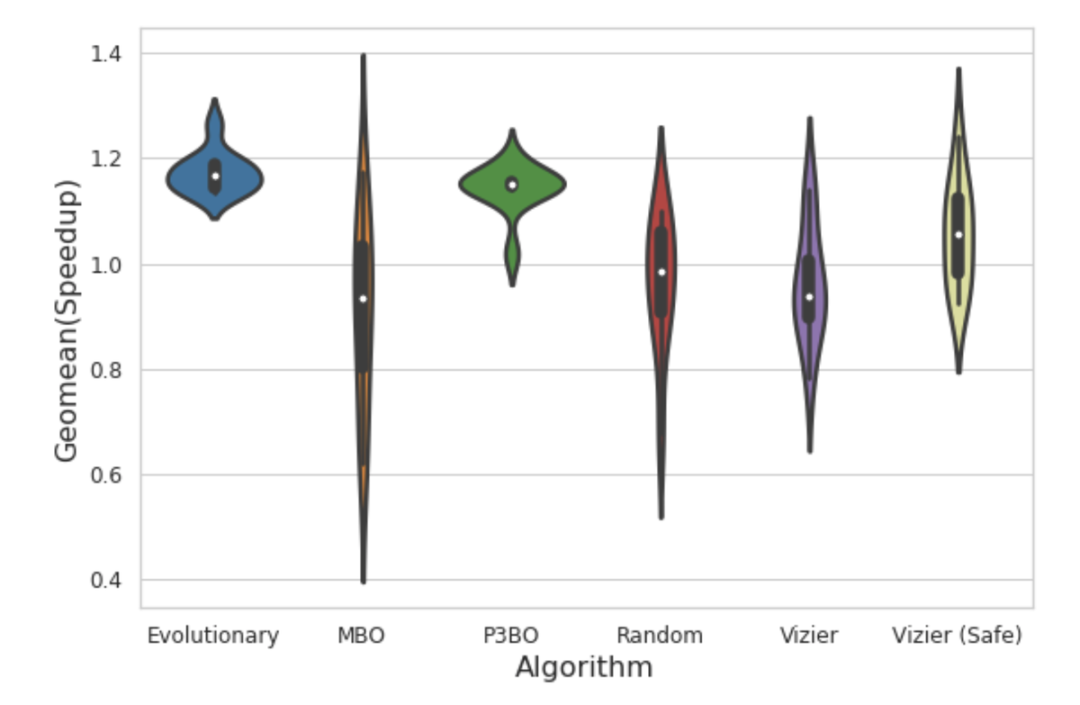
用Apollo设计芯片!Google说懂芯片才能更快「炼丹」新智元关注共 2699字,需浏览 6分钟 ·2021-03-03 13:21 新智元报道 来源:Google编辑:LRS、小匀【新智元导读】「在某些情况下,深度学习能够比人类做出更好地设计芯片电路」,Jeff Dean如是说。利用深度学习的力量来搜索更好的参数空间来设计电路,比人脑的穷尽更有效率。 近日,Google在arxiv上发表一篇名为《Apollo: Transferable Architecture Exploration》的论文。主要作者之一Amir Yazdanbakhsh在其博客中详细介绍了一个名为Apollo的研究项目。 这项工作可能标志着使用机器学习技术来优化芯片「结构」的开始。Apollo项目Jeff Dean 在一年前的国际固态电路大会(International Solid State Circuits Conference)中发表过一次演讲,认为「机器学习可以用于一些低层次的设计决策,也就是说在布局和走线(place and route)上,芯片设计人员可以使用软件来确定芯片的电路和布局,类似于设计建筑平面图。」 相比之下,Apollo的目标不是要构建一个平面图,而是要完成芯片的体系结构的设计。作者称其为「架构探索」(architecture exploration)。 架构探索比布局和走线的设计层级要更高,并且架构的改进能带来比布局走线更多的性能提升。 芯片的体系结构是一个芯片的功能元素设计,包括如何交互,软件开发人员如何获取硬件接口。经典的Intel x86处理器的片上存储器大小、专用算术逻辑单元和寄存器等等全部的片上元素,以及他们组合起来的方式一起被称为Intel架构。 作者称Apollo为「第一个可迁移的架构探索系统」,随着它设计更多不同的芯片,它的架构设计能力也会更好。也就是之前学习到的知识能够迁移到新的芯片设计任务上。 作者团队正在开发的芯片也是AI加速运算的芯片,和基于安培架构的GPU英伟达A100,Cerebras系统WSE芯片和其他创业公司的芯片类似。 「利用人工智能来设计人工智能芯片」,成为正反馈循环。 芯片的运算由于任务是设计人工智能芯片,Apollo正在探索的架构是适合运行神经网络的架构。神经网络的运算由大量简单的数学单元、线性代数组成,主要的运算是乘法和求和。 作者团队认为设计任务的目的是找到一种正确的方式来混合这些简单的数学算数来适配一个给定的AI任务。他们首先选择了一个相当简单的AI任务,一个卷积神经网络MobileNet,2017年由Google的Andrew G. Howard和其团队设计,是一种不需要太多资源的神经网络。此外,他们还测试了一些其他网络在不同任务(如目标检测、语义分割)的工作负载情况。 通过这种方式,目标重新被定义为:给定一个神经网络,什么芯片的参数结构能够让运算速度达到最快? 这个搜索过程对超过4.52亿个参数进行重排序,来寻找对于一个模型来说最优的参数。这些参数包括使用多少个数学单元(处理器),内存大小和激活函数的内存。 Apollo是一个框架,它可以把每个部分换成其他论文中描述的黑盒优化方法,并根据特定的工作负载来调整这些方法,然后比较每种方法在解决特定目标下的表现。 作者使用了一些用来优化神经网络结构的优化方法,包括2019年Google的Quoc V.Le开发的进化方法;基于模型的强化学习方法;由Christof Angermueller开发用来设计DNA序列的优化方法population-based的集成方法;和一个基于贝叶斯的优化方法。 Apollo将神经网络设计和生物合成上的设计方法结合来设计电路,电路上取得更快的速度又会反过来促进神经网络设计和生物合成的发展。 Apollo框架将所有的优化方法都进行了比较,实验结果详细说明了「基于进化」和「基于模型」的方法优于随机选择和其他候选方法。 Apollo另一个重要的发现是运行这些优化方法的方式要比暴力搜索更有效率。例如population-based的集成方法和半穷举「semi-exhausitive」搜索的方法更好。 population-based的方法能够找到权衡的解决方案,例如计算机和内存的设计需要领域知识,而半穷举搜索是不具有学习能力的,所以population-based能够找到半穷举找不到的答案。 因此Apollo能够指出不同优化方法之间在芯片设计上的差异。除此之外,Apollo能够利用迁移学习提升优化方法的能力。 通过给Apollo不同的设计方案限制,例如最大的芯片尺寸不能超过毫米级,这些实验结果可以作为一个后续的优化样本作为输入。作者团队发现利用这种面积约束的电路设计能够影响最终设计性能。 为MobileNet设计芯片中,负载的约束也是要在设计过程中考虑到的。作者团队中Berkin Akin已经开发了一个新版本的MobileNet,命名为MobileNet Edge,指出优化需要芯片和神经网络优化的协作。 Akin认为「神经网络架构设计者必须了解目标的硬件架构,才能够优化整体的系统性能和能效。」 Apollo对于给定负载约束的情况已经可以完成任务了,但是芯片设计和神经网络之间的协同优化,也许是下一个重点研究的目标。 参考链接:https://www.zdnet.com/article/googles-deep-learning-finds-a-critical-path-in-ai-chips/https://ai.googleblog.com/2021/02/machine-learning-for-computer.htmlhttps://www.zdnet.com/article/google-experiments-with-ai-to-design-its-in-house-computer-chips/https://arxiv.org/pdf/2102.01723.pdf 浏览 117点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 用一张图片告诉你芯片设计嵌入式Linux0OpenTitan安全芯片设计项目OpenTitan是Google开发的项目,旨在鼓励厂家为数据中心和消费级设备开发所谓的信任根(root-of-trust)技术。如果一个系统被称为拥有信任根,这意味着它有专门的芯片或模块负责阻击黑客OpenTitan安全芯片设计项目OpenTitan 是 Google 开发的项目,旨在鼓励厂家为数据中心和消费级设备开发所谓的信任根芯片设计规则,正在悄然变革!物联网智库0开源芯片:处理器芯片发展新趋势智能计算芯世界0AI+芯片=_____?芯片之家0芯片设计上云(路径篇)架构师技术联盟0漫画:芯片是如何设计的?李肖遥0芯片设计云技术白皮书2.0智能计算芯世界0开源芯片:处理器芯片发展新趋势架构师技术联盟0点赞 评论 收藏 分享 手机扫一扫分享分享 举报





 下载APP
下载APP