有哪些你看了之后大呼过瘾的数据分析方法论(万字长文)?
01
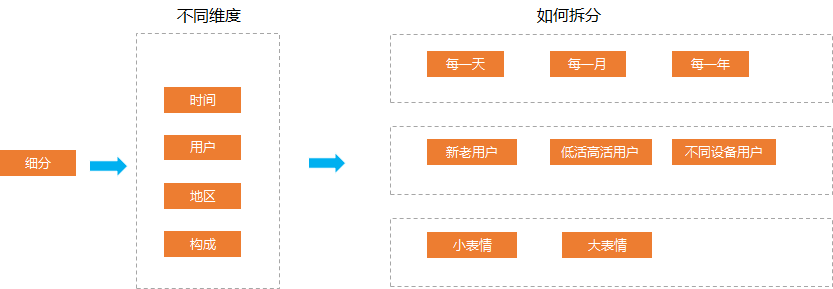
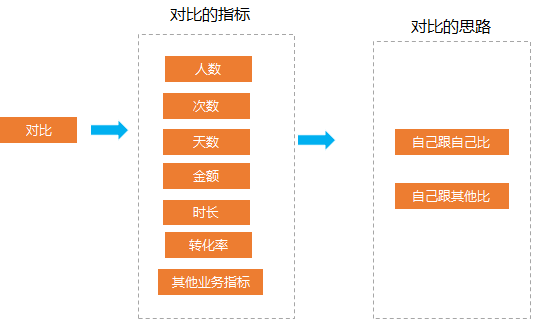
02
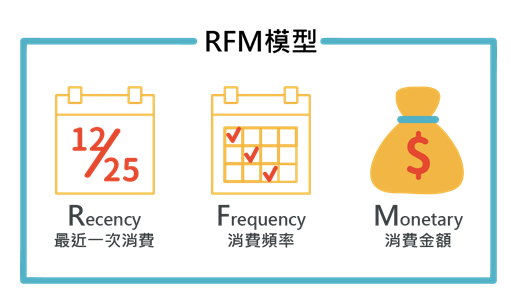
RFM 模型是利用 R, F, M 三个特征去对用户进行划分的。
其中R是表示最后一次付费的日期距离现在的时间, 比如你在 12月20号给一个主播打赏过, 那么到现在的距离的天数是5 那么R就是5, R是用来刻画用户的忠诚度, 一般来说R越小, 代表用户上一次刚刚才付费的, 这种用户的忠诚度比较高。
F是表示一段时间的付费频次, 也就是比如一个月付费了多少次, 这个是用来刻画用户付费行为的活跃度, 我们认为用户的付费行为频次越高, 一定程度上代表他的价值度
M是表示一段时间的付费金额, 比如一个月付费了10000元, M=10000, M主要是用来刻画用户的土豪程度。
以上我们就从用户的忠诚度, 活跃度, 土豪度三个方面去刻画一个用户的价值度。
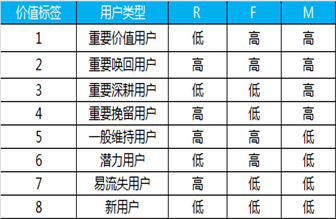
根据RFM的值, 我们就可以把用户划分为以下不同的类别:
重要价值用户: R 低, F 高, M 高, 这种用户价值度非常高, 因为忠诚度高, 付费频次高, 又很土豪
重要召回用户: R 低, F 低 M 高, 因为付费频次低, 但金额高, 所以是重点召回用户
重要发展用户: R 高, F 低, M 高 因为忠诚度不够, 所以需要大力发展
重要挽留用户: R 高 F 低 M高 因为 忠诚度和活跃度都不够 很容易流失 所以需要重点挽留
还有四种其他用户就不一一列举
RFM如何分群:
1.首先是利用sql 计算 每一个用户的 R, F, M, 最终得到的数据格式如下
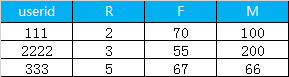
2. 读取数据和查看数据
pay_data= pd.read_csv('d:/My Documents/Desktop/train_pay.csv')# 路径名 'd:/My Documents/Desktop/train_pay.csv' 填写你自己的即可pay_data.head() # 查看数据前面几行
3. 选取我们要聚类的特征
pay_RFM = pay_data[['r_c','f_c','m_c']]4. 开始聚类, 因为我们用户分群分的是八个类别, 所以k =8
# 创建模型model_k = KMeans(n_clusters=8,random_state=1)# 模型训练model_k.fit(pay_RFM)# 聚类出来的类别赋值给新的变量 cluster_labelscluster_labels = model_k.labels_
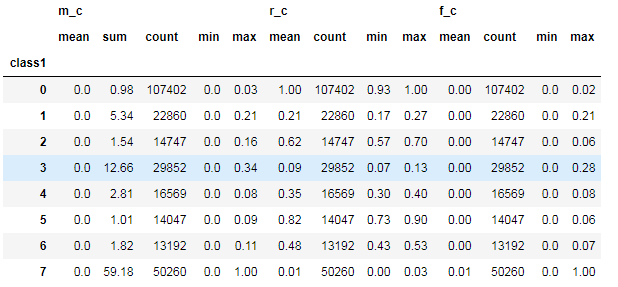
5. 对聚类的结果中每一个类别计算 每个类别的数量 最小值 最大值 平均值等指标
rfm_kmeans = pay_RFM.assign(class1=cluster_labels)num_agg = {'r_c':['mean', 'count','min','max'], 'f_c':['mean', 'count','min','max'],'m_c':['mean','sum','count','min','max']}rfm_kmeans.groupby('class1').agg(num_agg).round(2)
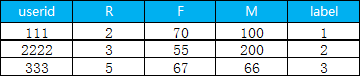
6. 把聚类出来的类别和用户id 拼接在一起
pay_data.assign(class1=cluster_labels).to_csv('d:/My Documents/Desktop/result.csv',header=True, sep=',')下面就是最终结果, label 表示用户是属于哪一个细分的类别
03
生命周期模型
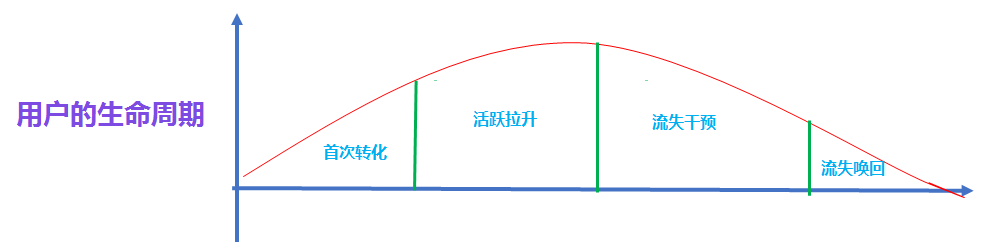
分位数法:
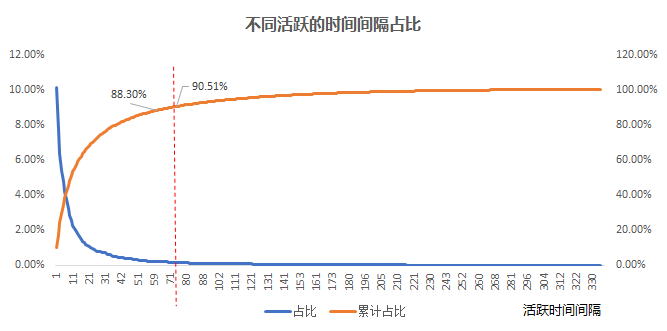
首先先计算用户活跃的时间间隔, 比如用户a 活跃的时间日期分别是 2020-12-01 和 2020-12-14 那么间隔就是13天, 我们把所有用户的活跃的时间间隔都计算好, 然后找出间隔的 90% 分位数.
为什么是90% 分位数呢?这是因为如果有90% 的活跃时间间隔都在某个周期以内的话, 那么这个周期内不活跃的话, 之后活跃的可能性也不高。
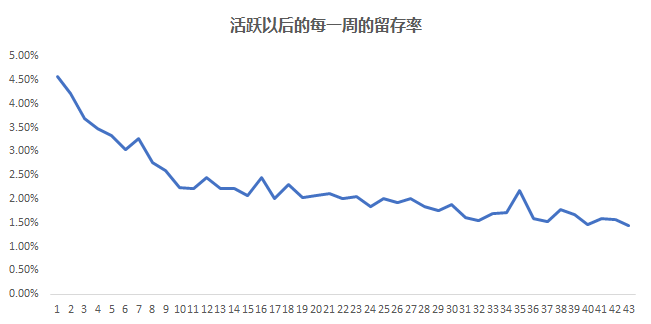
在数据分析的问题中, 经常会遇见的一种问题就是相关的问题, 比如抖音短视频的产品经理经常要来问留存(是否留下来)和观看时长, 收藏的次数, 转发的次数, 关注的抖音博主数等等是否有相关性, 相关性有多大。
因为只有知道了哪些因素和留存比较相关, 才知道怎么去优化从产品的方向去提升留存率, 比如 如果留存和收藏的相关性比较大 那么我们就要引导用户去收藏视频, 从而提升相关的指标,
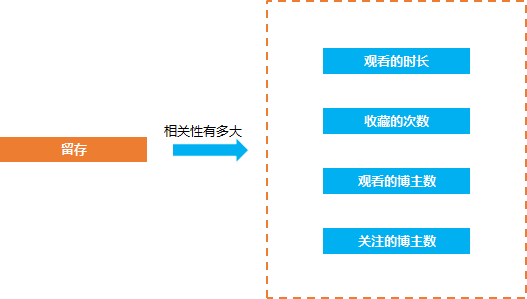
除了留存的相关性计算的问题, 还有类似的需要去计算相关性的问题, 比如淘宝的用户 他们的付费行为和哪些行为相关, 相关性有多大, 这样我们就可以挖掘出用户付费的关键行为
这种问题就是相关性量化, 我们要找到一种科学的方法去计算这些因素和留存的相关性的大小,
这种方法就是相关性分析
04
相关性分析是指对两个或多个具备相关性的变量元素进行分析,从而衡量两个变量因素的相关密切程度。相关性的元素之间需要存在一定的联系或者概率才可以进行相关性分析(官方定义)
简单来说, 相关性的方法主要用来分析两个东西他们之间的相关性大小
相关性大小用相关系数r来描述,关于r的解读:(从知乎摘录的)
(1)正相关:如果x,y变化的方向一致,如身高与体重的关系,r>0;一般地,
·|r|>0.95 存在显著性相关;
·|r|≥0.8 高度相关;
·0.5≤|r|<0.8 中度相关;
·0.3≤|r|<0.5 低度相关;
·|r|<0.3 关系极弱,认为不相关
(2)负相关:如果x,y变化的方向相反,如吸烟与肺功能的关系,r<0;
(3)无线性相关:r=0, 这里注意, r=0 不代表他们之间没有关系, 可能只是不存在线性关系。
下面用几个图来描述一下 不同的相关性的情况
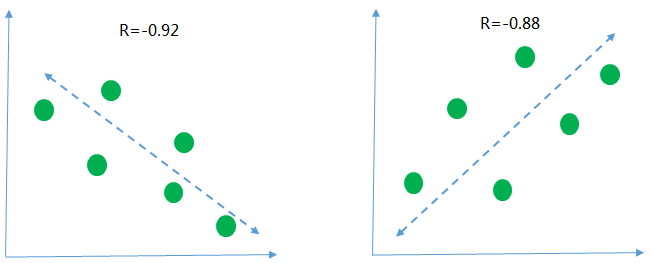
第一张图r=-0.92 <0 是说明横轴和纵轴的数据呈现负相关, 意思就是随着横轴的数据值越来越大纵轴的数据的值呈现下降的趋势, 从r的绝对值为0.92>0.8 来看, 说明两组数据的相关性高度相关
同样的, 第二张图 r=0.88 >0 说明纵轴和横轴的数据呈现正向的关系, 随着横轴数据的值越来越大, 纵轴的值也随之变大, 并且两组数据也是呈现高度相关
如何实现相关性分析:
前面已经讲了什么是相关性分析方法, 那么我们怎么去实现这种分析方法呢, 以下先用python 实现
1. 首先是导入数据集, 这里以tips 为例
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as sns%matplotlib inline## 定义主题风格sns.set(style="darkgrid")## 加载tipstips = sns.load_dataset("tips")
2. 查看导入的数据集情况,
字段分别代表
total_bill: 总账单数
tip: 消费数目
sex: 性别
smoker: 是否是吸烟的群众
day: 天气
time: 晚餐 dinner, 午餐lunch
size: 顾客数
tips.head() # 查看数据的前几行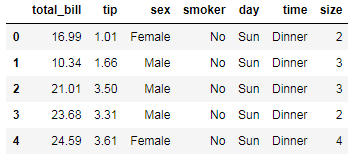
3. 最简单的相关性计算
tips.corr()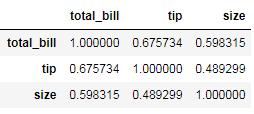
4. 任意看两个数据之间相关性可视化,比如看 total_bill 和 tip 之间的相关性,就可以如下操作进行可视化
## 绘制图形,根据不同种类的三点设定图注sns.relplot(x="total_bill", y="tip", data=tips);plt.show()
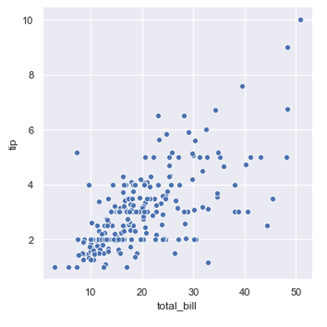
从散点图可以看出账单的数目和消费的数目基本是呈正相关, 账单的总的数目越高, 给得消费也会越多
5. 如果要看全部任意两两数据的相关性的可视化
sns.pairplot(tips)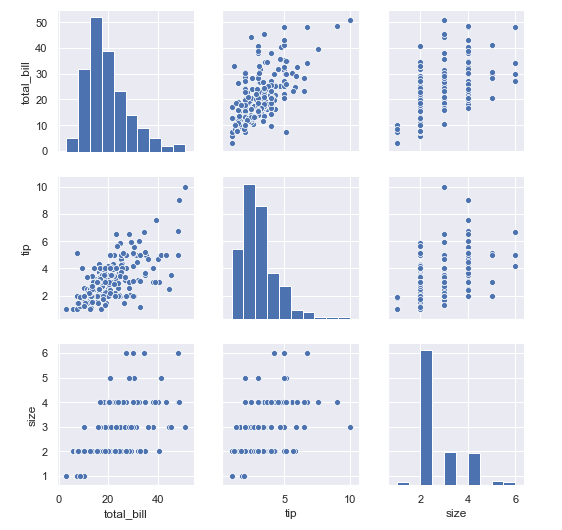
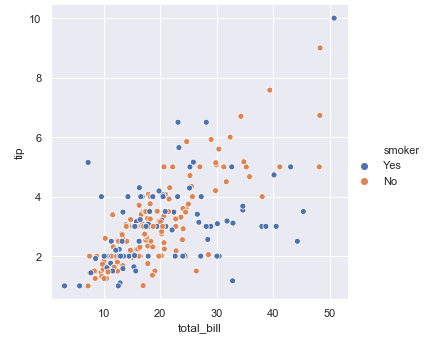
6. 如果要分不同的人群, 吸烟和非吸烟看总的账单数目total_bill和小费tip 的关系。
sns.relplot(x="total_bill", y="tip", hue="smoker", data=tips)# 利用hue 进行区分plt.show()
7. 同样的 区分抽烟和非抽烟群体看所有数据之间的相关性,我们可以看到
对于男性和女性群体, 在小费和总账单金额的关系上, 可以同样都是账单金额越高的时候, 小费越高的例子上, 男性要比女性给得小费更大方
在顾客数量和小费的数目关系上, 我们可以发现, 同样的顾客数量, 男性要比女性给得小费更多
在顾客数量和总账单数目关系上, 也是同样的顾客数量, 男性要比女性消费更多
sns.pairplot(tips ,hue ='sex')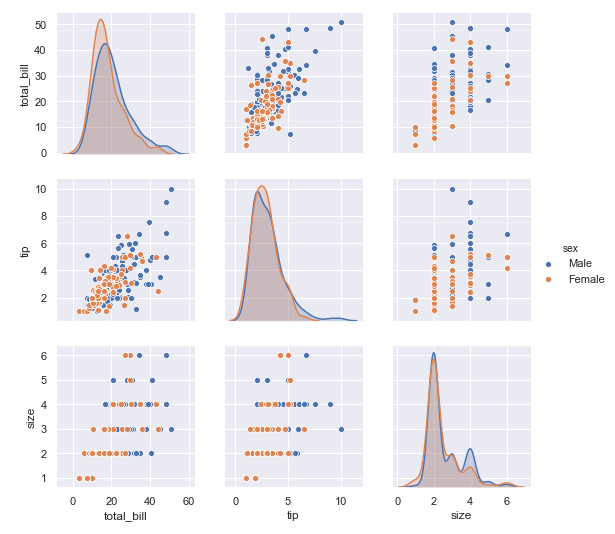
实战案例:
问题:
影响B 站留存的相关的关键行为有哪些?
这些行为和留存哪一个相关性是最大的?
分析思路:
找全与留存相关的行为
计算这些行为和留存的相关性大小
首先规划好完整的思路, 哪些行为和留存相关, 然后利用这些行为+时间维度 组成指标, 因为不同的时间跨度组合出来的指标, 意义是不一样的, 比如登录行为就有 7天登录天数, 30天登录天数
第二步计算这些行为和留存的相关性, 我们用1 表示会留存 0 表示不会留存
那么就得到 用户id + 行为数据+ 是否留存 这几个指标组成的数据
然后就是相关性大小的计算
import matplotlib.pyplot as pltimport seaborn as snsretain2 = pd.read_csv("d:/My Documents/Desktop/train2.csv") # 读取数据retain2 = retain2.drop(columns=['click_share_ayyuid_ucnt_days7']) # 去掉不参与计算相关性的列plt.figure(figsize=(16,10), dpi= 80)# 相关性大小计算sns.heatmap(retain2.corr(), xticklabels=retain2.corr().columns, yticklabels=retain2.corr().columns, cmap='RdYlGn', center=0, annot=True)# 可视化plt.title('Correlogram of retain', fontsize=22)plt.xticks(fontsize=12)plt.yticks(fontsize=12)plt.show()
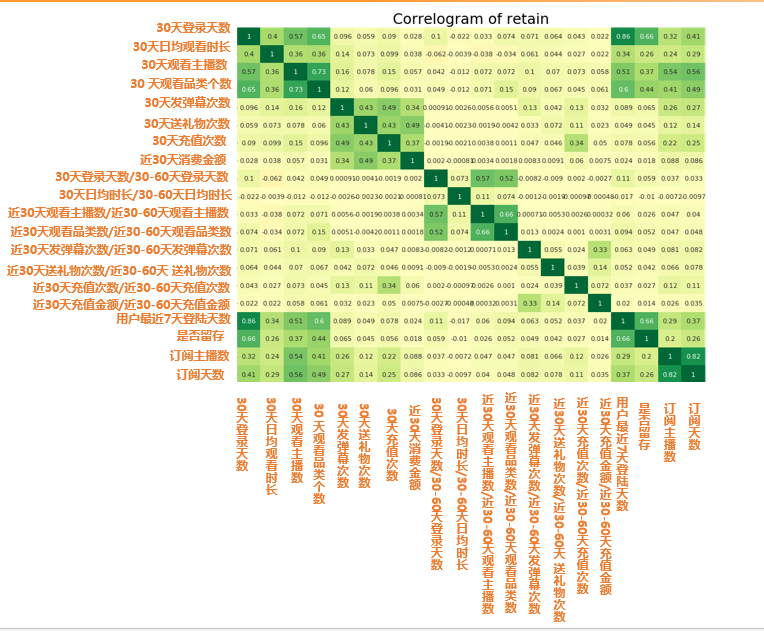
图中的数字值就是代表相关性大小 r 值 所以从图中我们可以发现
留存相关最大的四大因素:
•30天或者7天登录天数(cor: 0.66)
•30天观看品类个数(cor: 0.44)
•30天观看主播数 (cor: 0.37)
•30天日均观看时长(cor: 0.26)
05

我们经常在淘宝上购物, 作为淘宝方, 他们肯定想知道他的使用用户是什么样的, 是什么样的年龄性别, 城市, 收入, 他的购物品牌偏好, 购物类型, 平时的活跃程度是什么样的, 这样的一个用户描述就是用户画像分析
无论是产品策划还是产品运营, 前者是如何去策划一个好的功能, 去获得用户最大的可见的价值以及隐形的价值, 必须的价值以及增值的价值, 那么了解用户, 去做用户画像分析, 会成为数据分析去帮助产品做做更好的产品设计重要的一个环节。
那么作为产品运营, 比如要针用户的拉新, 挽留, 付费, 裂变等等的运营, 用户画像分析可以帮助产品运营去找到他们的潜在的用户, 从而用各种运营的手段去触达。
因为当我们知道我们的群体的是什么样的一群人的时候, 潜在的用户也是这样的类似的一群人, 这样才可以做最精准的拉新, 提高我们的ROI
在真正的工作中, 用户画像分析是一个重要的数据分析手段去帮助产品功能迭代, 帮助产品运营做用户增长。
总的来说, 用户画像分析就是基于大量的数据, 建立用户的属性标签体系, 同时利用这种属性标签体系去描述用户
用户画像的作用:
像上面描述的那样, 用户画像的作用主要有以下几个方面
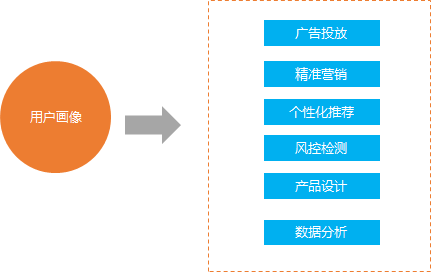
1.广告投放
在做用户增长的例子中, 我们需要在外部的一些渠道上进行广告投放, 对可能的潜在用户进行拉新, 比如B站在抖音上投广告
我们在选择平台进行投放的时候, 有了用户画像分析, 我们就可以精准的进行广告投放, 比如抖音的用户群体是18-24岁的群体, 那么广告投放的时候就可以针对这部分用户群体进行投放, 提高投放的ROI
假如我们没有画像分析, 那么可能会出现投了很多次广告, 结果没有人点击

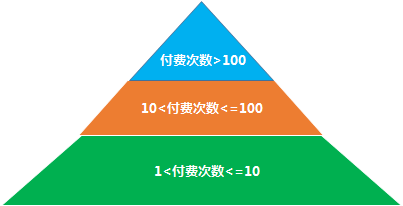
2.精准营销
假如某个电商平台需要做个活动给不同的层次的用户发放不同的券, 那么我们就要利用用户画像对用户进行划分, 比如划分成不同的付费的活跃度的用户, 然后根据不同的活跃度的用户发放不用的优惠券。
比如针对付费次数在 [1-10] 的情况下发 10 元优惠券刺激, 依次类推
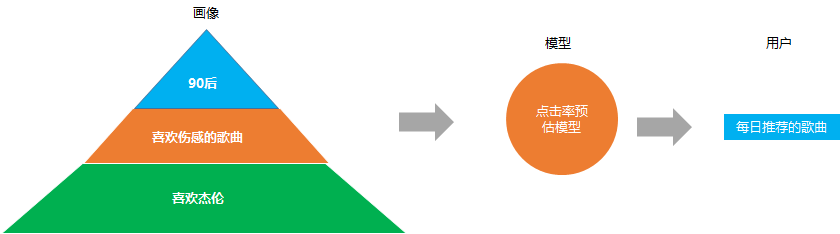
3. 个性化推荐
精确的内容分发, 比如我们在音乐app 上看到的每日推荐, 网易云之所以推荐这么准, 就是他们在做点击率预估模型(预测给你推荐的歌曲你会不会点击)的时候, 考虑了你的用户画像属性。
比如根据你是90后, 喜欢伤感的, 又喜欢杰伦, 就会推荐类似的歌曲给你, 这些就是基于用户画像推荐
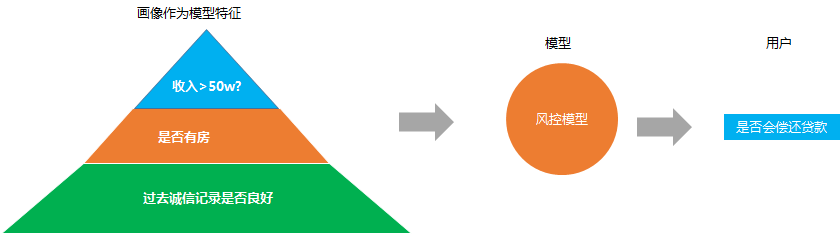
4. 风控检测
这个主要是金融或者银行业设计的比较多, 因为经常遇到的一个问题就是银行怎么决定要不要给一个申请贷款的人给他去放贷
经常的解决方法就是搭建一个风控预测模型, 去预约这个人是否会不还贷款,同样的, 模型的背后很依赖用户画像。
用户的收入水平, 教育水平, 职业, 是否有家庭, 是否有房子, 以及过去的诚信记录, 这些的画像数据都是模型预测是否准确的重要数据
5. 产品设计
互联网的产品价值 离不开 用户 需求 场景 这三大元素, 所以我们在做产品设计的时候, 我们得知道我们的用户到底是怎么样的一群人, 他们的具体情况是什么, 他们有什么特别的需求, 这样我们才可以设计出对应解决他们需求痛点的产品功能
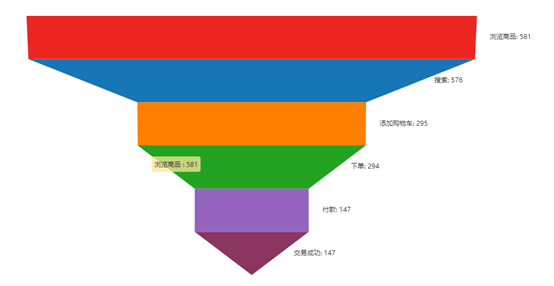
在产品功能迭代的时候, 我们需要分析用户画像行为数据, 去发现用户的操作流失情况, 最典型的一种场景就是漏斗转化情况, 就是基于用户的行为数据去发现流失严重的页面, 从而相对应的去优化对应的页面,
比如我们发现从下载到点击付款转化率特别低,那么有可能就是我们付款的按钮的做的有问题, 就可以针对性的优化按钮的位置等等
同时也可以分析这部分转化率主要是在那部分用户群体中低, 假如发现高龄的用户的转化率要比中青年的转化率低很多, 那有可能是因为我们字体的设置以及按钮本身位置不显眼等等, 还有操作起来不方便等等因素
6. 数据分析
在做描述性的数据分析的时候, 经常需要画像的数据, 比如描述抖音的美食博主是怎么样的一群人, 他们的观看的情况, 他们的关注其他博主的情况等等
简单来说就是去做用户刻画的时候, 用户画像可以帮助数据分析刻画用户更加清晰。
如何构建用户画像:
用户画像搭建的架构如下:
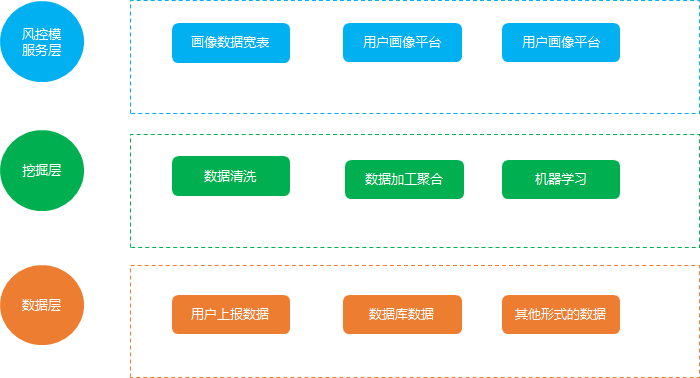
数据层:
首先 是数据层, 用户画像的基础是首先要去获取完整的数据, 互联网的数据主要是 利用打点, 也就是大家说的数据埋点上报上来的, 整个过程就是 数据分析师会根据业务需要提数据上报的需求,然后由开发完成, 这样就有了上报的数据。

除了上报的数据, 还有其他数据库同步的数据, 一般会把数据库的数据同步到hive表中, 按照数据仓库的规范, 按照一个个主题来放置
还有一些其他的数据比如外部的一些调研的数据, 以excel 格式存在, 就需要把excel 数据导入到hive 表中
挖掘层:
有了基础的数据以后, 就进入到挖掘层, 这个层次主要是两件事情, 一个是数据仓库的构建, 一个是标签的预测, 前者是后者的基础。
一般来说我们会根据数据层的数据表, 对这些数据表的数据进行数据清洗,数据计算汇总, 然后按照数据仓库的分层思想, 比如按照 数据原始层, 数据清洗层, 数据汇总层, 数据应用层等等进行表的设计

数据原始层的表的数据就是上报上来的数据入库的数据, 这一层的数据没有经过数据清洗处理, 是最外层的用户明细数据
数据清洗层主要是数据原始层的数据经过简单数据清洗之后的数据层, 主要是去除明显是脏数据, 比如年龄大于200岁, 地域来自 FFFF的 等明显异常数据
数据汇总层的数据主要是根据数据分析的需求, 针对想要的业务指标, 比如用户一天的听歌时长, 听歌歌曲数, 听的歌手数目等等, 就可以按照用户的维度, 把他的行为进行聚合, 得到用户的轻量指标的聚合的表。
这个层的用处主要是可以快速求出比如一天的听歌总数, 听歌总时长, 听歌时长高于1小时的用户数, 收藏歌曲数高于100 的用户数是多少等等的计算就可以从这个层的表出来
数据应用层主要是面向业务方的需求进行加工, 可能是在数据汇总的基础上加工成对应的报表的指标需求, 比如每天听歌的人数, 次数, 时长, 搜索的人数, 次数, 歌曲数等等
按照规范的数据仓库把表都设计完成后, 我们就得到一部分的用户的年龄性别地域的基础属性的数据以及用户观看 付费 活跃等等行为的数据
但是有一些用户的数据是拿不到的比如音乐app 为例, 我们一般是拿不到用户的听歌偏好这个属性的数据, 我们就要通过机器学习的模型对用户的偏好进行预测

机器学习的模型预测都是基于前面我们构建的数据仓库的数据的, 因为只有完整的数据仓库的数据, 是模型特征构建的基础
服务层:
有了数据层和挖掘层以后, 我们基本对用户画像体系构建的差不多, 那么就到了用户画像赋能的阶段。
最基础的应用就是利用用户画像宽表的数据, 对用户的行为进行洞察归因 挖掘行为和属性特征上的规律
另外比较大型的应用就是搭建用户画像的平台, 背后就是用户画像表的集成。
用户提取: 我们可以利用用户画像平台, 进行快速的用户选取, 比如抽取18-24岁的女性群体 听过杰伦歌曲的用户, 我们就可以快速的抽取。
分群对比: 我们可以利用画像平台进行分群对比。比如我们想要比较音乐vip 的用户和非vip 的用户他们在行为活跃和年龄性别地域 注册时间, 听歌偏好上的差异, 我们就可以利用这个平台来完成
功能画像分析: 我们还可以利用用户画像平台进行快速进行某个功能的用户画像描述分析, 比如音乐app 的每日推荐功能, 我们想要知道使用每日推荐的用户是怎么样的用户群体, 以及使用每日推荐不同时长的用户他们的用户特征分别都是怎么样的,就可以快速的进行分析
06
在数据分析的面试中, 你是否不止一次遇到以下的问题:
DAU降低了, 怎么分析,
用户留存率下降了怎么分析
订单数量下降了怎么分析
像这样的问题, 如果没有科学的思维框架去梳理你的思路的话, 去回答这个问题我们就会有一种想要说很多个点, 但不知道先说哪一个点, 只会造成回答很乱, 没有条理性, 同时有可能会漏斗很多点
回答这种分析的类似的问题的时候, 大多数情况下都可以利用5w2h 的方法帮助我们去组织思路, 这样可以在回答这种类似的问题的时候, 可以做到逻辑清晰, 答得点缜密完善
比如DAU下降了, 5w2h 分析法会教你如何拆解DAU下降以及归因以及给出建议
比如用户留存率下降了, 5w2h方法会教你去拆解用户, 归纳不同群体的留存率下跌原因
比如订单数量下跌了, 5w2h 方法助力漏斗分析, 快速挖掘流失的关键步骤, 关键节点
什么是5w2h:
5w2h 分析法主要是 以五个W开头的英语单词和两个以H开头的英语单词组成的, 这五个单词为我们提供了问题的分析框架
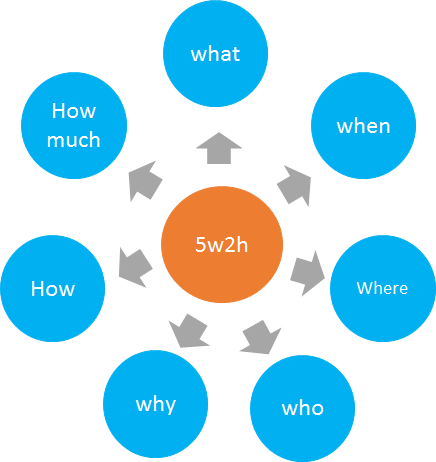
5W的内容
1.What-发生了什么?一般用来值得是问题是什么, what 的精髓在于告诉我们第一步要认清问题的本质是什么
2.When-何时?在什么时候发生的? 问题发生的时间, 比如dau 下降了就是下降的具体时间分析, 这个时间是不是节假日等等
3.Where-何地?在哪里发生的? 问题发生的拆解其中一个环节, 还是dau 下降了, 是哪一个的地区的下降了, 是哪一个功能的使用的人下降了等等
4.Who-是谁? 比如dau 下降了, 就是是哪一部分的用户群体在降, 是哪一个的年龄, 性别, 使用app 时长等等
5.Why-为什么会这样?dau 可能降低的原因猜想, 比如某个地区的dau 降低了, 其他地方的没有降低, 那可能是这个地区的app 在使用的过程中有什么问题
2H的内容
1.How-怎样做?知道了问题是什么以后, 就到了策略层了, 就是我们要采取什么样的方法和策略去解决这个dau 下降的问题
2.How Much-多少?做到什么程度?这个主要是比如dau下降了以后, 我们采取对应的策略是可能花费的成本是多少, 以及我们要解决这个降低的问题解决到什么程度才可以
案例实战:
1.背景:
某APP的付费人数一直在流失, 如何通过数据分析去帮助产品和业务去挖掘对应的付费的流失原因并给出对应的解决策略
2.分析思路:
尝试用5w2h 分析法去拆解这个问题

what: 我们的问题是付费人数开始流失了, 这种流失应该就是表现出来同比和环比可能都是下降的
when: 整体的流失很难看出问题, 所以我们需要去分析不同的流失周期的用户的占比大概都是多大, 从而分析出现在付费用户的流失周期主要集中在哪里。
where: 付费的入口和不同付费点的分析, 主要是分析哪一个入口的付费人数流失严重或者哪个功能的付费人数流失严重, 挖掘关键位置
who: 对用户的属性和行为进行分析, 分析流失的这部分用户群体是否具有典型的特征, 比如集中在老年群体, 集中在某个地区等等, 行为的特征分析表现在流失的用户的行为活跃表现是怎么样的, 比如是否还在app 上活跃, 活跃的时长和天数等等的分析
why: 通过上面的分析, 就可能大致得出用户的流失的原因, 需要把数据结论和猜想对应起来去看, 并做好归纳总结
how: 当我们挖掘和分析出付费用户流失的原因了以后, 需要采取对应的策略去减少流失的速度, 同时针对流失的用户进行挽留和召回
how much: 在通过数据分析给出对应的策略的时候, 也需要帮助业务方去评估我们的策略大概需要的成本, 让业务方知道这个策略的可行性以及价值
3.分析过程:
(1) 不同用户的流失周期比例分析, 大部分的群体的流失周期还不是很长, 说明整体来说用户的流失是最近刚发生的, 同时流失的周期不长, 说明我们有能力可以针对这部分的流失用户利用策略进行挽留
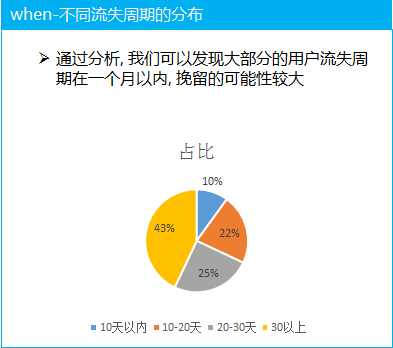
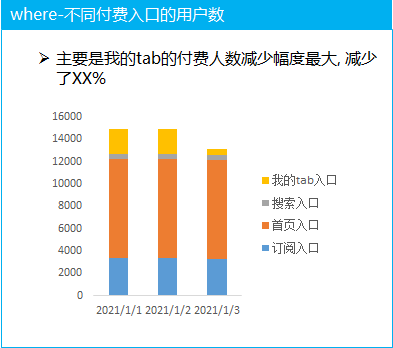
(2)不同付费入口的拆解分析
对比付费的四个主要的入口, 分析每天的付费人数的走势, 发现付费人数的减少主要集中在我的tab 入口, 我的tab 入口的付费降低的可能原因是什么呢
这就需要拉上业务方一起去分析对应的原因, 比如是可能是这个位置的付费功能的具体流失的每一个环节的流失情况(结合漏斗分析一起去看)
分析出我的tab 页面中 付费功能具体的流失环节, 然后再针对性的进行调整迭代
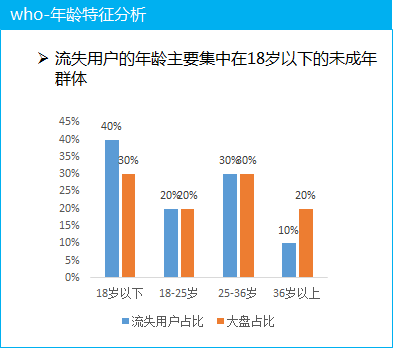
(3) 用户特征分析
这里以年龄为例, 分析流失的付费用户的年龄特征, 发现主要集中在18岁以下的未成年群体, 这部分的用户群体为什么流失呢? 就需要结合用户反馈等一起去看
除了年龄的角度, 我们还可以分析流失的用户的性别特征, 城市级别特征, 活跃时长和活跃天数, 经常使用的功能等特征
(4) 原因总结归纳
通过分析, 付费的用户群体主要原因是我的tab 的付费功能引起的, 可能是具体的某个付费转化环节出现问题
流失的用户群体主要是18岁以下, 男性, 三线城市为主(假设)
流失的用户群体活跃时长, 活跃次数, 活跃天数等没有明显下降
(5) 策略落地
这个环节需要和业务方反馈我们的数据分析结论, 然后结合产品的经验以及用户反馈以及调查问卷等方法进一步确定原因
如果确定好是我的tab 中付费功能的某个环节出现问题, 就需要针对的进行改进, 同时上线小流量的ab test 去验证我们的策略是否有效
07
麦肯锡逻辑树
逻辑树又称为问题数,演绎树或者分解树,是麦肯锡公司提出的分析问题,解决问题的重要方法
首先它的形态像一颗树,把已知的问题比作树干,然后考虑哪些问题或者任务与已知问题有关,将这些问题或子任务比作逻辑树的树枝,一个大的树枝还可以继续延续伸出更小的树枝,逐步列出所有与已知问题相关联的问题
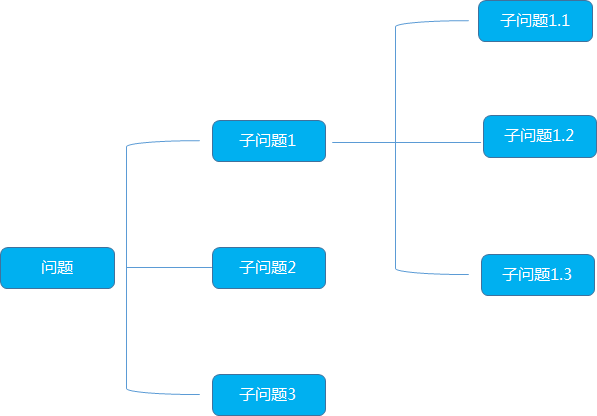
总的来说, 逻辑树满足三个要素
要素化:把相同问题总结归纳成要素
框架化:将各个要素组织成框架,遵守不重不漏的原则
关联化:框架内的各要素保持必要的相互关系,简单而不孤立
逻辑树的作用:
数据体系的搭建
数据体系的搭建中, 需要借助逻辑树的思路将业务的整体的目标结构化的进行拆解, 然后转化成可以量化的数据指标, 再转变为指标体系。
举个例子, 比如下面的OSM模型搭建数据体系的思路就是借助了逻辑树的思路
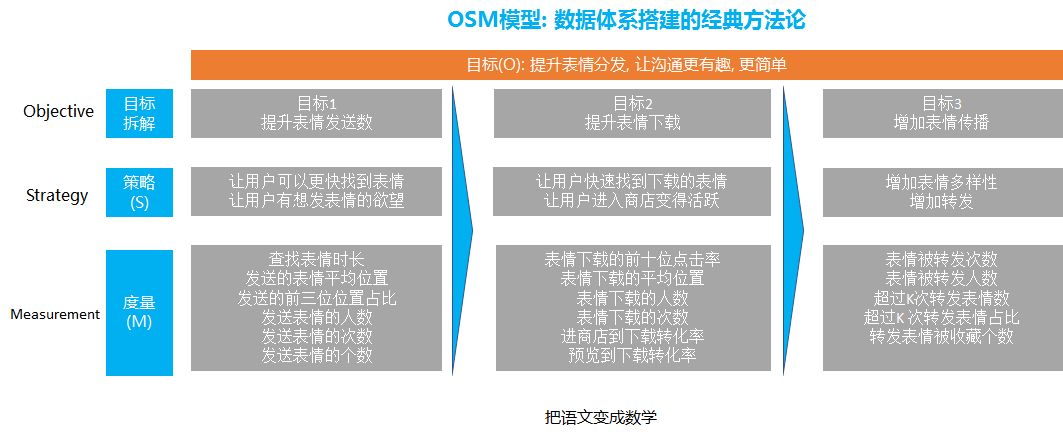
首先业务的整体目标是 提升表情的分发, 让表情的沟通更有趣更简单
通过逻辑树分析法, 我们可以进行第一步的拆解, 就是把整体表情进行拆解为提升表情发送数, 提升表情下载, 增加表情传播
提高表情发送数主要是提升用户的发送, 那么就变成去提升用户的发送, 那么怎么提升用户的发送呢, 我们可以通过内容和功能维度去解答
在内容方面, 我们要做到我们的表情丰富度和有趣度和新颖度和表达度等等, 要让用户有发这个表情的欲望
除了表情本身, 在发表情功能上我们也要针对性的进行优化, 比如提高用户查找表情的效率, 我们要去缩短查找表情的时间。
提升表情的下载, 也是同样的内容和功能本身, 在功能方面, 我们涉及到怎么把每个用户喜欢的表情排在最前面, 因为这样用户可以快速找到他们想要下载的表情.
另外, 也要通过功能的优化, 提升用户进入到表情商店的比例, 从源头上保证有足够的用户数都能够进入到表情商店
在内容方面, 我们要保证表情商店的表情在丰富度和吸引用户方面进行优化等等
提升表情的传播, 也是需要在内容和功能上优化, 这就涉及到社交关系的传播和表情的关系, 涉及除了要去引导用户下载自己喜欢的, 还要去下载他和朋友共同喜欢的表情
这样当a 用户发送了a 和a 的朋友b 共同喜欢的表情 就可以得到更多的转发
2. 数据问题的分析
针对用户订单减少的问题的分析, 可以利用逻辑树分析法, 定位到可能的流失原因, 再用数据验证
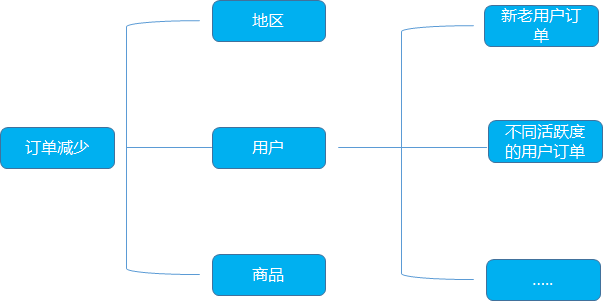
比如某个电商平台的订单降低, 我们利用逻辑树的拆解从地区, 用户, 商品类型等多个维度去思考。
从地区的角度, 整体的订单减少, 可以看一下是否是某个地区降低了, 可以细分到省, 市
从用户的角度, 是否是哪一类的用户的订单在减少, 同时还可以区分不同活跃度的用户在订单上的表现, 看具体的原因猜想
从商品的角度, 可以区分一下不同品类的商品看是否是特定品类的商品订单量跌了
逻辑树分析法在dau 中的应用:
背景:
某电商app DAU 跌了, 需要分析为什么dau 会跌, 这也是数据分析面试经典的问题, 在回答这个问题的时候, 为了使得我们的答案具有结构化和条理化, 需要应用逻辑树分析法
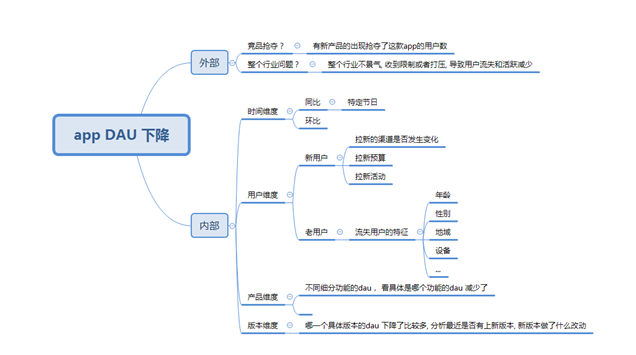
分析思路:
整体的分析思路如上,首先是拆分成外部和内部因素, 从最大的两个思路去切入, 一般去分析这个问题的时候, 很容易就会忽略外部因素, 外部因素也是很重要的一部分
外部的思考主要是竞品分析, 分析是否是竞品的崛起导致一部分用户转移到他们那边去了
外部的另外一个就是行业分析, 可以借助pest 等分析方法,分析这个行业的外部环境是否变得恶劣, 比如国家限制, 生活, 经济, 政策, 政治等外部原因
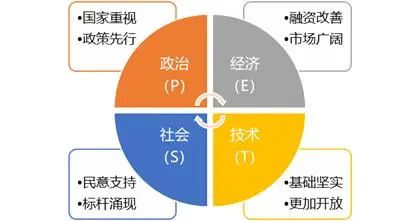
假如外部没有明显的问题, 这才进入到内部因素的排查
内部的分析首先应该是时间因素, 因为真正在工作实际中, 我们发现大多数的dau 等数据指标有大幅度波动都是因为节日引起的
所以有两个判断的方法, 假如这个dau 只是环比跌的很厉害, 然而同比没有明显变化, 甚至可能比去年这个指标还是涨的, 那么很大的概率可能就是节假日的影响
然后是用户维度, 整体的DAU= 新用户+老用户, 所以应该看这两个部分的是哪一部分的用户数减少
如果是新用户减少, 因为新用户是从渠道通过广告买量买过来的, 与这个数量相关的涉及到 渠道的质量, 买量的钱, 买完的一些承接运营活动
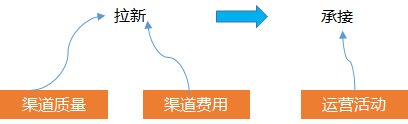
所以, 可以分开拆解看, 是否是渠道本身的质量问题, 比如腾讯广点通, 头条巨量, 看渠道本身在投放上起量是否是有问题的
同时也要看我们投放广告的钱是否有减少这会直接影响到我们能拉多少的人,预算直接决定了你的拉新绝对量的上限
拉取过来的用户要保证活跃, 我们通常会有运营活动或其他策略的承接, 也就是业界说的拉承一体化, 所以我们要去分析是否是运营活动的效果或者其他策略的效果影响我们的承接, 导致这部分用户的活跃度下降
除了新用户的分析, 老用户的分析也是非常重要的, 主要有常用的用户画像分析, 这部分可以参照 数据分析思维和方法—用户画像分析
主要是分析老用户是否下降, 如果下降了分析这部分下降的用户群体具有什么样的画像特征, 这样可以输出一个下跌用户的完整行为和基础属性的洞察, 比如下降的用户群主要是18岁以下的未成年人等等
第三个是产品本身维度, 如果分析出是所有类型的用户, 所有渠道的用户都在跌, 那就可能是产品本身的功能引起的
我们需要去排查一下dau 主要的功能模块的组成的用户, 去看一下这些功能的dau 是否跌的, 一般如果没有版本上线, 旧的功能的用户波动是由于功能bug 引起的
产品本身的排查比较麻烦, 因为有可能定位某个功能的人数变少了但是不知道原因, 这时候可以借助用户反馈, 一般可以从用户反馈上发现一些问题
08
漏斗分析法
漏斗分析是一种可以直观地呈现用户行为步骤以及各步骤之间的转化率,分析各个步骤之间的转化率的分析方法
比如对应我们每一次在淘宝上的购物, 从打开淘宝app, 到搜索产品, 到查看产品详情, 到添加购物车, 到下单, 到成功交易, 漏斗分析就是帮助我们去计算每一个环节的转化率
从打开淘宝app 到搜索的转化率, 从搜索产品到查看产品的详情的转化率,从查看产品到添加购物车的转化率, 从添加购物车到下单的转化率等等
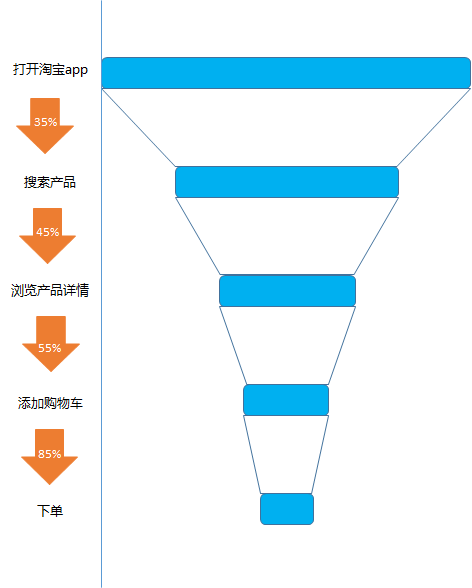
漏斗分析的价值:
漏斗分析的价值主要有: 功能优化, 运营投放, 用户流失等

功能优化:
以视频制作工具为例, 从下面我们可以明显看出, 进入到上传视频的转化率只有80%, 可能是上传入口不明显, 上传的引导不够, 上传功能的吸引程度不够等原因引起的, 我们就可以去优化上传功能

运营投放:
以运营投放类为例, 在实际业务中经常会对一些定向的用户投放一些活动, 让他们参加活动, 比如针对游戏的业务, 会定期针对潜在的付费用户投放一批充值优惠大礼包活动
从下图的触达到参与的转化率只有 62.5%, 说明我们选的定向的用户可能对于我们的活动不是非常感兴趣, 可能是这批用户本身不是特别喜欢参与活动, 所以我们就可以重新选取其他可能更加可能响应的用户来做定向推送
那么怎么选取最有可能参与活动的用户呢, 这里最简单的就可以用用户特征分析的方法来, 我们可以分析出参与活动和不参与活动的特征差异, 进行对比,
也就是采取对比的分析方法, 具体可以见数据分析方法和思维—对比细分
分析的结果就可以得到比如参与活动的用户可能本身在过去的付费频次上更好, 付费的金额更大, 并且在游戏的平均时长, 平均的游戏局数上更多, 年龄集中在18岁以下的群体中
那么我们就可以用这些特征去圈定更多的用户去做投放
另外一种去优化定向用户提高参与率的方法就是去利用模型去提前预测好哪些用户可能会参与活动, 可能使用的模型比如决策树, 逻辑回归等分类模型

用户流失:
以电商app 淘宝为例, 假如我们的订单人数下降了, 这时候就需要梳理用户购买链路, 把用户从打开app 到下单的所有的链路都梳理一遍, 然后利用漏斗分析, 计算每个环节的转化率
假如我们梳理链路中发现, 从搜索商品到查看商品的转化率很低, 那么我们就需要看是否是很多搜索无结果, 或者是搜索中的结果很多用户不太满意, 导致用户不买单
那就可以把电商的付费问题转化为搜索的问题, 从而又可以对搜索的整个转化链路再做一次漏斗分析, 一步步的去定位问题

漏斗分析的作用:
在用户增长的最出名的漏斗模型叫做AARRR, 即从用户获取, 用户激活, 用户留存, 用户付费到用户传播
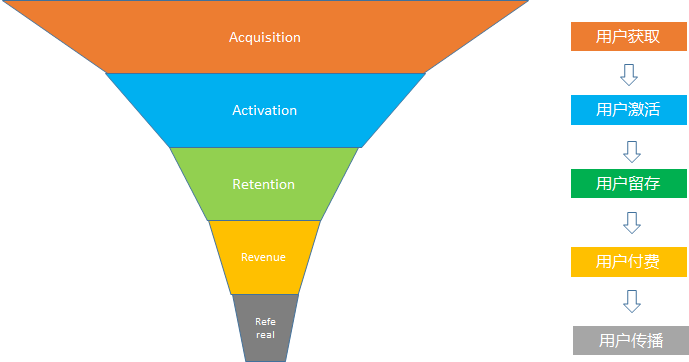
以拼多多为例, 以AARRR漏斗模型解析拼多多的用户增长之路
1.用户获取
拼多多主要的目标群体是三四线城市,这也属于现有电商品台比较空白的区域,对于三四线用户来说,最好的吸引方案就是优惠。
而且三四线用户时间充足,时间成本于他们而言是非常低的,而砍价也是一种惯常的方法,在他们的群体中很少存在对贪小便宜歧视的问题,也没有太多的社交压力,甚至砍价可以变成一种联系的手段,砍价群又何尝不是一种交流。
他们也很乐意用时间和社交成本来换取更大的优惠。所以砍价这种优惠活动红极一时,也帮助拼多多拉取了很多流量
砍价活动借助微信朋友圈和微信群的关系链, 成为爆发式的转发和增长, 一般亲朋友不会拒绝你的要请砍一刀
2.用户激活
当拉到新用户的时候, 就要保证最大程度的去激活他, 拼多多采取的做法也是跟拉新类似, 就是不断用用户的传播去触达好友
当一个用户被其他朋友反复触达的时候, 自然而然就会去打开曾经下载过的app,在其他朋友感受到拼多多百亿补贴各种补贴各种优惠的真香的时候, 自己也会去尝试
3.留存
为了提高用户的留存, 拼多多提供了一个签到领取奖品的活动鼓励用户每天都打开app 来签到打卡, 签到满XX天就可以送你对应的商品礼物, 大大促进拼多多用户群体的薅羊毛的心理, 同时也提升了留存
除了这个活动拼多多里面还设置了不同的各种小活动, 满足不同的用户群体的需要, 在玩小任务的过程中领取对应的奖励
4. 用户付费
拼多多以优惠券等的形式刺激用户下单, 比如下面的下首单并赚XX元, 而且还不给你叉掉这个页面的按钮
还有就是非常出名的百亿补贴, 直接用大额现金给用户补贴, 这一个打法把一二线的用户也被转化了
还有就是0元下单的活动, 0元免费下三单全额返还金额的活动
以及限时优惠限时秒杀, 9快手特卖等都是促使用户去下单等活动
页面上也是各种“”XX已经拼单“”等文字的提醒引导也是促进用户下单
5. 用户传播
传播主要依赖微信这个流量大平台以及微信关系链, 朋友之间的传播分为, 有些东西是要转发朋友才可以领取现金以及拼单以及优惠, 在这些优惠面前, 转发的成本变得很小
另外拼多多上是有一些真的实惠又好用的高性价比的商品, 这种的商品会引发朋友之间互相推荐
以上的一些原因, 拼多多的商品和玩法在朋友之前疯狂流转, 在传播的过程中, 每个用户都熟知了拼多多可以做到这么实惠的玩法, 被触达的用户又会开始新的转发, 从而引爆增长
社交网络的增长是没有尽头的, 也是阻止不了的, 一代帝国的诞生
数据是风, 你们是风上闪烁的星群
风中细数星群, 一如那余味缠绕的甘醇
-----------------------------------------------------------------
公布前期送书活动中奖读者,请于24小时内通过公众号菜单-“关于”添加小编微信,联系送书事宜。