
【学术相关】2020年AI领域有哪些让人惊艳的研究?

Switch Transformers 模型的创新:
1)Switch Transformer在网络结构上最大的改进是Sparse routing的稀疏结构,相比于OpenAI在GPT-3里所使用的Sparse Attention,需要用到稀疏算子而很难发挥GPU、TPU硬件性能的问题。Switch Transformer不需要稀疏算子,可以更好的适应GPU、TPU等硬件。
2)Switch Transformer虽然有1.6万亿参数,但通过Sparse routing的改进,每轮迭代只会触发部分Expert的计算,而每个token也只会路由给一个Expert,所以对算力的需求并没有随着参数量的增加而大幅增长,使得这个模型更加容易训练。
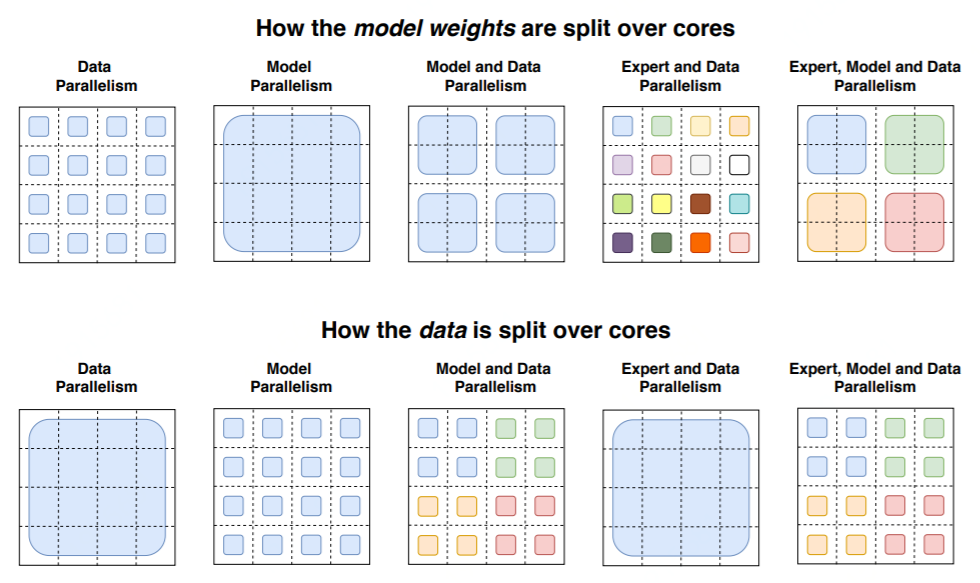
3)数据并行、模型并行、Expert并行的并行策略设计,在MoE网络结构上能够获得更低的通信开销,提高并行的效率。
有兴趣的可以读一下《Google Brain:从不废话,直接扔大》一文。
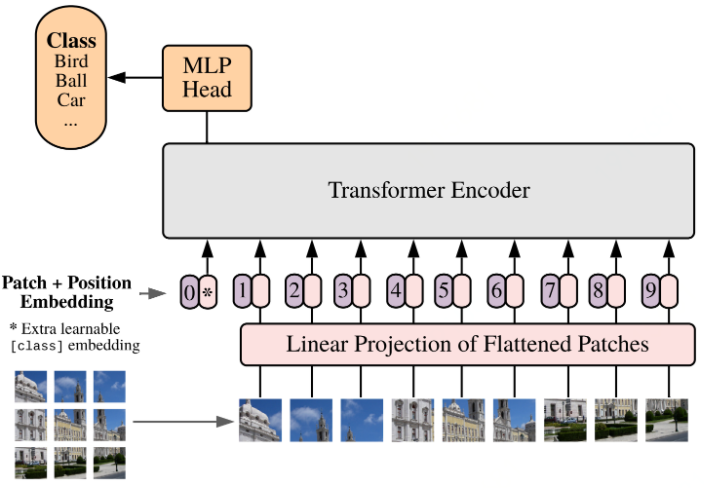
虽然Transformer在自然语言处理方面取得了巨大的成功,但在计算机视觉领域还是不太行的样子,卷积神经网络(CNNs)仍然在CV领域占据着主导地位。尽管在理论上,Transformer不如RNN牛B,但当数据规模足够大时,与 CNN 和 RNN 相比,Transformer 的归纳偏置更少,效果上也开始超越其他模型的表现。
Image GPT (Chen et al., 2020)、Vision Transformer (ViT,Dosovitskiy et al., 2020)、Image Processing Transformer(IPT,Chen et al., 2020)各放异彩,有的采用GPT-2思想直接从像素进行预训练,有的通过对比损失预训练的方式实现了新的SOTA,有的将图像重塑为被视为「token」。
未来,Transformer在计算机视觉中可能会变得越来越有意思。Transformer将特别适用于有足够算力和数据的预训练场景。在数据规模较小时,CNNs将仍然是一种可行的方法和一个强有力的Baseline。

少样本学习可以将一个模型应用于各种场景的各种任务,但每次根据新任务进行全局的模型更新是奢侈的,最好的方式是进行模型的局部更新,2020年在少样本学习方面使用Adapter(Houlsby et al., 2019、Pfeiffer et al., 2020a、Üstün et al., 2020),或者使用加入稀疏参数向量(Guo et al., 2020),以及仅修改偏差值(Ben-Zaken et al., 2020)等方法。
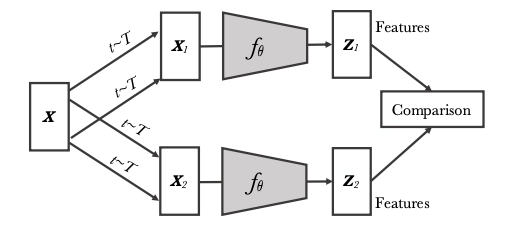
对比学习(Contrastive Learning)这类方法则是通过将数据分别与正例样本和负例样本在特征空间进行对比,来学习样本的特征表示。Contrastive Methods主要的难点在于如何构造正负样本。
2020年进一步改善了这种通用框架,SimCLR(Chen et al., 2020)、SwAV(Caron et al., 2020)、Momentum Contrast(He et al., 2020)等方法,有的定义了增强型实例的对比损失,有的试图确保大量且一致的样本对集合,有的利用在线聚类等。
同时,Zhao et al. (2020)发现数据增强在对比学习中是至关重要的。对比学习与 masked语言建模相结合的方式,能让模型具有更丰富、更鲁棒的特征表征,同时它可以帮助解决模型异常值以及罕见的句法和语义现象带来的问题,。
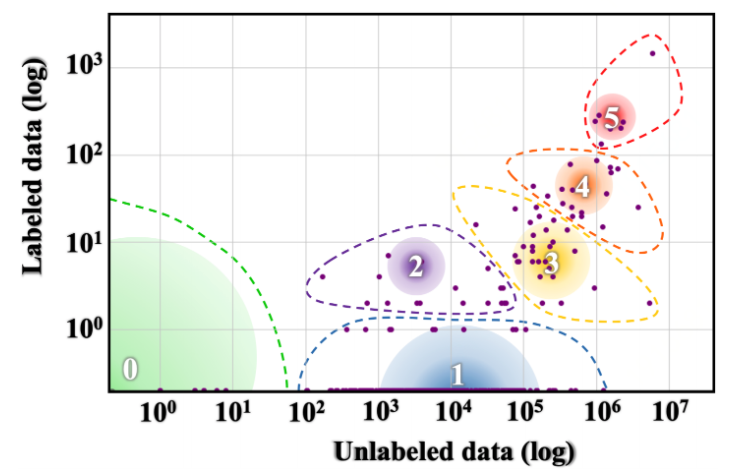
多语言模型在2020年的诸多研究中也颇有亮点,包括多语言数据集:
SQuAD: XQuAD (Artetxe et al., 2020), MLQA (Lewis et al., 2020), FQuAD (d'Hoffschmidt et al., 2020)
Natural Questions: TyDiQA (Clark et al., 2020), MKQA (Longpre et al., 2020)
MNLI: OCNLI (Hu et al., 2020), FarsTail (Amirkhani et al., 2020)
the CoNLL-09 dataset: X-SRL (Daza and Frank, 2020)
the CNN/Daily Mail dataset: MLSUM (Scialom et al., 2020)
BERT模型的诸多迭代创新中,有包含100多种语言的强大模型,包括AraBERT (Antoun et al., 2020)、IndoBERT (Wilie et al., 2020)、XML-R (Conneau et al., 2020)、RemBERT (Chung et al., 2020)、InfoXLM (Chi et al., 2020)等。
此外,《The State and Fate of Linguistic Diversity(Joshi et al., 2020)》一文,强调了使用英语之外语言的紧迫性。《Decolonising Speech and Language Technology (Bird, 2020)》一文指出了不要将语言社区及数据视为商品。
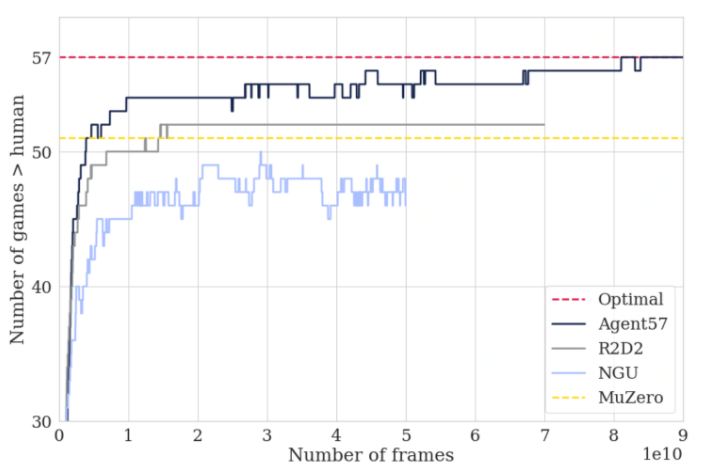
Agent57(Badia et al., 2020)首次在 57 款 Atari 游戏上超过人类,同时也为深度强化学习领域建立了baseline。
在游戏方面,强化学习的另一个里程碑是 Schrittwieser 等人开发的 MuZero,它能预测环境各个方面,而环境对精确的规划非常重要。在没有任何游戏动态知识的情况下,MuZero 在雅达利上达到了 SOTA 性能,在围棋、国际象棋和日本象棋上表现也很出色。
对强化学习有兴趣的同学可以看一下炼丹笔记出品的《从零单排强化学习》系列。

参考内容
1、Google Brain:从不废话,直接扔大
2、https://ruder.io/research-highlights-2020/
往期精彩回顾
本站知识星球“黄博的机器学习圈子”(92416895)
本站qq群704220115。
加入微信群请扫码: