肝|打补丁,顺便拓展下爬取公众号历史文章合并成一个PDF
↑↑↑关注后"星标"简说Python
人人都可以简单入门Python、爬虫、数据分析 简说Python发布 来源:简说Python 作者:老表
大家好,我是老表!
本文是对前天发布的文章搞定,爬取公众号文章转换成PDF,自动邮件发送给自己!的修正。
写在前面
搞定,爬取公众号文章转换成PDF,自动邮件发送给自己!文章发布后获得了不少读者朋友的好评,开心,不枉我回杭坐车一天写下该文章,更开心的是有不少读者朋友提出了一些问题,说明确实对大家有帮助,大家也实践了,今天这篇文章就是对一位读者发现的脚本bug的补丁。
很巧,又是在车上写下的!(两个下班路上+加夜工写完本文)
看到这里先划到文章末尾给本文点个赞和在看,留言:优秀,不过分吧,大家的支持就是我一直肝的动力。
开始动手动脑
首先明确下问题,这里也感谢下读者另外半只🐰提出的问题:非二十次幂会员用户登录后也无法从教程中的接口中获取数据,也就无法获取到公众号文章链接和标题了,我尝试新账号登录后发现确实是这样,之前大意了!!!
知道问题后,我就开始想解决方法了,正好也有读者加我微信了,问我相关问题,他已经爬取到了微信公众号文章链接和标题存在Excel中,他希望将内容转到word中,这我一想,这不正好互补吗哈哈哈哈。 找读者问了下他的爬取方法,他用的是之前文章提到的从微信公众号后台爬取,需要大家注册微信公众号,比较麻烦,所以最终略过了这个方案。
找读者问了下他的爬取方法,他用的是之前文章提到的从微信公众号后台爬取,需要大家注册微信公众号,比较麻烦,所以最终略过了这个方案。
正在我一筹莫展之时,公众号文章多了条留言。
志军大佬提供了个新接口,可以从https://www.ershicimi.com/a/EOdxnBO4 这里获取公众号文章链接和标题,直呼优秀!
分析新页面
https://www.ershicimi.com/a/EOdxnBO4
访问上方链接进入页面发现不用登录也能看到第一页的数据了,直呼优秀。(看到这里的读者请先将 优秀 二字 打在文末留言区)
数据都在页面上,我们直接利用requests发送一个get请求即可。
import requests
# bid=EOdxnBO4 表示公众号 简说Python,每个公众号都有对应的bid,可以直接搜索查看
url1 = 'https://www.ershicimi.com/a/EOdxnBO4'
r = requests.get(url1)
r.text
接下来我们需要解析网页,从其中提取出我们需要的数据:
最新发布文章标题 最新发布文章发布时间 最新发布文章对应链接
解析网页提取数据的方法很多,比较常用的有正则表达式、Xpath、CSS选择器等,网页标签十分规则,我们利用Xpath来提取数据。
from lxml import etree
# 把html的文本内容解析成html对象
html = etree.HTML(r.text)
# xpath 根据标签路径提取数据
html.xpath('//*[@id="wrapper"]/div/div[2]/div[1]/div[2]/div/div[1]/div/div/h4/a/text()')
输出:
[' 入门Pandas不可不知的技巧',
' 搞定,爬取公众号文章转换成PDF,自动邮件发送给自己!',
' PyPy为什么能让Python原地起飞,速度比C还快!',
...
' 给大家分享一个私藏已久的Python神器!']
这样我们就轻松的获取到了公众号简说Python近期推文的标题,接下来我们还要获取每篇文章对应的 发布时间和链接。
在此之前我们先来说说代码中的Xpath路径是如何获取到的,检索原理是什么?
在页面中,我们按住F12,调出浏览器的开发者工具,点击左上角的元素选择器,然后随便选择页面中的一个文章标题,选中后,开发者工具中的Elements会自动跳动到对应的页面源码处,如下图所示: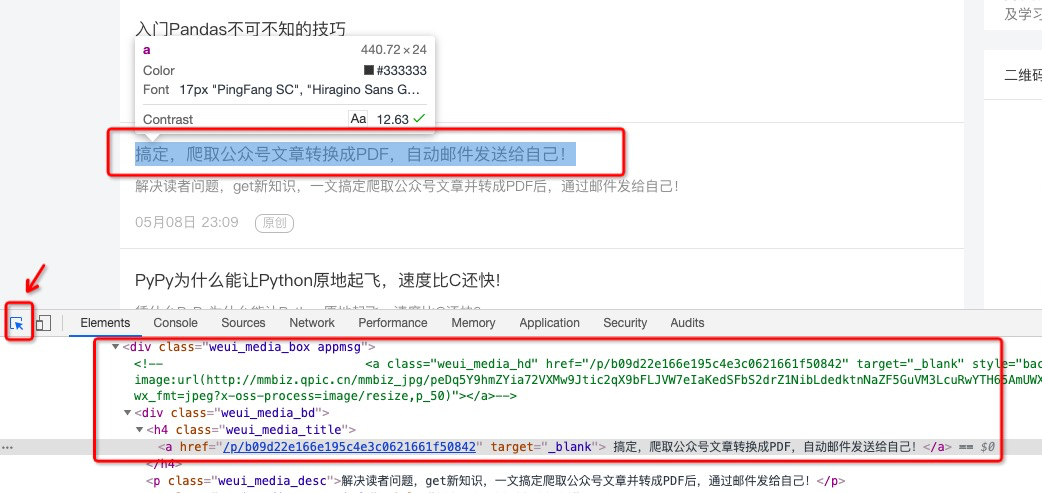
选中源码中对应内容,右键,选择Copy中的Copy XPath,即可复制出对应元素对应的XPath路径。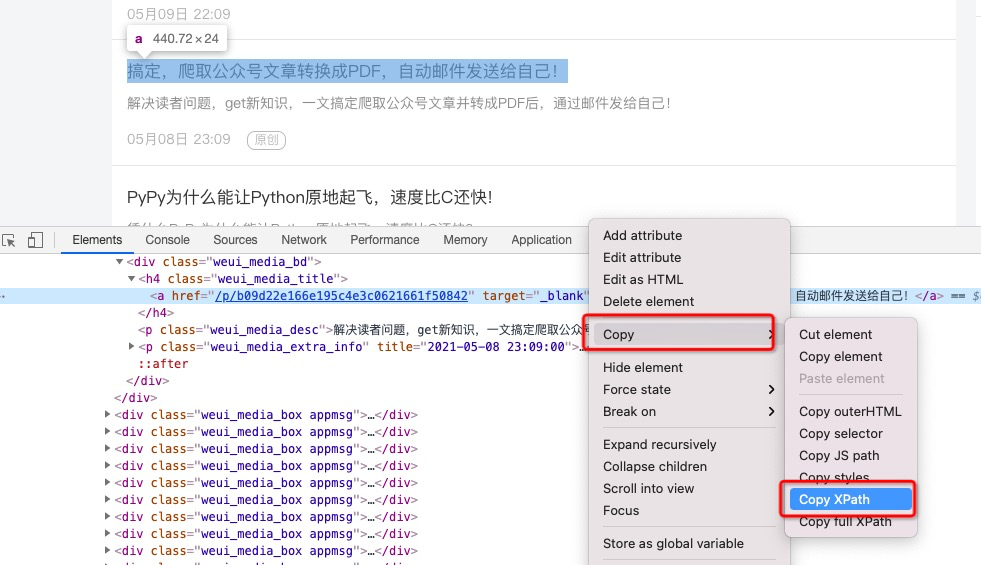
那如何获取到所有标题对应的XPath路径呢?需要一个个通过XPath路径来获取对应内容吗?
手动一个个复制肯定不切实际,其实很简单,我们先按上面方法在复制一个标题的XPath路径。
//*[@id="wrapper"]/div/div[2]/div[1]/div[2]/div/div[1]/div[3]/div/h4/a
//*[@id="wrapper"]/div/div[2]/div[1]/div[2]/div/div[1]/div[4]/div/h4/a
我们来观察下,会很快发现两个路径的区别在于倒数第二个div标签后面的数字不同,获取所有标题内容的方法就是直接给一个通用的XPath路径,直接去掉倒数第二个div后的中括号和数字即可,除此外还需要在路径后加上/text(),这样就可以提取出对应的内容了。
//*[@id="wrapper"]/div/div[2]/div[1]/div[2]/div/div[1]/div/div/h4/a/text()
同理我们可以获取到发布时间和对应文章链接的XPath通用路径,并获取对应数据,将之前代码中的get_data函数代码改为下面的即可,其他内容不需要修改。
'''
1、从二十次幂获取公众号最新的推文链接和标题(新接口,解决必须会员才看的到数据问题)
'''
def get_data(publish_date):
# bid=EOdxnBO4 表示公众号 简说Python,每个公众号都有对应的bid,可以直接搜索查看
url1 = 'https://www.ershicimi.com/a/EOdxnBO4'
r = requests.get(url1)
# 把html的文本内容解析成html对象
html = etree.HTML(r.text)
# xpath 根据标签路径提取数据
title = html.xpath('//*[@id="wrapper"]/div/div[2]/div[1]/div[2]/div/div[1]/div/div/h4/a/text()') # 标题
publish_time = html.xpath('//*[@id="wrapper"]/div/div[2]/div[1]/div[2]/div/div[1]/div/div/p[2]/@title') # 发布时间
title_url = html.xpath('//*[@id="wrapper"]/div/div[2]/div[1]/div[2]/div/div[1]/div/div/h4/a/@href') # 文章链接
# 对数据进行简单处理,选取最新发布的数据
data = []
for i in range(len(publish_time)):
if publish_date in publish_time[i]:
article = {}
article['content_url'] = 'https://www.ershicimi.com' + title_url[i]
article['title'] = title[i]
data.append(article)
return data
项目完整代码可以查看之前的文章获取,或者直接扫文末二维码加我微信获取。
拓展需求
爬取某个公众号全部文章,转成PDF教程集合
搞定了爬取最新文章转换成PDF,再来做爬取某个公众号全部文章,转成PDF教程集合就简单多了。
基本思路: 翻页爬取所有文章链接和标题--然后依次转换成pdf--合并所有PDF。
根据志军大佬提供的接口爬取第一页是没问题的,翻页会提示需要登录,参考第一篇文章解释,直接获取Cookie破解这个反爬虫措施是最简单的,模拟登录我也看了,有个动态参数csrf_token,有兴趣的同学可以看看如何破解。
0)导入需要的库
import requests # 发送get/post请求,获取网站内容
import wechatsogou # 微信公众号文章爬虫框架
import datetime # 日期数据处理模块
import pdfkit # 可以将文本字符串/链接/文本文件转换成为pdf
import os # 系统文件管理
import re # 正则匹配模块
import sys # 项目进程管理
from lxml import etree # 把html的文本内容解析成html对象
import time # 时间模块
from PyPDF2 import PdfFileReader, PdfFileWriter # pdf读取、写入操作模块
1)翻页爬取所有文章链接和标题
代码如下:
'''
1、从二十次幂获取公众号所有的推文链接和标题
'''
# 自动获取公众号文章总页数
def get_page_num():
# bid=EOdxnBO4 表示公众号 简说Python,每个公众号都有对应的bid,可以直接搜索查看
url1 = 'https://www.ershicimi.com/a/EOdxnBO4'
r = requests.get(url1)
# 把html的文本内容解析成html对象
html = etree.HTML(r.text)
# xpath 根据标签路径提取数据
page_num = html.xpath('//*[@id="wrapper"]/div/div[2]/div[1]/div[2]/div/div[2]/a/text()')
return int(page_num[-2]) # 放回倒数第二个元素,就是总页数
# 将title,publish_time,content_url数据格式化成我们想要的形式
def merge_data(title,publish_time,content_url):
data = []
for i in range(len(title)):
html_data ={}
html_data['title'] = title[i]
html_data['publish_time'] = publish_time[i]
html_data['content_url'] = 'https://www.ershicimi.com' + content_url[i]
data.append(html_data)
return data
# 获取数据
def get_data():
# 手动获取登录后的Cookie 保持登录状态
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36",
"Cookie":"登录后自己获取下,第一篇教程有详细说明"
}
# bid=EOdxnBO4 表示公众号 简说Python,每个公众号都有对应的bid,可以直接搜索查看
# 循环获取所有数据
page_num = get_page_num()
html_data = []
for i in range(page_num):
url1 = 'https://www.ershicimi.com/a/EOdxnBO4?page=%d'%(i+1)
print(url1)
r = requests.get(url1,headers=headers)
# 把html的文本内容解析成html对象
html = etree.HTML(r.text)
# xpath 根据标签路径提取数据
title = html.xpath('//*[@id="wrapper"]/div/div[2]/div[1]/div[2]/div/div[1]/div/div/h4/a/text()') # 标题
publish_time = html.xpath('//*[@id="wrapper"]/div/div[2]/div[1]/div[2]/div/div[1]/div/div/p[2]/@title') # 发布时间
content_url = html.xpath('//*[@id="wrapper"]/div/div[2]/div[1]/div[2]/div/div[1]/div/div/h4/a/@href') # 文章链接
html_data = html_data + merge_data(title,publish_time,content_url)
print("第%d页数据获取完成"%(i+1))
time.sleep(1) # 每隔1s 发送一次请求
return html_data
2)然后依次转换成pdf
代码不变,和第一篇教程一样。
'''
2、for循环遍历,将每篇文章转化为pdf
'''
# 转化url为pdf时,调用wechatsogou中的get_article_content函数,将url中的代码提取出来转换为html字符串
# 这里先初始化一个WechatSogouAPI对象
ws_api = wechatsogou.WechatSogouAPI(captcha_break_time=3)
def url_to_pdf(url, title, targetPath, publish_date):
'''
使用pdfkit生成pdf文件
:param url: 文章url
:param title: 文章标题
:param targetPath: 存储pdf文件的路径
:param publish_date: 文章发布日期,作为pdf文件名开头(标识)
'''
try:
content_info = ws_api.get_article_content(url)
except:
return False
# 处理后的html
html = f'''
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>{title}</title>
</head>
<body>
<h2 style="text-align: center;font-weight: 400;">{title}</h2>
{content_info['content_html']}
</body>
</html>
'''
# html字符串转换为pdf
filename = publish_date + '-' + title
# 部分文章标题含特殊字符,不能作为文件名
# 去除标题中的特殊字符 win / \ : * " < > | ?mac :
# 先用正则去除基本的特殊字符,python中反斜线很烦,最后用replace函数去除
filename = re.sub('[/:*"<>|?]','',filename).replace('\\','')
pdfkit.from_string(html, targetPath + os.path.sep + filename + '.pdf')
return filename # 返回存储路径,后面邮件发送附件需要
3)合并所有PDF
合并PDF我们使用了PyPDF2这个库,合并pdf的需求最早是合并自己的打车发票和行程单,代码引用了CSDN山阴少年大佬的文章Python之合并PDF文件中的代码,这里也非常适用,就直接拿过来了。
基本思路就是利用PyPDF2的PdfFileReader先依次读取pdf内容,然后利用PdfFileWriter写入,PyPDF2更详细用法和说明可以参考官方文档。
'''
3、合并所有的pdf
'''
# 使用os模块的walk函数,搜索出指定目录下的全部PDF文件
# 获取同一目录下的所有PDF文件的绝对路径
def getFileName(filedir):
file_list = [os.path.join(root, filespath) \
for root, dirs, files in os.walk(filedir) \
for filespath in files \
if str(filespath).endswith('pdf')
]
file_list.sort() # 排序
return file_list if file_list else []
# 合并同一目录下的所有PDF文件
def MergePDF(filepath, outfile):
output = PdfFileWriter()
outputPages = 0
pdf_fileName = getFileName(filepath)
if pdf_fileName:
for pdf_file in pdf_fileName:
# print("路径:%s"%pdf_file)
# 读取源PDF文件
input = PdfFileReader(open(pdf_file, "rb"))
# 获得源PDF文件中页面总数
pageCount = input.getNumPages()
outputPages += pageCount
# print("页数:%d"%pageCount)
# 分别将page添加到输出output中
for iPage in range(pageCount):
output.addPage(input.getPage(iPage))
print("合并后的总页数:%d."%outputPages)
# 写入到目标PDF文件
outputStream = open(os.path.join(filepath, outfile), "wb")
output.write(outputStream)
outputStream.close()
print("PDF文件合并完成!")
else:
print("没有可以合并的PDF文件!")
随便说说
只要大家支持,老表就能无限肝,大家如果有什么类似需求,或者想要本文所有相代码的ipynb文件,可以扫下方二维码添加我的微信,查看朋友圈获取。
欢迎大家进行学习交流,需求描述越明确,被选中的机率越高。
参考链接
wechatsogou
https://github.com/Chyroc/WechatSogou二十次幂平台
https://www.ershicimi.com/博客园xuzifan
https://www.cnblogs.com/xuzifan/p/11121878.htmlwkhtmltopdf下载地址
https://wkhtmltopdf.org/downloads.htmlSDN山阴少年大佬的文章Python之合并PDF文件
https://blog.csdn.net/jclian91/article/details/80362937搞定,爬取公众号文章转换成PDF,自动邮件发送给自己!
https://mp.weixin.qq.com/s/5ESrllgYExG0VJ9giCOp0w
扫码即可加我微信
观看朋友圈,获取最新学习资源
学习更多: 整理了我开始分享学习笔记到现在超过250篇优质文章,涵盖数据分析、爬虫、机器学习等方面,别再说不知道该从哪开始,实战哪里找了
“点赞”传统美德不能丢