
Python 爬虫 | feapder 与 Scrapy 横评对比,你会选择哪个?
本篇文章在源码层面比对feapder、scrapy 、scrapy-redis的设计,阅读本文后,会加深您对scrapy以及feapder的了解,以及为什么推荐使用feapder
Scrapy分析
1. 解析函数或数据入库出错,不会重试,会造成一定的数据丢失
scrapy自带的重试中间件只支持请求重试,解析函数内异常或者数据入库异常不会重试,但爬虫在请求数据时,往往会有一些意想不到的页面返回来,若我们解析异常了,这条任务岂不是丢了。
当然有些大佬可以通过一些自定义中间件的方式或者加异常捕获的方式来解决,我们这里只讨论自带的。
2. 运行方式,需借助命令行,不方便调试
若想直接运行,需编写如下文件,麻烦
from scrapy import cmdline
name = 'spider_name'
cmd = 'scrapy crawl {0}'.format(name)
cmdline.execute(cmd.split()
为什么必须通过命令行方式呢?因为scrapy是通过这种方式来加载项目中的settings.py文件的
3. 入库pipeline,不能批量入库
class TestScrapyPipeline(object):
def process_item(self, item, spider):
return item
pipelines里的item是一条条传过来的,没法直接批量入库,但数据量大的时候,我们往往是需要批量入库的,以节省数据库的性能开销,加快入库速度
Scrapy-redis分析
scrapy-redis任务队列使用redis做的,初始任务存在 [spider_name]:start_urls里,爬虫产生的子链接存在[spider_name]:requests下,那么我们先看下redis里的任务
1. redis中的任务可读性不好

我们看下子链任务,可以看到存储的是序列化后的,这种可读性不好
2. 取任务时直接弹出,会造成任务丢失
我们分析下scrapy-redis几种任务队列,取任务时都是直接把任务弹出来,如果任务刚弹出来爬虫就意外退出,那刚弹出的这条任务就会丢失。
FifoQueue(先进先出队列) 使用list集合
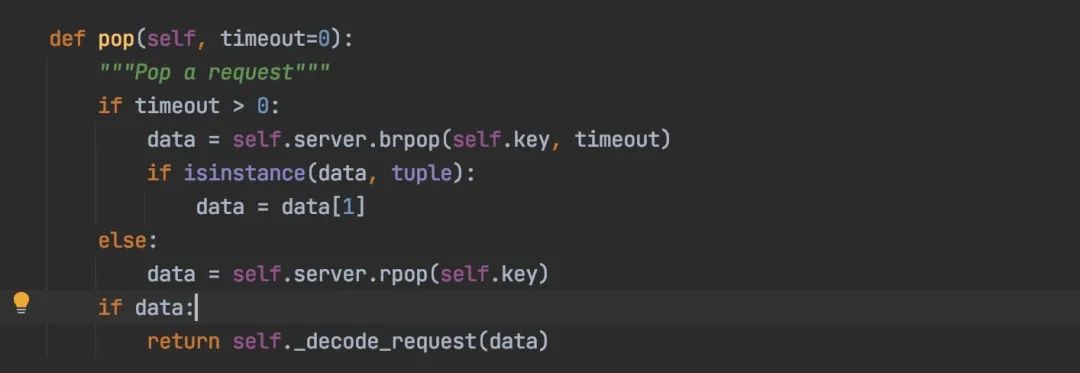
PriorityQueue(优先级队列),使用zset集合
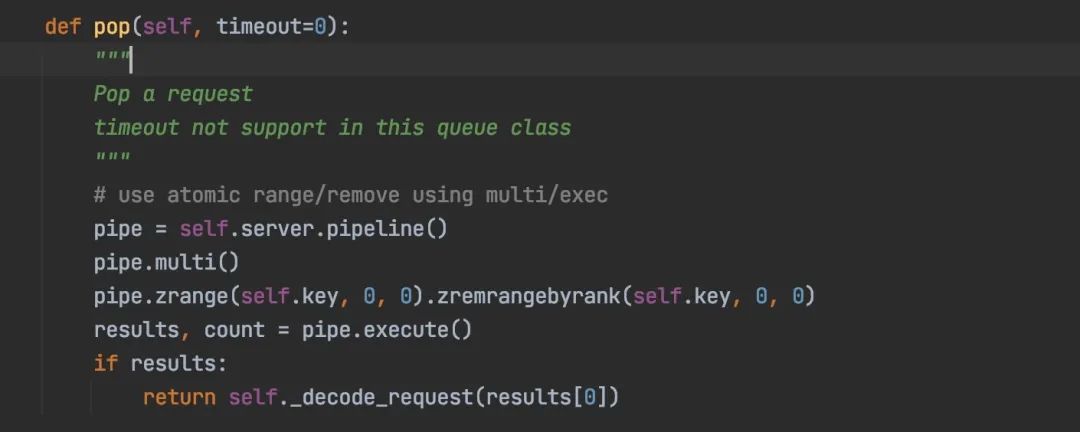
LifoQueue(先进后出队列),使用list集合
scrapy-redis默认使用PriorityQueue队列,即优先级队列
3. 去重耗内存
使用redis的set集合对request指纹进行去重,这种面对海量数据去重对redis内存容量要求很高
4. 需单独维护个下发种子任务的脚本
feapder分析
feapder内置 AirSpider、Spider、BatchSpider三种爬虫,AirSpider对标Scrapy,Spider对标scrapy-redis,BatchSpider则是应于周期性采集的需求,如每周采集一次商品的销量等场景
上述问题解决方案
1. 解析函数或数据入库出错,不会重试,会造成一定的数据丢失
feapder对请求、解析、入库进行了全面的异常捕获,任何位置出现异常会自动重试请求,若有不想重试的请求也可指定
2. 运行方式,需借助命令行,不方便调试
feapder支持直接运行,跟普通的python脚本没区别,可以借助pycharm调试。
除了断点调试,feapder还支持将爬虫转为Debug爬虫,Debug爬虫模式下,可指定请求与解析函数,生产的任务与数据不会污染正常环境
3. 入库pipeline,不能批量入库
feapder 生产的数据会暂存内存的队列里,积攒一定量级或每0.5秒批量传给pipeline,方便批量入库
def save_items(self, table, items: List[Dict]) -> bool:
pass
这里有人会有疑问
数据放到内存里了,会不会造成拥堵?
答:不会,这里限制了最高能积攒5000条的上限,若到达上限后,爬虫线程会强制将数据入库,然后再生产数据
若爬虫意外退出,数据会不会丢?
答:不会,任务会在数据入库后再删除,若意外退出了,产生这些数据的任务会重做
入库失败了怎么办?
答:入库失败,任务会重试,数据会重新入库,若失败次数到达配置的上限会报警
4. redis中的任务可读性不好
feapder对请求里常用的字段没有序列化,只有那些json不支持的对象才进行序列化

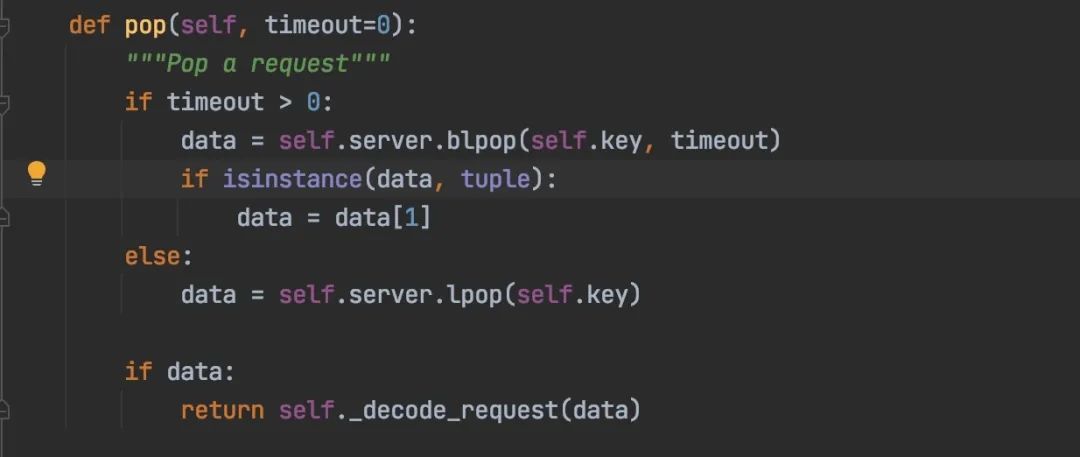
5. 取任务时直接弹出,会造成任务丢失
feapder在获取任务时,没直接弹出,任务采用redis的zset集合存储,每次只取小于当前时间搓分数的任务,同时将取到的任务分数修改为当前时间搓+10分钟,防止其他爬虫取到重复的任务。若爬虫意外退出,这些取到的任务其实还在任务队列里,并没有丢失
6. 去重耗内存
feapder支持三种去重方式
内存去重:采用可扩展的bloomfilter结构,基于内存,去重一万条数据约0.5秒,一亿条数据占用内存约285MB 临时去重:采用redis的zset集合存储数据的md5值,去重可指定时效性。去重一万条数据约0.26秒,一亿条数据占用内存约1.43G 永久去重:采用可扩展的bloomfilter结构,基于redis,去重一万条数据约0.5秒,一亿条数据占用内存约285MB
7. 分布式爬虫需单独维护个下发种子任务的脚本
feapder没种子任务和子链接的分别,yield feapder.Request都会把请求下发到任务队列,我们可以在start_requests编写下发种子任务的逻辑
这里又有人会有疑问了
我爬虫启动多份时,
start_requests不会重复调用,重复下发种子任务么?答:不会,分布式爬虫在调用
start_requests时,会加进程锁,保证只能有一个爬虫调用这个函数。并且若任务队列中有任务时,爬虫会走断点续爬的逻辑,不会执行start_requests那支持手动下发任务么
答:支持,按照feapder的任务格式,往redis里扔任务就好,爬虫支持常驻等待任务
三种爬虫简介
1. AirSpider
使用PriorityQueue作为内存任务队列,不支持分布式,示例代码
import feapder
class AirSpiderDemo(feapder.AirSpider):
def start_requests(self):
yield feapder.Request("https://www.baidu.com")
def parse(self, request, response):
print(response)
if __name__ == "__main__":
AirSpiderDemo().start()
2. Spider
分布式爬虫,支持启多份,爬虫意外终止,重启后会断点续爬
import feapder
class SpiderDemo(feapder.Spider):
# 自定义数据库,若项目中有setting.py文件,此自定义可删除
__custom_setting__ = dict(
REDISDB_IP_PORTS="localhost:6379", REDISDB_USER_PASS="", REDISDB_DB=0
)
def start_requests(self):
yield feapder.Request("https://www.baidu.com")
def parse(self, request, response):
print(response)
if __name__ == "__main__":
SpiderDemo(redis_key="xxx:xxx").start()
3. BatchSpider
批次爬虫,拥有分布式爬虫所有特性,支持分布式
import feapder
class BatchSpiderDemo(feapder.BatchSpider):
# 自定义数据库,若项目中有setting.py文件,此自定义可删除
__custom_setting__ = dict(
REDISDB_IP_PORTS="localhost:6379",
REDISDB_USER_PASS="",
REDISDB_DB=0,
MYSQL_IP="localhost",
MYSQL_PORT=3306,
MYSQL_DB="feapder",
MYSQL_USER_NAME="feapder",
MYSQL_USER_PASS="feapder123",
)
def start_requests(self, task):
yield feapder.Request("https://www.baidu.com")
def parse(self, request, response):
print(response)
if __name__ == "__main__":
spider = BatchSpiderDemo(
redis_key="xxx:xxxx", # redis中存放任务等信息的根key
task_table="", # mysql中的任务表
task_keys=["id", "xxx"], # 需要获取任务表里的字段名,可添加多个
task_state="state", # mysql中任务状态字段
batch_record_table="xxx_batch_record", # mysql中的批次记录表
batch_name="xxx", # 批次名字
batch_interval=7, # 批次周期 天为单位 若为小时 可写 1 / 24
)
# spider.start_monitor_task() # 下发及监控任务
spider.start() # 采集
任务调度过程:
从mysql中批量取出一批种子任务 下发到爬虫 爬虫获取到种子任务后,调度到start_requests,拼接实际的请求,下发到redis 爬虫从redis中获取到任务,调用解析函数解析数据 子链接入redis,数据入库 种子任务完成,更新种子任务状态 若redis中任务量过少,则继续从mysql中批量取出一批未做的种子任务下发到爬虫
封装了批次(周期)采集的逻辑,如我们指定7天一个批次,那么如果爬虫3天就将任务做完,爬虫重启也不会重复采集,而是等到第7天之后启动的时候才会采集下一批次。
同时批次爬虫会预估采集速度,若按照当前速度在指定的时间内采集不完,会发出报警
feapder项目结构
上述的三种爬虫例子修改配置后可以直接运行,但对于大型项目,可能会有就好多爬虫组成。feapder支持创建项目,项目结构如下:
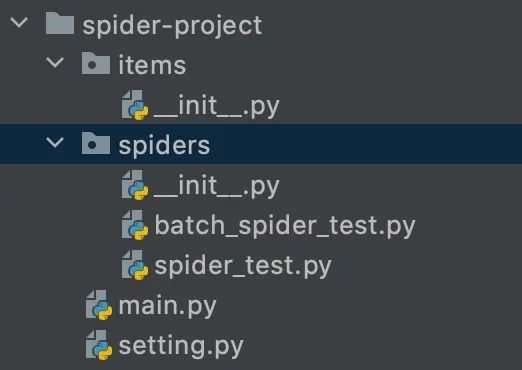
main.py 为启动入口
feapder部署
feapder有对应的管理平台feaplat,当然这个管理平台也支持部署其他脚本
在任务列表里配置启动命令,调度周期以及爬虫数等。爬虫数这个对于分布式爬虫是非常爽的,可一键启动几十上百份爬虫,再也不需要一个个部署了
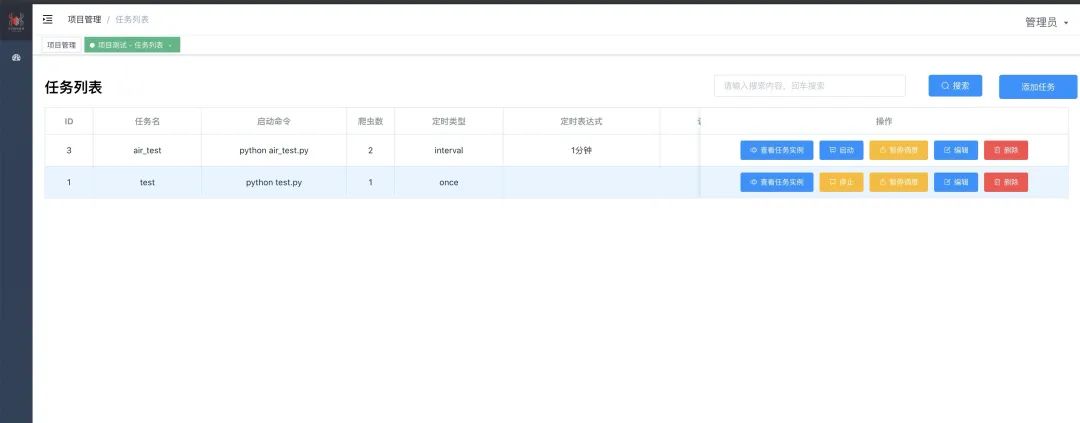
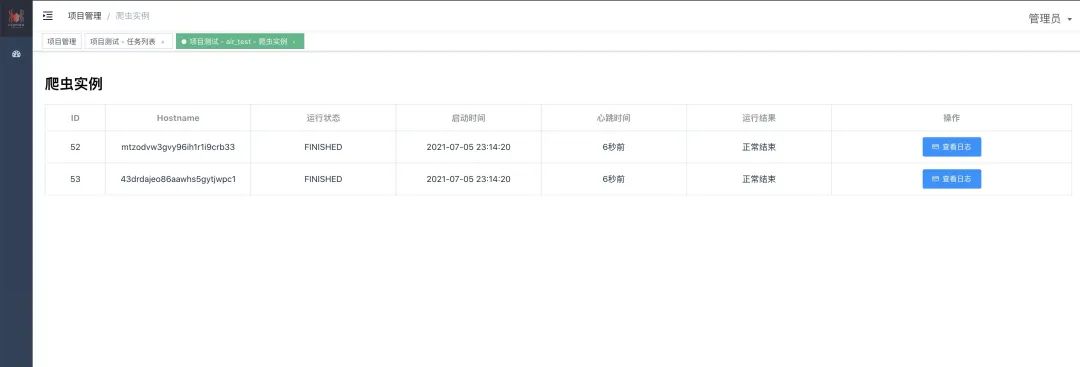
-w1791 任务启动后,可看到实例及实时日志
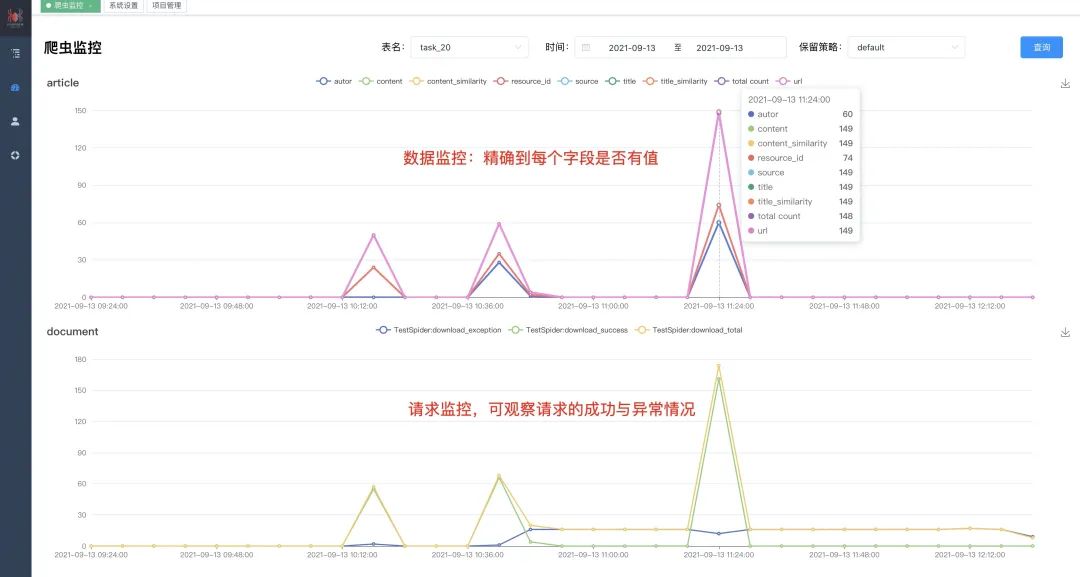
-w1785 爬虫监控面板可实时看到爬虫运行情况,监控数据保留半年,滚动删除
采集效率测试
请求百度1万次,线程都开到300,测试耗时
scrapy:
class BaiduSpider(scrapy.Spider):
name = 'baidu'
allowed_domains = ['baidu.com']
start_urls = ['https://baidu.com/'] * 10000
def parse(self, response):
print(response)
结果
{'downloader/request_bytes': 4668123,
'downloader/request_count': 20002,
'downloader/request_method_count/GET': 20002,
'downloader/response_bytes': 17766922,
'downloader/response_count': 20002,
'downloader/response_status_count/200': 10000,
'downloader/response_status_count/302': 10002,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2021, 9, 13, 12, 22, 26, 638611),
'log_count/DEBUG': 20003,
'log_count/INFO': 9,
'memusage/max': 74240000,
'memusage/startup': 58974208,
'response_received_count': 10000,
'scheduler/dequeued': 20002,
'scheduler/dequeued/memory': 20002,
'scheduler/enqueued': 20002,
'scheduler/enqueued/memory': 20002,
'start_time': datetime.datetime(2021, 9, 13, 12, 19, 58, 489472)}
耗时:148.149139秒
feapder:
import feapder
import time
class AirSpiderDemo(feapder.AirSpider):
def start_requests(self):
for i in range(10000):
yield feapder.Request("https://www.baidu.com")
def parse(self, request, response):
print(response)
def start_callback(self):
self.start_time = time.time()
def end_callback(self):
print("耗时:{}".format(time.time() - self.start_time))
if __name__ == "__main__":
AirSpiderDemo(thread_count=300).start()
结果:耗时:136.10122799873352
总结
本文主要分析了scrapy及scrapy-redis的痛点以及feapder是如何解决的,当然scrapy也有优点,比如社区活跃、中间件灵活等。但在保证数据及任务不丢的场景,报警监控等场景feapder完胜scrapy。并且feapder是基于实际业务,做过大大小小100多个项目,耗时5年打磨出来的,因此可满足绝大多数爬虫需求
效率方面,请求百度1万次,同为300线程的情况下,feapder耗时136秒,scrapy耗时148秒,算上网络的波动,其实效率差不多。
feapder爬虫文档:https://boris-code.gitee.io/feapder/#/

feaplat管理平台:https://boris-code.gitee.io/feapder/#/feapder_platform/%E7%88%AC%E8%99%AB%E7%AE%A1%E7%90%86%E7%B3%BB%E7%BB%9F
爬虫管理系统不仅支持
feapder、scrapy,且支持执行任何脚本,可以把该系统理解成脚本托管的平台 。支持集群
工作节点根据配置定时启动,执行完释放,不常驻
一个worker内只运行一个爬虫,worker彼此之间隔离,互不影响。
支持管理员和普通用户两种角色
可自定义爬虫端镜像