
从另外一个角度看什么是数据库
本文公众号来源:柳树的絮叨叨
作者:SexyCode
数据库是什么?
是 Mysql?Oracle?HBase?
或许你还能想到 Redis、Zookeeper,甚至是 Elasticsearch ……
让我们从一个文件系统开始。
数据库 1.0 —— 文件系统
我们正在做一个电子书的小程序。
一开始,我们把所有图书信息都放在 csv 文件中:
Book.csv ( title , author , year )
"Gone with the Wind","Margaret Mitchell",1936"Hamlet","William Shakespeare",1602"活着","余华",1993"三体","刘慈欣",2006
这种存储方式,实现起来简单,似乎很完美。
接下来,我们要查询《三体》的作者,于是写了这段代码:
for line in file:record = parse(line)if "三体" == record[0]:print record[1]
我们用了「遍历」,这是非常糟糕的查询方式。
一旦后面数据量上去了,数据被存放在多个文件里,每次查询,我们就得打开很多个文件,打开后还要遍历里面的数据,「磁盘 IO」 和「时间复杂度」都很高。
问题症结在于:我们的数据,是没有无规律的。
一旦数据没有规律,我们查找数据时,就不知道数据在哪个文件,就只能一个个文件打开来看,靠蛮力去遍历。
所以,让数据规律存储,是优化这个文件系统的第一步。
数据库 2.0 —— 规律存储
让数据有规律的存储,一旦数据有规律,我们就可以使用各种算法去高效地查找它们。
让书籍,按照「字典排序」升序存储,于是我们可以进行「二分查找」,时间复杂度从 O(n) -> O(log2n),缺点是每次插入都要排序;
让书籍,按照「Hash 表」的结构进行存储,于是我们可以进行「Hash 查找」,用空间换时间,时间复杂度 O(1);
让书籍,按照「二叉树」的结果进行存储,于是我们可以进行「二叉查找」,时间复杂度 O(log2n);
二叉树极端情况下会退化成 O(n),于是有了「平衡二叉树」;
平衡二叉树终究还是“二叉”,只有两个子节点,一次从磁盘 load 的数据太少,于是有了可以有多于 2 个子节点的 B 树;
B 树找出来的数据,是无序的,如果你要求数据排好序返回,还要在内存手动排一次序,于是有了叶子节点是一个双向链表的 B+ 树;
……
看到没,不断规律化你的存储结构,你就能得到越来越牛逼的查找性能。
当然你会发现,按照「作者」查询,我建一个 B+ 树,按照「年份」查询,我也建一个 B+ 树,这样每增加一个字段查询,我都要建一个 B+ 树,如果 B+ 树里面放的是全部数据的信息,那会很冗余、很占用空间;
于是我让 B+ 树只记录数据的唯一标识,按照索引找到数据的唯一标识后,再去 load 全量的数据。
这就是 Mysql 里面的「二级索引」和「聚簇索引」:
「二级索引」只存储对应字段和唯一标识,查找时利用「二级索引」,可以快速找到数据的「唯一标识」;
「聚簇索引」是数据实际存储的位置,它也是有序的,按照「唯一标识」有序存储;
所以你在「二级索引」里拿到「唯一标识」后,可以快速地在「聚簇索引」找到数据的位置,大大减少了磁盘 IO;
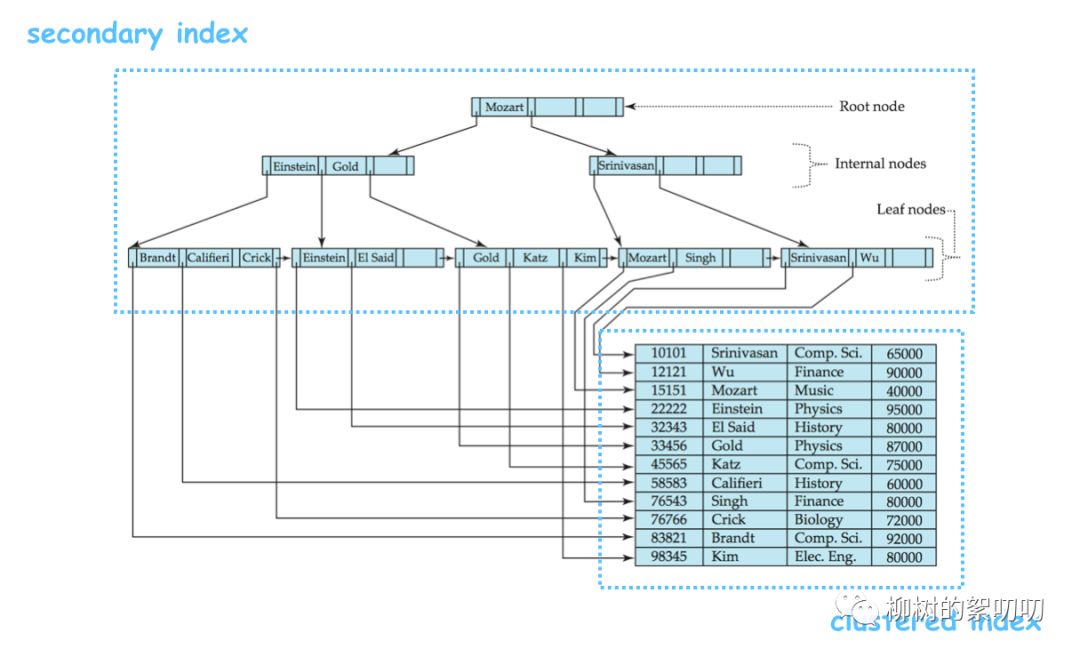
Mysql 有一句话,“索引即数据”,指的就是「聚簇索引」,当然,如果用到了「覆盖索引」,那「二级索引」也能提供数据。
我们经常说,「索引」提高了查找性能,其实不完全正确。
还是以 Mysql 为例,二级索引只是告诉了你数据的「唯一标识」,但是你还要拿着这个「唯一标识」去数据里查找,如果这些数据本身不是有序的,那你还是得找大半天。于是 Mysql 再弄了个 B+ 树来存储数据,让这些数据有序,也就是「聚簇索引」。
这就像你在字典里查一个单词 incredible ,你在目录,也就是索引里,找到这个单词在第 256 页,然而,这本书在装订的时候,页面订乱了,不是按递增来装订的,完全无序,于是乎,就算你知道了 incredible 在第 256 页,你还是得海底捞针般的,把整本书翻一遍。
「索引」仅仅帮助你快速找到数据的标识,辅之以「数据规律的存储」,才能「减少磁盘 IO」,才能「加速查询」:
索引 + 规律存储 = 快速查询
不过对于 Mysql 来说,它的规律存储,是通过「聚簇索引」来实现的,所以说是「索引」让它查询变快也对。
数据结构带来了规律存储和快速查询,也带来了操作的复杂度。
你再也不能随意插入数据,因为你要维护数据的规律性,不管你是顺序存储还是 B+ 树,都要找到正确的位置进行插入;
可能你还想做个缓存来进一步减少磁盘 IO,那你得维护好缓存的生命周期,等等 ……
这么多复杂的逻辑,如果都要让用户感知到,自己手动操作,那使用成本太高,每次插入都要写一大段代码,于是我们要给用户提供简洁的操作方式。
数据库 3.0 —— 简单操控
几乎你用过的所有数据库,都会提供让你很方便的操控它的方式。
像 Mysql、Oracle 等关系型数据库,操作它们的语言,都是 SQL(Structured Query Language,结构化查询语言),这是结构化数据领域的通用语言,于是我们称之为 DSL(domain-specific language,领域特定语言):
INSERT INTO Customer (FirstName, LastName, City, Country, Phone)
VALUES (‘Craig’, ‘Smith’, ‘New York’, ‘USA’, 1-01-993 2800)
而像 redis,它也定义了自己的一套语言,但是它比较谦虚,自称为 Command :
redis> SET mykey “Hello” “OK” redis> GET mykey “Hello”
也有像 Elasticsearch 一样直接提供 Restful API 的:
curl -X GET “localhost:9200/twitter/_doc/0?_source=false&pretty”
DSL、Command、API,其实都是为了方便你使用,降低了你的使用成本,不至于插入个数据,都要写一堆代码。
但是对于你的学习成本,却不一定降低了,反之,可能加大了你的学习成本,因为它屏蔽了背后的实现细节。
看似简简单单的语句背后,触发的可能是一连串复杂的逻辑。
数据库 4.0 —— 隐藏技能
这些复杂的逻辑,就是数据库的隐藏技能。
一个数据库在隐藏技能上下的功夫,决定了它是 Mysql,还是 Microsoft Access,决定了它能在高性能高可靠的道路上走多远,决定了它能否被广泛用到生产环境。
而对一个数据库隐藏技能了解的程度,也成了衡量一个人对这项知识掌握程度的标准。
在你一行指令的背后,触发的隐藏技能,包括但不限于:
事务:事务具有四个属性:ACID,当然数据库不会完全满足这四个属性,有的数据库甚至还不支持事务,比如 Mysql 在 「读未提交」的隔离级别下,就不满足「C 隔离性」,对数据可靠性要求不高的,比如 redis,它也无需实现事务(当然你可以用各种方法来近似实现)。
锁:和 Java 一样,有并发访问,就有并发安全,就需要锁,比如 Mysql 的 MVCC.
集群:这是实现一个高性能高可靠系统的标配,你需要对数据进行冗余和分片存储,所以,在插入一条数据时,你的数据库可能需要判断要插入到哪一台机器,插入后,还有判断要冗余到哪些个机器。
缓存:数据不能每次都去磁盘 load,放到缓存,缓存失效了再去磁盘拿,数据一旦被更新,缓存就失效吗?不,数据更新时,更新的是缓存的数据,同时记录日志,然后再去刷磁盘,Mysql 和 Elasticsearch 都这么做。
……
上文从「文件系统」开始,一步一步演化成一个常用的「数据库」。
这里我用「三个关键字」 + 「三句话」,来给「数据库」下一个演进式的、通俗易懂的定义:
规律存储的文件系统:数据库,是一个把数据进行「规律存储」的文件系统;
简单访问:它给使用者提供了简单的操控方式,去访问(插入、修改、查询)它的数据;
隐藏技能:为了做到高性能高可靠,它实现了一系列复杂的逻辑,这些逻辑对一般使用者来说无需关心。
我们再来看看维基百科上给「Database」和「DBMS」的定义:
Database
A database is an organized collection of data, generally stored and accessed electronically from a computer system. Where databases are more complex they are often developed using formal design and modeling techniques.
Database management system
Connolly and Begg define Database Management System (DBMS) as a “software system that enables users to define, create, maintain and control access to the database”
这是学术上的定义。
学术定义,目的是「给一个通用的解释」,「划定边界」,所以一般会比较抽象。
它告诉你:
数据库是数据的有组织的集合,用到了一些设计和技巧;
数据库管理系统(DBMS),则是给你去访问数据库的;
它不会告诉你数据库具体怎么组织,用到怎么个技巧,也不会告诉你 DBMS 是怎么去访问数据库的,因为它只是一个「通用的解释」,只是给「Database」和「DBMS」划定边界。
所以只看定义,是看不出什么的,只有学习了具体的知识,然后再反过来看定义,才能看懂、看透,才能摸索出通用的规律。
你会发现,通常我们在聊「数据库」时,聊得不只是个普通的数据,而是规律存储的数据,而且还有一个 DBMS,让我们去访问它:
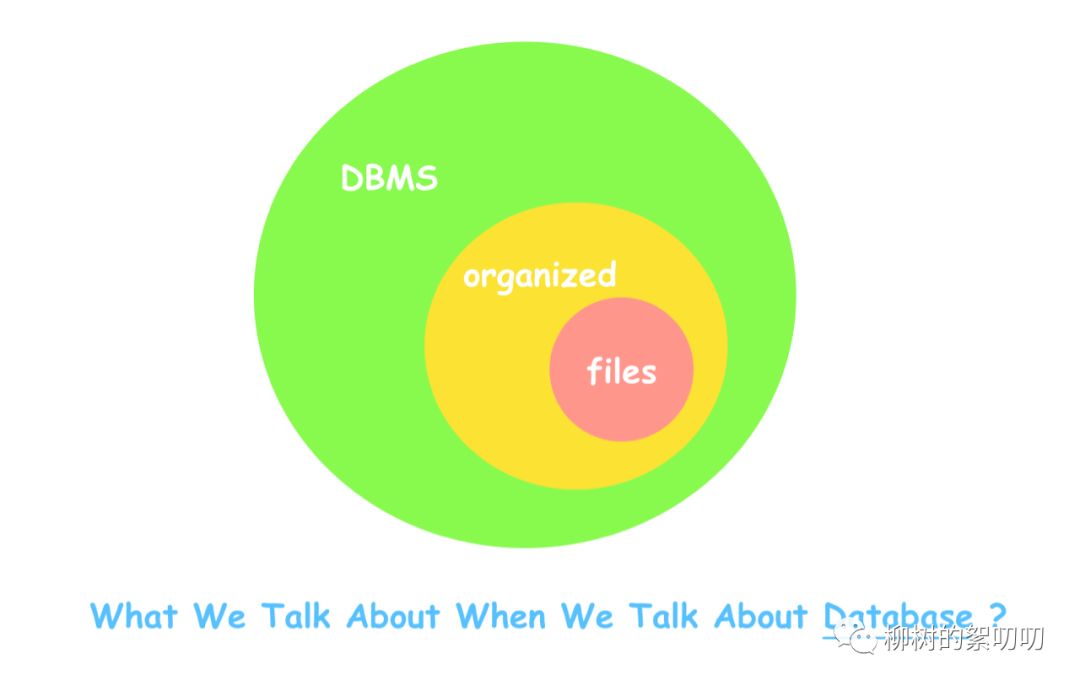
数据库,是你和数据打交道的媒介,你的所有对数据的操作,都会通过「数据库」来实现。
于是,从「使用角度」,我再给数据库下另一个通俗的定义:
数据库,是你访问数据的中间件。
选择哪个中间件,取决于你的使用场景;而选择哪种数据库,则取决于你对数据的使用场景:
如果你需要数据安全可靠,最好是用 Mysql 这样的关系型数据库;
如果你只是缓存一些临时数据,需要快速查询,不妨用 Redis 这样的 Key-Value 内存数据库;
如果你想放一些文档,并且还可以支持「相关性搜索」,那像 Elasticsearch 这样的搜索引擎,则是你的首选。
接上面一节给数据库下的定义,我尝试给数据库学习分三个层级:
接触:了解这个数据库的使用场景,为什么需要它,在什么场合下使用它
使用:如何通过这个数据库操控数据,了解它的 API/Command/DSL
深入理解:它是如何存储和索引数据的?它是如何做集群和分布式的?还有什么其他让它高性能高可靠的隐藏技能?
随便找几个数据库验证上面的学习模型:
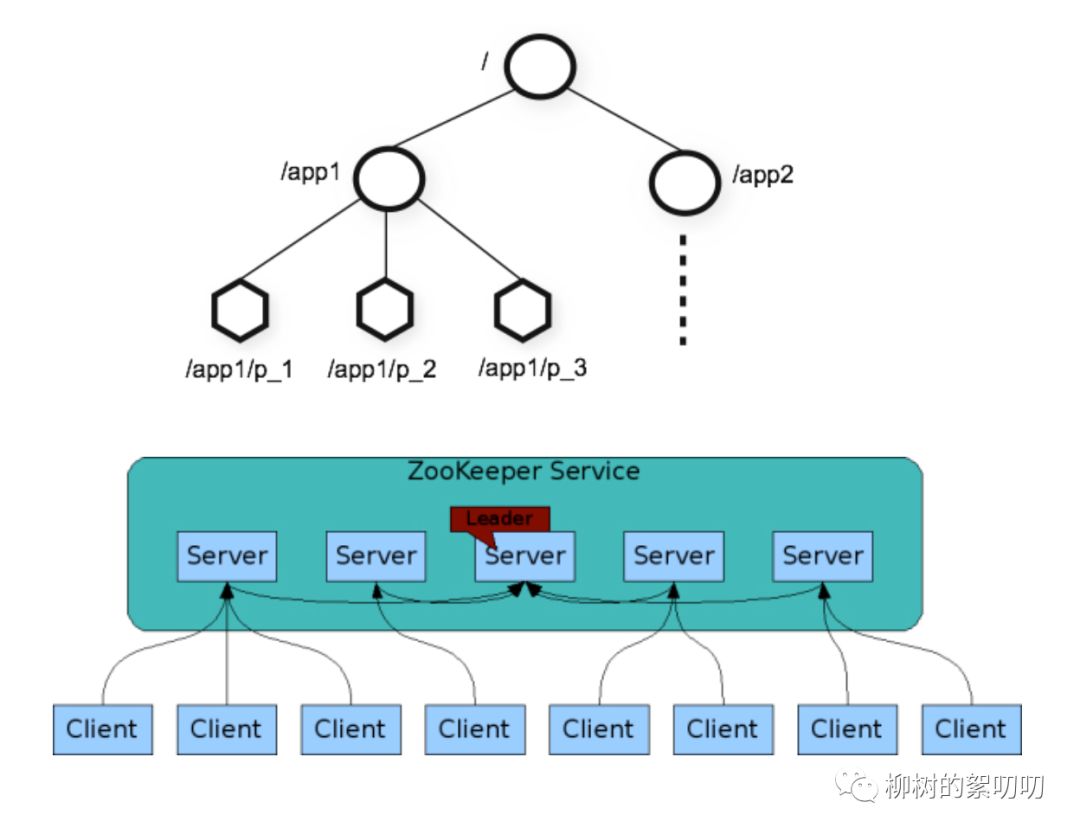
Zookeeper:
为什么需要 Zookeeper?
如何往 ZK 里插入数据、查找数据、更新数据 ……
ZK 是如何存储数据、如何查找数据的?ZK 集群中各个节点如何配合?
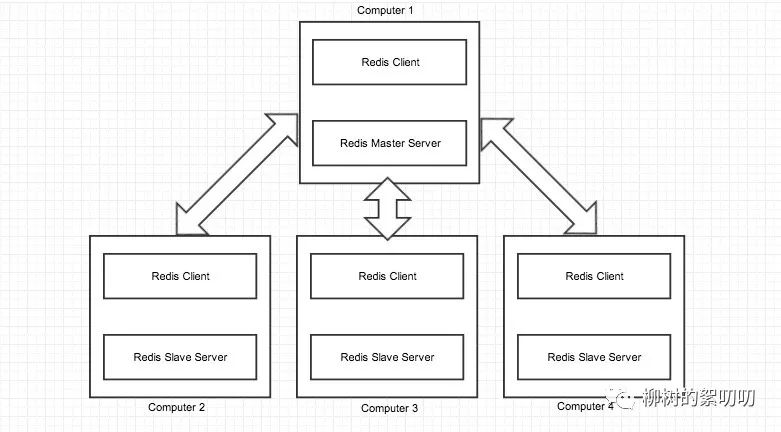
Redis:
Redis是做缓存的,这个基本都知道,于是你可以了解下什么时候要用到缓存,它相比其他缓存中间件具有的优势
如何往 Redis 插入数据、更新数据、查询数据 ……
Redis 各种数据类型的数据都是怎么存储的?为什么可以那么快找到数据?Redis 的分片和主从是如何实现的?
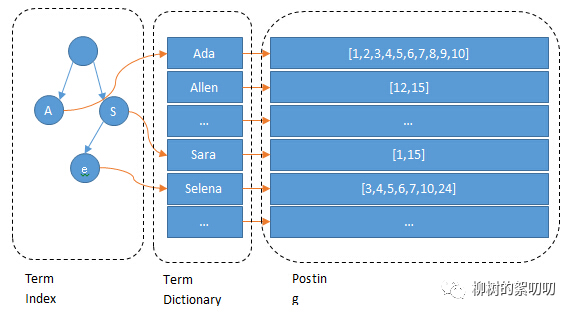
Elasticsearch:
为什么需要 Elasticsearch ?什么情况下需要用到搜索引擎?
如何往 Elasticsearch 插入数据、搜索数据、分析数据?
Elasticsearch 如何存储数据?如何索引?集群结构长什么样?
……
实际使用中,经常会遇到的问题是:
到底用哪一种数据库?
通常我们会在「关系型数据库」和各种各样的「Nosql」之间纠结。
其实在关系型数据库(Relational Database)出现之前,还出现过层次结构(hierarchical)和网络结构(network)数据库。
从数据库的起源讲起,一直聊到各种 Nosql,这样就弄明白到底要怎么选数据库,为什么会有 Nosql了。
公众号文章导航:两年呕心沥血的文章!
长按扫码可关注获取
在看和分享对我非常重要!