
拖拽公式图片、一键转换LaTex公式,这款开源公式识别神器比Mathpix Snip更适合你
视学算法报道
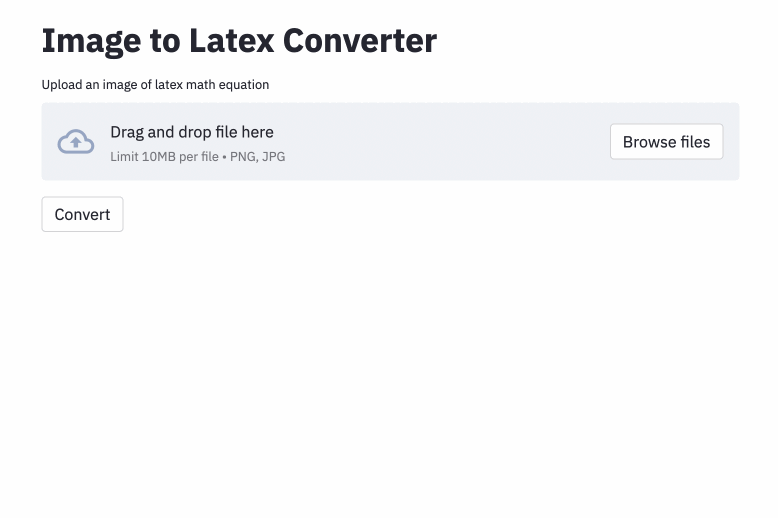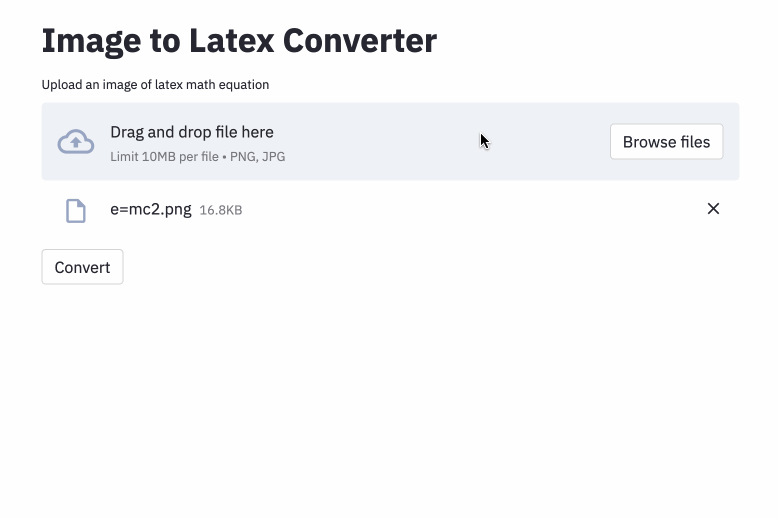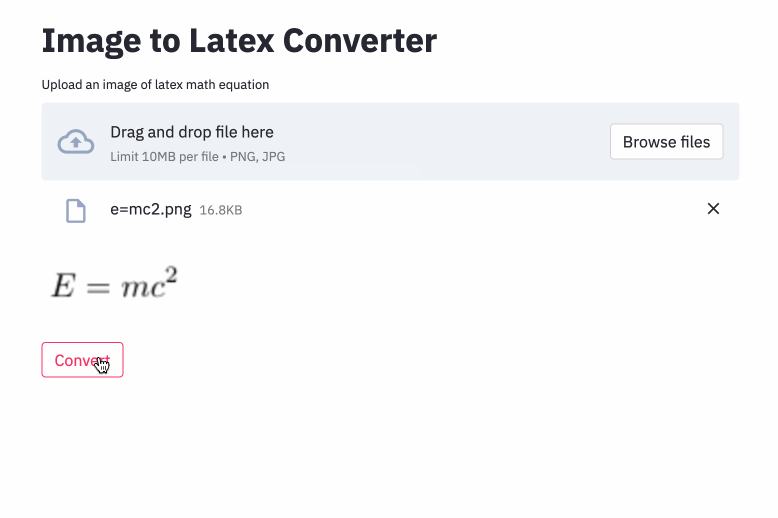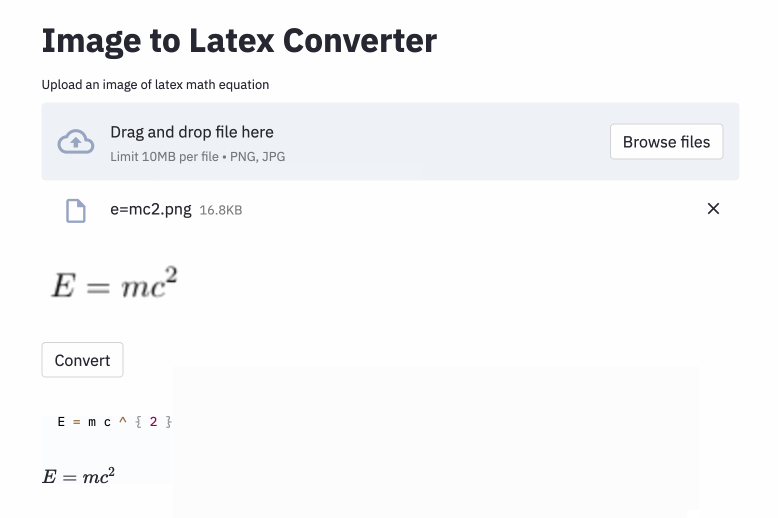
只需要把公式图片用鼠标拖动到工具内,就能一键转成 LaTex 公式。

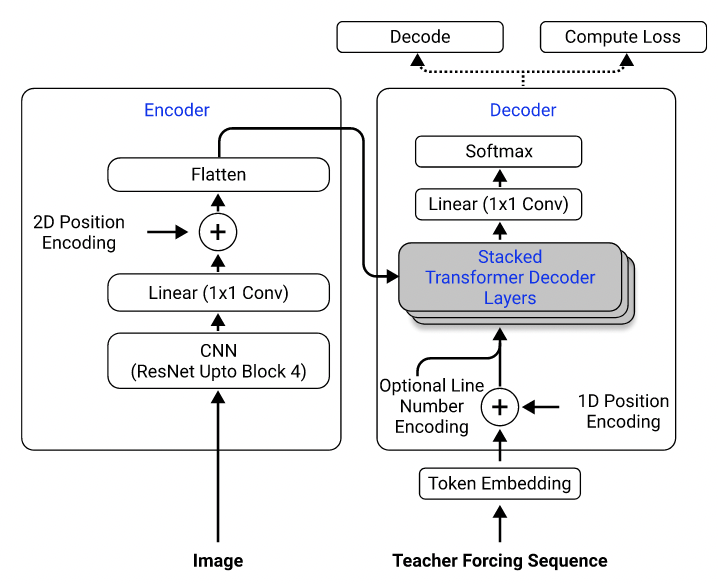
一些 LaTex 代码生成了视觉上相同的输出,比如 \left(和 \ right),看起来与 (和)) 一样,因此做了规范化处理;
一些 LaTex 代码用来添加空间,比如 \ vspace{2px}和 \ hspace{0.3mm})。但是,间距对于人类来说也很难判断。此外,表述相同间距有很多方法,比如 1 cm = 10 mm。最后,作者比希望模型在空白图像上生成代码,因此删除了这些空白图像。
更好地数据清理(比如删除间距命令)
尽可能多地训练模型(由于时间原因,只训练了 15 个 epoch 的模型,但是验证损失依然下降)
使用集束搜索(只实现了贪婪搜索)
使用更大的模型(比如 ResNet-34 而不是 ResNet-18)
进行一些超参数调优
git clone https://github.com/kingyiusuen/image-to-latex.gitcd image-to-latex
make venvmake install-dev
python scripts/prepare_data.pypython scripts/run_experiment.py trainer.gpus=1 data.batch_size=32python scripts/download_checkpoint.py RUN_PATHpython scripts/download_checkpoint.py kingyiusuen/image-to-latex/1w1abmg1isort:对 Python 脚本中的 import 语句进行排序和格式化;
black:遵循 PEP8 的代码格式化程序;
flake8:在 Python 脚本中报告风格问题的代码检查器;
mypy:在 Python 脚本中执行静态类型检查。
make lintmake apimake streamlitmake docker© THE END
转载请联系原公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

点个在看 paper不断!
评论