
独家|pytorch模型性能分析和优化

翻译:林立锟
校对:zrx
本文约6700字,建议阅读10分钟
本文介绍了pytorch模型性能分析和优化。

照片由 Torsten Dederichs 拍摄,上传到 Unsplash
训练深度学习模型,尤其是大型模型,可能是一笔昂贵的开支。性能优化是我们降低成本的主要方法之一。性能优化是一个迭代过程,在这个过程中,我们不断寻找提高应用程序性能的机会并加以利用。在以前的文章中,我们强调过使用适当工具进行分析的重要性。工具的选择可能取决于多种因素,包括训练加速器的类型(如GPU、HPU 或其他)和训练框架。

性能优化流程(来自作者)
这篇文章的重点是在 GPU 上使用 PyTorch 进行训练。具体地说,我们将关注PyTorch内置性能分析器、 PyTorch Profiler 以及查看其结果的方法之一,即 PyTorch Profiler TensorBoard 插件。
这篇文章并不是要取代关于PyTorch Profiler 或使用 TensorBoard 插件分析剖析器结果的PyTorch官方文档。我们的目的是演示如何在日常开发过程中使用这些工具。事实上,如果您还没有阅读过官方文档,我们建议您在阅读这篇文章之前先阅读一下官方文档。
一段时间以来,我一直对 TensorBoard-plugin 教程感兴趣。该教程介绍了一个基于 Resnet 架构的分类模型,该模型是在流行的Cifar10 数据集上训练的。接下来,它将演示如何使用PyTorch Profiler 和 TensorBoard 插件来识别和修复数据加载器的瓶颈。输入数据管道中的性能瓶颈并不罕见,我们在以前的一些文章中已经详细讨论过。教程中令人惊讶的是最终(优化后)结果(截至本文撰写时),我们将其粘贴在下面:
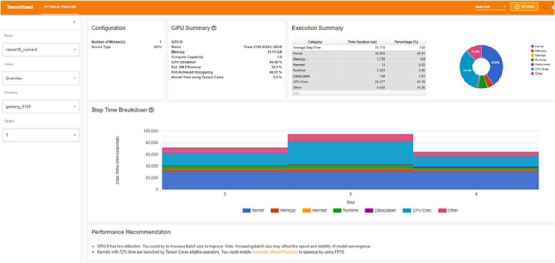
优化后的性能(摘自 PyTorch 网站)
如果仔细观察,你会发现优化后的 GPU 利用率为 40.46%。现在,没有任何办法来粉饰这一点:这些结果绝对惨不忍睹,应该让你彻夜难眠。正如我们在过去所阐述的, GPU 是训练机中最昂贵的资源,我们的目标应该是最大限度地提高其利用率。40.46% 的利用率通常代表着训练加速和成本节约的重要机会。当然,我们可以做得更好!在本博文中,我们将尝试做得更好。首先,我们将尝试重现官方教程中介绍的结果,看看能否使用相同的工具进一步提高训练性能。
简单示例
下面的代码块包含由 TensorBoard-plugin 教程中定义的训练循环,并做了两处小修改:
我们使用了一个假数据集,其属性和行为与教程中使用的 CIFAR10 数据集相同。这一改变的动机可在此处找到。
我们初始化 我们初始化初始化时,预热标志设置为 3,重复标志设置为 1。我们发现,热身步骤数的轻微增加提高了结果的稳定性。
import numpy as npimport torchimport torch.nnimport torch.optimimport torch.profilerimport torch.utils.dataimport torchvision.datasetsimport torchvision.modelsimport torchvision.transforms as Tfrom torchvision.datasets.vision import VisionDatasetfrom PIL import Imageclass FakeCIFAR(VisionDataset):def __init__(self, transform):super().__init__(root=None, transform=transform)self.data = np.random.randint(low=0,high=256,size=(1,000,032,323),dtype=np.uint8)self.targets = np.random.randint(low=0,high=10,size=(10000),dtype=np.uint8).tolist()def __getitem__(self, index):img, target = self.data[index], self.targets[index]img = Image.fromarray(img)if self.transform is not None:img = self.transform(img)return img, targetdef __len__(self) -> int:return len(self.data)transform = T.Compose([T.Resize(224),T.ToTensor(),T.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])train_set = FakeCIFAR(transform=transform)train_loader = torch.utils.data.DataLoader(train_set, batch_size=32,shuffle=True)device = torch.device("cuda:0")model = torchvision.models.resnet18(weights='IMAGENET1K_V1').cuda(device)criterion = torch.nn.CrossEntropyLoss().cuda(device)optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)model.train()# train stepdef train(data):inputs, labels = data[0].to(device=device), data[1].to(device=device)outputs = model(inputs)loss = criterion(outputs, labels)optimizer.zero_grad()loss.backward()optimizer.step()# training loop wrapped with profiler objectwith torch.profiler.profile(schedule=torch.profiler.schedule(wait=1, warmup=4, active=3, repeat=1),on_trace_ready=torch.profiler.tensorboard_trace_handler('./log/resnet18'),record_shapes=True,profile_memory=True,with_stack=True) as prof:for step, batch_data in enumerate(train_loader):if step >= (1 + 4 + 3) * 1:breaktrain(batch_data)prof.step() # Need to call this at the end of each step
教程中使用的 GPU 是 Tesla V100-DGXS-32GB。在这篇文章中,我们尝试使用包含 Tesla V100-SXM2-16GB GPU 的Amazon EC2 p3.2xlarge 实例重现并改进教程中的性能结果。虽然它们采用相同的架构,但这两种 GPU 之间存在一些差异。您可以在此处了解这些差异。我们使用 AWS PyTorch 2.0 Docker 映像运行了训练脚本。训练脚本的性能结果显示在TensorBoard 查看器的预览页面中,如下图所示:
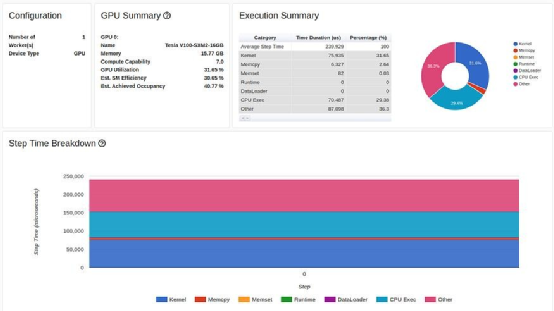
TensorBoard Profiler 概述选项卡中显示的基线性能结果(作者截图)
首先,我们注意到,与教程相反,我们实验中的概述页面(torrent-tb-profiler 0.4.1 版)将三个步骤合并为一个。因此,整个步骤的平均时间是 80 毫秒,而不是报告中的 240 毫秒。从跟踪选项卡(根据我们的经验,跟踪选项卡几乎总能提供更准确的报告)中可以清楚地看到这一点,其中每个步骤耗时约为80毫秒。
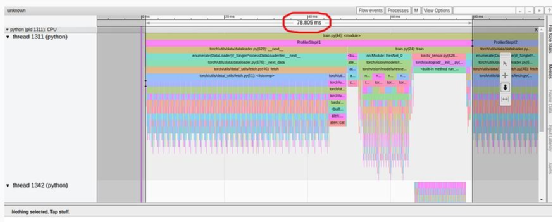
TensorBoard Profiler 跟踪视图选项卡中显示的基线性能结果(作者截图)
请注意,我们的起点(31.65% 的 GPU 利用率和 80 毫秒的步进时间)与教程中介绍的起点(分别为 23.54% 和 132 毫秒)有所不同。这可能是包括 GPU 类型和 PyTorch 版本在内的训练环境不同造成的。我们还注意到,教程的基线结果将性能问题明确诊断为数据加载器的瓶颈,而我们的结果并非如此。我们经常发现,数据加载瓶颈会伪装成 "概览 "选项卡中"CPU 执行 "或 "其他 "的高百分比。
优化 #1:多进程数据加载
首先,让我们按照教程中的描述使用多进程数据加载。鉴于Amazon EC2 p3.2xlarge 实例有 8 个 vCPU,我们将数据加载器工作者的数量设置为 8,以获得最高性能:
train_loader = torch.utils.data.DataLoader(train_set, batch_size=32,shuffle=True, num_workers=8)
优化结果如下:
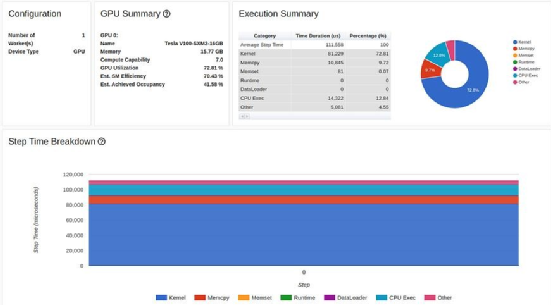 |
TensorBoard Profiler 概述选项卡中的多进程数据加载结果(作者截图)
只需修改一行代码,GPU 利用率就提高了 200% 以上(从31.65% 提高到 72.81%),训练步骤时间缩短了一半以上(从80 毫秒缩短到 37 毫秒)。
教程中的优化过程到此为止。虽然我们的 GPU 利用率(72.81%)比教程中的结果(40.46%)高出不少,但我毫不怀疑,你也会像我们一样,觉得这些结果仍不尽如人意。
作者评论:试想一下,如果 PyTorch 在 GPU 上训练时默认应用多进程数据加载,那么全球可以节省多少钱?诚然,使用多进程可能会有一些不必要的副作用。不过,一定有某种形式的自动检测算法可以运行,以排除潜在的问题场景,并相应地应用这种优化。
优化#2:固定内存
如果我们分析一下上次实验的跟踪视图,就会发现大量时间(37 毫秒中的 10 毫秒)仍然花在将训练数据加载到 GPU上。
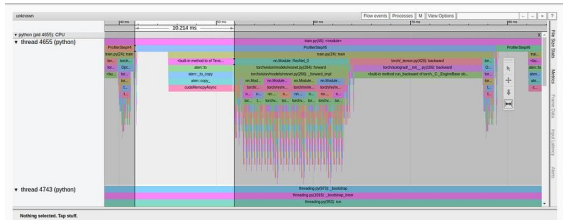
跟踪视图选项卡中的多进程数据加载结果(作者截图)
为了解决这个问题,我们将应用 PyTorch 推荐的另一种优化方法来简化数据输入流,即固定内存。使用固定内存可以提高主机到 GPU 数据拷贝的速度,更重要的是,我们可以将它们异步化。这意味着我们可以在 GPU 中准备下一个训练批次,同时在当前批次上进行训练。要注意的是,虽然异步化处理可以优化性能,但他可能会降低时间测量的精度。在本博文中,我们将继续使用 PyTorch Profiler 报告的测量结果。更多详情以及固定内存的潜在副作用,有关如何精确测量的说明,请参见此处。请参阅 PyTorch 文档。
这一优化需要修改两行代码。首先,我们在数据加载器中把pinn_memory置为 True。
train_loader = torch.utils.data.DataLoader(train_set, batch_size=32,shuffle=True, num_workers=8, pin_memory=True)
然后,我们将主机到设备的内存传输(在训练函数中)修改为non-blocking:
inputs, labels = data[0].to(device=device, non_blocking=True), \data[1].to(device=device, non_blocking=True)
固定内存优化后的结果显示如下: |
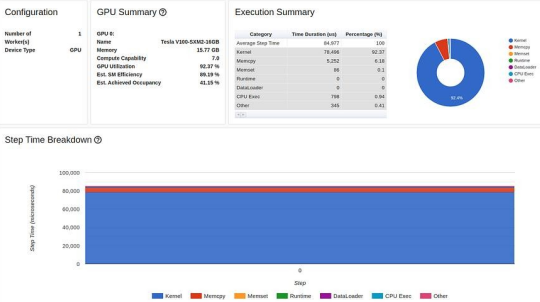
TensorBoard Profiler 概述选项卡中的固定内存结果(作者截图)
现在,我们的 GPU 利用率达到了 92.37%,步进时间进一步缩短。但我们还可以做得更好。请注意,尽管进行了优化,但性能报告仍然显示我们在将数据复制到 GPU 上花费了大量时间。我们将在下文第 4 步中再次讨论这个问题。
优化 #3:增加batch大小
在下一步优化中,我们将关注上次实验中的 "内存视图":
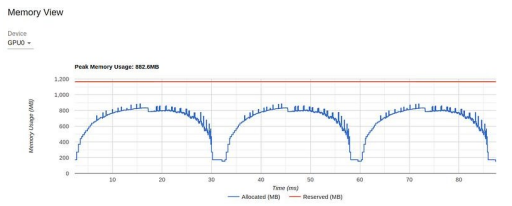
TensorBoard Profiler 中的内存视图(由作者截图)
图表显示,在 16 GB 的 GPU 内存中,我们的峰值利用率不到1 GB。这是一个资源利用率不足的极端例子,通常(但不总是)表明有机会提高性能。控制内存利用率的方法之一是增加批次大小。在下图中,我们显示了当批处理大小增加到 512(内存利用率增加到 11.3 GB)时的性能结果。
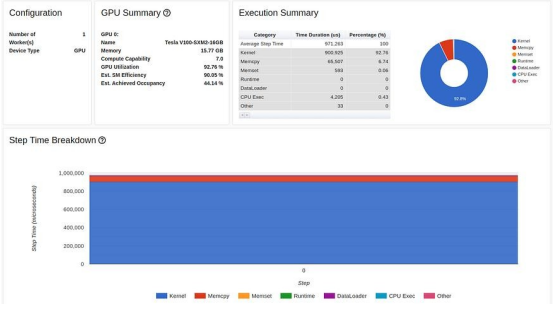
在 TensorBoard Profiler 概述选项卡中增加批次大小的结果(作者截图)
虽然GPU 利用率没有太大变化,但我们的训练速度却大幅提高,从每秒 1200 个样本(批量大小为 32 时为 46 毫秒)提高到每秒 1584 个样本(批量大小为 512 时为 324 毫秒)。
注意:与我们之前的优化相反,增加批次大小可能会对训练应用程序的行为产生影响。不同的模型对批量大小变化的敏感程度不同。有些模型可能只需要对优化设置进行一些调整。而对于其他模型,调整到大的批次规模可能会更加困难,甚至不可能。请参阅上一篇文章,了解大批量训练所面临的一些挑战。
优化 #4:减少主机到设备的复制
您可能注意到了,在我们之前的结果中,饼状图中代表主机到设备数据拷贝的红色大块。要解决这种瓶颈,最直接的方法就是看能否减少每批数据的数量。请注意,在图像输入的情况下,我们将数据类型从 8位无符号整数转换为 32 位浮点数,并在执行数据复制之前进行归一化处理。在下面的代码块中,我们建议对输入数据流进行修改,将数据类型转换和归一化推迟到数据进入 GPU 后进行:
# maintain the image input as an 8-bit uint8 tensortransform = T.Compose([T.Resize(224),T.PILToTensor()])train_set = FakeCIFAR(transform=transform)train_loader = torch.utils.data.DataLoader(train_set, batch_size=1024, shuffle=True, num_workers=8, pin_memory=True)device = torch.device("cuda:0")model = torch.compile(torchvision.models.resnet18(weights='IMAGENET1K_V1').cuda(device), fullgraph=True)criterion = torch.nn.CrossEntropyLoss().cuda(device)optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)model.train()# train stepdef train(data):inputs, labels = data[0].to(device=device, non_blocking=True), \data[1].to(device=device, non_blocking=True)# convert to float32 and normalizeinputs = (inputs.to(torch.float32) / 255. - 0.5) / 0.5outputs = model(inputs)loss = criterion(outputs, labels)optimizer.zero_grad()loss.backward()optimizer.step()
由于这一改变,从 CPU 复制到 GPU 的数据量减少了 4 倍, 碍眼的红色块也几乎消失了:
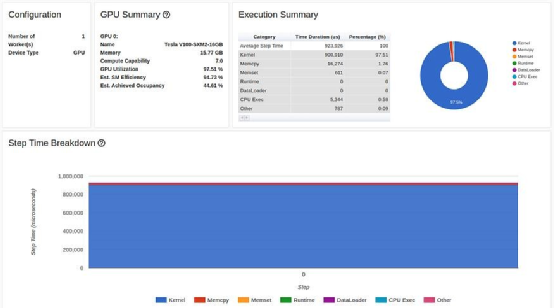
在 TensorBoard Profiler 概述选项卡中减少 CPU 到 GPU 副本的结果(作者截图)
现在,我们的 GPU 利用率达到了 97.51%(!!)的新高,训练速度达到了每秒 1670 个采样点!让我们看看我们还能做些什么。
优化 #5:将梯度设置为无
现阶段我们似乎已经充分利用了 GPU,但这并不意味着我们不能更有效地利用它。据说有一种流行的优化方法可以减少 GPU 中的内存操作,那就是在每个训练步骤中将模型参数梯度设置为 "无 "而不是零。请参阅 PyTorch 文档了解有关该优化的更多详情。要实现这一优化,只需将 optimizer.zero_grad 调用的 set_too_none 设置为 True:
optimizer.zero_grad(set_to_none=True)在我们的例子中,这种优化并没有在提高我们的性能方面有意义。
优化 #6:自动混合精度
GPU 内核视图显示 GPU 内核的活动时间,是提高 GPU 利用率的有用资源:
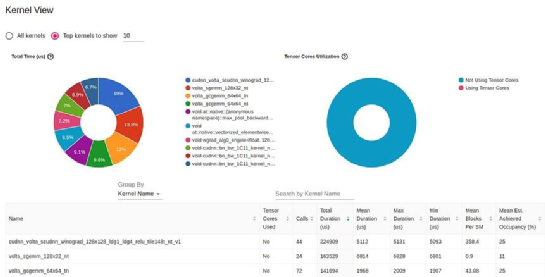
TensorBoard Profiler 中的内核视图(由作者捕获)
这份报告中最明显的一个细节是没有使用 GPU Tensors Corses。Tensor Cores,是矩阵乘法的专用处理单元,且可用于较新的 GPU 架构,它可显著提升人工智能应用的性能。缺乏使用张量核意味着这可能是一个重大的优化机会。
由于张量核是专为混合精度计算而设计的,因此提高其利用率的一个直接方法就是修改我们的模型,使其使用自动混合精度(AMP)。在 AMP 模式下,模型的部分内容会自动转换为精度较低的 16 位浮点数,并在 GPU 张量核上运行。
重要的是,请注意 AMP 的全面实施可能需要梯度缩放,而我们的演示并不包括这一点。在调整之前,请务必查看混合精度训练的相关文档。
下面码块演示了为启用 AMP 而对训练步骤进行的修改。
def train(data):inputs, labels = data[0].to(device=device, non_blocking=True), \data[1].to(device=device, non_blocking=True)inputs = (inputs.to(torch.float32) / 255. - 0.5) / 0.5with torch.autocast(device_type='cuda', dtype=torch.float16):outputs = model(inputs)loss = criterion(outputs, labels)# Note - torch.cuda.amp.GradScaler() may be requiredoptimizer.zero_grad(set_to_none=True)loss.backward()optimizer.step()
下图显示了对“张量核心”利用率的影响。虽然它继续表明还有进一步改进的机会,但仅凭一行代码,
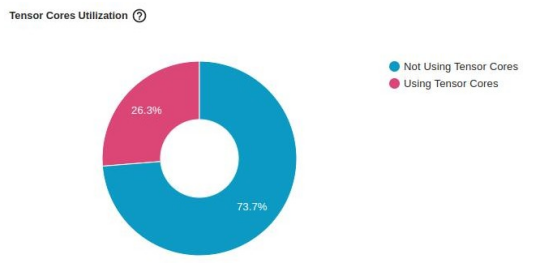
利用率就从 0% 跃升至26.3%。
TensorBoard Profiler 内核视图中使用 AMP 优化的张量核利用率(作者截图)
除了提高张量核心利用率外,使用 AMP 还能降低 GPU 内存利用率,从而腾出更多空间来增加批次大小。下图展示了 AMP 优化后的训练性能结果,其中批量大小设置为 1024:
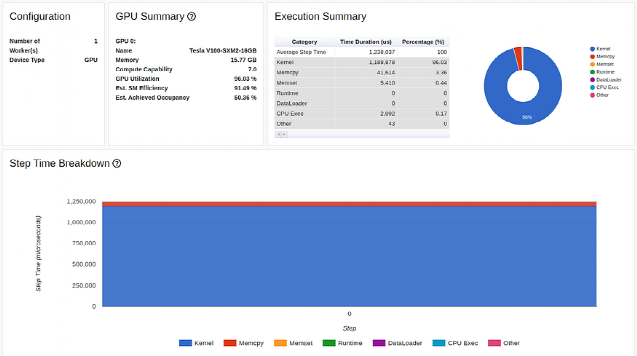
TensorBoard Profiler 概述选项卡中的 AMP 优化结果(作者截图)
虽然 GPU 利用率略有下降,但我们的主要吞吐量指标却进一步提高了近 50%,从每秒 1670 个样本提高到 2477 个。我们的优化正在发挥作用!
注意:降低部分模型的精度可能会对其收敛性产生重大影响。与增加批量大小的情况一样(见上文),使用混合精度的影响因模型而异。在某些情况下,使用 AMP 几乎基本不会改变2。其他情况下,您可能需要花更多精力来调整autoscaler。还有一些时候,您可能需要明确设置模型不同部分的精度类型(即手动混合精度)。
有关使用混合精度作为内存优化方法的更多详情,请参阅我们之前的相关博文。
优化 #7:在图形模式下进行训练
我们将应用的最后一项优化是模型编译。与 PyTorch 默认的急切执行模式(每个 PyTorch 操作都会 "急切地 "运行)相反, 编译 API 会将你的模型转换成中间计算图,然后以对底层训练加速器最优的方式编译成底层计算内核。有关 PyTorch 2 中模型编译的更多信息,请查看我们之前发布的相关文章。
以下代码块演示了应用模型编译所需的更改:
model = torchvision.models.resnet18(weights='IMAGENET1K_V1').cuda(device)model = torch.compile(model)
模型编译优化的结果显示如下:

TensorBoard Profiler 概述选项卡中的图形编译结果(作者截图)
模型编译将我们的吞吐量进一步提高到每秒 3268 个采样点,而之前实验中为每秒 2477 个采样点,性能提高了 32%(!!)。
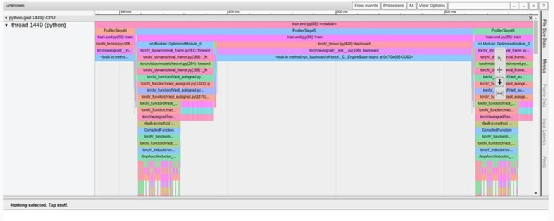
图形编译改变训练步骤的方式在 TensorBoard 插件的不同视图中非常明显。例如,"内核视图 "显示使用了新的(融合的) GPU 内核,而 "跟踪视图"(如下图所示)显示的模式与我们之前看到的完全不同。
TensorBoard Profiler 跟踪视图选项卡中的图形编译结果(作者截图)
临时成果
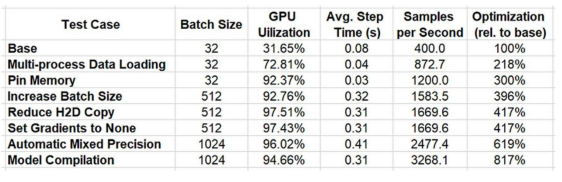
我们在下表中总结了一系列优化的结果。
性能结果总结(作者)
通过使用 PyTorch Profiler 和 TensorBoard 插件进行迭代分析和优化,我们将性能提高了 817%!
我们的工作完成了吗?绝对没有!我们实施的每一次优化都会发现新的潜在性能改进机会。这些机会以释放资源的形式出现(例如,转向混合精度使我们能够增加批量大小),或者以新发现的性能瓶颈的形式出现(例如,我们的最终优化发现了主机到设备数据传输的瓶颈)。此外,还有许多其他众所周知的优化形式,我们在本篇文章中并未尝试(例如,请参见此处和此处)。最后,新的优化库(例如我们在第 7 步中演示的模型编译功能)不断发布,进一步实现了我们的性能提升目标。正如我们在导言中强调的,要充分利用这些机会,性能优化必须成为开发工作流程中迭代和持续的一部分。
总结
在这篇文章中,我们展示了简单模型性能优化的巨大潜力。虽然您还可以使用其他性能分析器,它们各有利弊,但我们还是选择了 PyTorch Profiler 和 TensorBoard 插件,因为它们易于集成。
我们需要强调的是,根据培训项目的具体情况,包括模型结构和训练环境,成功优化的途径会有很大不同。在实践中,实现目标可能比我们在这里介绍的例子更加困难。我们介绍的某些技术可能对性能影响甚微,甚至会使性能下降。我们还注意到,我们所选择的精确优化方法以及应用它们的顺序有些随意。我们强烈建议您根据自己项目的具体细节开发自己的工具和技术,以实现优化目标。
机器学习工作负载的性能优化有时被视为次要的、非关键的和令人厌烦的。我希望我们能够成功地说服您,节省开发时间和成本的潜力值得您在性能分析和优化进行投入。而且,嘿嘿,您甚至可能会觉得这很有趣:)。
下一个是?
这只是冰山一角。性能优化的内容远不止这些。在本篇文章的续篇中,我们将深入探讨 PyTorch 模型中非常常见的一个性能问题,即在 CPU 而不是 GPU 上运行了过多的计算量,而开发者往往对此并不知情。我们还鼓励您查看我们在 medium 上发布的其他文章,其中很多都涉及机器学习工作负载性能优化的不同要素。
原文标题:
PyTorch Model Performance Analysis and Optimization
原文链接:
PyTorch Model Performance Analysis and Optimization | by Chaim Rand | Towards Data Science
编辑:王菁
校对:林亦霖
译者简介
作者简介
林立锟,香港城市大学计算数学本科,数据科学爱好者,对数学和计算机特别感兴趣,尤其是两者的结合部分特别感兴趣。兴趣是打羽毛球,以及琢磨一些奇奇怪怪的学习工具。希望能够通过自己的努力,将一些更优质的文章,更有价值的内容分享给读者,让大家在学习数据科学时能够更加顺利!
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。
点击“阅读原文”拥抱组织