
工业对象数据建模的四个灵魂之问
在生产过程中,为了更好地控制工艺过程和产品质量,往往需要利用生产数据,对设备、产品和工艺工程进行建模。当我阅读相关论文时,感觉多数作者对工业过程数据建模的理解不深。我这里谈四个基本的常识性问题。
1、为什么要为工业对象模型?
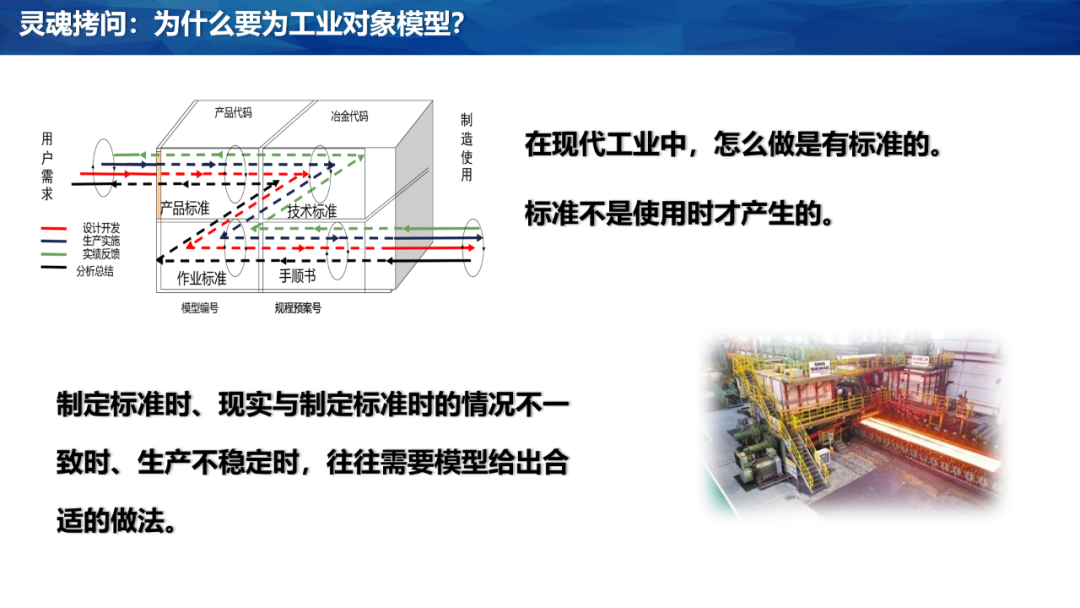
很多人知道,模型往往是用来计算系统输入的,是用来解决“怎么做”的问题。
现实中,没有模型的时候,人们也知道“怎么做”。在现代化企业中,会把“怎么做”固化成标准。这些标准包括了很多层级。在每个层级,都包含目标和做法。上一层的输入就是下一层的输出。既然如此,为什么还需要模型?
模型的用途有两个:一个是为了制定标准,一个是应对应对变化。
我们知道,生产系统的参数会不断变化,部分标准需要经常性地修订。另外,生产过程中会有各种干扰。干扰导致标准的输入无法达到标准的输出。这时候就需要模型动态计算输入,以便让输出符合要求。
2、有了科学知识,为什么还要建模?

很多人认为,建模的前提是没有模型,尤其是没有理论模型。其实,在冶金、化工、机械、航空等领域,都有着相当成熟的科学理论基础和数学模型。那么,为什么还要建模呢?
现实的问题是:理论模型需要很多参数和实时数据。现实中,实时数据和参数缺失、不准确;系统越是复杂,这类问题越是严重。理论模型虽然正确,如果没有这些参数,就无法满足工业企业的需要。这时候,需要用现实的数据建模,才能满足工业的需要。
从某种意义上说,工业数据建模得到的模型“并不正确”,但是有用。
3、工业企业,到底需要什么样的模型?

很多人认为,只要模型的精度高就可以了。但其实,这里存在一个误区:什么叫模型精度高?平均精度高吗? 现实中,人们对模型的稳定性有很高的要求,往往是建模的难点。所谓稳定,就是要避免下面的情况:
今天模型精度高,明天模型精度低
正常工况精度高,异常工况精度低
有些场景精度高,有些场景精度低
4、工业对象的数据建模,难在什么地方?

多人认为难在算法上。
在笔者看来,本质问题是数据质量的问题。数据质量高,建模往往不难;数据质量低,神仙都没有办法。数据建模的重点工作,往往是设法提高数据质量。
数据量大不等于数据质量高。但数据量大有利于提高数据质量。工业大数据时代的意义,就在于此。
(欢迎大家加入数据工匠知识星球获取更多资讯。)

扫描二维码关注我们

我们的使命:发展数据治理行业、普及数据治理知识、改变企业数据管理现状、提高企业数据质量、推动企业走进大数据时代。
我们的愿景:打造数据治理专家、数据治理平台、数据治理生态圈。
我们的价值观:凝聚行业力量、打造数据治理全链条平台、改变数据治理生态圈。
了解更多精彩内容
长按,识别二维码,关注我们吧!
数据工匠俱乐部
微信号:zgsjgjjlb
专注数据治理,推动大数据发展。