
NLP 的 不可能三角?
作者 | 太子长琴
整理 | NewBeeNLP
今天来看看 NLP 模型的不可能三角,并基于此一些未来的研究方向。
Paper: Impossible Triangle: What's Next for Pre-trained Language Models?[1]
PLM 的不可能三角指的是:
中等模型大小(1B以下) SOTA few-shot 能力 SOTA 微调能力
目前所有的 PLM 都缺其中一个或多个。很多注入知识蒸馏、数据增强、Prompt 的方法用以缓解这些缺失,但却在实际中带来了新的工作量。本文提供了一个未来的研究方向,将任务分解成几个关键阶段来实现不可能三角。
预训练模型已经广为人知,但人们并未在中小模型上发现 few-shot 甚至 zero-shot 的能力,大模型上的确有,但由于太大在实际使用时很不方便。而现实是很多时候我们没有过多标注数据,需要这种 few-shot 的能力。
不可能三角
如下图所示:
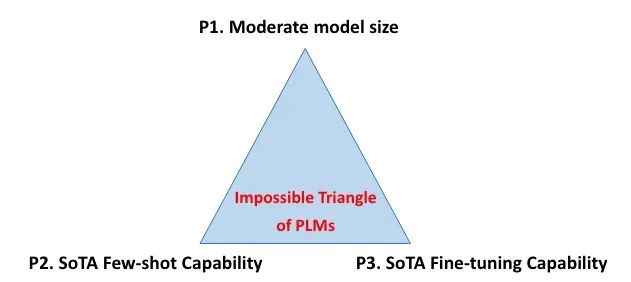
P1 用于使用合理的计算资源进行高效部署 P2 用于没有或少量标注数据场景 P3 用于相对大量标注数据场景
一个很好的证据是 Google 最近发表的 PaLM,论文发现,模型规模和 few/zero-shot 表现之间存在 不连续 的提升。比如说,与 8B 和 62B 的模型对比,PaLM 的 540B 在很多任务上表现出突破性的提升。
对于不可能三角,实际的 PLM 往往可以达到 1-2 个:
中等大小 PLM(1B以下):P1+P3 超大规模 PLM:P2。值得注意的是:zero/few-shot 的效果依然不如有监督;另外大部分微调后也不如中等大小 PLM 微调后的结果(原因很可能是模型太大)。
当前策略
对模型规模(缺 P1):
一般在超大模型显示出极好的 zero/few-shot 能力和微调后强大的性能时发生。 常用的方法是「知识蒸馏」。 有两个问题:学生模型几乎不能达到教师模型的效果;模型太大会阻碍有效推理,使其作为教师模型不方便。
对较差的 zero/few-shot 能力(缺 P2):
这是中等模型较为常见的:可以通过微调达到 SOTA,但 zero/few-shot 能力相对不足。 方法是「通过其他模型生成伪标签和样例,或噪声注入扩充数据」。 不过,伪数据质量的变化和不同任务中数据类型的多样性对普遍适用的解决方案提出了挑战。
对较差的有监督训练表现(缺 P3):
这在超大模型微调时很典型,其中计算资源有限或训练数据量不足以对其进行微调。 典型的策略是「Prompt 学习」,可以使用硬提示(离散文本模板)或软提示(连续模板),以便在微调期间仅更新硬提示词或软提示的参数。 不过,该方法对 Prompt 的选择和训练数据格外敏感,依然不如中等大小 PLM + 有监督。
未来方法
本文提出了一种多阶段的方法。
阶段 1:确定目标是实现一些(不可能三角中)需要的属性,改进缺失的属性。比如,SOTA 有监督的中等模型可以提高 few-shot 学习表现,SOTA few-shot 能力的大模型压缩到有更好有监督表现的小点的模型。 阶段 2:实现三个属性的 PLM 是为少数任务开发的。可以利用目标任务的独特特征,比如表现对训练数据规模依赖性较小,zero/few-shot 和有监督表现之间的 gap 较小等。 阶段 3:基于阶段 1 和阶段 2,在一般 NLP 任务上实现三个属性。可能的方法包括:用大量数据预训练一个中等大小的模型,更好的知识蒸馏,通用的数据增强方法等。
这篇文章虽然篇幅不长,但切入点还挺有意思,也分析了针对各属性的缓解策略:知识蒸馏、数据增强、Prompt 学习等,并基于此提出了未来的研究方向,其实看起来是很自然的想法。不过这个不可能三角的确有点意思。
本文参考资料
Impossible Triangle: What's Next for Pre-trained Language Models?: https://arxiv.org/abs/2204.06130
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码
评论