
不到 30 行代码,我自制了一个成语接龙小游戏!
大家好,我是杰哥。
中国文化底蕴深厚,在漫长的历史中,我们的语言文字形成了大量特定的组合,用来表达特定的意思。成语是中国传统文化的一大特色,有的来源于典故,有的则来源于固定的使用方法。在成语类的比赛中,经常有“成语接龙”的比赛,往往是双方对战,一方先提出一个成语,然后另一方根据这个成语最后一个字的拼音,作为下一个成语的首拼,承接下去。

本文中,我们希望借助R语言的文本处理工具做一个简单的成语接龙小游戏,可以满足简单的人机对战的需求。首先,让我们在R中加载基本的环境:
if(!require(pacman)) install.packages("pacman")
## Loading required package: pacman
pacman::p_load(tidyfst,pinyin,stringr)
在上面加载的包中,tidyfst包用于数据的处理,pinyin包用于把汉字转化为其拼音,stringr包则被用于字符串的处理。
首先,我们需要对成语的数据集进行加载。这需要我们有中华成语的语料库,在GitHub中有相关的库可以用,详情见:https://github.com/pwxcoo/chinese-xinhua。这个项目中的idiom.json文件包含了成语的信息,可以使用jsonlite包将其读入并转化为数据框。这里我们不详细展开数据获取和转化的过程,我们最终把数据存储在名为“chengyu.csv”的文件中,它只有一列,我们在这里进行简单展示:
fread("chengyu.csv",encoding = "UTF-8") # 编码格式需要设置,否则可能显示乱码
## word
## <char>
## 1: 阿谀奉承
## 2: 阿党比周
## 3: 阿党相为
## 4: 阿狗阿猫
## 5: 阿姑阿翁
## ---
## 30891: 做一天和尚撞一天钟
## 30892: 做贼心虚
## 30893: 做张做势
## 30894: 做张做致
## 30895: 做张做智
我们看到,这份数据只有一列成语,共30895行,列名为word。仅仅是这个数据框还不足够,我们还需要有每一个成语的首字拼音(简称“首拼”)和尾字拼音(简称“尾拼”)。关于这个步骤,我们可以使用pinyin包进行实现,具体操作如下:
my_dic = pydic(method = "tone",dic = "pinyin2") # 设置词典
# 取得成语的首拼和尾拼
chengyu = fread("chengyu.csv",encoding = "UTF-8")%>%
mutate_dt(shoupin = str_sub(word,1,1)
%>% py(dic = my_dic),
weipin = str_sub(word,-1,-1) %>% py(dic = my_dic))
# 展示结果
chengyu
## word shoupin weipin
## <char> <char> <char>
## 1: 阿鼻地狱 a1 yu4
## 2: 阿党比周 a1 zhou1
## 3: 阿党相为 a1 wei2
## 4: 阿狗阿猫 a1 mao1
## 5: 阿姑阿翁 a1 weng1
## ---
## 30891: 做一天和尚撞一天钟 zuo4 zhong1
## 30892: 做贼心虚 zuo4 xu1
## 30893: 做张做势 zuo4 shi4
## 30894: 做张做致 zuo4 zhi4
## 30895: 做张做智 zuo4 zhi4
在上面的操作中,str_sub函数用来提取成语的第一个字和最后一个字,然后利用py函数来将其转化为首拼和尾拼。pinyin包中有两套词典,这里用“pinyin2”词典来完成转化,因为它的错误率较低
(“pinyin1”词典有bug,详情可参考:https://github.com/pzhaonet/pinyin/issues/16)
下面,我们要设置一个小游戏。游戏中,我们首先提示用户输入一个成语,然后把用户写入的字符串导入,然后把匹配到的第一个成语输出来,作为接龙的结果。如果库内没有匹配的成语,那么就输出“好吧,你赢了。”,然后换行。如果匹配上了,就直接输出匹配结果。当用户想退出的时候,键入大写字母Q,然后按回车即可。实现代码如下:
game = function(){
chengyu1 = chengyu
repeat{
cat("请输入一个成语(认输或离开请按Q):")
input = readline()
if(input == "Q") break else chengyu1 = chengyu1[word != input]
str_sub(input,-1,-1) %>% py(dic = my_dic) -> input_weipin
res = chengyu1[shoupin == input_weipin]
if(nrow(res) == 0) {
cat("好吧,你赢了。\n")
}else{
cat(res$word[1])
chengyu1 = chengyu1[word != res$word[1]]
cat("\n")
}
}
}
现在,game函数中就封装了我们这个游戏的所有过程。下面我们进行简单的解释:
1、把chengyu这个数据框复制一份放在chengyu1中,因为我们在成语接龙中不允许成语重复出现,因此出现过一次的成语都会删掉。
2、readline函数可以让用户交互式地读入一段字符串;
3、cat函数可以在屏幕中输出一段文字对话;
4、repeat语句相当于while(1),如果没有跳出语句(break),它会一直执行下去。
下面,我们可以尝试玩耍,从而进行测试:
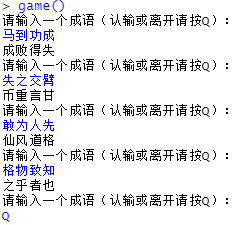
成语接龙测试
我们可以看到,基于命令行的小游戏没有出现明显的问题。这样,我们就用了不到30行的代码完成了成语接龙的小游戏,实现的完成代码如下:
if(!require(pacman)) install.packages("pacman")
pacman::p_load(tidyfst,pinyin,stringr)
my_dic = pydic(method = "tone",dic = "pinyin2")
chengyu = fread("chengyu.csv",encoding = "UTF-8")%>%
mutate_dt(shoupin = str_sub(word,1,1)
%>% py(dic = my_dic),weipin = str_sub(word,-1,-1) %>% py(dic = my_dic))
chengyu
game = function(){
chengyu1 = chengyu
repeat{
cat("请输入一个成语(认输或离开请按Q):")
input = readline()
if(input == "Q") break else chengyu1 = chengyu1[word != input]
str_sub(input,-1,-1) %>% py(dic = my_dic) -> input_weipin
res = chengyu1[shoupin == input_weipin]
if(nrow(res) == 0) {
cat("好吧,你赢了。\n")
}else{
cat(res$word[1])
chengyu1 = chengyu1[word != res$word[1]]
cat("\n")
}
}
}
game()
在这个基础上,我们还可以让电脑和电脑自己玩接龙游戏,从而得到一大串没有重复的成语接龙结果。此外,还可以利用shiny包做一个漂亮的人机交互界面。
通过这个例子中,我们可以看到R语言强大的文本挖掘能力,但这都是比较零散的知识。要系统地学习一套R语言文本挖掘的系统知识与技术,可以参考机械工业出版社出版的新作《文本数据挖掘——基于R语言》。
该书立足于R语言与文本挖掘知识基础,实用性和趣味性兼具,循序渐进地引导读者掌握各项文本挖掘实现。书中包含大量代码,因此也可以作为工具书为文本挖掘用户提供R代码参考。
赠书福利
书籍赞助方: 机械工业出版社计算机分社
赠书书籍:《文本数据挖掘基于 R 语言》
赠书规则: 为本文「点赞」+ 「在看」 +「留言」且与文章内容相关的优质留言即可上墙并从所有留言中选出点赞最多的前三位读者留言将各获得一本。
截止时间: 2021年6月22日,晚 20:00
领书须知: 提供转发截图 + 点赞和在看截图
注意事项: 凡发现刷赞者一律取消资格,最终获赠者请在24小时以内添加我的微信,备注:赠书👇
原创专辑
杰哥的另一个公众号,主要分享关于个人成长经历的那点事,欢迎您的关注。
