【测试】680- 京喜前端自动化测试之路
前言—
京喜(原京东拼购)项目,作为京东战略级业务,拥有千万级别的流量入口。为了保障线上业务的稳定运行,每月例行开展前端容灾演习,主要包含小程序及 H5 版本,要求各页面各模块在异常情况下进行适当的降级处理,不能出现空窗、样式错乱、不合理的错误提示等体验问题。
原来的容灾演习过程:小程序(通信方式改成 HTTPS )和 H5 通过 Whistle 对接口返回进行修改来模拟异常情况,验证各页面各模块的降级处理符合预期。
容灾演习是一项长期持续的工作,且涉及页面功能及场景多,人工的切换场景模拟异常导致演习效率很低,因此想通过开发自动化测试工具来提升研发效率,让容灾演习工作随时可以轻松开展。京喜 H5 和小程序场景差异比较大,因此自动化测试之路分 H5 和小程序两部分进行,以 H5 作为一个开篇。
综上所述,我们希望京喜 H5 自动化测试工具可以提供以下功能:
访问目标页面,对页面进行截图; 设置 UA(模拟不同渠道:微信、手Q、其它浏览器等); 模拟用户点击、滑动页面操作; 网络拦截、模拟异常情况(接口响应码 500、接口返回数据异常); 操作缓存数据(模拟有无缓存的场景等)。
技术选型—
提到 Web 的自动化测试,很多人熟悉的是 Selenium 2.0(Selenium WebDriver), 支持多平台、多语言、多款浏览器(通过各种浏览器的驱动来驱动浏览器),提供了功能丰富的API接口。而随着前端技术的发展,Selenium 2.0 逐渐呈现出环境安装复杂、API 调用不友好、性能不高等缺点。新一代的自动化测试工具 —— Puppeteer ,相较于 Selenium WebDriver 环境安装更简单、性能更好、效率更高、在浏览器执行 Javascript 的 API 更简单,它还提供了网络拦截等功能。
Puppeteer[1] 是一个 Node 库,它提供了一套高阶 API ,通过 Devtools 协议控制
Chromium或Chrome浏览器。Puppeteer默认以Headless模式运行,但是可以通过修改配置文件运行“有头”模式。
官方描述的功能:
生成页面 PDF; 抓取 SPA(单页应用)并生成预渲染内容(即“ SSR ”,服务器端渲染); 自动提交表单,进行 UI 测试,键盘输入等; 创建一个时时更新的自动化测试环境,使用 JavaScript 和最新的浏览器功能直接在最新版本的 Chrome 中执行测试; 捕获网站的 Timeline Trace,用来帮助分析性能问题; 测试浏览器扩展。
Puppeteer 提供了一种启动 Chromium 实例的方法。当 Puppeteer 连接到一个 Chromium 实例的时候会通过 puppeteer.launch 或 puppeteer.connect 创建一个 Browser 对象,再通过 Browser 创建一个 Page 实例,导航到一个 Url ,然后保存截图。一个 Browser 实例可以有多个 Page 实例。下面就是使用 Puppeteer 进行自动化的一个典型示例:
const puppeteer = require('puppeteer');
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
await page.goto('https://example.com');
await page.screenshot({path: 'screenshot.png'});
await browser.close();
});
综上所述,我们选择基于 Puppeteer 来开发京喜首页容灾演习的自动化测试工具,通过 Puppeteer 提供的一系列 API ,实现访问目标页面、模拟异常场景、生成截图的过程自动化。最后再通过人工比对截图,判断页面降级处理是否符合预期、用户体验是否友好。
实现方案—
我们将容灾演习过程分为自动化流程和人工操作两部分。
自动化流程:
模拟用户访问页面操作; 拦截网络请求,修改接口返回数据,模拟异常场景(接口返回 500、异常数据等); 生成截图。
人工操作:
自动化脚本执行完毕后,人工比对各个场景的截图,判断是否符合预期。
方案流程图: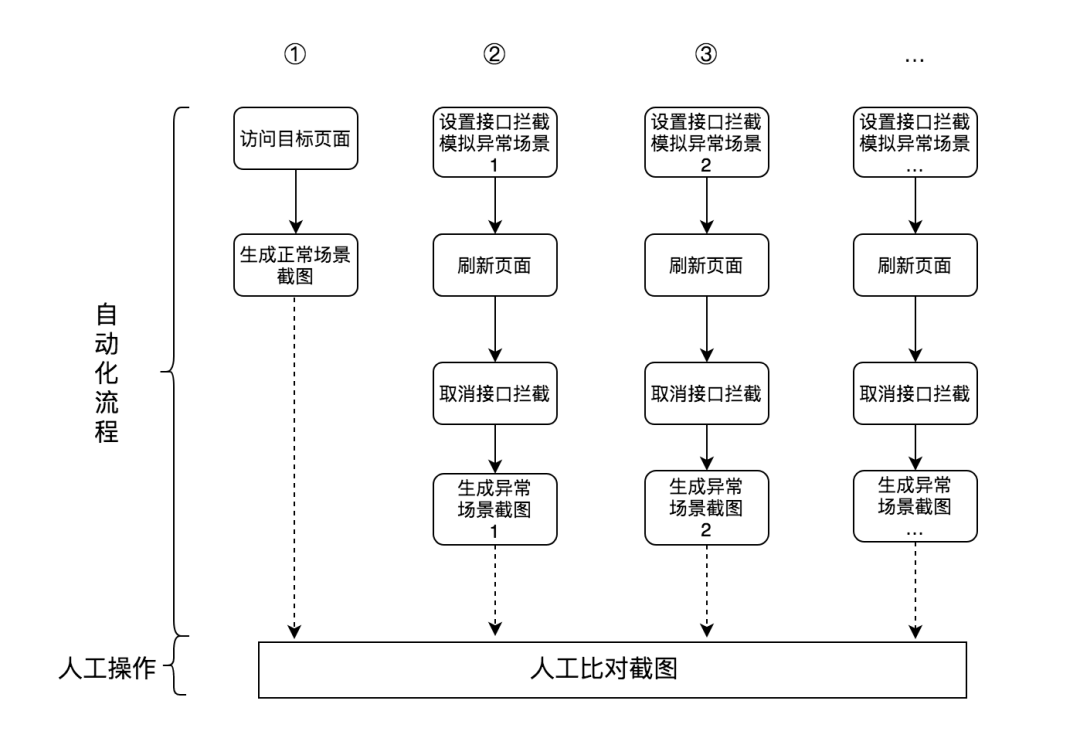
开发实录—
安装 Puppeteer ,你可能会遇到的那些事
通过 npm init 初始化项目后, 就可以安装 Puppeteer 依赖了:
npm i puppeteer :在安装时自动下载最新版本 Chromium。
或者
npm i puppeteer-core :在安装时不会自动下载 Chromium。(不能生成截图)
另外,在安装过程中可能会因为下载 Chromium 导致报错,官网建议是先通过 npm i --save puppeteer --ignore-scripts 阻止下载 Chromium, 然后再手动下载 Chromium[2] 。
手动下载后,需要配置指定路径,修改 index.js 文件
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
// 运行 Chromium 或 Chrome 可执行文件的路径(相对路径)
executablePath: './chrome-mac/Chromium.app/Contents/MacOS/Chromium',
headless: false
});
const page = await browser.newPage();
await page.goto('https://example.com');
await page.screenshot({path: 'screenshot.png'});
browser.close();
})();
快速创建测试用例
为了提高测试脚本的可维护性、扩展性,我们将测试用例的信息都配置到 JSON 文件中,这样编写测试脚本的时候,我们只需关注测试流程的实现。
测试用例 JSON 数据配置包括公用数据(global)和私有数据:
公用数据(global):各测试用例都需要用到的数据,如:模拟访问的目标页面地址、名字、描述、设备类型等。
私有数据:各测试用例特定的数据,如测试模块信息、API 地址、测试场景、预期结果、截图名字等数据。
{
"global": {
"url": "https://wqs.jd.com/xxx/index.shtml",
"pageName": "index",
"pageDesc": "首页",
"device": "iPhone 7"
},
"homePageApi": {
"id": 1,
"module": "home_page_api",
"moduleDesc": "首页主接口",
"api": "https://wqcoss.jd.com/xxx",
"operation": "模拟响应码 500",
"expectRules": [
"1. 显示异常信息、刷新按钮",
"2. 点击刷新按钮,显示异常信息",
"3. 恢复网络,点击刷新按钮,显示正常数据"
],
"screenshot": [
{
"name": "normal",
"desc": "正常场景"
},
{
"name": "500_cache",
"desc": "有缓存-返回500"
},
{
"name": "500_no_cache",
"desc": "无缓存-返回500"
},
{
"name": "500_no_cache_reload",
"desc": "无缓存-返回500-点击刷新按钮"
},
{
"name": "500_no_cache_recover",
"desc": "无缓存-返回500-恢复网络"
}
]
},
…
}
编写测试脚本
我们以京喜首页主接口的测试用例为例子,通过模接口返回 500 响应码的异常场景,验证主接口的异常处理机制是否完善、用户体验是否友好。
预期效果:
有缓存情况下,显示缓存数据 无缓存情况下显示异常信息、刷新按钮 点击刷新按钮,显示异常信息 恢复网络,点击刷新按钮,显示正常数据
测试流程:
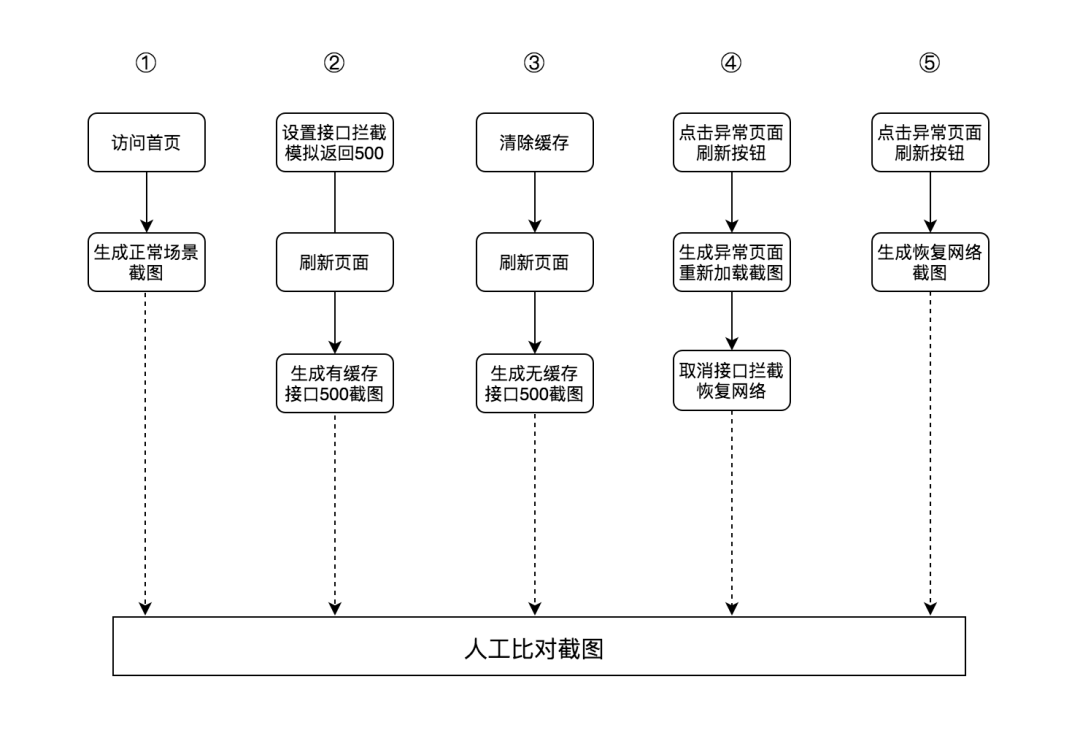
场景实现:
根据测试流程以及配置的测试用例信息,编写测试脚本,实现测试用例场景:
访问页面
await page.goto(url)
生成截图
await page.screenshot({
path: './screenshot/index_home_page_500.png'
})
拦截接口请求
async test () => {
... // 创建 Page 实例,访问首页
await page.setRequestInterception(true) // 设置拦截请求
page.on("request", interceptionEvent) // 监听请求事件,当请求发起后页面会触发这个事件
... // 刷新页面,触发请求拦截,生成测试场景截图
}
若测试用例需要拦截不同的请求,或是模拟多种场景,则需要设置多个请求监听事件。且一个事件执行结束后,必须要移除事件监听,才能继续下一个事件监听。
添加事件监听:page.on("request", eventFunction)
移除事件监听:page.off("request", eventFunction)
// 设置拦截请求
await page.setRequestInterception(true)
const iconInterception1 = requestInterception(api, "body")
// 添加事件 1 监听
page.on("request", iconInterception1)
await page.goto(url)
await page.screenshot({
path: './screenshot/1.png'
})
// 移除事件 1 监听
page.off("request", iconInterception1)
const iconInterception2 = requestInterception(api, "body", )
// 添加事件 2 监听
page.on("request", iconInterception2)
await page.goto(url)
await page.screenshot({
path: './screenshot/2.png'
})
// 移除事件 2 监听
page.off("request", iconInterception2)
模拟异常数据场景,生成 mock 数据。
function requestInterception (api, setProps, setValue) {
let mockData
switch (setProps) {
case"status": // 修改返回状态码
mockData = {
status: setValue
}
break
case"contentType": // 修改返回内容类型
mockData = {
contentType: setValue
}
break
case"body": // 修改返回数据
mockData = {
contentType: getMockResponse(setValue)
}
break
default:
break
}
returnasync req => {
// 如果是需要拦截的 API,则通过 req.respond(mockData) 修改返回数据,否则 continue 继续请求别的
if (req.url().includes(api)) { // 拦截 API
req.respond(mockData) // 修改返回数据
returnfalse// 处理完了某个请求必须退出,不再执行 continue
}
req.continue()
}
模拟接口返回 500:
const interception500 = requestInterception(api, 'status', 500)
page.on("request", interception500) // 当请求发起后页面会触发这个事件
模拟异常数据:
const iconInterception = requestInterception(api, "body", {
"data": {
"modules": [{
"tpl": "3000",
"content": []
}]
}
})
page.on("request", iconInterception)
生成 mock 数据有两种实现方案,可依据实际情况而定:
[ ] 直接通过修改接口真实返回的数据生成 mock 数据,需要先获取接口实时返回数据 [x] 本地存储一份完整的接口数据,通过修改本地存储数据的方式生成 mock 数据(本文所述案例均基于此方案实现)
若选择第一种方案,则需先拦截接口请求,通过 req.response() 获取接口实时返回数据,根据测试场景修改实时返回数据作为 mock 数据。
由于京喜 H5 页面接口返回是 JSONP 格式的数据,所以在模拟返回数据的时候,必须先截取 JSONP 的 callback 信息,与模拟数据拼接后再返回;
function requestInterception (api, setProps, setValue) {
let mockData
switch (setProps) {
case"status":
mockData = {
status: setValue
}
break
case"contentType":
mockData = {
contentType: setValue
}
break
default:
break
}
returnasync req => {
if (req.url().includes(api)) {
if (setProps === "body") {
const callback = getUrlParam("callback", req.url()) // 获取 callback 信息
const localData = getLocalMockResponse(api) // 匹配 API ,获取本地存储数据
mockData = {
body: getResponseMockLocalData(localData, setValue, callback, api) // 生成 mock 数据
}
}
req.respond(mockData) // 设置返回数据
returnfalse
}
req.continue()
}
}
清除缓存
page.evaluate(() => {
try {
localStorage.clear()
sessionStorage.clear()
} catch (e) {
console.log(e)
}
})
点击刷新按钮
await page.waitFor(".page-error__refresh-btn") // 可以传 CSS 选择器,也可以传时间(单位毫秒)
await page.click(".page-error__refresh-btn")
在模拟点击刷新按钮之前,需等待按钮渲染完成,再触发按钮点击。(防止刷新页面后,DOM 还未渲染完成的情况下,因找不到 DOM 导致报错)
取消拦截,恢复网络
await page.setRequestInterception(false)
运行脚本及调试
由于第一阶段的测试工具尚未平台化,自动化测试流程先通过在终端输入命令行,运行脚本的方式启动。
在项目的 package.json 文件中,使用 scripts 字段定义脚本命令:
"scripts": {
"test:real": "node ./pages/index/index.js",
"test:mock": "node ./pages/index-mock/index.js"
},
运行:
在终端切入到项目根目录路径,输入以下命令行,就可以启动测试工具,运行测试脚本。
- npm run test:real // 接口真实返回的数据测试
- npm run test:mock // 使用本地 mock 数据测试
调试:
开启调试模式之前,需要先了解 Headless Chrome。
Headless Chrome ,无头模式,浏览器的无界面形态,可以在不打开浏览器的前提下,在命令行中运行测试脚本,能够完全像真实浏览器一样完成用户所有操作,不用担心运行测试脚本时浏览器受到外界的干扰,也不需要借助任何显示设备,使自动化测试更稳定。
Puppeteer 默认以无头模式运行。
那么要开启调试模式,就必须取消无头模式,在打开浏览器的场景下,进行自动化测试。因此,在命令行脚本中增加了“取消无头模式”和“打开开发者工具”的参数,测试脚本通过获取到的参数,决定是否开启调试模式。
const headless = process.argv[2] !== 'head'// 获取是否开启无头模式参数
const devtools = process.argv[3] === 'dev'// 获取是否打开开发者工具参数
const browser = await puppeteer.launch({
executablePath: browserPath,
headless,
devtools
})
在终端切入到项目根目录路径,输入以下命令行,就可以开启调试模式,运行测试脚本。
- npm run test:mock head // 打开 Chromium 窗口
- npm run test:mock head dev // 打开 Chromium 窗口 和 开发者工具窗口
head参数:取消无头模式,打开 Chromium 窗口运行脚本;head dev参数:在打开 Chromium 窗口运行脚本,并打开 Devtools 窗口,开启调试模式。
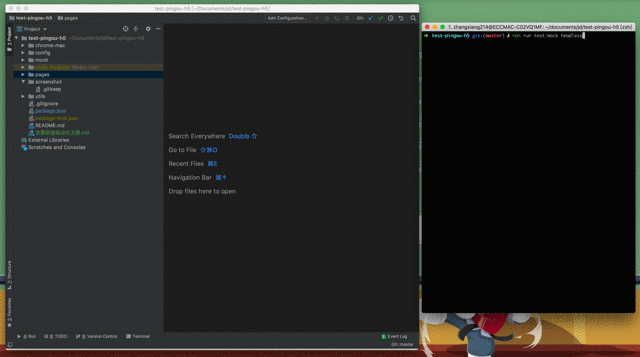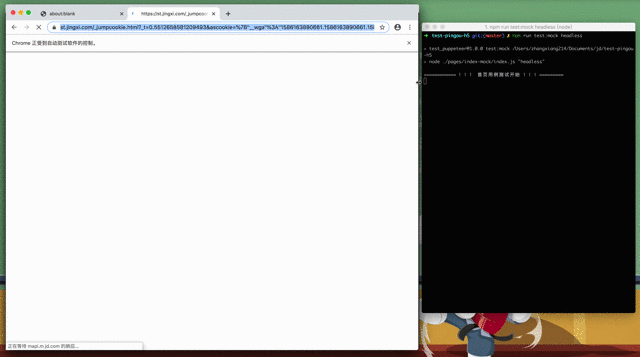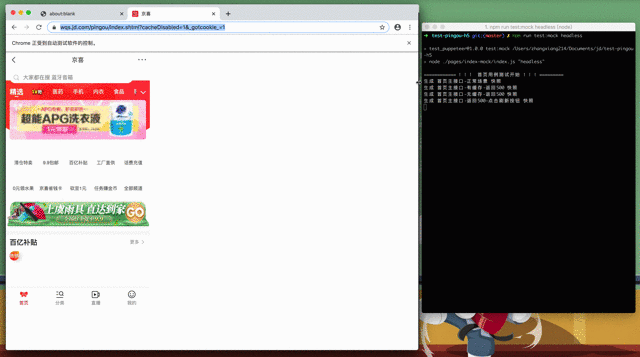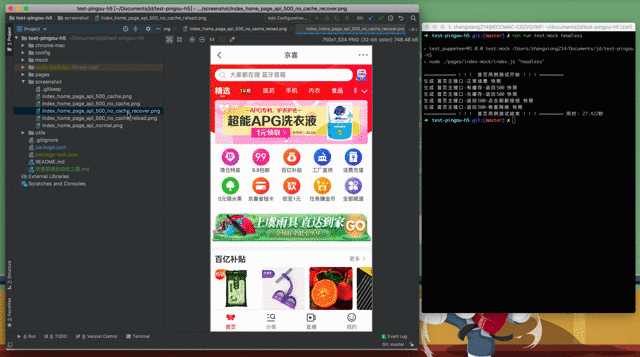
测试结果
人工比对截图结果:
运行脚本示例:
更多测试场景实现—
1. 截取从页面顶部到指定 DOM 之间的区域(内容可能超出一屏的长图)
Puppeteer 提供了四种截图方式:
(1)截取一屏内容(默认普通截屏);
(2)截取指定 DOM;
(3)截取全屏;
(4)指定裁剪区域,可设置 x、y、width、height。x, y 是相对页面左上角。但只能截取一屏的内容,超出一屏不展示。基于第四种方法进行改造:
通过原生 JavaScript 的 getBoundingClientRect() 方法获取到指定 DOM 的 x,y 坐标值; 通过 page.setViewport() 重置视口的高度; 调用截图 API 生成截图。
asyncfunction screenshotToElement (page, selector, path) {
try {
await page.waitForSelector(selector)
let clip = await page.evaluate(selector => {
const element = document.querySelector(selector)
let { x, y, width, height } = element.getBoundingClientRect()
return {
x: 0,
y: 0,
width,
height: M(y),
}
}, selector)
await page.setViewport(clip)
await page.screenshot({
path: path,
clip: clip
})
} catch (e) {
console.log(e)
}
}
height: y:截到指定 DOM 的顶部,不包含该 DOM;height: y + height:截到指定 DOM 的底部,包含该 DOM;原生 Javascript 的 getBoundingClientRect() 方法获取 DOM 元素定位和宽高值可能是小数,而 Puppeteer 的 setViewport() 设置视口方法不支持小数,所以需要对获取到的 DOM 元素定位信息取整。
2. 模拟不同渠道,如:手Q场景:
// 设置 UA
await page.setUserAgent("Mozilla/5.0 (iPhone; CPU iPhone OS 10_2_1 like Mac OS X) AppleWebKit/602.4.6 (KHTML, like Gecko) Mobile/14D27 QQ/6.7.1.416 V1_IPH_SQ_6.7.1_1_APP_A Pixel/750 Core/UIWebView NetType/4G QBWebViewType/1")
3. 滚动页面
await page.evaluate((top) => {
window.scrollTo(0, top)
}, top)
page.evaluate(pageFunction, …args):在当前页面实例上下文中执行 JavaScript 代码
4. 监听页面崩溃事件
// 当页面崩溃时触发
page.on('error', (e) => {
console.log(e)
})
结语—
第一阶段的 H5 自动化之路告一段落,容灾演习已实现了半自动化,可通过在终端运行测试脚本,模拟异常场景自动生成截图,再配合人工比对截图操作,判断演习结果是否符合预期。目前已投入到每个月的容灾演习中使用。
随着京喜业务的迭代,页面也将更新改版,因此测试用例也需要持续维护和更新。后续将持续优化自动化工具,共享测试脚本、在生成截图的基础上自动比对测试结果是否符合预期、数据入库、将测试结果转化成文档,自动发送邮件等等。基于容灾演习的自动化测试,还可扩展广告位的监测,数据上报监听自动化测试……
对于京喜首页自动化测试之路,远没有结束,还有很多可以优化和扩展的地方,接下来分阶段持续优化自动化测试工具,敬请期待!
参考资料
Puppeteer: https://zhaoqize.github.io/puppeteer-api-zh_CN/
[2]Chromium: https://download-chromium.appspot.com/

回复“加群”与大佬们一起交流学习~
点击“阅读原文”查看70+篇原创文章