
HTTP 传输大文件的几种方案
在 JavaScript 中如何实现大文件并发上传? 和 JavaScript 中如何实现大文件并行下载? 这两篇文章中,阿宝哥介绍了如何利用 async-pool 这个库来优化传输大文件的功能。本文阿宝哥将为大家介绍一下 HTTP 传输大文件的几种方案。不过在介绍具体的方案之前,我们先使用 Node.js 的 fs 模块来生成一个 “大” 文件。
const fs = require("fs");
const writeStream = fs.createWriteStream(__dirname + "/big-file.txt");
for (let i = 0; i <= 1e5; i++) {
writeStream.write(`${i} 我是阿宝哥,欢迎关注全栈修仙之路\n`, "utf8");
}
writeStream.end();
以上代码成功运行后,在当前的执行目录下将会生成一个大小为 5.5 MB 的文本文件,该文件将作为以下方案的 “素材”。准备工作完成之后,我们先来介绍第一种方案 —— 数据压缩。
一、数据压缩
当使用 HTTP 进行大文件传输时,我们可以考虑对大文件进行压缩。通常浏览器在发送请求时,都会携带 accept 和 accept-* 请求头信息,用于告诉服务器当前浏览器所支持的文件类型、支持的压缩格式列表和支持的语言。
accept: */*
accept-encoding: gzip, deflate, br
accept-language: zh-CN,zh;q=0.9
gzip 的压缩率通常能够超过 60%,而 br 算法是专门为 HTML 设计的,压缩效率和性能比 gzip 还要好,能够再提高 20% 的压缩密度。
上述 HTTP 请求头中的 Accept-Encoding 字段,用于将客户端能够理解的内容编码方式(通常是某种压缩算法)告诉给服务端。通过内容协商的方式,服务端会选择一个客户端所支持的方式,并通过响应头 Content-Encoding 来通知客户端该选择。
cache-control: max-age=2592000
content-encoding: gzip
content-type: application/x-javascript
以上的响应头告诉浏览器返回的 JS 脚本,是经过 gzip 压缩算法处理过的。不过需要注意的是,gzip 等压缩算法通常只对文本文件有较好的压缩率,而图片、音视频等多媒体文件数据本身就已经是高度压缩的,再用 gzip 进行压缩也不会有好的压缩效果,甚至还可能会出现变大的情况。
了解完 Accept-Encoding 和 Content-Encoding 字段,我们来验证一下未开启 gzip 和开启 gzip 的效果。
1.1 未开启 gzip
const fs = require("fs");
const http = require("http");
const util = require("util");
const readFile = util.promisify(fs.readFile);
const server = http.createServer(async (req, res) => {
res.writeHead(200, {
"Content-Type": "text/plain;charset=utf-8",
});
const buffer = await readFile(__dirname + "/big-file.txt");
res.write(buffer);
res.end();
});
server.listen(3000, () => {
console.log("app starting at port 3000");
});
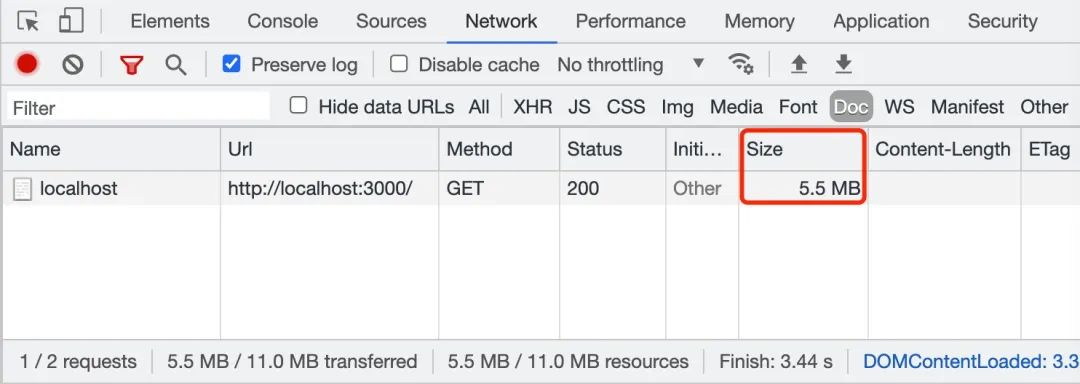
1.2 开启 gzip
const fs = require("fs");
const zlib = require("zlib");
const http = require("http");
const util = require("util");
const readFile = util.promisify(fs.readFile);
const gzip = util.promisify(zlib.gzip);
const server = http.createServer(async (req, res) => {
res.writeHead(200, {
"Content-Type": "text/plain;charset=utf-8",
"Content-Encoding": "gzip"
});
const buffer = await readFile(__dirname + "/big-file.txt");
const gzipData = await gzip(buffer);
res.write(gzipData);
res.end();
});
server.listen(3000, () => {
console.log("app starting at port 3000");
});
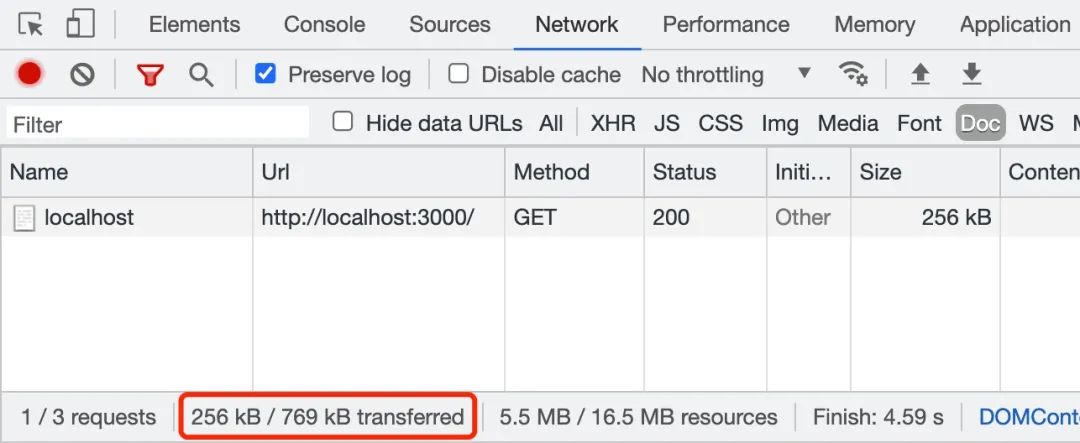
观察上面两张图,我们可以直观感受到当传输 5.5 MB 的 big-file.txt 文件时,若开启 gzip 压缩后,文件被压缩成 256 kB。这样就大大加快了文件的传输。在实际工作场景中,我们可以使用 nginx 或 koa-static 来开启 gzip 压缩功能。接下来,我们来介绍另一个方案 —— 分块传输编码。
二、分块传输编码
分块传输编码主要应用于如下场景,即要传输大量的数据,但是在请求在没有被处理完之前响应的长度是无法获得的。例如,当需要用从数据库中查询获得的数据生成一个大的 HTML 表格的时候,或者需要传输大量的图片的时候。
要使用分块传输编码,则需要在响应头配置 Transfer-Encoding 字段,并设置它的值为 chunked 或 gzip, chunked:
Transfer-Encoding: chunked
Transfer-Encoding: gzip, chunked
响应头 Transfer-Encoding 字段的值为 chunked,表示数据以一系列分块的形式进行发送。需要注意的是 Transfer-Encoding 和 Content-Length 这两个字段是互斥的,也就是说响应报文中这两个字段不能同时出现。下面我们来看一下分块传输的编码规则:
每个分块包含分块长度和数据块两个部分; 分块长度使用 16 进制数字表示,以 \r\n结尾;数据块紧跟在分块长度后面,也使用 \r\n结尾,但数据不包含\r\n;终止块是一个常规的分块,表示块的结束。不同之处在于其长度为 0,即 0\r\n\r\n。
了解完分块传输编码的相关知识后,阿宝哥将使用 big-file.txt 文件的前 100 行数据来演示分块传输编码是如何实现的。
2.1 数据分块
const buffer = fs.readFileSync(__dirname + "/big-file.txt");
const lines = buffer.toString("utf-8").split("\n");
const chunks = chunk(lines, 10);
function chunk(arr, len) {
let chunks = [],
i = 0,
n = arr.length;
while (i < n) {
chunks.push(arr.slice(i, (i += len)));
}
return chunks;
}
2.2 分块传输
// http-chunk-server.js
const fs = require("fs");
const http = require("http");
// 省略数据分块代码
http
.createServer(async function (req, res) {
res.writeHead(200, {
"Content-Type": "text/plain;charset=utf-8",
"Transfer-Encoding": "chunked",
"Access-Control-Allow-Origin": "*",
});
for (let index = 0; index < chunks.length; index++) {
setTimeout(() => {
let content = chunks[index].join("&");
res.write(`${content.length.toString(16)}\r\n${content}\r\n`);
}, index * 1000);
}
setTimeout(() => {
res.end();
}, chunks.length * 1000);
})
.listen(3000, () => {
console.log("app starting at port 3000");
});
使用 node http-chunk-server.js 命令启动服务器之后,在浏览中访问 http://localhost:3000/ 地址,你将看到以下输出结果:

上图是第 1 个数据块返回的内容,当所有数据块都传输完成之后,服务器会返回终止块,即向客户端发送 0\r\n\r\n。此外,对于返回的分块数据,我们也可以利用 fetch API 中的响应对象,以流的形式来读取已返回的数据块,即通过 response.body.getReader() 来创建读取器,然后调用 reader.read() 方法来读取数据。
2.3 流式传输
其实当使用 Node.js 向客户端返回大文件时,我们最好使用流的形式来返回文件流,这样能避免处理大文件时,占用过多的内存。具体实现方式如下所示:
const fs = require("fs");
const zlib = require("zlib");
const http = require("http");
http
.createServer((req, res) => {
res.writeHead(200, {
"Content-Type": "text/plain;charset=utf-8",
"Content-Encoding": "gzip",
});
fs.createReadStream(__dirname + "/big-file.txt")
.setEncoding("utf-8")
.pipe(zlib.createGzip())
.pipe(res);
})
.listen(3000, () => {
console.log("app starting at port 3000");
});
当使用流的形式来返回文件数据时,HTTP 响应头 Transfer-Encoding 字段的值为 chunked,表示数据以一系列分块的形式进行发送。
Connection: keep-alive
Content-Encoding: gzip
Content-Type: text/plain;charset=utf-8
Date: Sun, 06 Jun 2021 01:02:09 GMT
Transfer-Encoding: chunked
如果你对 Node.js Stream 感兴趣的话,可以阅读阿宝哥 Github 上 semlinker/node-deep —— 深入学习 Node.js Stream 基础篇 这篇文章。
项目地址:https://github.com/semlinker/node-deep
三、范围请求
HTTP 协议范围请求允许服务器只发送 HTTP 消息的一部分到客户端。范围请求在传送大的媒体文件,或者与文件下载的断点续传功能搭配使用时非常有用。如果在响应中存在 Accept-Ranges 首部(并且它的值不为 “none”),那么表示该服务器支持范围请求。
在一个 Range 首部中,可以一次性请求多个部分,服务器会以 multipart 文件的形式将其返回。如果服务器返回的是范围响应,需要使用 206 Partial Content 状态码。假如所请求的范围不合法,那么服务器会返回 416 Range Not Satisfiable 状态码,表示客户端错误。服务器允许忽略 Range 首部,从而返回整个文件,状态码用 200 。
3.1 Range 语法
Range: <unit>=<range-start>-
Range: <unit>=<range-start>-<range-end>
Range: <unit>=<range-start>-<range-end>, <range-start>-<range-end>
Range: <unit>=<range-start>-<range-end>, <range-start>-<range-end>, <range-start>-<range-end>
unit:范围请求所采用的单位,通常是字节(bytes)。<range-start>:一个整数,表示在特定单位下,范围的起始值。<range-end>:一个整数,表示在特定单位下,范围的结束值。这个值是可选的,如果不存在,表示此范围一直延伸到文档结束。
了解完 Range 语法之后,我们来看一下实际的使用示例:
3.1.1 单一范围
$ curl http://i.imgur.com/z4d4kWk.jpg -i -H "Range: bytes=0-1023"
3.1.2 多重范围
$ curl http://www.example.com -i -H "Range: bytes=0-50, 100-150"
3.2 Range 请求示例
3.2.1 服务端代码
// http/range/koa-range-server.js
const Koa = require("koa");
const cors = require("@koa/cors");
const serve = require("koa-static");
const range = require('koa-range');
const app = new Koa();
// 注册中间件
app.use(cors()); // 注册CORS中间件
app.use(range); // 注册范围请求中间件
app.use(serve(".")); // 注册静态资源中间件
app.listen(3000, () => {
console.log("app starting at port 3000");
});
3.2.2 客户端代码
<!DOCTYPE html>
<html lang="zh-cn">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>大文件范围请求示例(阿宝哥)</title>
</head>
<body>
<h3>大文件范围请求示例(阿宝哥)</h3>
<div id="msgList"></div>
<script>
const msgList = document.querySelector("#msgList");
function getBinaryContent(url, start, end, responseType = "arraybuffer") {
return new Promise((resolve, reject) => {
try {
let xhr = new XMLHttpRequest();
xhr.open("GET", url, true);
xhr.setRequestHeader("range", `bytes=${start}-${end}`);
xhr.responseType = responseType;
xhr.onload = function () {
resolve(xhr.response);
};
xhr.send();
} catch (err) {
reject(new Error(err));
}
});
}
getBinaryContent(
"http://localhost:3000/big-file.txt",
0, 100, "text"
).then((text) => {
msgList.append(`${text}`);
});
</script>
</body>
</html>
使用 node koa-range-server.js 命令启动服务器之后,在浏览中访问 http://localhost:3000/index.html 地址,你将看到以下输出结果:

该示例对应的 HTTP 请求头和响应头(只包含部分头部信息)分别如下所示:
3.2.3 HTTP 请求头
GET /big-file.txt HTTP/1.1
Host: localhost:3000
Connection: keep-alive
Referer: http://localhost:3000/index.html
Accept-Encoding: identity
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,id;q=0.7
Range: bytes=0-100
3.2.4 HTTP 响应头
HTTP/1.1 206 Partial Content
Vary: Origin
Accept-Ranges: bytes
Last-Modified: Sun, 06 Jun 2021 01:40:19 GMT
Cache-Control: max-age=0
Content-Type: text/plain; charset=utf-8
Date: Sun, 06 Jun 2021 03:01:01 GMT
Connection: keep-alive
Content-Range: bytes 0-100/5243
Content-Length: 101
关于范围请求的相关内容就介绍到这里,想了解它在实际工作中的应用,可以继续阅读 JavaScript 中如何实现大文件并行下载? 这篇文章。
四、总结
本文阿宝哥介绍了 HTTP 传输大文件的 3 种方案,希望了解完这些知识后,对大家今后的工作能有一些帮助。在实际使用中,大家要注意 Transfer-Encoding 和 Content-Encoding 之间的区别。Transfer-Encoding 在传输后会被自动解码还原出原始数据,而 Content-Encoding 则必须由应用自行解码。
五、参考资源
透视 HTTP 协议 MDN - HTTP 请求范围 MDN - Accept-Encoding