
强烈建议你学这 3 个 Python AutoEDA 工具包!
关注上方"机器学习社区",
设为"置顶或星标",第一时间送达干货
数据科学爱好者知道,在将原始数据输入机器学习模型解决实际问题之前,需要对其进行大量处理。根据问题的类型(回归或分类),需要遵循一系列步骤来准备和格式化数据。为了探索数据集,Python 是可以说是最强大的数据分析工具之一。此外,它可以更好地数据可视化。
数据科学和机器学习不仅仅是拥有强大计算机科学背景的人可以接触到的。相反,越来越多的来自不同行业的专业人士已加入这一领域。但是对于一个刚刚开始机器学习的初学者来说,也不是一件很容易的事情。
在本文中,我们将讨论三个面向初学者非常友好的自动化 EDA Python 库,在文末我会分享其他有趣的 AutoEDA 库。喜欢的小伙伴欢迎收藏学习、点赞。
首先我们加载一下数据
#loading the dataset
from sklearn import datasets
import pandas as pd
data = datasets.load_iris()
df = pd.DataFrame(data.data,columns=data.feature_names)
df['target'] = pd.Series(data.target)
df.head()
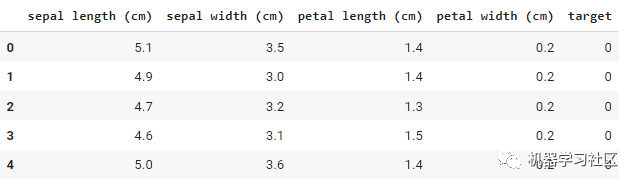 如果我们不使用 AutoEDA,这里有一个通常用于 EDA 的命令列表,用于打印有关 DataFrame/数据集的不同信息
如果我们不使用 AutoEDA,这里有一个通常用于 EDA 的命令列表,用于打印有关 DataFrame/数据集的不同信息
df.head() – 前五行
df.tail() – 最后五行
df.describe() – 有关数据集的百分位数、平均值、标准偏差等的基本统计信息
df.info() – 数据集摘要
df.shape() – 数据集中的观察值和变量的数量,即数据的维度
df.dtypes() – 变量的数据类型(int、float、object、datetime)
df.unique()/df.target.unique() – 数据集/目标列中的唯一值
df[‘target’].value_counts() – 分类问题的目标变量分布
df.isnull().sum()- 计算数据集中的空值
df.corr() – 相关信息
等等..
AutoEDA 库可以通过几行 Python 代码快速完成所有这些以及更多工作。但在我们开始之前,让我们先检查安装的 Python 版本,因为这些库需要 Python >=3.6。
print(python --version) # check installed Python version
1. Pandas Profiling
首先,auto-EDA 库是一个用 Python 编写的开源选项。它为给定的数据集生成一个全面的交互式 HTML 报告。它能够描述数据集的不同方面,例如变量类型、处理缺失值、数据集的众数。
要安装库,请在 jupyter notebook 中输入并运行以下命令
!pip install pandas-profiling
EDA 使用 Pandas Profiling
我们将首先导入主包pandas 来读取和处理数据集。
接下来,我们将导入pandas profiling
import pandas_profiling
#Generating PandasProfiling Report
report = pandas_profiling.ProfileReport(df)
从报告中,初学者可以很容易地理解 iris 数据集中有 5 个变量——4 个数字变量,结果变量是分类变量。此外,数据集中有 150 个样本并且没有缺失值。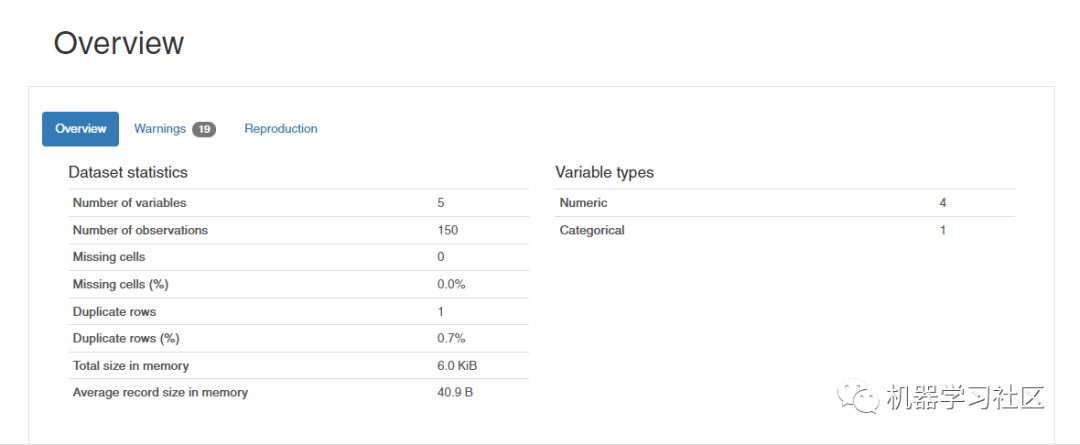 下面由 Pandas 分析生成的一些示例图有助于理解我们之前列出的命令的相关性、唯一值和缺失值。
下面由 Pandas 分析生成的一些示例图有助于理解我们之前列出的命令的相关性、唯一值和缺失值。 相关性
相关性
 总的来说,Pandas Profiling 在从数据集中可以快速生成方面令人印象深刻。
总的来说,Pandas Profiling 在从数据集中可以快速生成方面令人印象深刻。
2. Sweetviz
这是一个开源 Python 库,仅使用两行代码即可执行EDA。该库为数据集生成的报告以.html 文件形式提供,可以在任何浏览器中打开。使用 Sweetviz,我们可以实现:
数据集特征如何与目标值相关联
可视化测试和训练数据并比较它们。我们可以使用analyze()、compare() 或compare_intra() 来评估数据并生成报告。
绘制数值和分类变量的相关性
总结有关缺失值、重复数据条目和频繁条目的信息以及数值分析,即解释统计值
要安装库,请在 jupyter notebook 运行以下命令
!pip install sweetviz
EDA 使用 Sweetviz
与前面的部分类似,我们将首先导入pandas 来读取和处理数据集。
接下来,我们只需导入 sweetviz 来探索数据。
import sweetviz as sv
#Generating Sweetviz report
report = sv.analyze(df)
report.show_html("iris_EDA_report.html") # specify a name for the report
这就是典型的 Sweetviz 报告的样子 确实令人印象深刻和漂亮。
确实令人印象深刻和漂亮。
3. AutoViz
AutoViz 只需一行代码即可快速分析任何数据。要安装库,与以上类似。
from autoviz.AutoViz_Class import AutoViz_Class
AV = AutoViz_Class()
#Generating AutoViz Report #this is the default command when using a file for the dataset
filename = ""
sep = ","
dft = AV.AutoViz(
filename,
sep=",",
depVar="",
dfte=None,
header=0,
verbose=0,
lowess=False,
chart_format="svg",
max_rows_analyzed=150000,
max_cols_analyzed=30,
)
由于我们使用的是库中的数据集,我们需要如下修改
#Generating AutoViz Report
filename = "" # empty string ("") as filename since no file is being used for the data
sep = ","
dft = AV.AutoViz(
'',
sep=",",
depVar="",
dfte=df,
header=0,
verbose=0,
lowess=False,
chart_format="svg",
max_rows_analyzed=150000,
max_cols_analyzed=30,
)

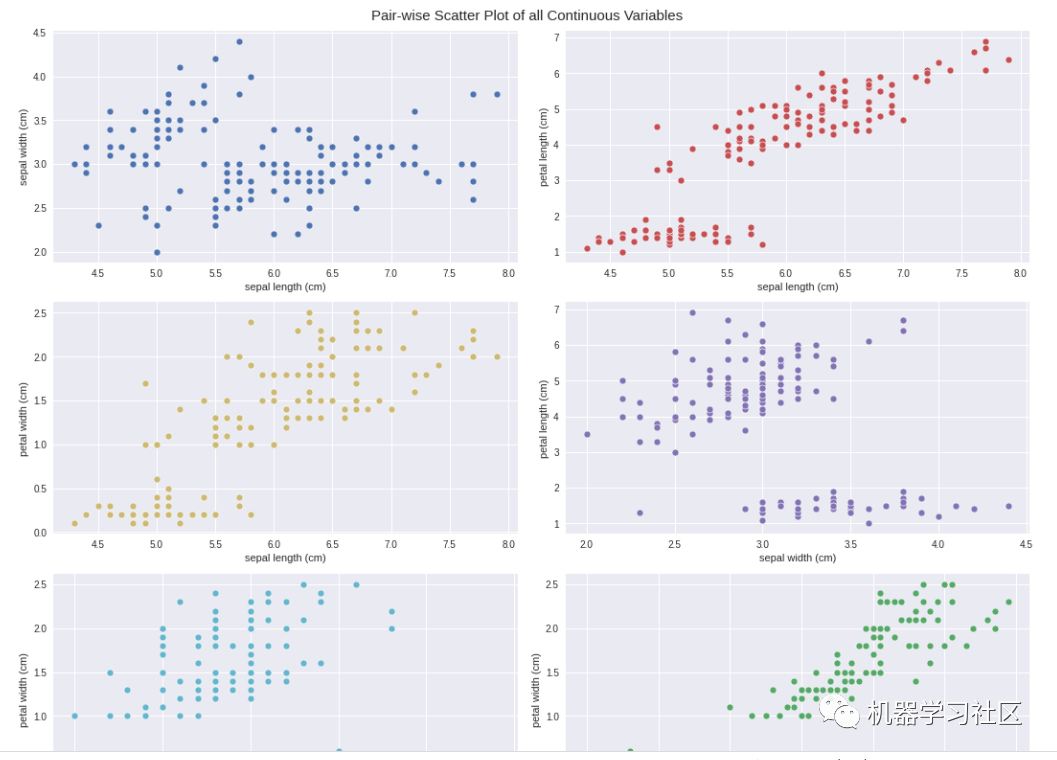
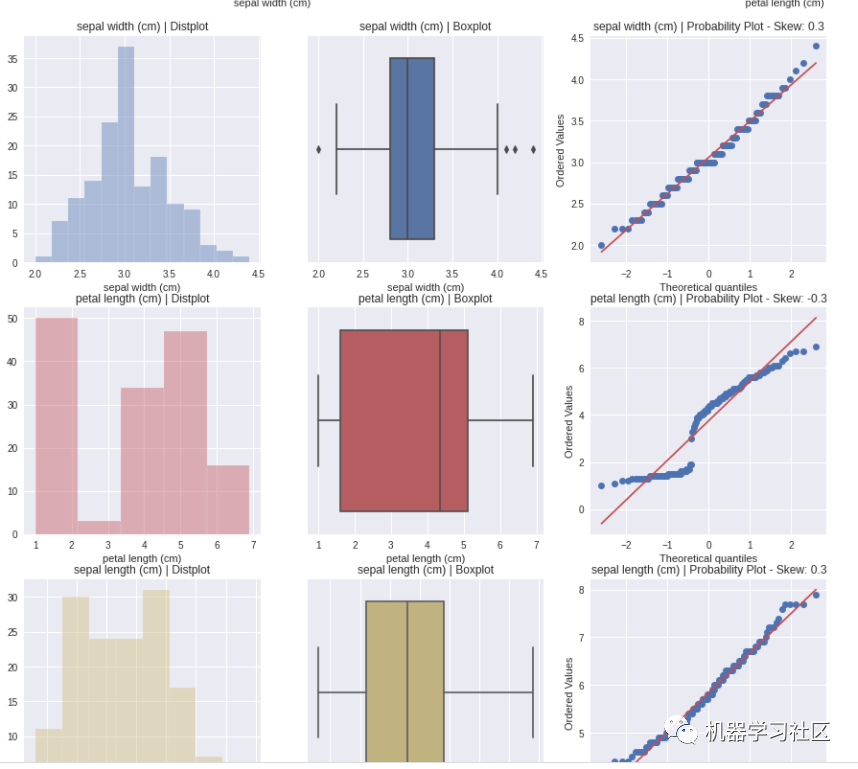
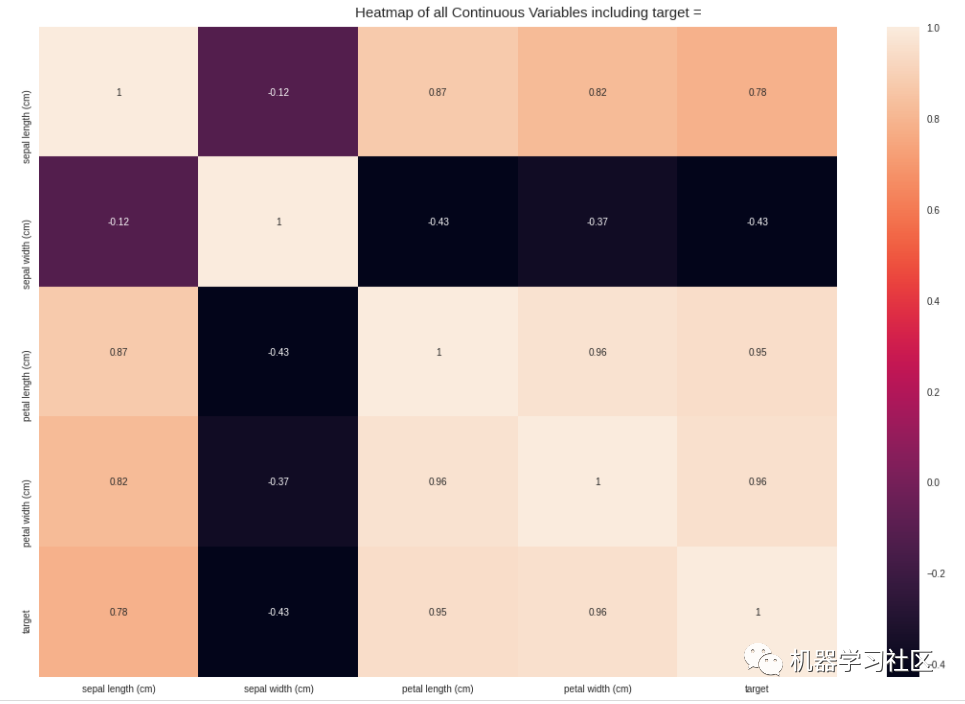
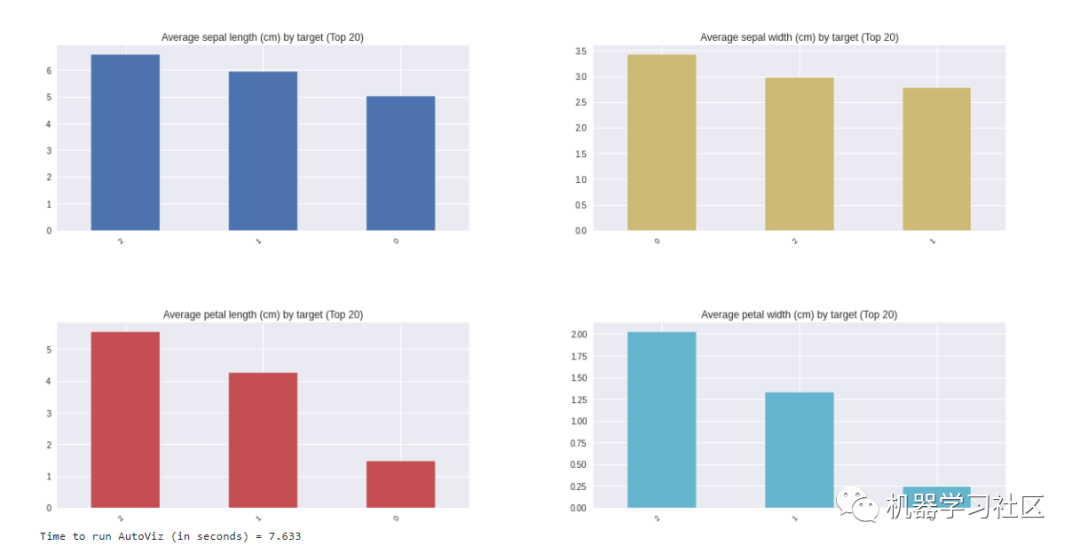 AutoViz 报告包括有关数据集形状的信息以及所有可能的图表,包括条形图、小提琴图、相关矩阵(热图)、配对图等。所有这些信息与一行代码肯定对任何初学者都有用。
AutoViz 报告包括有关数据集形状的信息以及所有可能的图表,包括条形图、小提琴图、相关矩阵(热图)、配对图等。所有这些信息与一行代码肯定对任何初学者都有用。
结论
还有其他有趣的 AutoEDA 库,如 Dora、D-Tale 和 DataPrep,它们类似于本文中讨论的这三个库,如果你感兴趣,可以深入研究。
从初学者的角度来看,Pandas Profiling、Sweetviz 和 AutoViz 似乎是最简单的生成报告以及呈现数据集洞察力的工具。
参考:
https://github.com/Devashree21/AutoEDA-Iris-AutoViz-Sweetviz-PandasProfiling https://pypi.org/project/pandas-profiling/[accessed: Aug-09-2021] https://pypi.org/project/sweetviz/ [accessed: Aug-09-2021] https://pypi.org/project/autoviz/ [accessed: Aug-09-2021]
(完)
欢迎大家加入机器学习社区技术交流群,加入方式非常简单,在下方二维码后台回复:加群,备注说明:你的研究方向,小助手拉你入群。
长按扫码,申请入群
推荐阅读