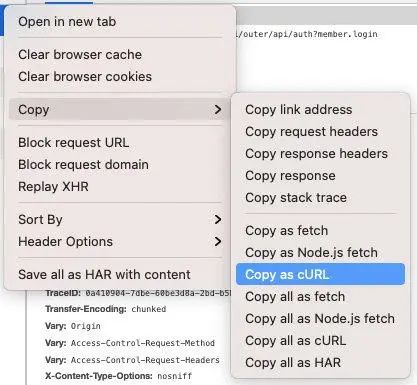
获得 curl 请求后,对此请求稍加改造,加上如下 -o,-s, -w 选项
curl -o /dev/null -s -w "time_connect: %{time_connect}\ntime_starttransfer:
%{time_starttransfer}\ntime_nslookup:%{time_namelookup}\ntime_total: %{time_total}\n"
浏览器copy而来的请求
画外音:这里对几个参数简要作下说明: -o /dev/null 屏蔽原有输出信息,-s 静默模式,不输出任何东西,-w %{http_code} 控制额外输出
请求后会出现类似以下的结果
time_connect: 0.045897
time_starttransfer: 3.064762
time_nslookup:0.004328
time_total: 3.064777
前面几个参数就不多做说明了,一般我们只要关心最后一个 time_total 参数即可,表示请求花费的全部时间。
综上,经过 safari 与 终端测试发现登录接口都有超过 3s 的现象出现,就此可以排除客户端的问题,接下来就是我们的重头戏:服务端排查!
2. 服务端排查
我们的 server 端是一个 Spring MVC 服务,对于登录接口来说,它的逻辑如下
@RestController
@RequestMapping(path = "/api/auth", method = RequestMethod.POST)
@Slf4j
public class AuthController {
@RequestMapping(params = "member.login")
public ResultTO<TokenDTO> login(@RequestBody UserLoginDTO userLogin) {
/** 这里写登录逻辑 */
return ResultTO.responseSuccess(tokenDTO);
}
}
里面的逻辑其实非常简单,就是根据用户名输入的账号密码去 db 请求一下校验用户信息是否正确,正确则生成 jwt token 返回给前端,看起来没啥问题,当然为了确保这段逻辑确实没问题,我们可以用一些工具来帮助我们实时验证一下,这里推荐一款阿里开源的 Java 诊断工具:Arthas,采用命令行交互模式,提供了丰富的功能,是排查 jvm 相关问题的利器,简单列举一下它的功能:
提供性能看板,包括线程、cpu、内存等信息,并且会定时的刷新。
根据各种条件查看线程快照。比如找出cpu占用率最高的 n 个线程等
输出jvm的各种信息,如 gc 算法、jdk 版本、ClassPath 等
查看/设置sysprop和sysenv
查看某个类的静态属性,也可以通过 ognl 语法执行一些语句
查看已加载的类的详细信息,比如这个类从哪个 jar 包加载的。也可以查看类的方法的信息
dump 某个类的字节码到指定目录
直接反编译指定的类
查看类加载器的一些信息
可以让jvm重新加载某个类
监控方法的执行,同时可以获取到执行的入参、出参以及抛出的异常
追踪方法执行的调用栈,以及各个方法的调用时间
这里我们要用到它的最后一项功能,实时查看各个方法的调用时间,整个使用 arthas 的步骤如下
1、 首先我们要先下载一下 arthas,如下
curl -O https://arthas.aliyun.com/arthas-boot.jar
2、 启动 arthas,启动后会展示一个 java 进程列表,我们选中 Arthas 将要调试的 Spring MVC 进程,以下选中 2,然后即可进入 arthas 的交互式界面(以下 arthas 展示的其实不只这么多信息,过滤了不少描述性的信息,只保留对大家有用的核心信息)
[root@d-sts-sh-1-spring-mvc-service-0 buser]# /opt/java8/bin/java -jar arthas-boot.jar
[INFO] arthas-boot version: 3.5.1
[INFO] Found existing java process, please choose one and input the serial number of the process, eg : 1. Then hit ENTER.
* [1]: 99 org.apache.flume.node.Application
[2]: 2698 /opt/apps/business/spring-mvc-service.jar
2
[arthas@2698]$
然后我们就可以用 arthas 的 trace 命令来追踪方法调用,什么是 trace 命令,官方对其功能的介绍如下:
追踪方法内部调用路径,并输出方法路径上的每个节点上耗时,trace 命令能主动搜索 class-pattern/method-pattern 对应的方法调用路径,渲染和统计整个调用链路上的所有性能开销和追踪调用链路。
现在我们要跟踪 login 的实时耗时,那就可以指定「trace + 此方法所在类的全限定名(包名+类名)+方法名」来跟踪了,如下
[arthas@2698]$ trace com.xxx.AuthController login
然后在浏览器执行登录操作,当浏览器登录时间为 3s+ 时, trace 对应的追踪结果如下
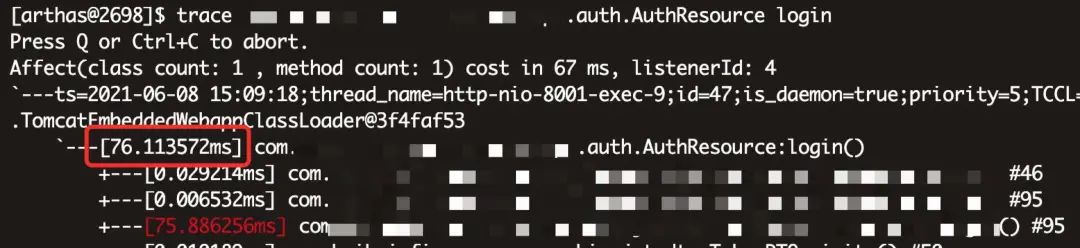
可以看到登录只花费了 76 ms,远达不到 3 s,那是否可以就此断定此台机器服务没问题呢?
PS:我们线上的 SpringMVC 服务部署了两台机器,另一台机器也打开了 arthas 调试,也是 76 ms 左右
答案是不行,我们先来看一下 Spring MVC 的请求流转图
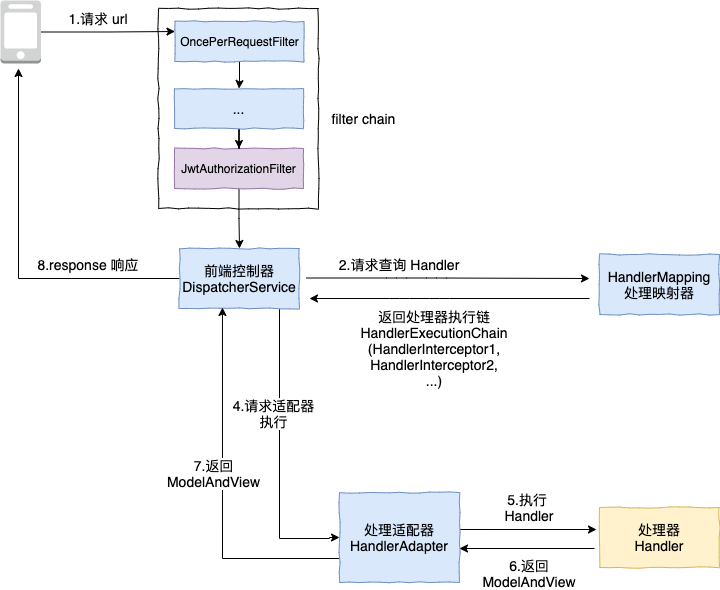
上图黄色部分的处理器即处理业务逻辑的 Controller,可以看到从请求到 Controller 还要经过 filter chain,DispatcherService 等类,在最开始的 filter chain 中,紫色的 JwtAuthorizationFilter 是我们自定义的 filter,是否有可能是这个 filter 处理过慢导致的呢,所以我们最好在请求的起始点 OncePerRequestFilter 的 doFilter 方法(实际上在此 filter 之前还要经过不少流转,不过在此之前都是框架的正常处理流程,可忽略) 来执行 arthas 的 trace。
当浏览器的登录请求为 3s+ 时,再次观察此次的 trace 结果:
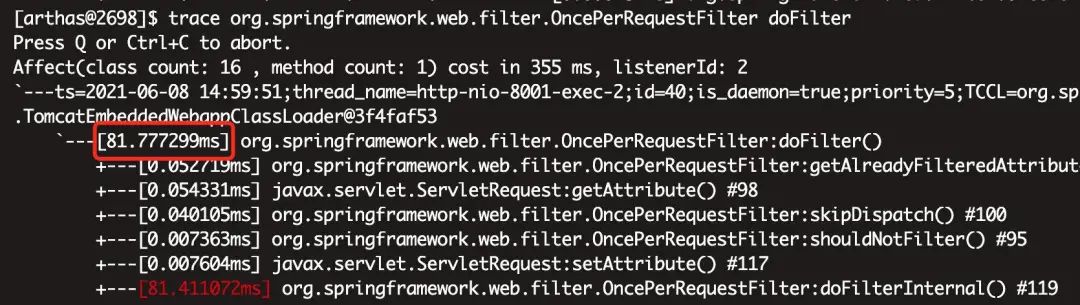
也不过区区 81 ms! 在生产的两台机器上都试了多次,结论为当前端请求为 3s 时,两台机器的执行时间都为 81 ms 左右!至此可以断定线上的两台机器 SpringMVC 服务是没有问题的!既然线上机器服务没有问题,那只能从流量的流转路径着手了,客户端发出请求要经过哪些流程才能到达 SpringMVC 服务?
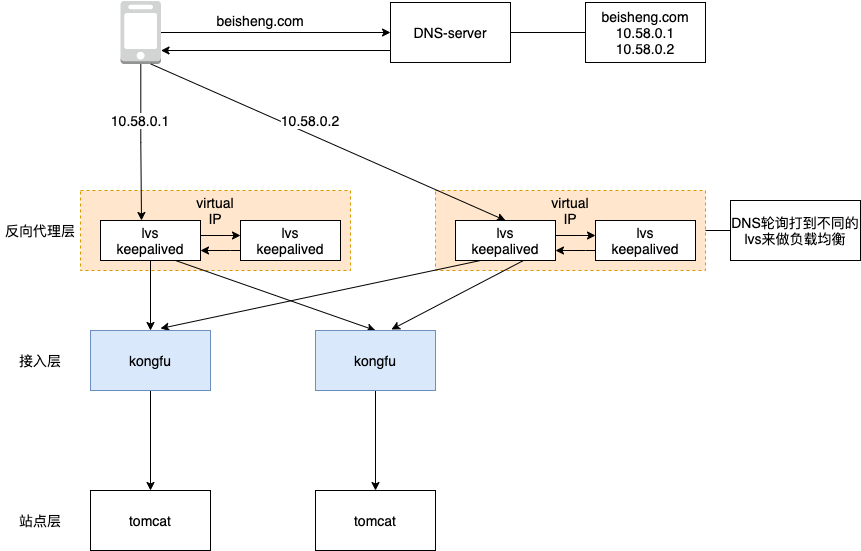
可以看到请求需要经过反向代理层,接入层后才能到达我们的站点层(即我们的 Spring MVC 服务),也就是说从「反向代理层到接入层」及「接入层到站点层」都可能导致请求缓慢,于是我把我用 arthas trace 执行的结果(MVC 服务执行时间 80ms 左右)与前端请求有 1/3 的概率超过 3s 的结论告诉了运维,让他们排查一下从反向代理层到站点层这中间是否有啥问题,不一会儿果然查出了问题。
结论是这样的:本来 MVC 服务的机器有三台,后来缩容了一台,变成了两台,但接入层 kongfu 依然持有这台被缩容的机器 ip,没有将其踢掉,所以前端流量打进来后,由于接入层的负载均衡策略,请求是有 1/3 的概率打到这台下线机器的 ip 上的,由于这个 ip 对应的机器无法响应这个请求,等到超时后,kongfu 会重试把这个请求打到另外正常的两台机器中的任意一台,也就是说请求 3s 中的大部分时间花在了等待那台不正常的 ip 机器响应上了。
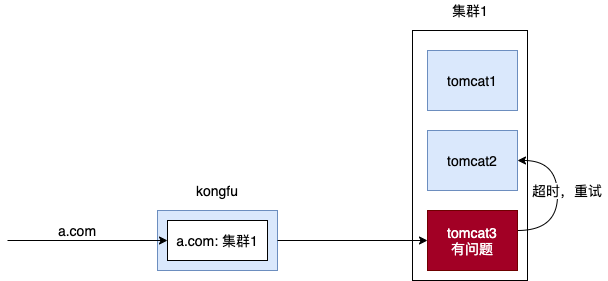
有人可能会问,机器被踢掉了,接入层 kongfu 应该是能检测其下线的吧,怎么还会给这台下线的机器发请求呢?
是的,kongfu 会通过端口检测来检测机器是否存活的,但问题是,这台被缩容的机器虽然被回收了,但它的 ip 也是可以重新被分配给其他机器的,这种情况下 kongfu 通过端口检测就会认为它持有的 ip 对应的机器是存活的,而这台被分配此 ip 的机器又刚好不是 Spring MVC 服务,那正常 MVC 请求打给它的话,它就无法处理了,只能等到请求超时再由 kongfu 重试转发给正常的机器。
有人可能会好奇,运维是怎么查出来的呢,通过 「curl -I www.example」的形式可以输出开头信息,然后加上 -b 选项可以带上 cookie,我们的接入层如果发现请求里带有某些特殊的 cookie 会返回一个名为「X-KF-Via」的头字段,如下
X-KF-Via: agw(bip=10.65.x.1:8001,10.65.x.2:8001;b=mvc_service)
这个头字段表示,请求 mvc_service 服务总共请求了两台机器,第一台 10.65.x.1 未成功后,再接着重试 10.65.x.2:8001,所以由此可以排查出 10.65.x.1 这台机器有问题,所以你看熟悉系统架构有多重要,如果我早知道有这么一个选项,就可以一步到位排查出此问题了
知道了问题所在,处理方案就很简单了,直接把这台有问题的机器从 kongfu 摘掉就行了
总结
排查的思路其实相对比较清晰,但一定要对请求的整个流转流程有一个比较清醒的认识,这样才能快速判断出问题所在,现在再回头看下开头的那道经典面试题「请详细地说出从浏览器地址栏输入 url 到最终呈现出结果的过程,越详细越好」,相信你会颇有感触,这道面试题如果你对请求流转的每个点都吃透得话,将极大地提升你排查解决问题的能力,举个例子,之前就有人反馈这样的一个问题:
在做 Server 压力测试时发现,客户端给服务器不断发请求,并接受服务器端的响应。发现接收服务器响应的过程中,会出现 recv 服务器端响应,阻塞 40ms 的情况,但是查看 server 端日志,Server 都在 2ms 内将请求处理完成,并给客户端响应
如果你了解 TCP,就知道它是由于 TCP 的延迟确认机制和 Nagle 算法及拥塞控制导致的,自然而然就会朝着这个方向 去解决了,比如打开 TCP_NODELAY 选项等。