
一文看尽 CVPR 2022 最新 20 篇 Oral 论文
导读
极市平台一直在对CVPR 2022的论文进行分方向的整理,目前已累计更新了535篇,本文为最新的CVPR 2022 Oral 论文,包含目标检测、图像处理等方向,附打包下载链接。
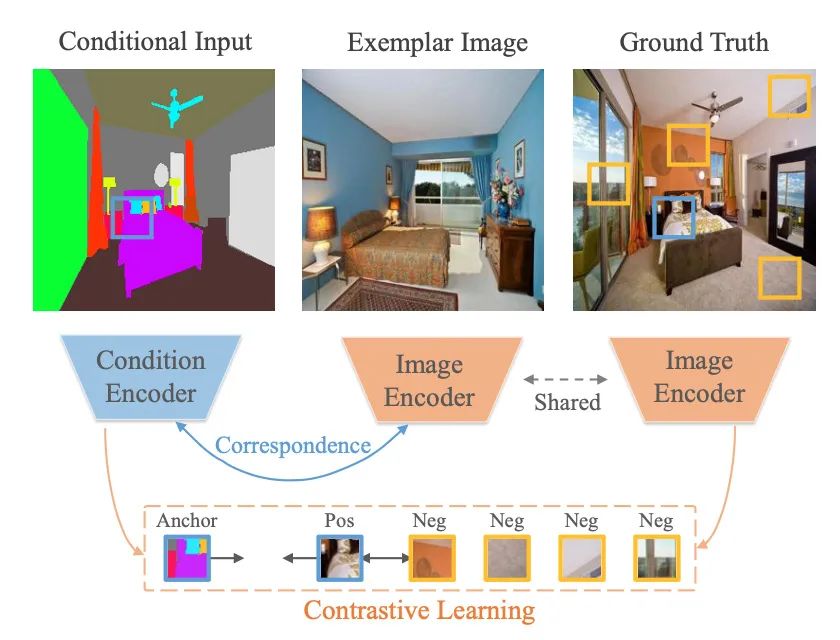
【1】Marginal Contrastive Correspondence for Guided Image Generation
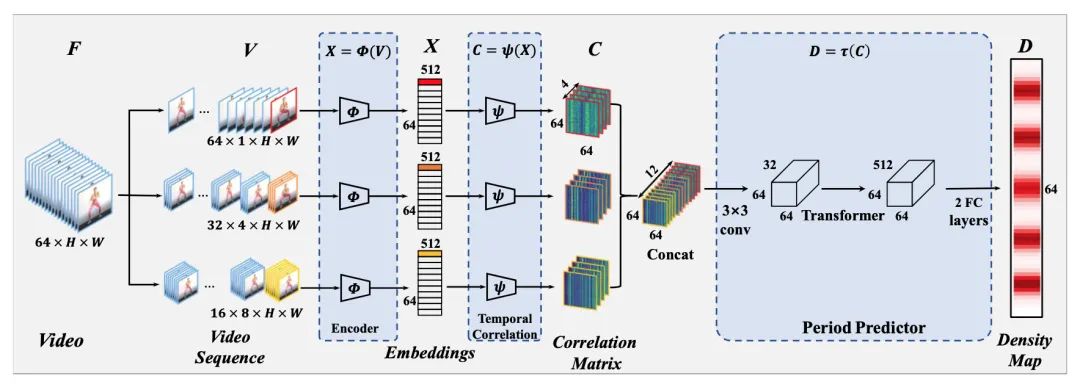
【2】TransRAC: Encoding Multi-scale Temporal Correlation with Transformers for Repetitive Action Counting
dataset:https://svip-lab.github.io/dataset/RepCount_dataset.html
code:https://github.com/SvipRepetitionCounting/TransRAC

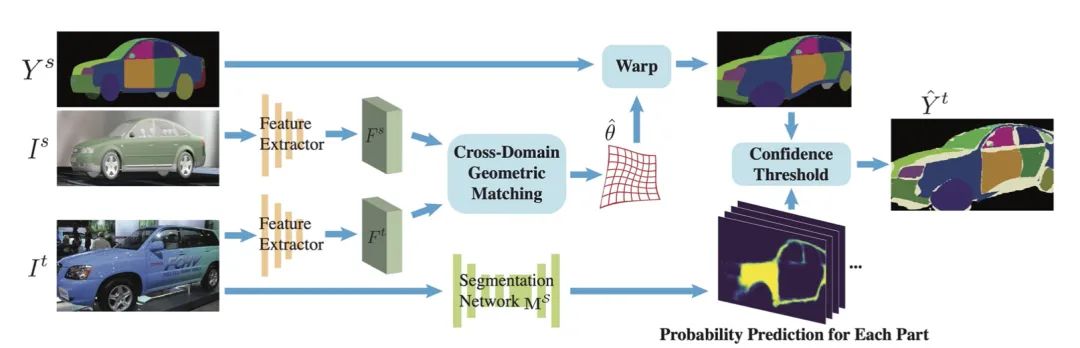
【3】Learning Part Segmentation through Unsupervised Domain Adaptation from Synthetic Vehicles
dataset:https://qliu24.github.io/udapart
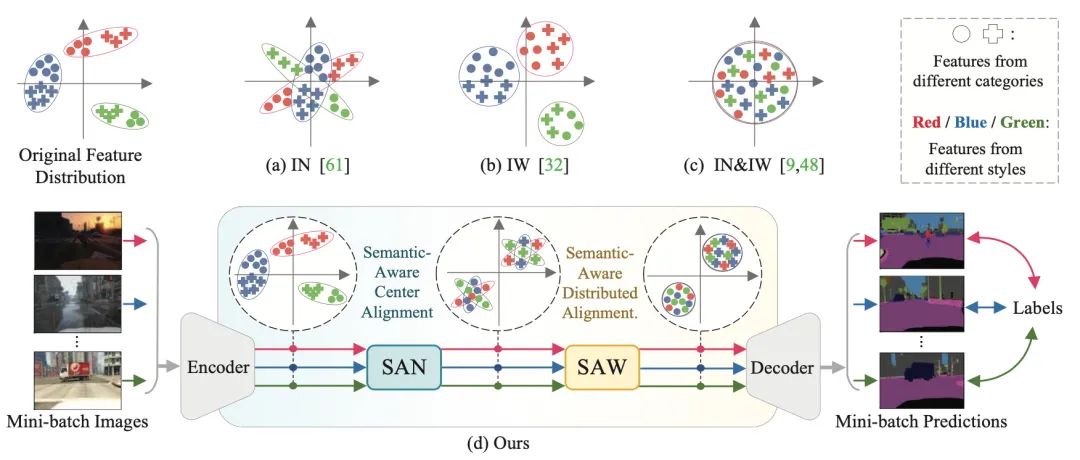
【4】Semantic-Aware Domain Generalized Segmentation
code:https://github.com/leolyj/SAN-SAW
【5】Revisiting Skeleton-based Action Recognition
code:https://github.com/kennymckormick/pyskl
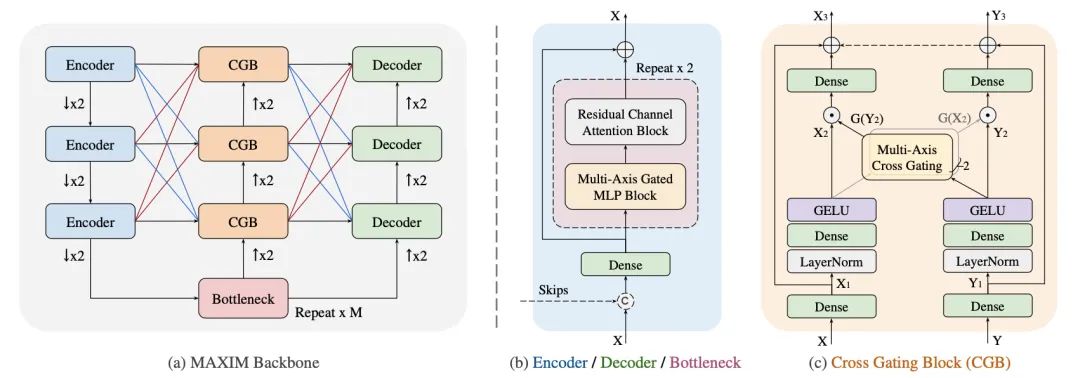
【6】MAXIM: Multi-Axis MLP for Image Processing
code:https://github.com/google-research/maxim
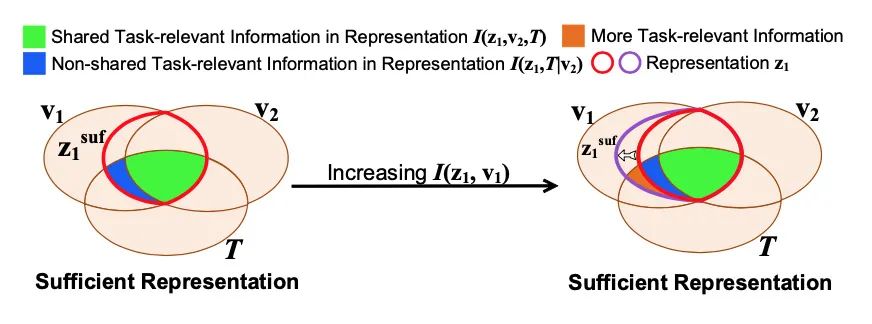
【7】Rethinking Minimal Sufficient Representation in Contrastive Learning
code:https://github.com/Haoqing-Wang/InfoCL
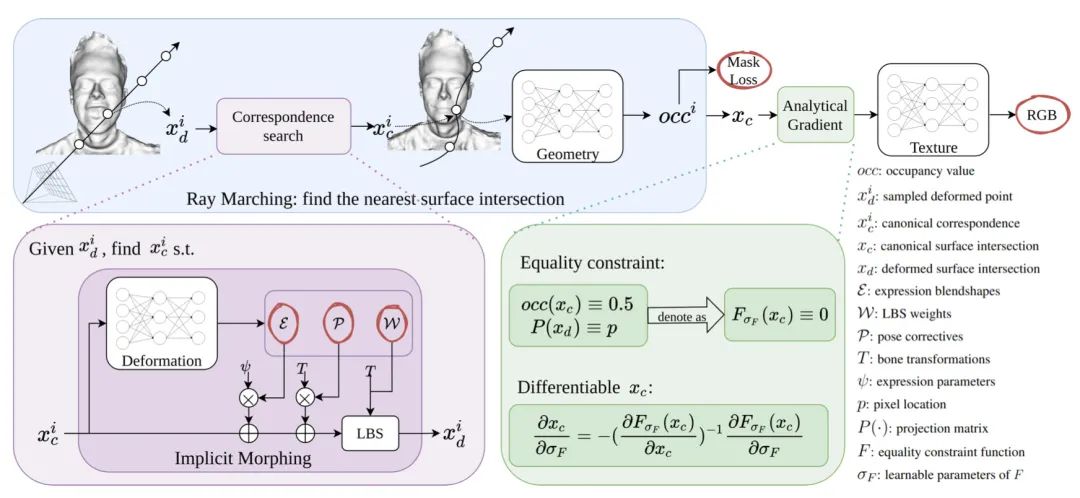
【8】 I M Avatar: Implicit Morphable Head Avatars from Videos
project:https://ait.ethz.ch/projects/2022/IMavatar/
【9】Parameter-free Online Test-time Adaptation
code:https://github.com/fiveai/LAME
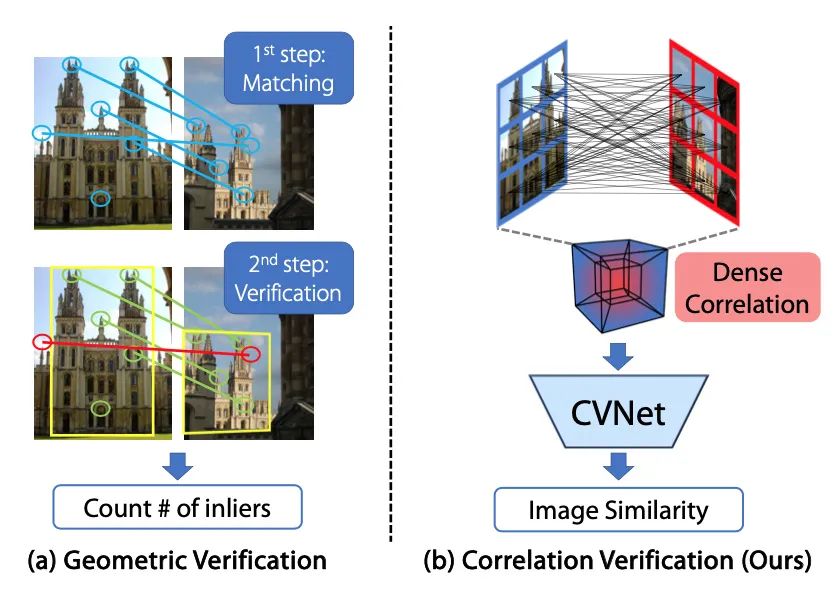
【10】Correlation Verification for Image Retrieval
code:https://github.com/sungonce/CVNet
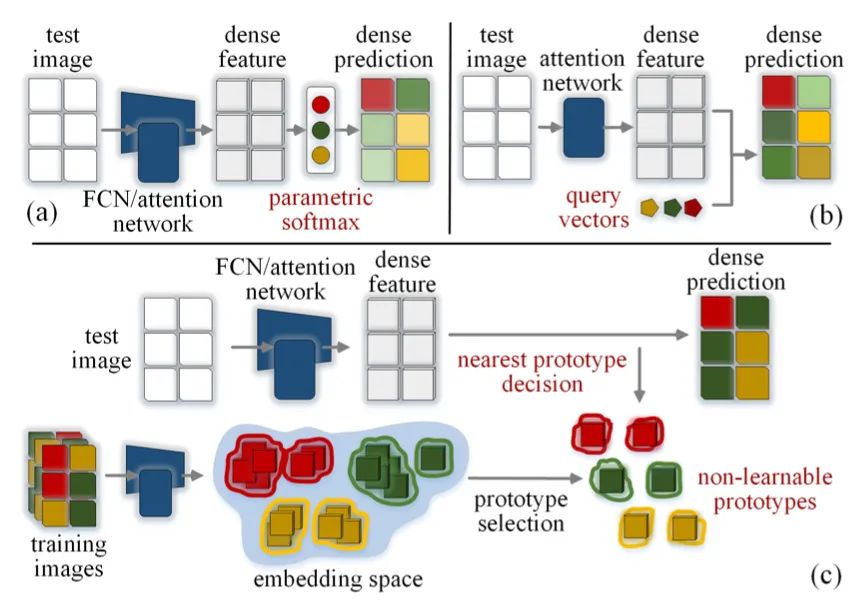
【11】Rethinking Semantic Segmentation: A Prototype View
code:https://github.com/tfzhou/ProtoSeg
【12】SNUG: Self-Supervised Neural Dynamic Garments
project:http://mslab.es/projects/SNUG/

【13】SelfRecon: Self Reconstruction Your Digital Avatar from Monocular Video
code:https://github.com/jby1993/SelfReconCode
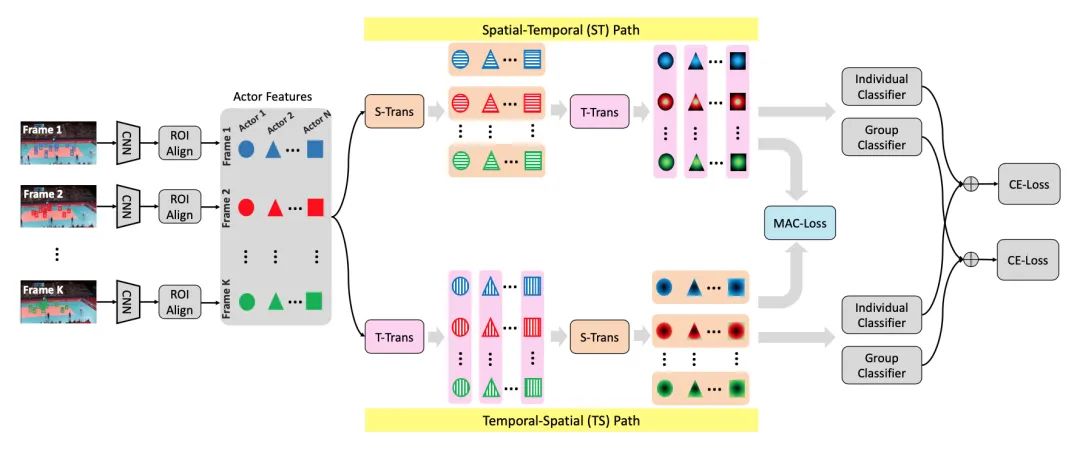
【14】Dual-AI: Dual-path Action Interaction Learning for Group Activity Recognition
project:https://arxiv.org/pdf/2204.02148
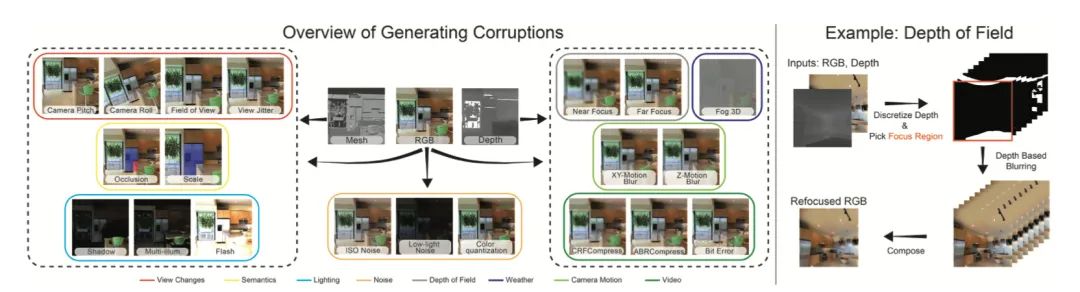
【15】3D Common Corruptions and Data Augmentation
project:https://3dcommoncorruptions.epfl.ch/
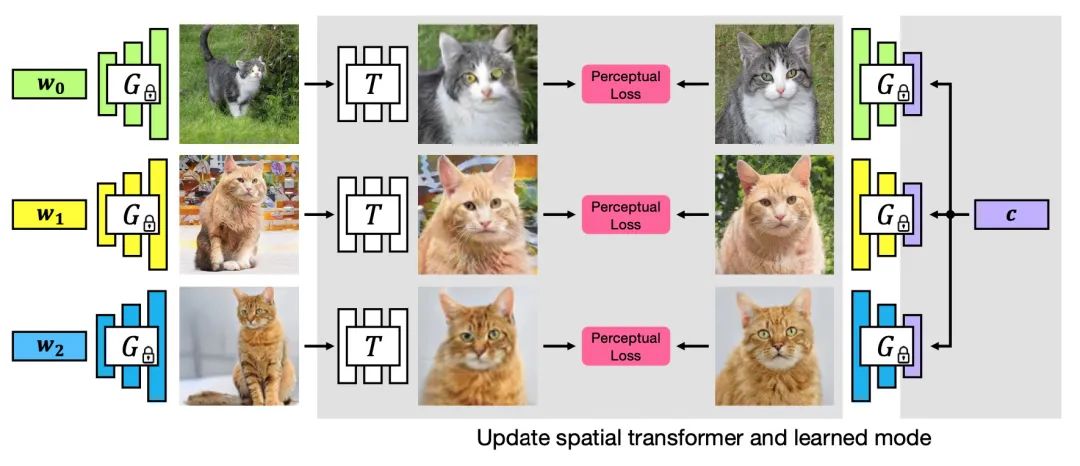
【16】GAN-Supervised Dense Visual Alignment
code:https://www.github.com/wpeebles/gangealing
project:https://www.wpeebles.com/gangealing
【17】It's All In the Teacher: Zero-Shot Quantization Brought Closer to the Teacher
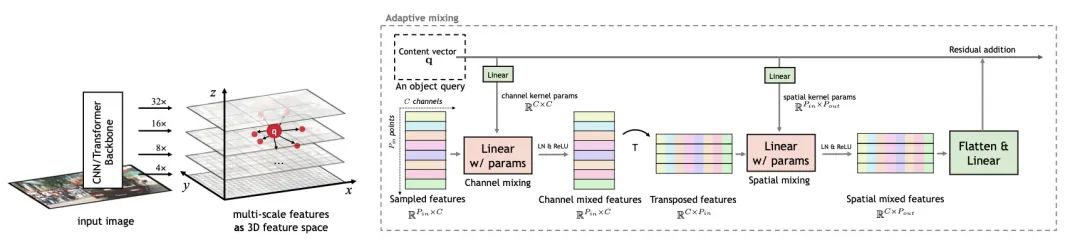
【18】AdaMixer: A Fast-Converging Query-Based Object Detector
code:https://github.com/MCG-NJU/AdaMixer
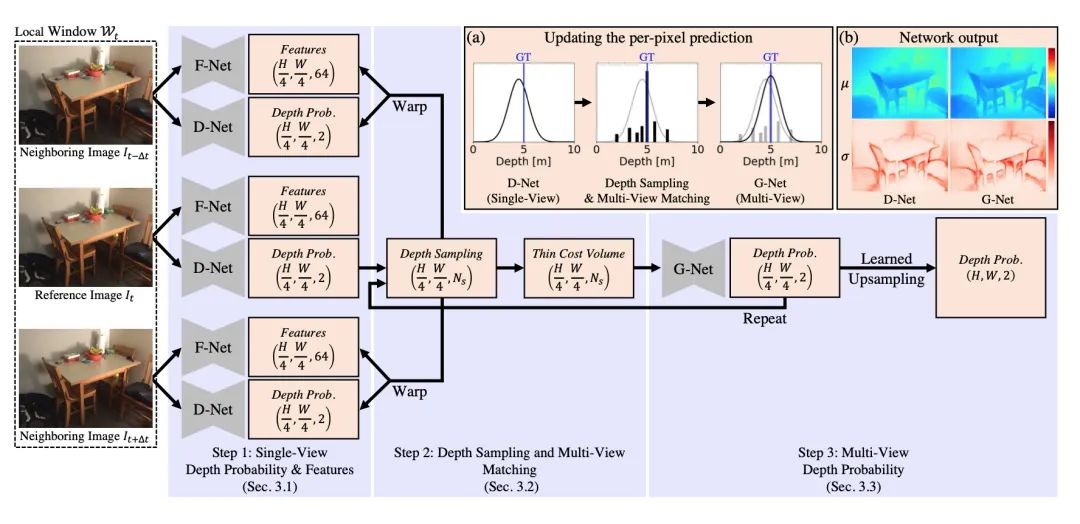
【19】Multi-View Depth Estimation by Fusing Single-View Depth Probability with Multi-View Geometry
code:https://github.com/baegwangbin/MaGNet
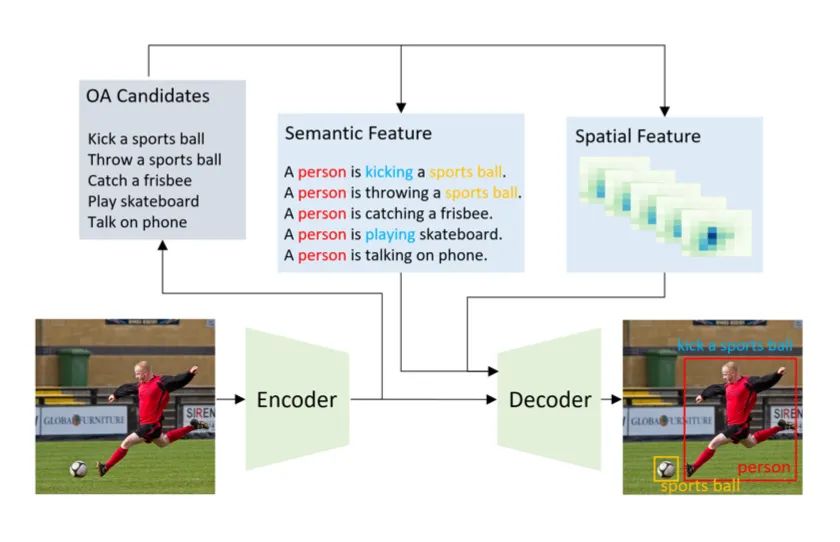
【20】 What to look at and where: Semantic and Spatial Refined Transformer for detecting human-object interactions
评论