
程序员修神之路--略懂数据库集群读写分离而已
“灵魂拷问:
解决数据库读写瓶颈有哪些解决方案呢? 这些方案解决了什么问题呢? 这些方案有那些优势和劣势呢?
一个可以抵抗高并发流量系统的背后必定有一个高性能的数据库集群,就像每一个成功的男人背后总有一个强势的女人一样。数据库集群在部署模式上属于分布式,但是CAP原则却不适用于分布式数据库,具体原因可见之前文章:、
要想实现数据库读写的高性能,目前针对写操作的优化方案主要有分库分表以及采用IO更优的设备来辅助,具体可见之前的文章:
分库分表作为一种普遍的解决方案,几乎已经成为面试者吹水的利剑,却很少有人在意它所带来的副作用。其实分库分表是利用了分治的思路来解决数据库的瓶颈问题,这种方案同时解决了并发读和并发写的瓶颈,利用数据分片的方式,以堆积硬件的方式来抵抗了高流量的冲击,当然带来了某些业务需要跨库查询,跨表join等问题,不过这些问题总能以别的解决方案来应对。
数据库读写分离是解决数据库性能瓶颈的另外一个方案,和分库分表方案相比较,他们有着本质的区别。分库分表会把数据分散在多个库表中,然后利用数据分片的规则来读取和写入数据,而读写分离是利用“冗余”的方式来应对大流量的冲击。
读写分离原理
“读写分离的基本原理是将数据读写分散到不同的数据库节点上,写操作一般只发生在主节点,可以接受少量延迟的读操作发生在从节点上
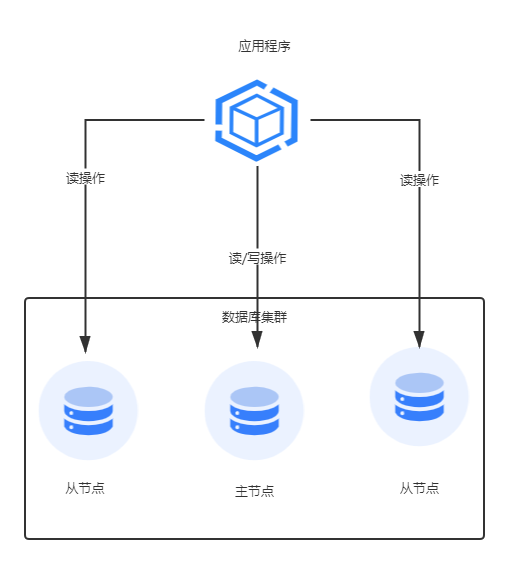
至于读写分离的实现方式:
多台数据库服务器组件成集群,并配置主从关系 主节点负责读写操作,从节点只负责读操作 主节点通过数据复制机制,把数据从主节点同步到所有的从节点 业务方利用程序或者中间件把写操作发送给主节点,将读操作发送给从节点
读写分离优势
一般的系统都会满足28原则,既:80%的操作是读操作,20%的操作是写操作。系统的读操作占比越大,读写分离的优势就越发明显,因为读操作可以通过简单的增加数据库从节点来解决,当然从节点的增加并不是毫无限制,当从节点到达一定数量的时候,必然会影响主从同步的效率,会降低主节点的性能,这个时候需要考虑一致性和可用性的平衡问题了。
另外一点,在很多业务中都会有一定的数据统计需求,单机数据库的时候,这些统计需求执行的sql和业务sql混合在一起,在一定程度上会影响正常业务的运行,尤其是那些数据量比较大的业务场景。在做了读写分离的策略之后,统计业务完全可以独占一个从库来进行统计,就算是比较耗时的操作,也不会影响正常的业务运行。
“数据库的读写分离方案在所有读操作场景中,发挥了最大优势
读写分离劣势
数据库读写分离有一个很多系统都会遇到的问题,那就是有些业务在写操作成功之后需要实时的读取到数据,可是数据从主节点同步到从节点是有一定时间延迟的,所以很多情况下业务方在从节点并不能实时的读取到正确的数据,这种业务场景其实就是主节点也需要提供读操作的典型场景,当然如果系统架设的有缓存模块,在主节点写操作成功之后可以同步更新缓存,以达到业务需要实时数据的要求。
路由机制
读写分离在写操作上有着严格的要求,写操作必须发生在主节点上,因为读写分离是基于中心化的思想来建立的集群,中心化的思想要求主节点上的数据必须是最新且最全的。这就要求调用方必须要区分出主节点才可以。
代码封装
用程序代码封装读写分离逻辑需要在代码中抽象出一个数据访问层,在这一层中实现操作分离以及数据库的连接管理等。
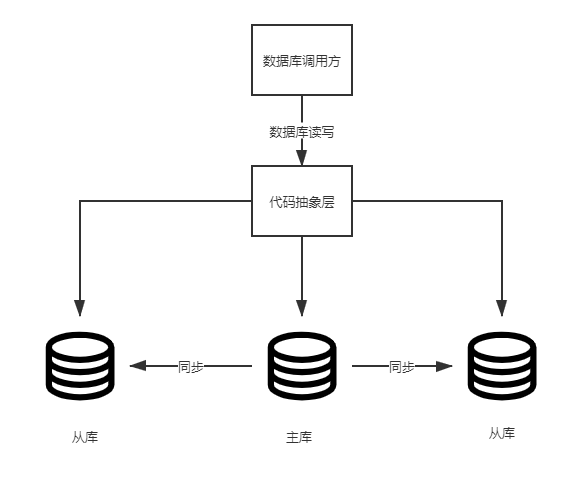
用代码封装读写分离逻辑在落地上并非易事,需要经过很长时间的测试才可以上生产环境。如果公司内部存在多个语言的开发团队,每个语言可能都需要实现一次,开发量还是比较大的。但是在针对不同的业务中,可以做到定制化的需求,在落地过程中还需要考虑如果主从发生切换,代码中必须要有类似选举的过程。
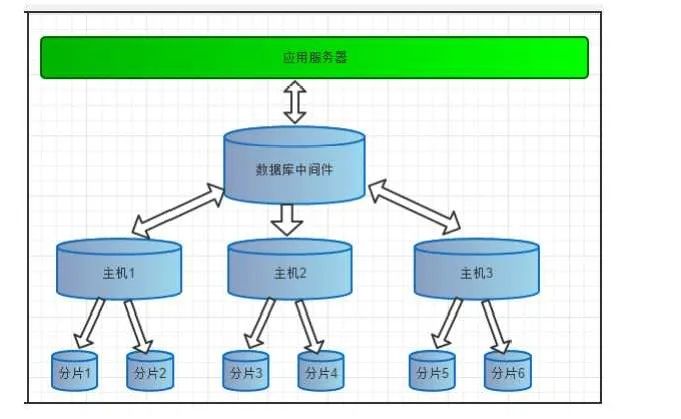
数据库中间件
数据库中间件是指基于数据库提供的SQL协议来开发的一套和具体业务无关的系统,它的作用也是实现操作分离和数据库的连接管理等,它同样也是对读写分离的一个抽象层,但是这个抽象层是基于数据库协议的,对于业务的使用方来说,就像访问单个数据库一样方便。
同步延迟
任何分布式的系统都逃不过一致性的问题。数据库的主从架构也是一样,发生在主节点的操作需要同步给每个从库。像MySQL的主从复制是依赖于binlog的,主从复制就是将binlog中的数据从主库复制到从库上,一般这个过程都会采用异步的方式,因为在网络延迟的情况下,如果采用同步方式会大大降低主库的可用性。
在binlog的复制过程中,极低的概率会发生binlog还没有来得及刷新到磁盘就出现磁盘坏掉或者down机的情况,最终的效果就是主从数据的不一致,但是这种不可抗拒的因素,一般是可以容忍的。
还有一种现象,一般数据从主节点复制到从节点会开启单线程模式,如果主库产生新数据的速度大于同步的速度,那有可能会进一步加大主从同步的延迟时间,这个是否可以考虑开启多线程或者利用缓存模块来屏蔽同步延迟的问题呢?
主备方案
说到数据库主从的架构部署方式,还有一种类似的方案:主备。主备是利用冗余一个节点来做备用节点,但是这个节点在主节点正常运行的情况下,不会对外提供服务,做了一个真正的“备胎”。当主节点挂掉,备用节点会代替主节点的位置,并成为主节点开始对外提供服务。
主备方式可以利用简单的类似keepalive机制来实现自动化,理论上不需要进行选举操作。利用主备方式来实现数据库高可用有哪些特点呢?
可用性是利用keepalive机制来保证的,这个切换过程对业务是透明的,业务方无需修改任何代码 读写都在主库上进行,很容易产生单点的瓶颈问题,由于没有其他节点的数据同步过程,所以数据可以保证一致性 主备架构中,备库只是单纯的备份,整体的资源利用率50%,因为备库一直在被闲置 扩展性比较差,无法做到横向扩展,但是可以利用分库分表来解决扩展性问题
一主一备或者一主多备方案在资源的利用率上很低,所以后来出现了多主的架构,多主架构是指,会存在多个主库,每个主库都提供读写功能,这就涉及到多个主库之间数据同步的方式,虽然性能上要比一主要高,但是数据一致性上很难搞。所以很多互联网公司并不推荐使用这种方案。
写在最后
数据库的扩展由于其属于有状态的范畴,所以比无状态的网站或者服务要困难很多。现在主流的落地方案也都是基于“分”的策略,分库分表方案和主从读写分离方案是两种最常用的扩展方式,在很多情况下,二者是结合起来使用的,即:在分库分表的情况下,每个节点采用主从读写分离的方式,这也是目前比较主流的方式了。
“更多精彩文章