
深入理解G1垃圾收集器
1. 垃圾收集器简析
Java语言一直使用GC技术进行JVM自动内存管理,避免手动管理带来的一系列问题,以提升开发人员效率。衡量垃圾回收的三个最重要指标:
内存占用(Footprint); 吞吐量(Throughput); 延迟(Latency);
目前的垃圾收集器能是尽量在这三个指标中寻找平衡,以达到最大的回收效率,能同时达到这三个指标完美的垃圾收集器是比较困难的,但是随着20多年来垃圾收集器的技术进步,一款优秀的收集器也越来越满足大家的需求。目前,比较经典的垃圾收集器有如下几种:
Serial收集器,历史最悠久,GC是单线程,会有“Stop The World”,内存消耗最小,作用于新生代,基于标记-复制算法实现; Serial Old收集器,是Serial的老年代版本,基于标记-整理算法实现,在JDK5及之前,和Parallel Scavenge搭配使用,以及作为CMS失败时的备选方案; ParNew收集器,是Serial收集器的多线程并行版本,作用于新生代,基于标记-复制算法实现,也会暂停所有用户线程; Parallel Scavenge收集器,作用于新生代,基于标记-复制算法实现,侧重于吞吐量,有自适应调节策略,合理搭配新生代和老年代大小; Parallel Old收集器,是Parallel Scavenge的老年代版本,基于标记-整理算法实现,JDK6开始提供; CMS收集器,作用于老年代,目标是低延迟,收集速度较快,基于标记-清除算法实现,会有内存碎片;
各垃圾收集器作用域及组合关系可参考下图:

2. G1收集器
2.1 G1收集器介绍
Garbage
First(G1)收集器是垃圾回收技术发展历史上里程碑式的成果,它开创了收集器面向局部收集的设计思路和基于Region的堆内存布局,自JDK7之后开始发布,到了JDK8
Update 40版本后,G1提供了类卸载的支持,这个版本的G1被Oracle称为全功能垃圾收集器(Fully-Featured
Garbage Collector)。G1主要面向服务端应用,自JDK9之后,G1取代了Parallel Old + Parallel
Old的组合,成为服务端模式下的默认垃圾收集器。也是自JDK9之后,CMS和Serial
Old被标记为废弃(Deprecate)状态而不再推荐使用。
经典的GC收集器将对内存按代划分,这种划代方式的内存在逻辑上是连续的。而G1垃圾收集器将堆内存按Region划分,回收的衡量标准不再是它属于哪个分代,而是哪块内存中存放的垃圾数量最多,回收收益最大,这就是G1收集器独有的Mixed GC模式。
2.2 G1收集器堆内存分布
G1收集器的堆内存布局可参考下图:
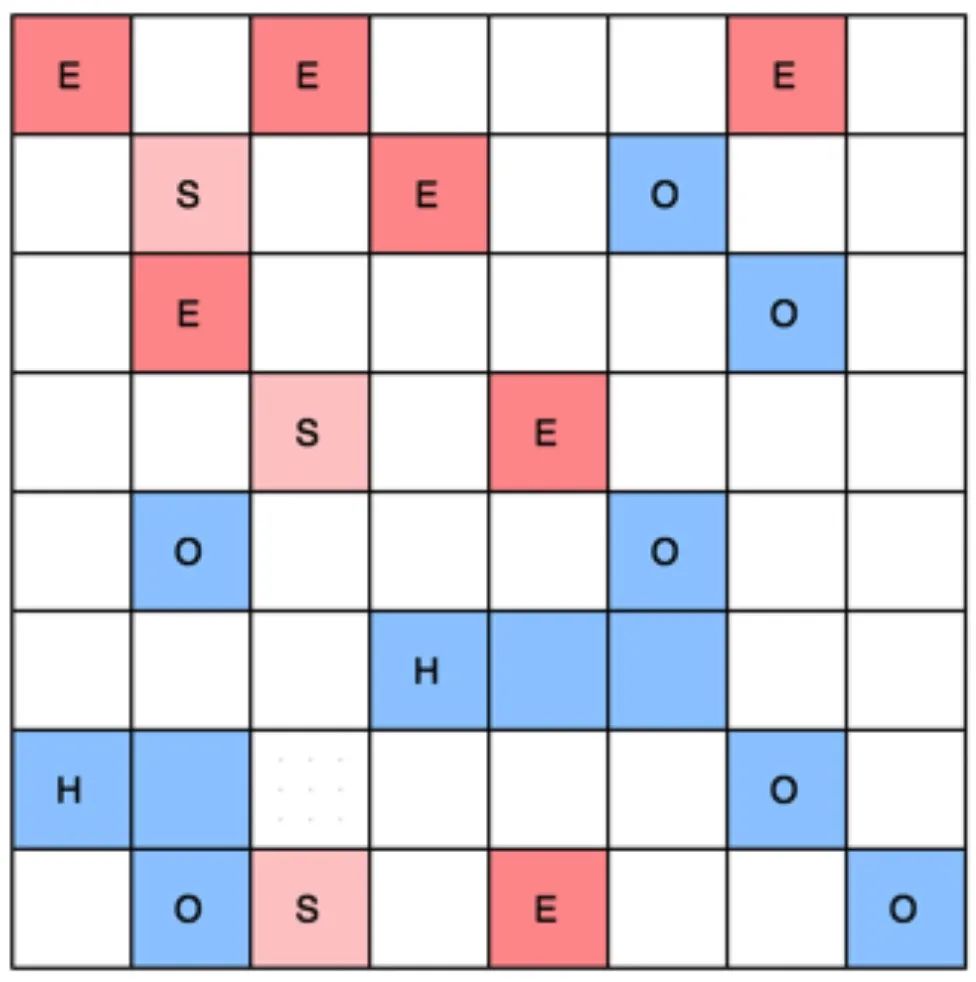
E,新生代Eden空间; S,新生代Survivor空间; O,老年代空间; H,Humongous区域,专门用来存储大对象;
G1其实也遵循了按代回收的理念,只是不再固定的分配各代的大小,而是把连续的堆划分为多个大小相等的独立空间(Region),每一个Region,可以根据需要,扮演新生代(Eden、Survivor)、老年代的角色。收集器能够对扮演不同角色的Region采用不同的策略去处理,这样无论是新对象还是老对象,熬过多次收集的旧对象都能够有较好的收集效果。G1中还有一类Humongous区域,G1认为大小大于等于Region一半的对象即可判定为大对象。对于超过1个Region容量的大对象,将会被存放在N个连续的H
Region之中,G1的大多数行为都把H Region作为来年代的一部分来看待。
每个Region的大小可通过参数-XX:G1HeapRegionSize设定,取值范围1~32MB,且应该为2的N次幂。
2.3 停顿预测模型
停顿预测模型(Pause
Prediction
Model)是指能够支持指定在一个长度为M的时间片段内,垃圾回收的时间不超过N的模型。G1的内存被划分为一系列不需要连续区域,即将Region作为单次回收的最小单元,每次垃圾回收到的空间都是Region大小的整数倍,这样可以有计划地避免在整个堆空间收集,也更容易控制垃圾回收时间。G1也会跟踪各个Region的价值大小,建立各个Region空间的优先级列表,已达到最大化的垃圾收集的收益。
那么如何建立可靠的停顿预测模型呢?用户在启动Java程序时可以通过-XX:MaxGCPauseMillis指定停顿时间的最大期望值,在垃圾收集过程中,G1收集每个Region的回收耗时,再根据历史数据的偏差、置信度等统计数据,由哪些Region组成的回收集合才能达到期望停顿值之内的最高收益。
// share/vm/gc_implementation/g1/g1CollectorPolicy.hpp
double get_new_prediction(TruncatedSeq* seq) {
return MAX2(seq->davg() + sigma() * seq->dsd(),
seq->davg() * confidence_factor(seq->num()));
}
在这个预测计算公式中:davg表示衰减均值,sigma()返回一个系数,表示信赖度,dsd表示衰减标准偏差,confidence_factor表示可信度相关系数。而方法的参数TruncateSeq,是一个截断的序列,它只跟踪了序列中的最新的n个元素。TruncateSeq(继承了AbsSeq)中,用来计算衰减均值、衰减变量,衰减标准偏差等:
// src/share/vm/utilities/numberSeq.cpp
void AbsSeq::add(double val) {
if (_num == 0) {
// if the sequence is empty, the davg is the same as the value
_davg = val;
// and the variance is 0
_dvariance = 0.0;
} else {
// otherwise, calculate both
_davg = (1.0 - _alpha) * val + _alpha * _davg;
double diff = val - _davg;
_dvariance = (1.0 - _alpha) * diff * diff + _alpha * _dvariance;
}
}
3. G1收集器运行过程
3.1 需要思考的问题
将Java堆按Region划分后,跨Region对象的引用怎么解决?G1的解决办法是每个Region维护自己的记忆集(Remembered
Set),可以看做一个哈希表,key是别的Region的地址,value是本地的索引,通过这种双向的结构,记录下“我指向谁”和“谁指向我”的问题。由于需要额外记录这些数据,G1比其他经典收集器多了很多内存占用。
在并发标记阶段如何保证收集线程和用户线程互不干扰的运行?如果GC线程标记对象时,用户线程改变了对象之间的引用关系,必须保证不能打破原有的对象依赖图结构,G1采用原始快照(SATB,Snapshot
At The
Begining)算法来实现,由字面理解,SATB是GC开始时活着的对象的一个快照。根据对象标记算法,把遍历对象图结构中遇到的对象,按照“是否被访问过”分为三种颜色:
白色,该对象未被垃圾收集器访问过,在可达性分析阶段结束后,若仍是白色,即代表对象不可达,会被当做垃圾收集掉; 黑色,对象已经被垃圾收集器访问过,且对象的所有引用也被扫描过了,它是安全存活的,因此黑色对象不可能指向白色对象; 灰色,表示对象已被垃圾收集器访问过,但这个对象还至少有一个引用还没有扫描过;
此时,若用户线程和GC线程并发工作,用户也要修改对象间的引用关系结构,这样就会产生两种后果:一种是把原本消亡的对象标记为存活;另一种是会把原本存活的对象标记为消亡。
SATB快照的存在,就可以让G1采用如下办法解决上述问题:当灰色对象要删除指向白色对象的引用关系时,就将这个要删除的引用记录下来,在并发扫描结束后,再以记录过的引用关系中的灰色对象为根,重新扫描一次,这样无论引用关系删除与否,都会按照最初的对象结构图进行搜索。虚拟机通过写屏障,实现操作记录的记录和修改,避免并发带来的问题。
G1垃圾收集器在收集过程中,此时若用户线程还在创建新对象,G1在每个Region中划出一部分空间用于垃圾收集过程中的新对象分配,而且在收集过程中,默认这块区域的对象都是存活的。
如果内存回收的速度赶不上内存分配的速度,G1收集器也要被迫冻结用户线程的执行,导致Full GC而产生较长时间的”Stop The World”。
3.2 垃圾回收过程
初始标记(Initial Marking),仅标记GC Roots能直接关联到的对象,这个阶段需要停顿线程,但耗时很短,借用进行Young GC的时候同步完成的,G1收集器在这个阶段没有额外的停顿; 并发标记(Concurrent Marking),从GC Root开始做可达性分析,扫描整个对象引用结构图,耗时较长,但是可与用户线程并发执行,扫描完成后,还要重新处理SATB记录下的并发时有引用修改的对象; 最终标记(Final Marking),此时用户线程也需要短暂暂停,用于处理并发标记结束后仍遗留的SATB记录; 筛选回收(Counting and Evacuation),更新Region数据,对Region的回收价值做优先级排序,根据用户期望时间值制定回收集合,然后把被回收的Region的存活对象复制到另一个空的Region区域,此阶段暂停所有用户线程;
从上收集过程可以看出,用户指定期望停顿时间是G1收集器很重要的参数,它会让G1收集器在吞吐量和延迟两个指标之间取一个平衡。因此设置合理的期望停顿时间是必要的,通常设置为100到200ms是比较合理的。
4. 应用及总结
4.1 G1使用
如果你的JDK是9及之后的版本,那会默认开启G1收集器,G1收集器其他相关的参数:
| 参数 | 含义 |
|---|---|
-XX:+UseG1GC | 使用G1收集器 |
-XX:MaxGCPauseMillis | 设置G1期望停顿时间,默认值200ms |
-XX:G1HeapRegionSize | 设置Region大小 |
-XX:ParallelGCThreads | STW时间并行的线程数 |
-XX:ConcGCThreads | 并发标记阶段的线程数 |
-XX:G1NewSizePercent | 新生代占比最小值,默认值5% |
-XX:G1MaxNewSizePercent | 新生代占比最大值,默认值60% |
4.2 G1总结
G1垃圾收集器,从整体上来说,以Region划分,可以看做是基于标记-整理实现,但从局部来说,两个Region之间又是采用标记-复制的算法,因此G1垃圾收集器不会产生内存碎片,收集完成后能提供较完整的可用内存。
G1收集器的内存停顿模型,把内存的期望停顿时间交给了程序员,对控制GC停顿时间可依据不同的业务模型、硬件
条件来合理的设置。
G1收集器的额外负载高,G1的记忆集可能会占到整个堆容量的20%甚至更多。另外G1对写屏障的复杂操作要比其他收集器消耗更多的运算资源。
5. 参考文档
Getting Started with the G1 Garbage Collector Garbage First Garbage Collector Java Hotspot G1 GC的一些关键技术 Java中9种常见的CMS GC问题分析与解决 Best practice for JVM Tuning with G1 GC Garbage Collectors – Serial vs. Parallel vs. CMS vs. G1
以上内容就是关于深入理解G1垃圾收集器的全部内容了,谢谢你阅读到了这里!