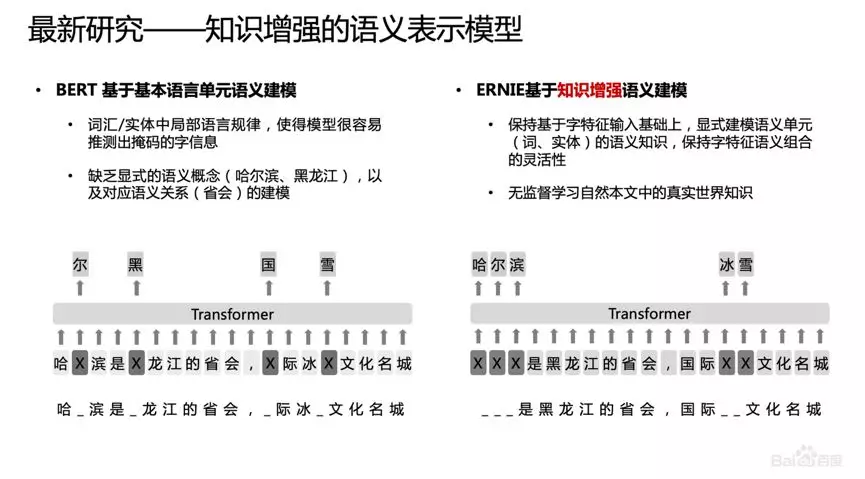
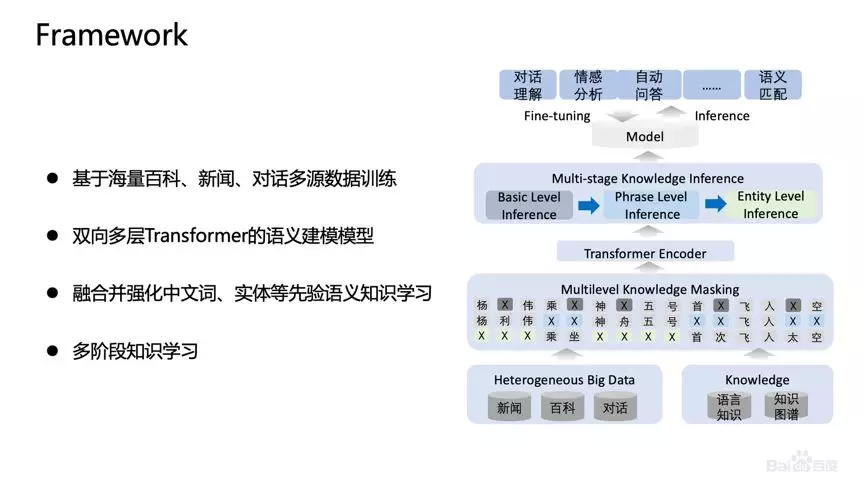
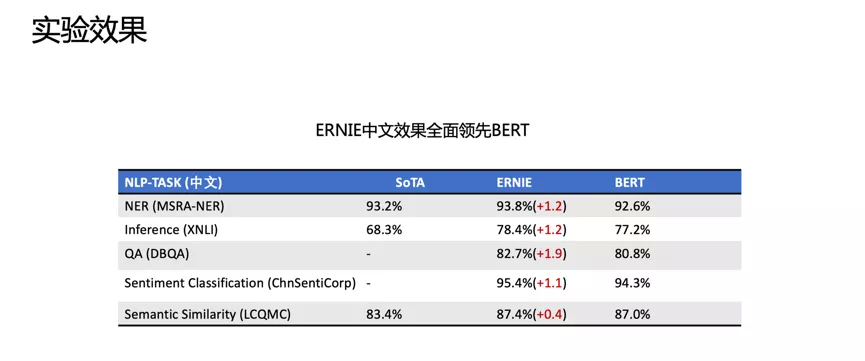
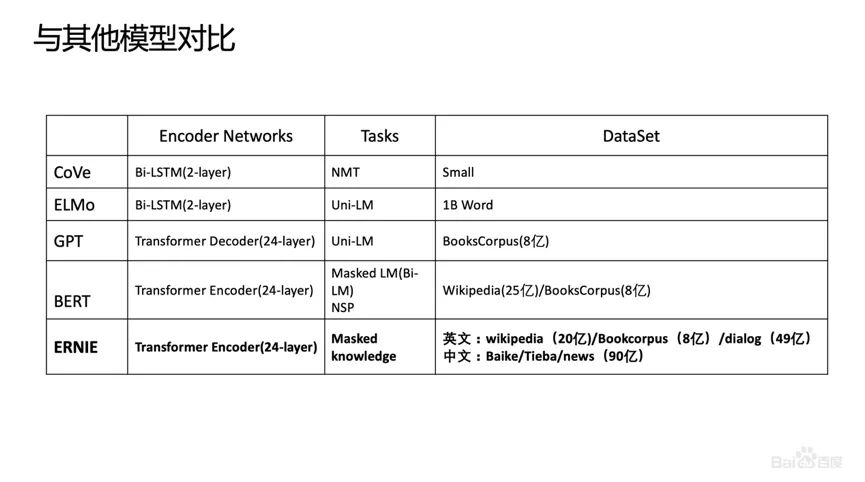
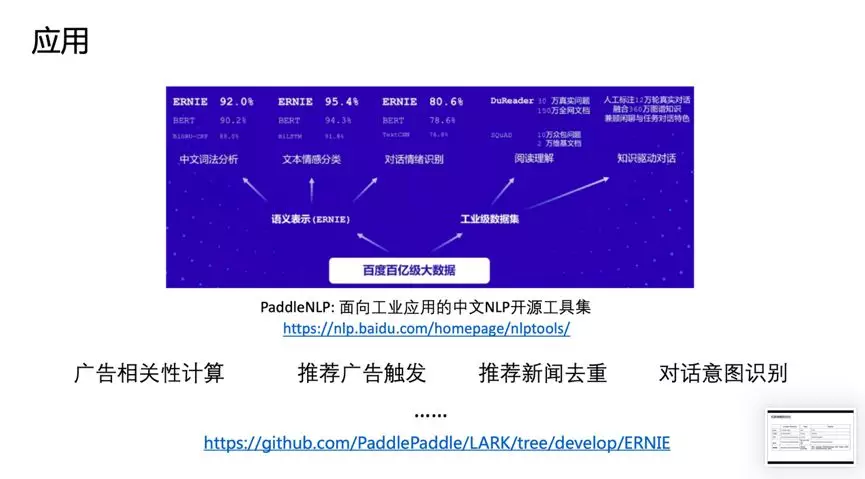
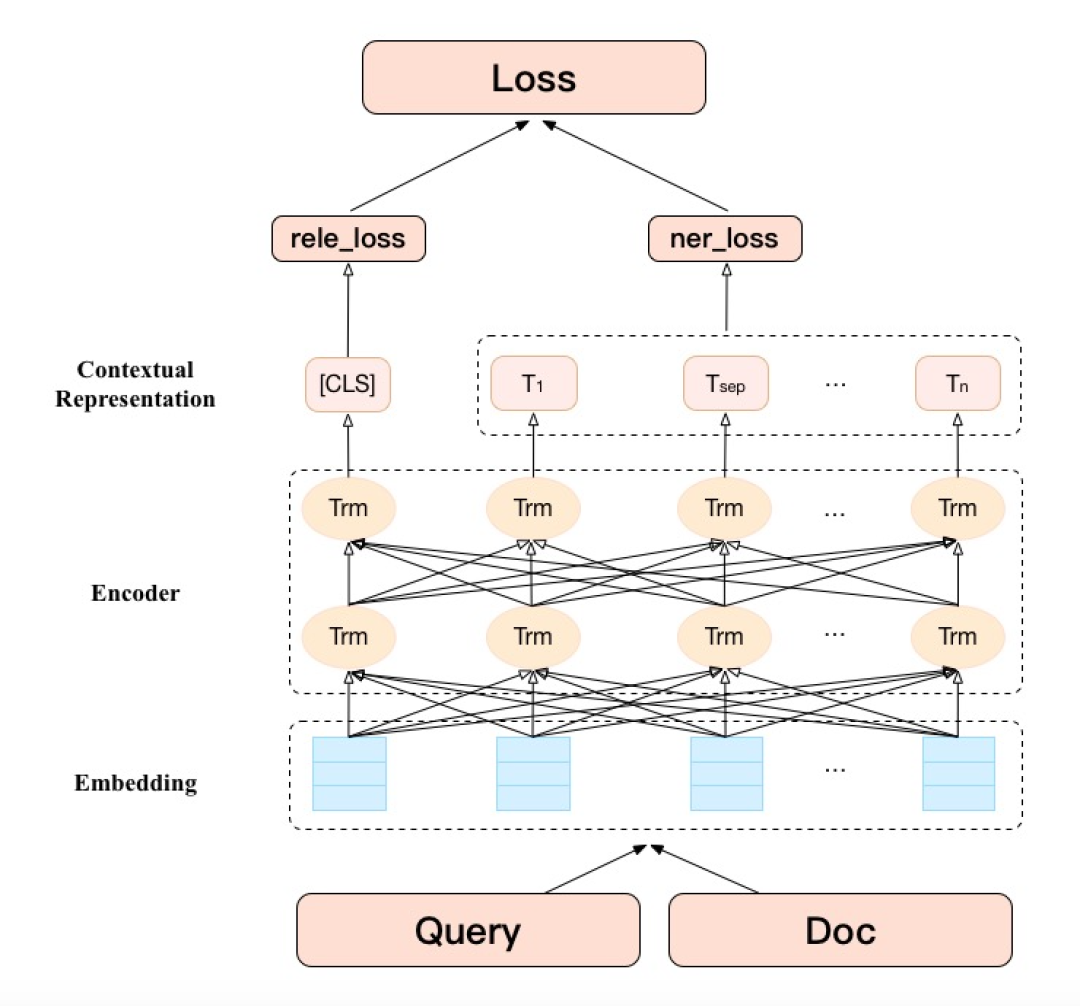
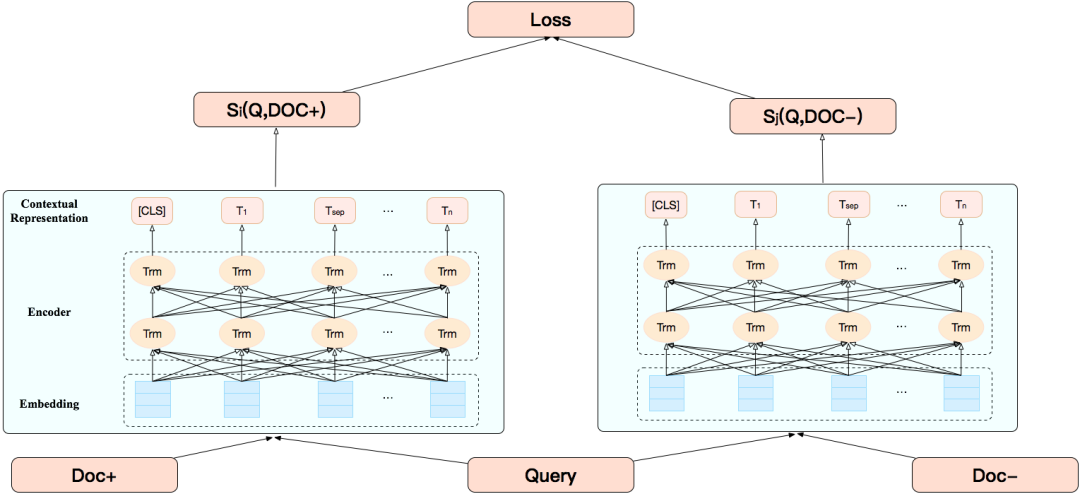
论文:ERNIE 2.0: A Continual Pre-Training Framework for Language Understandinggithub:http://github.com/PaddlePaddle/ERNIE 改进点:引入知识,在BERT基础上MASK 词和实体的方法,学习这个词或者实体在句子里面 Global 的信号。BERT 提出后,我们发现一个问题,它学习的还是基础语言单元的 Language Model,并没有充分利用先验语言知识,这个问题在中文很明显,它的策略是 MASK 字,没有 MASK 知识或者是短语。在用 Transformer 预测每个字的时候,很容易根据词包含字的搭配信息预测出来。比如预测“雪”字,实际上不需要用 Global 的信息去预测,可以通过“冰”字预测。基于这个假设,我们做了一个简单的改进,把它做成一个 MASK 词和实体的方法,学习这个词或者实体在句子里面 Global 的信号。基于上述思想我们发布了基于知识增强的语义表示ERNIE(1.0)。英文上验证了推广性,实验表明 ERNIE(1.0)在 GLUE 和 SQuAd1.1 上提升也是非常明显的。为了验证假设,我们做了一些定性的分析,找了完形填空的数据集,并通过 ERNIE 和 BERT 去预测,效果如上图。我们对比了 ERNIE、BERT、CoVe、GPT、ELMo 模型,结果如上图所示。ELMo 是早期做上下文相关表示模型的工作,但它没有用 Transformer,用的是 LSTM,通过单向语言模型学习。百度的 ERNIE 与 BERT、GPT 一样,都是做网络上的 Transformer,但是 ERNIE 在建模 Task 的时候做了一些改进,取得了很不错的效果。在应用上,ERNIE 在百度发布的面向工业应用的中文 NLP 开源工具集进行了验证,包括 ERNIE 与 BERT 在词法分析、情感分类这些百度内部的任务上做了对比分析。同时也有一些产品已经落地,在广告相关性的计算、推荐广告的触发、新闻推荐上都有实际应用。 后来,百度艾尼 ( ERNIE ) 再升级,发布了持续学习语义理解框架 ERNIE 2.0,同时借助飞桨 ( PaddlePaddle ) 多机多卡高效训练优势发布了基于此框架的 ERNIE 2.0 预训练模型。该模型在共计 16 个中英文任务上超越了 BERT 和 XLNet,取得了 SOTA 效果。
二、阿里大文娱—Poly Encoders
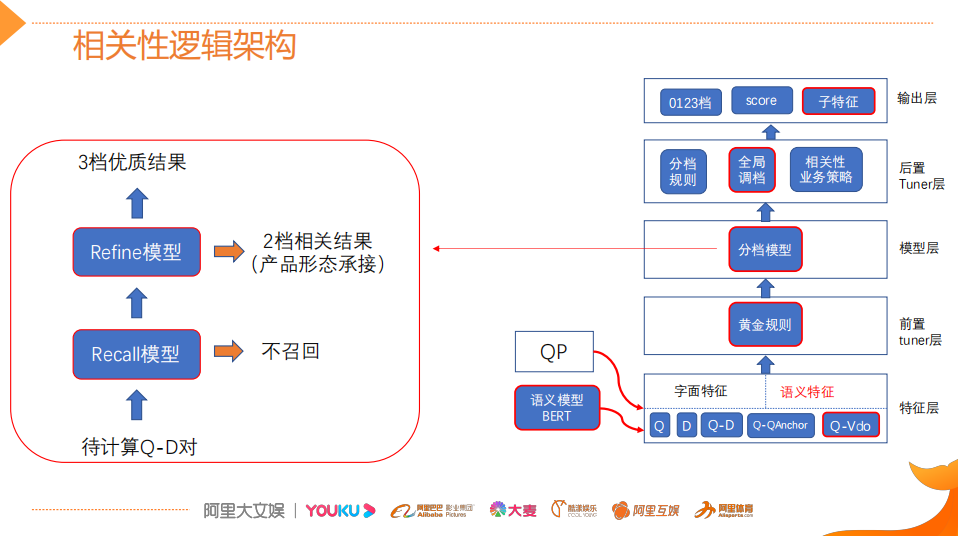
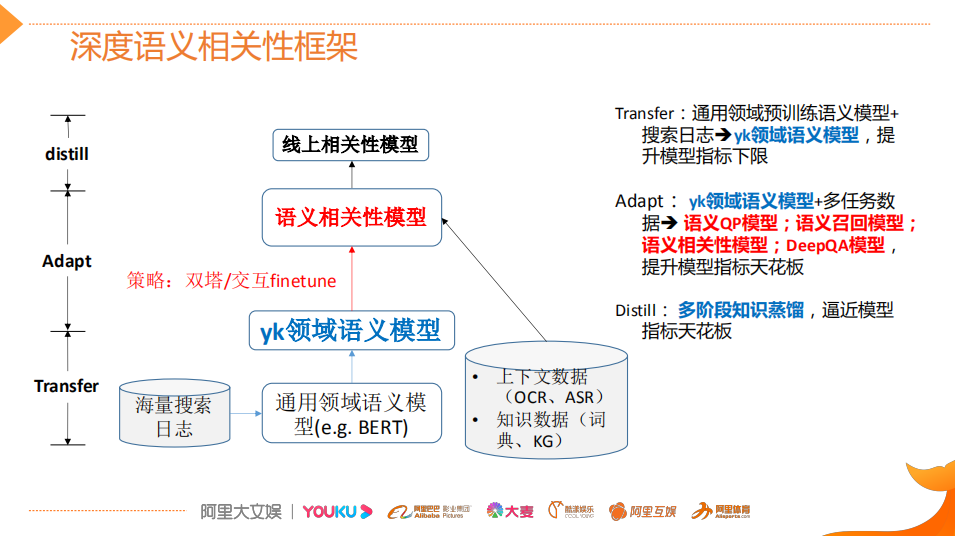
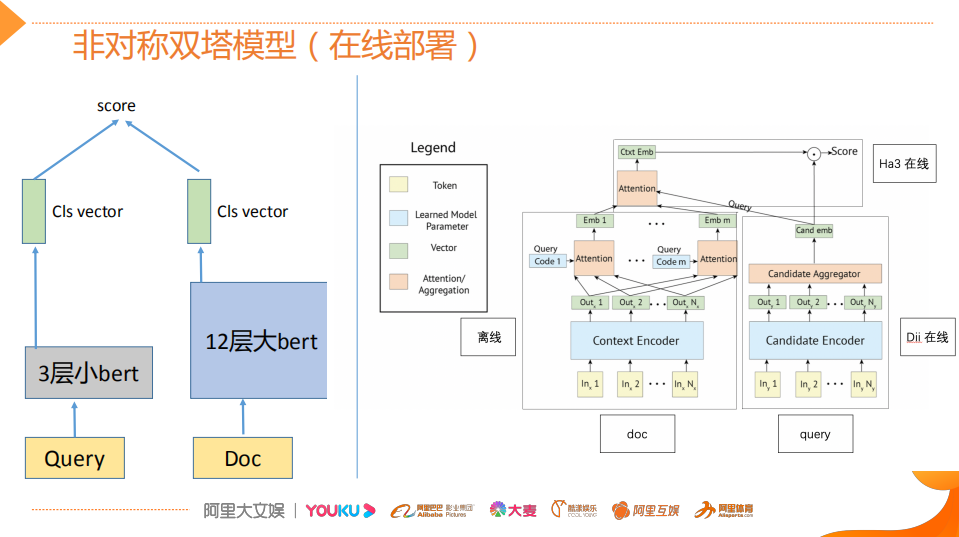
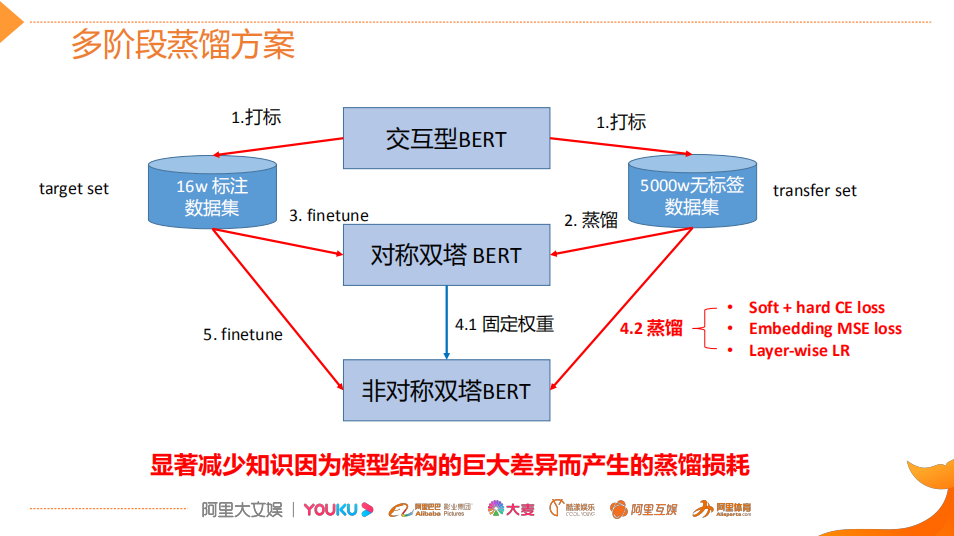
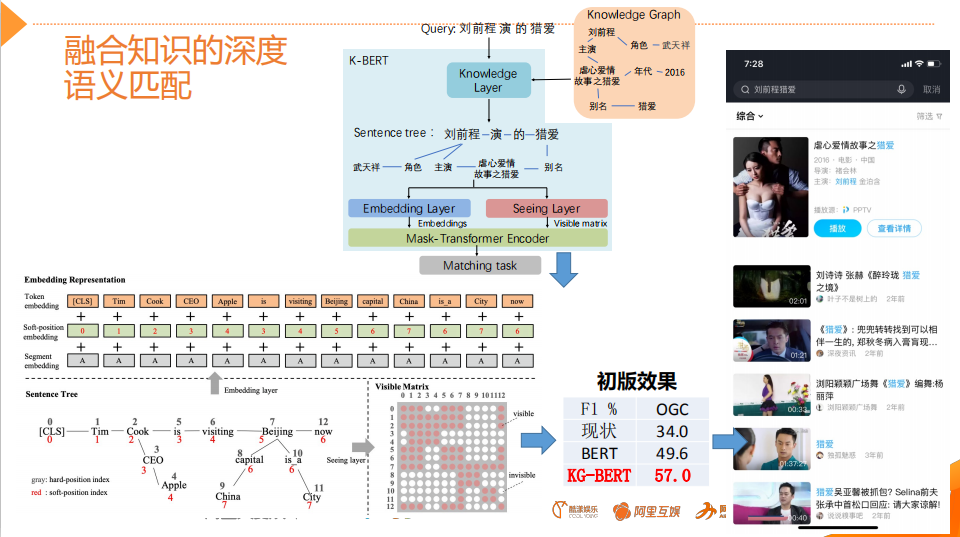
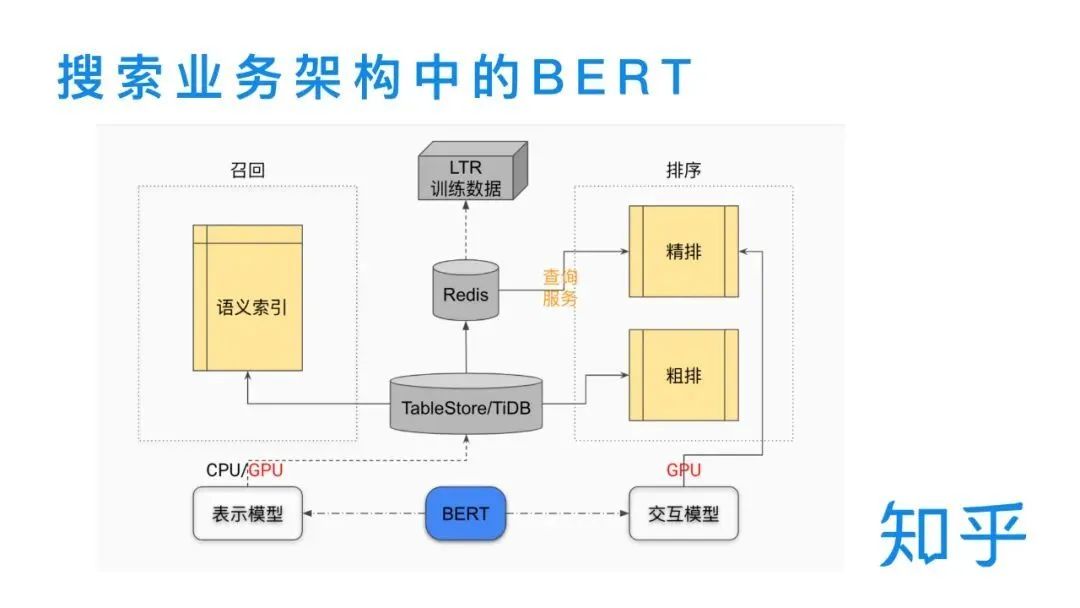
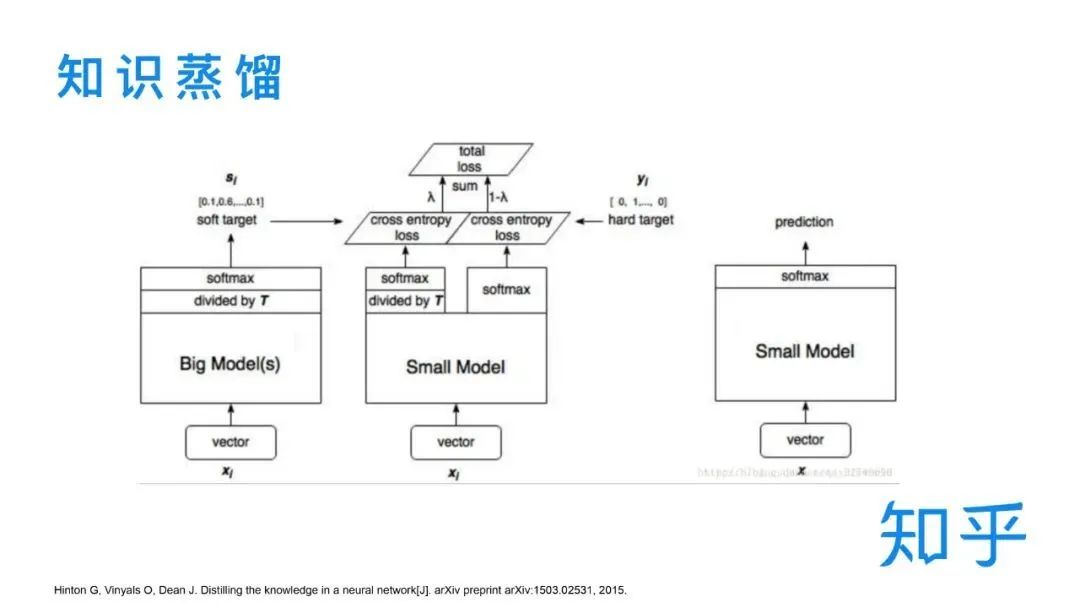
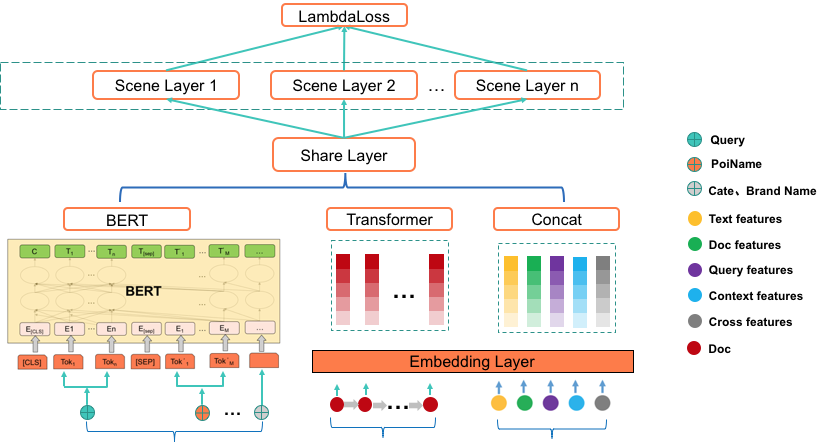
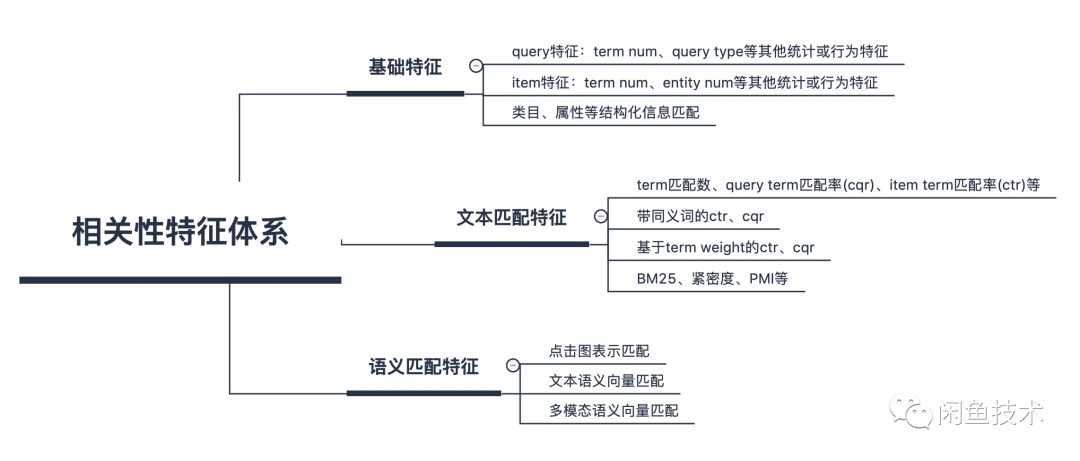
论文:Poly-encoders: Transformer Architectures and Pre-training Strategies for Fast and Accurate Multi-sentence Scoring相关性逻辑架构:前置的tuner层:主要包含一些黄金的规则,在训练集上准确率超过95%的这种规则策略,当满足这些条件时,不进行模型处理,直接通过规则处理。 模型层:当黄金规则处理不了时,利用分档的模型做兜底。分档的模型含有两个子模型为Recall模型和Refine模型,两个模型的结构一样,但它们使用的特征以及样本的选择是不一样的。分档模型的好处在于将整个相关性分档的功能进行了解耦,一个是用来发现高相关性的优质DOC,另外一个是用来降低相关性的岔道和进行过滤。 后置的tuner层:该层对于因为样本数据不均衡、核心特征缺少等原因没有学出来的情况,会添加一些人工的兜底规则进行补充。比如说会针对视频内容理解特征做了一些规则。该层中还全局调档的一个Tuner,它的作用是基于全局的DOC匹配再做一些调整。 BERT在工业界落地的常用三步 非对称双塔模型(在线部署)如果直接从交互性(12层BERT)改成双塔(2个12层BERT),指标下降较多非对称双塔: