
Java 线程安全问题的本质
点击上方蓝色字体,选择“标星公众号”
优质文章,第一时间送达
作者 | Arnold-zhao
来源 | urlify.cn/ryQFJn
出现线程安全的问题本质是因为:
主内存和工作内存数据不一致性以及编译器重排序导致。
所以理解上述两个问题的核心,对认知多线程的问题则具有很高的意义;
简单理解CPU
CPU除了控制器、运算器等器件还有一个重要的部件就是寄存器。其中寄存器的作用就是进行数据的临时存储。
CPU的运算速度是非常快的,为了性能CPU在内部开辟一小块临时存储区域,并在进行运算时先将数据从内存复制到这一小块临时存储区域中,运算时就在这一小快临时存储区域内进行。我们称这一小块临时存储区域为寄存器。
CPU读取指令是往内存里面去读取的,读一条指令放到CPU中,CPU去执行,对内存的读取速度比较慢,所以从内存读取的速度去决定了这个CPU的执行速度的。所以无论我们的CPU怎么去升级,但是如果这方面速度没有解决的话,其的性能也不会得到多大的提升。
为了弥补这个缺陷,所以添加了高速缓存的机制,如ARM A11的处理器,它的1级缓存中的容量是64KB,2级缓存中的容量是8M,
通过增加cpu高速缓存的机制,以此弥补服务器内存读写速度的效率问题;
JVM虚拟机类比于操作系统
JVM虚拟计算机平台就类似于一个操作系统的角色,所以在具体实现上JVM虚拟机也的确是借鉴了很多操作系统的特点;
JAVA中线程的工作空间(working memory)就是CPU的寄存器和高速缓存的抽象描述,cpu在计算的时候,并不总是从内存读取数据,它的数据读取顺序优先级 是:寄存器-高速缓存-内存;
而在JAVA的内存模型中也是同等的,Java内存模型中规定了所有的变量都存储在主内存中,每条线程还有自己的工作内存(类似于CPU的高速缓存),线程的工作内存中保存了该线程使用到的变量到主内存副本拷贝,线程对变量的所有操作(读取、赋值)都必须在工作内存中进行,而不能直接读写主内存中的变量,操作完成后再将变量写回主内存。不同线程之间无法直接访问对方工作内存中的变量,线程间变量值的传递均需要在主内存来完成。基本关系如下图:
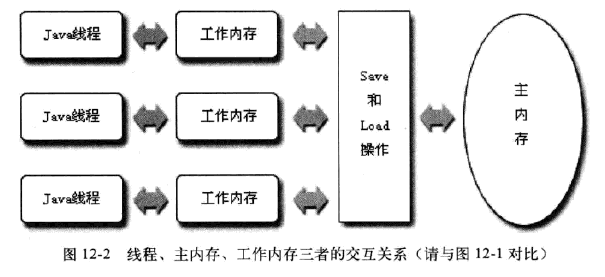
注意:这里的Java内存模型,主内存、工作内存与Java内存区域模型的Java堆、栈、方法区不是同一层次内存划分,这两者基本上没有关系。
重排序
在执行程序时,为了提高性能,编译器和处理器常常会对指令进行重排序。一般重排序可以分为如下三种:

举例如下:
public class Singleton {
public static Singleton singleton;
/**
* 构造函数私有,禁止外部实例化
*/
private Singleton() {};
public static Singleton getInstance() {
if (singleton == null) {
singleton = new Singleton();
}
return singleton;
}
}
如上,一个简单的单例模式,按照对象的构造过程,实例化一个对象1、可以分为三个步骤(指令):
1、 分配内存空间。
2、 初始化对象。
3、 将内存空间的地址赋值给对应的引用。
但是由于操作系统可以对指令进行重排序,所以上面的过程也可能变为如下的过程:
1、 分配内存空间。
2、 将内存空间的地址赋值给对应的引用。
3、 初始化对象 。
所以,如果出现并发访问getInstance()方法时,则可能会出现,线程二判断singleton是否为空,此时由于当前该singleton已经分配了内存地址,但其实并没有初始化对象,则会导致return 一个未初始化的对象引用暴露出来,以此可能会出现一些不可预料的代码异常;
当然,指令重排序的问题并非每次都会进行,在某些特殊的场景下,编译器和处理器是不会进行重排序的,但上述的举例场景则是大概率会出现指令重排序问题(关于指令重排序的概念后续给出详细的地址)
原创声明:作者:Arnold.zhao 博客园地址:https://www.cnblogs.com/zh94
汇总
所以,如上可知,多线程在执行过程中,数据的不可见性,原子性,以及重排序所引起的指令有序性 三个问题基本是多线程并发问题的三个重要特性,也就是我们常说的:
并发的三大特性:原子性,有序性,可见性;
原子性:代码操作是否是原子操作(如:i++ 看似一个代码片段,实际的执行中将会分为三步执行,则必然是非原子化的操作,在多线程的场景中则会出现异常)
有序性:CPU执行代码指令时的有序性;
可见性:由于工作线程的内存与主内存的数据不同步,而导致的数据可见性问题;
一些解释
但是,问题就真的有那么复杂吗?如果按照上面所说的问题,i++是非原子操作,就会出现并发异常的问题,new Object() 就会出现重排序的并发问题,那么Java开发还能做吗。。我随便写个方法代码,岂不是就会出现并发问题?但是为什么我开发了这么久的代码,也没有出现过方法并发导致的异常问题啊?
烧的麻袋;
这里就要说明另外一个问题,JVM的线程栈,JVM线程栈中是线程独有的内存空间(如:程序计数器以线程栈帧)而线程栈帧中的局部变量表则用来存储当前所执行方法的基本数据类型(包含 reference, returnAddress等),所以当方法在被线程执行的过程中,相关的对象引用信息,以及基本类型的数据都是线程独有的,并不会出现多个线程访问时的并发问题,也就是简单来说:一个方法内的变量定义以及方法内的业务代码,是不会出现并发问题的。多个线程并不会共享一个方法内的变量数据,而是每个方法内的定义都属于当前该执行线程的独有栈空间中。(所以通过Java线程栈的这一独特特性自然当中则为我们省了很多事项;)
但是由于我们的线程的数据操作不可能每次都去访问主存中的数据,对于线程所使用到的变量需要copy至线程内存中以增加我们的执行速度,所以就引出了我们上述所提到的并发问题的本质问题,线程工作空间和主内存的数据不同步而导致的数据共享时的可见性问题;
如:此时定义一个简单的类
class Person{
int a = 1;
int b = 2;
public void change() {
a = 3;
b = a;
}
public void print() {
String result = "b=" + b + ";a=" + a;
System.out.println(result);
}
public static void main(String[] args) {
while (true) {
final Person test = new Person();
new Thread(() -> {
Thread.sleep(10);
test.change();
}).start();
new Thread(() -> {
Thread.sleep(10);
test.print();
}).start();
}
}
}
如上,假设此时多个线程同时访问change()以及print() 方法,则可能会出现print所输出的结果是:b=2;a=1或者b=3;a=3;这两种都是正常现象,但还有可能是会输出结果是:b=2;a=3以及b=3;a=1;
Person类所定义的变量a和b,按照JVM内存区域划分,在对象实例化后则都是存储到数据堆中;
按照我们上述关于线程工作内存的解释来看,此时线程在执行change()方法和print()方法时,由于两个方法都有关于外部变量的引用,所以需要copy主内存中的这两个变量副本到对应的线程工作内存中进行操作,执行完以后再同步至主内存中。
此时在A线程执行完change()方法后,a=3,b=3;但此时a=3在执行完成后还没有同步到主内存,但b=3此时已经提供至主内存了,那么此时B线程执行print()数据输出后,则得到的是结果是:b=3;a=1;同理也可以得到b=2;a=3的可能性结果;所以此处则由于线程共享变量的可见性问题,而导致了上述的问题;
正是由于存在上述所提到的线程并发所可能引起的种种问题,所以JDK则也有了后续的一系列多线程玩法:ThreadLocal,CountDownLatch,ReentrantLock,Unsafe,synchronized,volatile,Executor,Future 这些供开发者在开发程序时用来对多线程保驾护航的助手类,以及JDK已经自身开发好的支持线程安全的一些工具类,StringBuffer,CopyOnWriteArrayList, ConcurrentHashMap,AtomicInteger等,供开发者开箱即用;后续针对这些JDK自身所提供的一些类的玩法会做进一步说明,顺便系统整理下脑中的信息,形成有效的知识结构;End;
粉丝福利:Java从入门到入土学习路线图
???

?长按上方微信二维码 2 秒
感谢点赞支持下哈 