
从8个角度5分钟搞定数据仓库
声明 l 本文部分内容及图片来源于互联网,版权归原作者所有,仅供学习参考之用,禁止用于商业用途,如有侵权,请联系删除。
高清思维导图已同步Git:https://github.com/SoWhat1412/xmindfile,关注公众号获取海量资源
来源: https://juejin.im/post/5f198814f265da22d5312035

1. 什么是数据仓库
数据仓库,英文名称为Data Warehouse,可简写为DW或DWH。数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它出于分析性报告和决策支持目的而创建。为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制。
2. 数据仓库能干什么?
年度销售目标的指定,需要根据以往的历史报表进行决策,不能拍脑袋。 如何优化业务流程
例如:一个电商网站订单的完成包括:浏览、下单、支付、物流,其中物流环节可能和中通、申通、韵达等快递公司合作。快递公司每派送一个订单,都会有订单派送的确认时间,可以根据订单派送时间来分析哪个快递公司比较快捷高效,从而选择与哪些快递公司合作,剔除哪些快递公司,增加用户友好型。
简而言之就是汇总八方数据,清洗后提供对我服务。
3. 数据仓库的特点
1. 数据仓库的数据是面向主题的
与传统数据库面向应用进行数据组织的特点相对应,数据仓库中的数据是面向主题进行组织的。什么是主题呢?首先,主题是一个抽象的概念,是较高层次上企业信息系统中的数据综合、归类并进行分析利用的抽象。在逻辑意义上,它是对应企业中某一宏观分析领域所涉及的分析对象。面向主题的数据组织方式,就是在较高层次上对分析对象的数据的一个完整、一致的描述,能完整、统一地刻划各个分析对象所涉及的企业的各项数据,以及数据之间的联系。所谓较高层次是相对面向应用的数据组织方式而言的,是指按照主题进行数据组织的方式具有更高的数据抽象级别。说白了就个写作文一样,写什么你总的有个主题思想啊!
2. 数据仓库的数据是集成的
数据仓库的数据是从原有的分散的数据库数据抽取来的。操作型数据与分析型数据之间差别甚大。
数据仓库的每一个主题所对应的源数据在原有的各分散数据库中有许多重复和不一致的地方,且来源于不同的联机系统的数据都和不同的应用逻辑捆绑在一起;
数据仓库中的综合数据不能从原有的数据库系统直接得到。因此在数据进入数据仓库之前,必然要经过统一与综合,这一步是数据仓库建设中
最关键、最复杂的一步,所要完成的工作有:1、要统一解决源数据中所有矛盾之处,如字段的同名异义、异名同义、单位不统一、字长不一致等。2、进行数据综合和计算。数据仓库中的数据综合工作可以在从原有数据库抽取数据时生成,但许多是在数据仓库内部生成的,即进入数据仓库以后进行综合生成的。3、大部分情况下一般数仓的建立是由大数据部门负责构建,而别的分析业务部门是无权直接用线上的table的。
3. 数据仓库的数据是不可更新的
数据仓库的数据主要供企业决策分析之用,所涉及的数据操作主要是数据查询,一般情况下并不进行修改操作。数据仓库的数据反映的是一段相当长的时间内历史数据的内容,是不同时点的数据库快照的集合,以及基于这些快照进行统计、综合和重组的导出数据,而不是联机处理的数据。数据库中进行联机处理的数据经过集成输入到数据仓库中,一旦数据仓库存放的数据已经超过数据仓库的数据存储期限,这些数据将从当前的数据仓库中删去。因为数据仓库只进行数据查询操作,所以数据仓库管理系统相比数据库管理系统而言要简单得多。
数据库管理系统中许多技术难点,如完整性保护、并发控制等等,在数据仓库的管理中几乎可以省去。但是由于数据仓库的查询数据量往往很大,所以就对数据查询提出了更高的要求,它要求采用各种复杂的索引技术;同时由于数据仓库面向的是商业企业的高层管理者,他们会对数据查询的界面友好性和数据表示提出更高的要求。
4. 数据仓库的数据是随时间不断变化的
数据仓库中的数据不可更新是针对应用来说的,也就是说,数据仓库的用户进行分析处理时是不进行数据更新操作的。但并不是说,在从数据集成输入数据仓库开始到最终被删除的整个数据生存周期中,所有的数据仓库数据都是永远不变的。
数据仓库的数据是随时间的变化而不断变化的,这是数据仓库数据的第四个特征。这一特征表现在以下3方面:
1、数据仓库随时间变化不断增加新的数据内容。数据仓库系统必须不断捕捉OLTP数据库中变化的数据,追加到数据仓库中去,也就是要不断地生成OLTP数据库的快照,经统一集成后增加到数据仓库中去;但对于确实不再变化的数据库快照,如果捕捉到新的变化数据,则只生成一个新的数据库快照增加进去,而不会对原有的数据库快照进行修改。形象来说就是对数据进每日全量数据的收集。
2、数据仓库随时间变化不断删去旧的数据内容。数据仓库的数据也有存储期限,一旦超过了这一期限,过期数据就要被删除。只是数据仓库内的数据时限要远远长于操作型环境中的数据时限。在操作型环境中一般只保存有60到90天的数据,而在数据仓库中则需要保存较长时限的数据(如5~10年),以适应DSS(Decision Support System)进行趋势分析的要求。
3、数据仓库中包含有大量的综合数据,这些综合数据中很多跟时间有关,如数据经常按照时间段进行综合,或隔一定的时间片进行抽样等等。这些数据要随着时间的变化不断地进行重新综合。因此,数据仓库的数据特征都包含时间项,以标明数据的历史时期。
4. 数据仓库发展历程

5. 数据库与数据仓库的区别

5. OLTP跟OLAP
数据库与数据仓库的区别实际讲的是OLTP与OLAP的区别。
操作型处理:叫联机事务处理OLTP(On-Line Transaction Processing),也可以称面向交易的处理系统,它是针对具体业务在数据库联机的日常操作,通常对少数记录进行查询、修改。用户较为关心操作的响应时间、数据的安全性、完整性和并发支持的用户数等问题。传统的数据库系统作为数据管理的主要手段,主要用于操作型处理。
分析型处理:叫联机分析处理OLAP(On-Line Analytical Processing)一般针对某些主题的历史数据进行分析,支持管理决策,ETL。
| 操作型处理(OLTP) | 分析型处理(OLAP) |
|---|---|
| 细节的 | 综合的或提炼的 |
| 实体——关系(E-R)模型 | 星型模型或雪花模型 |
| 存取瞬间数据 | 存储历史数据,不包含最近的数据 |
| 可更新的 | 只读、只追加 |
| 一次操作一个单元 | 一次操作一个集合 |
| 性能要求高,响应时间短 | 性能要求宽松 |
| 面向事务 | 面向分析 |
| 一次操作数据量小 | 一次操作数据量大 |
| 支持日常操作 | 支持决策需求 |
| 数据量小 | 数据量大 |
| 客户订单、库存水平和银行账户查询等 | 客户收益分析、市场细分等 |
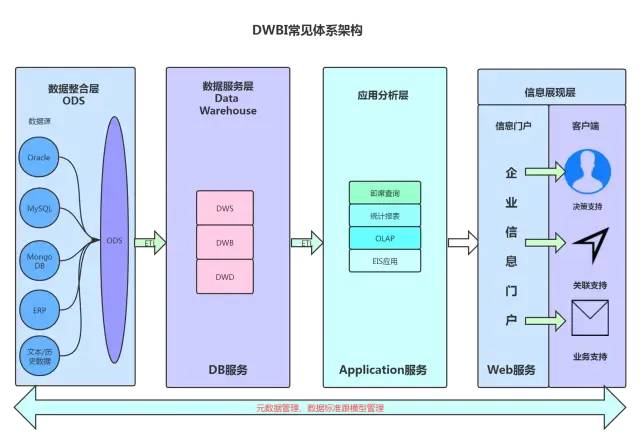
6. 数据仓库架构分层(重点)
1. 数据仓库架构
数据仓库标准上可以分为四层:ODS(临时存储层)、PDW(数据仓库层)、DM(数据集市层)、APP(应用层)。各个系统的元数据通过ETL同步到操作性数据仓库ODS中,对ODS数据进行面向主题域建模形成DW(数据仓库),DM是针对某一个业务领域建立模型,具体用户(决策层)查看DM生成的报表。
临时存储数据运营层:ODS(Operational Data Store):ODS层是这样一种数据存储系统,它将来自不同数据源的数据(各种操作型数据库、外部数据源等)通过 ETL(Extract-Transform-Load)过程汇聚整合成面向主题的、集成的、企业全局的、一致的数据集合(主要是最新的或者最近的细节数据以及可能需要的汇总数据)。从数据粒度上来说ODS层的数据粒度是最细的。ODS层的表通常包括两类,一个用于存储当前需要加载的数据,一个用于存储处理完后的历史数据。历史数据一般保存3-6个月后需要清除,以节省空间。但不同的项目要区别对待,如果源系统的数据量不大,可以保留更长的时间,甚至全量保存。数据仓库层:DW(Data Warehouse):为数据仓库层,DW层的数据应该是一致的、准确的、干净的数据,即对源系统数据进行了 清洗(去除了杂质)后的数据。这一层的数据一般是遵循数据库第三范式的,其数据粒度通常和ODS的粒度相同。在DW层会保存BI系统中所有的历史数据,例如保存10年的数据。
DW:Data Warehouse翻译成数据仓库,DW由下到上分为DWD、DWB、DWS。DWD:Warehouse Detail细节数据层,有的也称为ODS层,是业务层与数据仓库的隔离层 DWB:Data Warehouse Base基础数据层,存储的是客观数据,一般用作中间层,可以认为是大量指标的数据层。DWS:Data Warehouse Service服务数据层,基于DWB上的基础数据,整合汇总成分析某一个主题域的服务数据,一般是宽表。
数据集市层:DM(Data Mart):为数据集市层,这层数据是 面向主题来组织数据的,通常是星形或雪花结构的数据。从数据粒度来说,这层的数据是轻度汇总级的数据,已经不存在明细数据了。从数据的时间跨度来说,通常是DW层的一部分,主要的目的是为了满足用户分析的需求,而从分析的角度来说,用户通常只需要分析近几年(如近三年的数据)的即可。从数据的广度来说,仍然覆盖了所有业务数据。应用层:Application层:这层数据是完全为了满足具体的分析需求而构建的数据,也是 星形或雪花结构的数据。从数据粒度来说是高度汇总的数据。从数据的广度来说,则并不一定会覆盖所有业务数据,而是DM层数据的一个真子集,从某种意义上来说是DM层数据的一个重复。从极端情况来说,可以为每一张报表在APP层构建一个模型来支持,达到以空间换时间的目的数据仓库的标准分层只是一个建议性质的标准,实际实施时需要根据实际情况确定数据仓库的分层,不同类型的数据也可能采取不同的分层方法。
2. 为什么要对数据仓库分层?
用空间换时间,通过大量的预处理来提升应用系统的用户体验(效率),因此数据仓库会存在大量冗余的数据。解偶,如果不分层的话,如果源业务系统的业务规则发生变化将会影响整个数据清洗过程,工作量巨大。 通过数据分层管理可以简化数据清洗的过程,因为把原来一步的工作分到了多个步骤去完成,相当于把一个复杂的工作拆成了多个简单的工作,把一个大的黑盒变成了一个白盒,每一层的处理逻辑都相对简单和容易理解,这样我们比较容易保证每一个步骤的正确性,当数据发生错误的时候,往往我们只需要局部调整某个步骤即可。
7. 元数据介绍
当需要了解某地企业及其提供的服务时,电话黄页的重要性就体现出来了。元数据(Metadata)类似于这样的电话黄页。
1. 元数据的定义

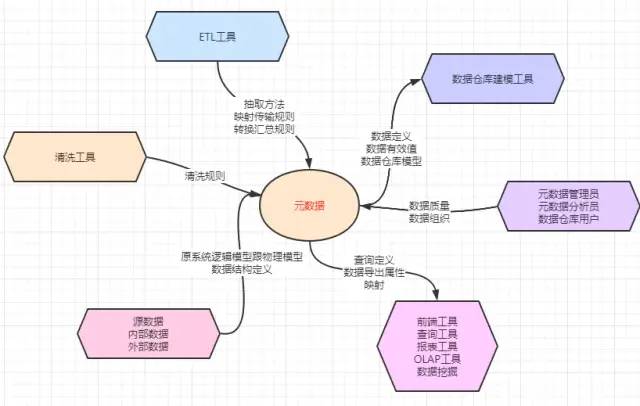
2. 元数据的存储方式

3. 元数据的作用

8. 星型模型和雪花模型
在多维分析的商业智能解决方案中,根据事实表和维度表的关系,又可将常见的模型分为星型模型和雪花型模型。在设计逻辑型数据的模型的时候,就应考虑数据是按照星型模型还是雪花型模型进行组织。
1. 星型模型
当所有维表都直接连接到事实表上时,整个图解就像星星一样,故将该模型称为星型模型。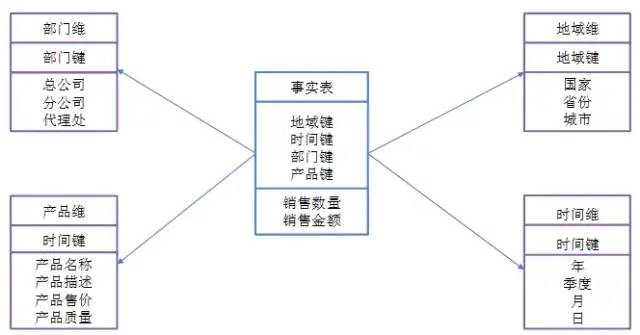
星型架构是一种非正规化的结构,多维数据集的每一个维度都直接与事实表相连接,不存在渐变维度,所以数据有一定的冗余,如在地域维度表中,存在国家A 省B的城市C以及国家A省B的城市D两条记录,那么国家A和省B的信息分别存储了两次,即存在冗余。
2. 雪花模型
当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像多个雪花连接在一起,故称雪花模型。雪花模型是对星型模型的扩展。它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的层次 区域,这些被分解的表都连接到主维度表而不是事实表。如图所示,将地域维表又分解为国家,省份,城市等维表。它的优点是:通过最大限度地减少数据存储量以及联合较小的维表来改善查询性能。雪花型结构去除了数据冗余。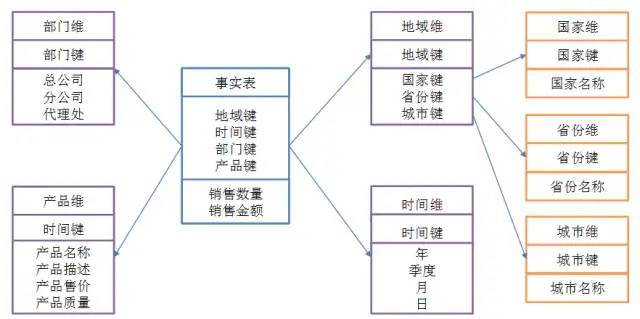 星型模型因为数据的冗余所以很多统计查询不需要做外部的连接,因此一般情况下效率比雪花型模型要高。星型结构不用考虑很多正规化的因素,设计与实现都比较简单。雪花型模型由于去除了冗余,有些统计就需要通过表的联接才能产生,所以效率不一定有星型模型高。正规化也是一种比较复杂的过程,相应的数据库结构设计、数据的 ETL、以及后期的维护都要复杂一些。因此在冗余可以接受的前提下,实际运用中星型模型使用更多,也更有效率。
星型模型因为数据的冗余所以很多统计查询不需要做外部的连接,因此一般情况下效率比雪花型模型要高。星型结构不用考虑很多正规化的因素,设计与实现都比较简单。雪花型模型由于去除了冗余,有些统计就需要通过表的联接才能产生,所以效率不一定有星型模型高。正规化也是一种比较复杂的过程,相应的数据库结构设计、数据的 ETL、以及后期的维护都要复杂一些。因此在冗余可以接受的前提下,实际运用中星型模型使用更多,也更有效率。
3. 星型模型和雪花模型对比
星形模型和雪花模型是数据仓库中常用到的两种方式,而它们之间的对比要从四个角度来进行讨论。
数据优化 雪花模型使用的是规范化数据,也就是说数据在数据库内部是组织好的,以便消除冗余,因此它能够有效地减少数据量。通过引用完整性,其业务层级和维度都将存储在数据模型之中。相比较而言, 星形模型使用的是反规范化数据。在星形模型中,维度直接指的是事实表,业务层级不会通过维度之间的参照完整性来部署。业务模型 在雪花模型中,数据模型的业务层级是由一个不同维度表主键-外键的关系来代表的。而在星形模型中,所有必要的维度表在事实表中都只拥有外键。 性能 第三个区别在于性能的不同。 雪花模型在维度表、事实表之间的连接很多,因此性能方面会比较低。举个例子,如果你想要知道一个用户的详细信息,雪花模型就会进行若干表的join最终汇总结果。而星形模型的连接就少的多,在这个模型中,如果你需要对应信息,你只要将维度表和事实表连接即可。ETL 雪花模型加载数据集市,因此ETL操作在设计上更加复杂,而且由于附属模型的限制,不能并行化。星形模型加载维度表,不需要再维度之间添加附属模型,因此ETL就相对简单,而且可以实现高度的并行化。 总结 雪花模型使得维度分析更加容易,比如 针对特定的广告主,有哪些客户或者公司是在线的?星形模型用来做指标分析更适合,比如给定的一个客户他们的收入是多少?