
高糊图片可以做什么?
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转自:视学算法
给出一张低分辨率图像,你可以用它做什么,用机器学习方法将它尽量恢复原貌?除此之外呢?近日,谷歌 David Berthelot、Peyman Milanfar,以及 Goodfellow 提出了一种名为 LAG 的生成器,可以基于一张低分辨率图像生成一组合理的高分辨率图像。

论文链接:https://arxiv.org/pdf/2003.02365.pdf
代码地址:https://github.com/google-research/lag
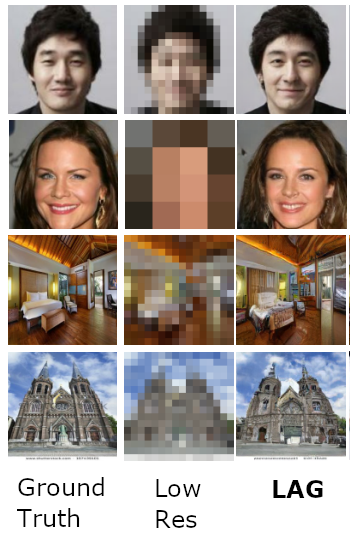
将输入图像建模为一组可能的图像,而不是单张图像,即建模了(低分辨率)输入图像的流形;
学习单个感知潜在空间,来描述预测和真值之间的距离;
分析条件 GAN(conditional GAN)和 LAG 之间的关系。
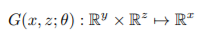
从图像到潜在空间 p 的投影 P;
从该潜在空间到 R 的映射 F。
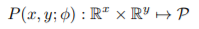
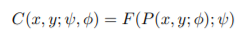
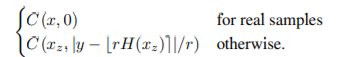





交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
评论