
RxJS:给你如丝一般顺滑的编程体验(建议收藏)

转自:陌小路
juejin.cn/post/6910943445569765384
前言
怀着对于RxJS这项技术的好奇,笔者花了数天时间研究了这项技术,并肝了一包枸杞才完成这篇文章的撰写,属实不易。不过也正是通过这段时间的学习,我发现这项技术在一定程度上可以解决我在日常业务中遇到的一些痛点,以及有种想马上应用到自己的新项目中的欲望,的确这种以数据流的理念来管控大型项目中的数据能给人带来一种十分优雅的编程体验。
如果看完觉得有收获,希望给笔者一个赞呀😘
概念
RxJS 是 Reactive Extensions for JavaScript 的缩写,起源于 Reactive Extensions,是一个基于可观测数据流 Stream 结合观察者模式和迭代器模式的一种异步编程的应用库。RxJS 是 Reactive Extensions 在 JavaScript 上的实现。
注意!它跟
React没啥关系,笔者最初眼花把它看成了React.js的缩写(耻辱啊!!!)
对于陌生的技术而言,我们一般的思路莫过于,打开百度(google),搜索,然后查看官方文档,或者从零散的博客当中,去找寻能够理解这项技术的信息。但在很多时候,仅从一些只言片语中,的确也很难真正了解到一门技术的来龙去脉。
本文将从学习的角度来解析这项技术具备的价值以及能给我们现有项目中带来的好处。
背景
从开发者角度来看,对于任何一项技术而言,我们经常会去谈论的,莫过于以下几点:
应用场景? 如何落地? 上手难易程度如何? 为什么需要它?它解决了什么问题?
针对以上问题,我们可以由浅入深的来刨析一下RxJS的相关理念。
应用场景?
假设我们有这样一个需求:
我们上传一个大文件之后,需要实时监听他的进度,并且待进度进行到100的时候停止监听。
对于一般的做法我们可以采用短轮询的方式来实现,在对于异步请求的封装的时候,如果我们采用Promise的方式,那么我们一般的做法就可以采用编写一个用于轮询的方法,获取返回值进行处理,如果进度没有完成则延迟一定时间再次调用该方法,同时在出现错误的时候需要捕获错误并处理。
显然,这样的处理方式无疑在一定程度上给开发者带来了一定开发和维护成本,因为这个过程更像是我们在观察一个事件,这个事件会多次触发并让我感知到,不仅如此还要具备取消订阅的能力,Promise在处理这种事情时的方式其实并不友好,而RxJS对于异步数据流的管理就更加符合这种范式。
引用尤大的话:
我个人倾向于在适合
Rx的地方用Rx,但是不强求Rx for everything。比较合适的例子就是比如多个服务端实时消息流,通过Rx进行高阶处理,最后到view层就是很清晰的一个Observable,但是view层本身处理用户事件依然可以沿用现有的范式。
如何落地?
针对现有项目来说,如何与实际结合并保证原有项目的稳定性也的确是我们应该优先考虑的问题,毕竟任何一项技术如果无法落地实践,那么必然给我们带来的收益是比较有限的。
这里如果你是一名使用
Angular的开发者,或许你应该知道Angular中深度集成了Rxjs,只要你使用Angular框架,你就不可避免的会接触到RxJs相关的知识。
在一些需要对事件进行更为精确控制的场景下,比如我们想要监听点击事件(click event),但点击三次之后不再监听。
那么这个时候引入RxJS进行功能开发是十分便利而有效的,让我们能省去对事件的监听并且记录点击的状态,以及需要处理取消监听的一些逻辑上的心理负担。
你也可以选择为你的大型项目引入RxJS进行数据流的统一管理规范,当然也不要给本不适合RxJS理念的场景强加使用,这样实际带来的效果可能并不明显。
上手难易程度如何?
如果你是一名具备一定开发经验的JavaScript开发者,那么几分钟或许你就能将RxJS应用到一些简单的实践中了。
为什么需要它?它解决了什么问题?
如果你是一名使用JavaScript的开发者,在面对众多的事件处理,以及复杂的数据解析转化时,是否常常容易写出十分低效的代码或者是臃肿的判断以及大量脏逻辑语句?
不仅如此,在JavaScript的世界里,就众多处理异步事件的场景中来看,“麻烦”两个字似乎经常容易被提起,我们可以先从JS的异步事件的处理方式发展史中来细细品味RxJS带来的价值。

回调函数时代(callback)
使用场景:
事件回调 Ajax请求Node APIsetTimeout、setInterval等异步事件回调
在上述场景中,我们最开始的处理方式就是在函数调用时传入一个回调函数,在同步或者异步事件完成之后,执行该回调函数。可以说在大部分简单场景下,采用回调函数的写法无疑是很方便的,比如我们熟知的几个高阶函数:
forEachmapfilter
[1, 2, 3].forEach(function (item, index) {
console.log(item, index);
})
他们的使用方式只需要我们传入一个回调函数即可完成对一组数据的批量处理,很方便也很清晰明了。
但在一些复杂业务的处理中,我们如果仍然秉持不抛弃不放弃的想法顽强的使用回调函数的方式就可能会出现下面的情况:
fs.readFile('a.txt', 'utf-8', function(err, data) {
fs.readFile('b.txt', 'utf-8', function(err, data1) {
fs.readFile('c.txt', 'utf-8', function(err, data2) {
// ......
})
})
})
当然作为编写者来说,你可能觉得说这个很清晰啊,没啥不好的。但是如果再复杂点呢,如果调用的函数都不一样呢,如果每一个回调里面的内容都十分复杂呢。短期内自己可能清楚为什么这么写,目的是什么,但是过了一个月、三个月、一年后,你确定在众多业务代码中你还能找回当初的本心吗?
你会不会迫不及待的查找提交记录,这是哪个憨批写的,跟
shit......,卧槽怎么是我写的。
这时候,面对众多开发者苦不堪言的回调地域,终于还是有人出来造福人类了......
Promise时代
Promise最初是由社区提出(毕竟作为每天与奇奇怪怪的业务代码打交道的我们来说,一直用回调顶不住了啊),后来官方正式在ES6中将其加入语言标准,并进行了统一规范,让我们能够原生就能new一个Promise。
就优势而言,Promise带来了与回调函数不一样的编码方式,它采用链式调用,将数据一层一层往后抛,并且能够进行统一的异常捕获,不像使用回调函数就直接炸了,还得在众多的代码中一个个try catch。
话不多说,看码!
function readData(filePath) {
return new Promise((resolve, reject) => {
fs.readFile(filePath, 'utf-8', (err, data) => {
if (err) reject(err);
resolve(data);
})
});
}
readData('a.txt').then(res => {
return readData('b.txt');
}).then(res => {
return readData('c.txt');
}).then(res => {
return readData('d.txt');
}).catch(err => {
console.log(err);
})
对比一下,这种写法会不会就更加符合我们正常的思维逻辑了,这种顺序下,让人看上去十分舒畅,也更利于代码的维护。
优点:
状态改变就不会再变,任何时候都能得到相同的结果 将异步事件的处理流程化,写法更方便
缺点:
无法取消 错误无法被 try catch(但是可以使用.catch方式)当处于 pending状态时无法得知现在处在什么阶段
虽然Promise的出现在一定程度上提高了我们处理异步事件的效率,但是在需要与一些同步事件的进行混合处理时往往我们还需要面临一些并不太友好的代码迁移,我们需要把原本放置在外层的代码移到Promise的内部才能保证某异步事件完成之后再进行继续执行。
Generator函数
ES6 新引入了 Generator 函数,可以通过 yield 关键字,把函数的执行流挂起,为改变执行流程提供了可能,从而为异步编程提供解决方案。形式上也是一个普通函数,但有几个显著的特征:
function关键字与函数名之间有一个星号 "*" (推荐紧挨着function关键字)函数体内使用 yield· 表达式,定义不同的内部状态 (可以有多个yield`)直接调用 Generator函数并不会执行,也不会返回运行结果,而是返回一个遍历器对象(Iterator Object)依次调用遍历器对象的 next方法,遍历Generator函数内部的每一个状态
function* read(){
let a= yield '666';
console.log(a);
let b = yield 'ass';
console.log(b);
return 2
}
let it = read();
console.log(it.next()); // { value:'666',done:false }
console.log(it.next()); // { value:'ass',done:false }
console.log(it.next()); // { value:2,done:true }
console.log(it.next()); // { value: undefined, done: true }
这种模式的写法我们可以自由的控制函数的执行机制,在需要的时候再让函数执行,但是对于日常项目中来说,这种写法也是不够友好的,无法给与使用者最直观的感受。
async / await
相信在经过许多面试题的洗礼后,大家或多或少应该也知道这玩意其实就是一个语法糖,内部就是把Generator函数与自动执行器co进行了结合,让我们能以同步的方式编写异步代码,十分畅快。
有一说一,这玩意着实好用,要不是要考虑兼容性,真就想大面积使用这种方式。
再来看看用它编写的代码有多快乐:
async readFileData() {
const data = await Promise.all([
'异步事件一',
'异步事件二',
'异步事件三'
]);
console.log(data);
}
直接把它当作同步方式来写,完全不要考虑把一堆代码复制粘贴的一个其他异步函数内部,属实简洁明了。
RxJS
它在使用方式上,跟Promise有点像,但在能力上比Promise强大多了,不仅仅能够以流的形式对数据进行控制,还内置许许多多的内置工具方法让我们能十分方便的处理各种数据层面的操作,让我们的代码如丝一般顺滑。
优势:
代码量的大幅度减少 代码可读性的提高 很好的处理异步 事件管理、调度引擎 十分丰富的操作符 声明式的编程风格
function readData(filePath) {
return new Observable((observer) => {
fs.readFile(filePath, 'utf-8', (err, data) => {
if (err) observer.error(err);
observer.next(data);
})
});
}
Rx.Observable
.forkJoin(readData('a.txt'), readData('b.txt'), readData('c.txt'))
.subscribe(data => console.log(data));
这里展示的仅仅是RxJS能表达能量的冰山一角,对于这种场景的处理办法还有多种方式。RxJS 擅长处理异步数据流,而且具有丰富的库函数。对于RxJS而言,他能将任意的Dom事件,或者是Promise转换成observables。
前置知识点
在正式进入RxJS的世界之前,我们首先需要明确和了解几个概念:
响应式编程( Reactive Programming)流( Stream)观察者模式(发布订阅) 迭代器模式
响应式编程(Reactive Programming)
响应式编程(Reactive Programming),它是一种基于事件的模型。在上面的异步编程模式中,我们描述了两种获得上一个任务执行结果的方式,一个就是主动轮训,我们把它称为 Proactive 方式。另一个就是被动接收反馈,我们称为 Reactive。简单来说,在 Reactive 方式中,上一个任务的结果的反馈就是一个事件,这个事件的到来将会触发下一个任务的执行。
响应式编程的思路大概如下:你可以用包括 Click 和 Hover 事件在内的任何东西创建 Data stream(也称“流”,后续章节详述)。Stream 廉价且常见,任何东西都可以是一个 Stream:变量、用户输入、属性、Cache、数据结构等等。举个例子,想像一下你的 Twitter feed 就像是 Click events 那样的 Data stream,你可以监听它并相应的作出响应。
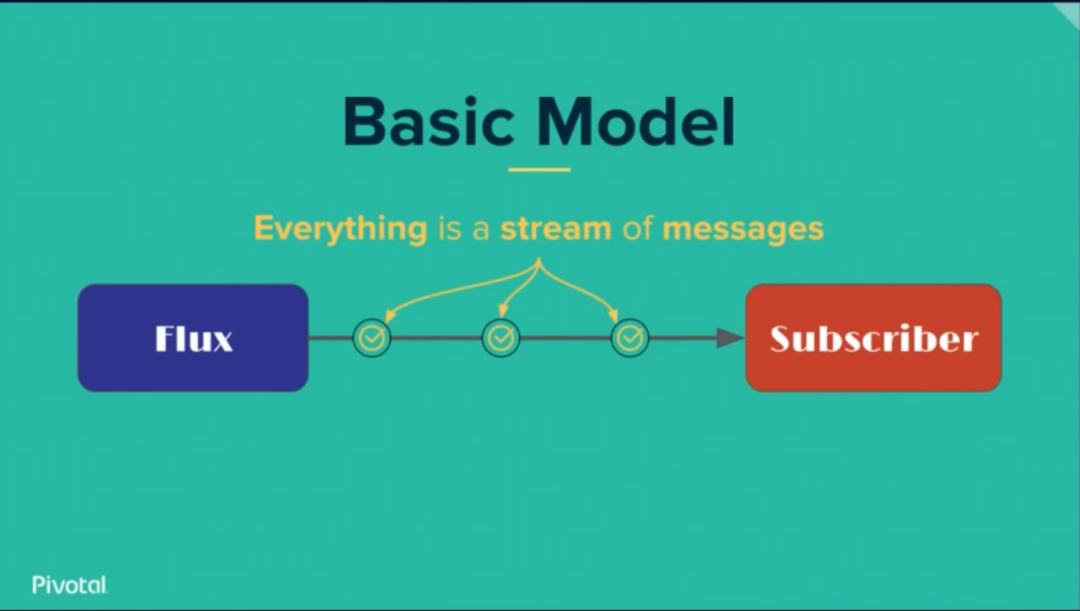
结合实际,如果你使用过Vue,必然能够第一时间想到,Vue的设计理念不也是一种响应式编程范式么,我们在编写代码的过程中,只需要关注数据的变化,不必手动去操作视图改变,这种Dom层的修改将随着相关数据的改变而自动改变并重新渲染。
流(Stream)
流作为概念应该是语言无关的。文件IO流,Unix系统标准输入输出流,标准错误流(stdin, stdout, stderr),还有一开始提到的 TCP 流,还有一些 Web 后台技术(如Nodejs)对HTTP请求/响应流的抽象,都可以见到流的概念。
作为响应式编程的核心,流的本质是一个按时间顺序排列的进行中事件的序列集合。
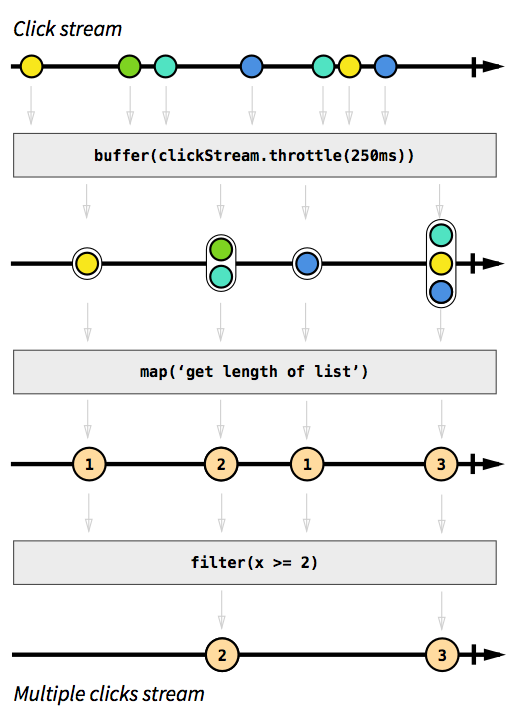
对于一流或多个流来说,我们可以对他们进行转化,合并等操作,生成一个新的流,在这个过程中,流是不可改变的,也就是只会在原来的基础返回一个新的stream。
观察者模式
在众多设计模式中,观察者模式可以说是在很多场景下都有着比较明显的作用。
观察者模式是一种行为设计模式, 允许你定义一种订阅机制, 可在对象事件发生时通知多个 “观察” 该对象的其他对象。
用实际的例子来理解,就比如你订了一个银行卡余额变化短信通知的服务,那么这个时候,每次只要你转账或者是购买商品在使用这张银行卡消费之后,银行的系统就会给你推送一条短信,通知你消费了多少多少钱,这种其实就是一种观察者模式,又称发布-订阅模式。
在这个过程中,银行卡余额就是被观察的对象,而用户就是观察者。
优点:
降低了目标与观察者之间的耦合关系,两者之间是抽象耦合关系。 符合依赖倒置原则。 目标与观察者之间建立了一套触发机制。 支持广播通信
不足:
目标与观察者之间的依赖关系并没有完全解除,而且有可能出现循环引用。 当观察者对象很多时,通知的发布会花费很多时间,影响程序的效率。
迭代器模式
迭代器(Iterator)模式又叫游标(Sursor)模式,在面向对象编程里,迭代器模式是一种设计模式,是一种最简单也最常见的设计模式。迭代器模式可以把迭代的过程从从业务逻辑中分离出来,它可以让用户透过特定的接口巡访容器中的每一个元素而不用了解底层的实现。
const iterable = [1, 2, 3];
const iterator = iterable[Symbol.iterator]();
iterator.next(); // => { value: "1", done: false}
iterator.next(); // => { value: "2", done: false}
iterator.next(); // => { value: "3", done: false}
iterator.next(); // => { value: undefined, done: true}
作为前端开发者来说,我们最常遇到的部署了iterator接口的数据结构不乏有:Map、Set、Array、类数组等等,我们在使用他们的过程中,均能使用同一个接口访问每个元素就是运用了迭代器模式。
Iterator作用:
为各种数据结构,提供一个统一的、简便的访问接口; 使得数据结构的成员能够按某种次序排列; 为新的遍历语法 for...of实现循环遍历
在许多文章中,有人会喜欢把迭代器和遍历器混在一起进行概念解析,其实他们表达的含义是一致的,或者可以说(迭代器等于遍历器)。
Observable
表示一个概念,这个概念是一个可调用的未来值或事件的集合。它能被多个observer订阅,每个订阅关系相互独立、互不影响。
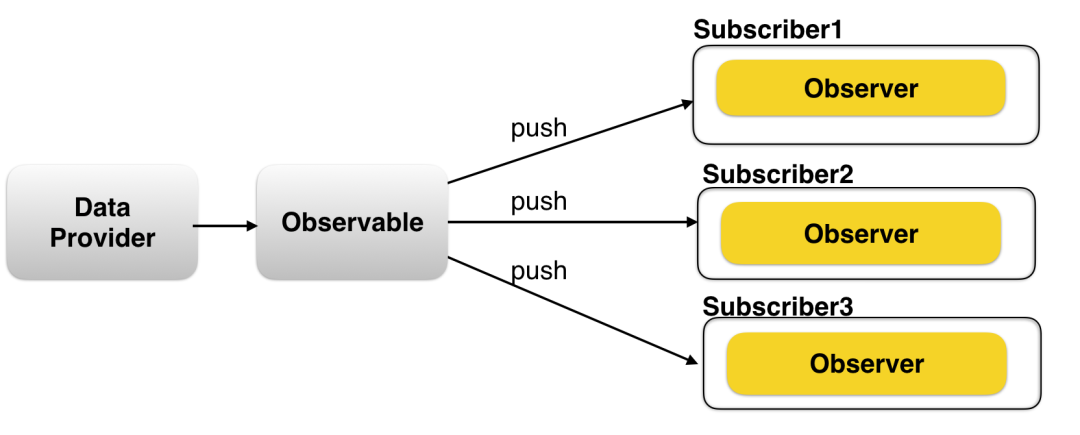
举个栗子:
假设你订阅了一个博客或者是推送文章的服务号(微信公众号之类的),之后只要公众号更新了新的内容,那么该公众号就会把新的文章推送给你,在这段关系中,这个公众号就是一个Observable,用来产生数据的数据源。
相信看完上面的描述,你应该对Observable是个什么东西有了一定的了解了,那么这就好办了,下面我们来看看在RxJS中如何创建一个Observable。
const Rx = require('rxjs/Rx')
const myObservable = Rx.Observable.create(observer => {
observer.next('foo');
setTimeout(() => observer.next('bar'), 1000);
});
我们可以调用Observable.create方法来创建一个Observable,这个方法接受一个函数作为参数,这个函数叫做 producer 函数, 用来生成 Observable 的值。这个函数的入参是 observer,在函数内部通过调用 observer.next() 便可生成有一系列值的一个 Observable。
我们先不应理会
observer是个什么东西,从创建一个Observable的方式来看,其实也就是调用一个API的事,十分简单,这样一个简单的Observable对象就创建出来了。
Observer
一个回调函数的集合,它知道如何去监听由Observable提供的值。Observer在信号流中是一个观察者(哨兵)的角色,它负责观察任务执行的状态并向流中发射信号。
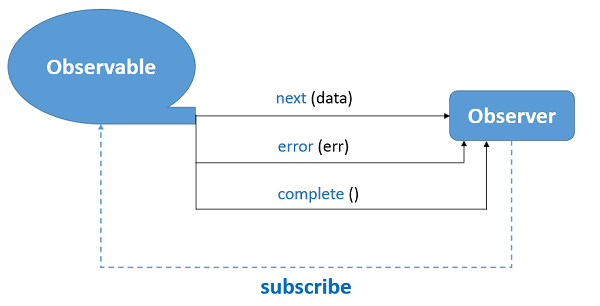
这里我们简单实现一下内部的构造:
const observer = {
next: function(value) {
console.log(value);
},
error: function(error) {
console.log(error)
},
complete: function() {
console.log('complete')
}
}
在RxJS中,Observer是可选的。在next、error 和 complete处理逻辑部分缺失的情况下,Observable仍然能正常运行,为包含的特定通知类型的处理逻辑会被自动忽略。
比如我们可以这样定义:
const observer = {
next: function(value) {
console.log(value);
},
error: function(error) {
console.log(error)
}
}
它依旧是可以正常的运行。
那么它又是怎么来配合我们在实际战斗中使用的呢:
const myObservable = Rx.Observable.create((observer) => {
observer.next('111')
setTimeout(() => {
observer.next('777')
}, 3000)
})
myObservable.subscribe((text) => console.log(text));
这里直接使用subscribe方法让一个observer订阅一个Observable,我们可以看看这个subscribe的函数定义来看看怎么实现订阅的:
subscribe(next?: (value: T) => void, error?: (error: any) => void, complete?: () => void): Subscription;
源码是用ts写的,代码即文档,十分清晰,这里笔者给大家解读一下,我们从入参来看,从左至右依次是next、error,complete,且是可选的,我们可以自己选择性的传入相关回调,从这里也就印证了我们上面所说next、error 和 complete处理逻辑部分缺失的情况下仍可以正常运行,因为他们都是可选的。
Subscription与Subject
Subscription
Subscription就是表示Observable的执行,可以被清理。这个对象最常用的方法就是unsubscribe方法,它不需要任何参数,只是用来清理由Subscription占用的资源。同时,它还有add方法可以使我们取消多个订阅。
const myObservable = Rx.Observable.create(observer => {
observer.next('foo');
setTimeout(() => observer.next('bar'), 1000);
});
const subscription = myObservable.subscribe(x => console.log(x));
// 稍后:
// 这会取消正在进行中的 Observable 执行
// Observable 执行是通过使用观察者调用 subscribe 方法启动的
subscription.unsubscribe();
Subject (主体)
它是一个代理对象,既是一个 Observable 又是一个 Observer,它可以同时接受 Observable 发射出的数据,也可以向订阅了它的 observer 发射数据,同时,Subject 会对内部的 observers 清单进行多播(multicast)
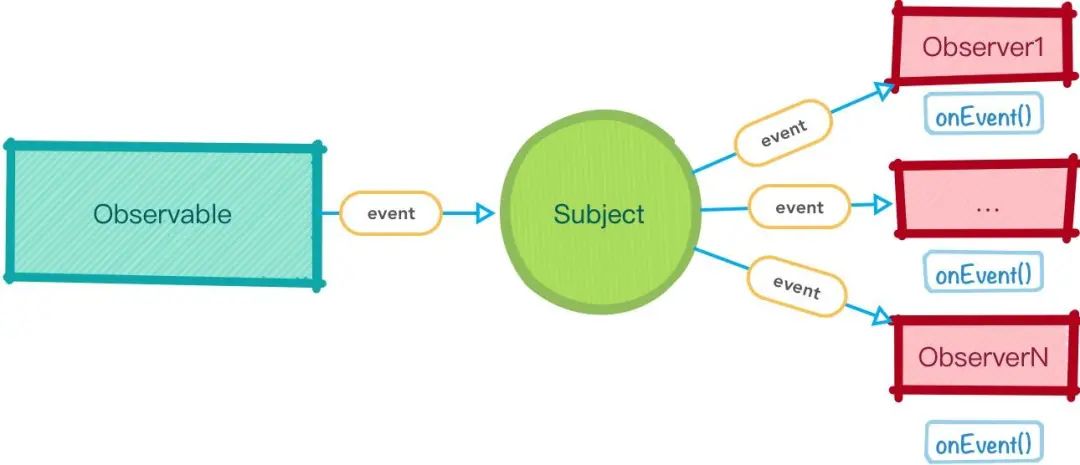
Subjects是将任意Observable执行共享给多个观察者的唯一方式
这个时候眼尖的读者会发现,这里产生了一个新概念——多播。
那么多播又是什么呢? 有了多播是不是还有单播? 他们的区别又是什么呢?
接下来就让笔者给大家好好分析这两个概念吧。
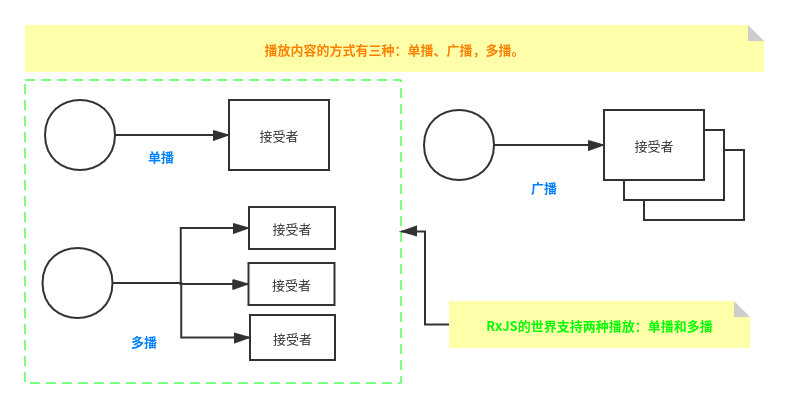
单播
普通的Observable 是单播的,那么什么是单播呢?
单播的意思是,每个普通的 Observables 实例都只能被一个观察者订阅,当它被其他观察者订阅的时候会产生一个新的实例。也就是普通 Observables 被不同的观察者订阅的时候,会有多个实例,不管观察者是从何时开始订阅,每个实例都是从头开始把值发给对应的观察者。
const Rx = require('rxjs/Rx')
const source = Rx.Observable.interval(1000).take(3);
source.subscribe((value) => console.log('A ' + value))
setTimeout(() => {
source.subscribe((value) => console.log('B ' + value))
}, 1000)
// A 0
// A 1
// B 0
// A 2
// B 1
// B 2
看到陌生的调用不要慌,后面会进行详细解析,这里的
source你可以理解为就是一个每隔一秒发送一个从0开始递增整数的Observable就行了,且只会发送三次(take操作符其实也就是限定拿多少个数就不在发送数据了。)。
从这里我们可以看出两个不同观察者订阅了同一个源(source),一个是直接订阅,另一个延时一秒之后再订阅。
从打印的结果来看,A从0开始每隔一秒打印一个递增的数,而B延时了一秒,然后再从0开始打印,由此可见,A与B的执行是完全分开的,也就是每次订阅都创建了一个新的实例。
在许多场景下,我们可能会希望B能够不从最初始开始接受数据,而是接受在订阅的那一刻开始接受当前正在发送的数据,这就需要用到多播能力了。
多播
那么如果实现多播能力呢,也就是实现我们不论什么时候订阅只会接收到实时的数据的功能。
可能这个时候会有小伙伴跳出来了,直接给个中间人来订阅这个源,然后将数据转发给A和B不就行了?
const source = Rx.Observable.interval(1000).take(3);
const subject = {
observers: [],
subscribe(target) {
this.observers.push(target);
},
next: function(value) {
this.observers.forEach((next) => next(value))
}
}
source.subscribe(subject);
subject.subscribe((value) => console.log('A ' + value))
setTimeout(() => {
subject.subscribe((value) => console.log('B ' + value))
}, 1000)
// A 0
// A 1
// B 1
// A 2
// B 2
先分析一下代码,A和B的订阅和单播里代码并无差别,唯一变化的是他们订阅的对象由source变成了subject,然后再看看这个subject包含了什么,这里做了一些简化,移除了error、complete这样的处理函数,只保留了next,然后内部含有一个observers数组,这里包含了所有的订阅者,暴露一个subscribe用于观察者对其进行订阅。
在使用过程中,让这个中间商subject来订阅source,这样便做到了统一管理,以及保证数据的实时性,因为本质上对于source来说只有一个订阅者。
这里主要是方便理解,简易实现了
RxJS中的Subject的实例,这里的中间人可以直接换成RxJS的Subject类实例,效果是一样的
const source = Rx.Observable.interval(1000).take(3);
const subject = new Rx.Subject();
source.subscribe(subject);
subject.subscribe((value) => console.log('A ' + value))
setTimeout(() => {
subject.subscribe((value) => console.log('B ' + value))
}, 1000)
同样先来看看打印的结果是否符合预期,首先A的打印结果并无变化,B首次打印的数字现在是从1开始了,也就当前正在传输的数据,这下满足了我们需要获取实时数据的需求了。
不同于单播订阅者总是需要从头开始获取数据,多播模式能够保证数据的实时性。
除了以上这些,RxJS还提供了Subject的三个变体:
BehaviorSubjectReplaySubjectAsyncSubject
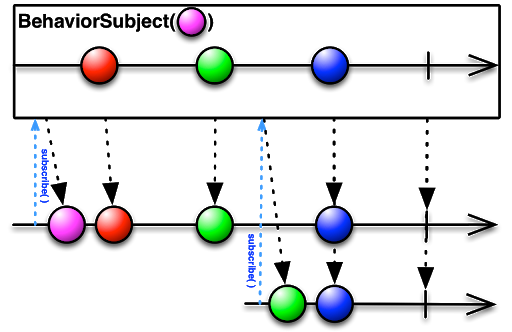
BehaviorSubject
BehaviorSubject 是一种在有新的订阅时会额外发出最近一次发出的值的Subject。
 ]
]
同样我们结合现实场景来进行理解,假设有我们需要使用它来维护一个状态,在它变化之后给所有重新订阅的人都能发送一个当前状态的数据,这就好比我们要实现一个计算属性,我们只关心该计算属性最终的状态,而不关心过程中变化的数,那么又该怎么处理呢?
我们知道普通的Subject只会在当前有新数据的时候发送当前的数据,而发送完毕之后就不会再发送已发送过的数据,那么这个时候我们就可以引入BehaviorSubject来进行终态维护了,因为订阅了该对象的观察者在订阅的同时能够收到该对象发送的最近一次的值,这样就能满足我们上述的需求了。
然后再结合代码来分析这种Subject应用的场景:
const subject = new Rx.Subject();
subject.subscribe((value) => console.log('A:' + value))
subject.next(1);
// A:1
subject.next(2);
// A:2
setTimeout(() => {
subject.subscribe((value) => console.log('B:' + value)); // 1s后订阅,无法收到值
}, 1000)
首先演示的是采用普通Subject来作为订阅的对象,然后观察者A在实例对象subject调用next发送新的值之前订阅的,然后观察者是延时一秒之后订阅的,所以A接受数据正常,那么这个时候由于B在数据发送的时候还没订阅,所以它并没有收到数据。
那么我们再来看看采用BehaviorSubject实现的效果:
const subject = new Rx.BehaviorSubject(0); // 需要传入初始值
subject.subscribe((value: number) => console.log('A:' + value))
// A:0
subject.next(1);
// A:1
subject.next(2);
// A:2
setTimeout(() => {
subject.subscribe((value: number) => console.log('B:' + value))
// B:2
}, 1000)
同样从打印的结果来看,与普通Subject的区别在于,在订阅的同时源对象就发送了最近一次改变的值(如果没改变则发送初始值),这个时候我们的B也如愿获取到了最新的状态。
这里在实例化
BehaviorSubject的时候需要传入一个初始值。
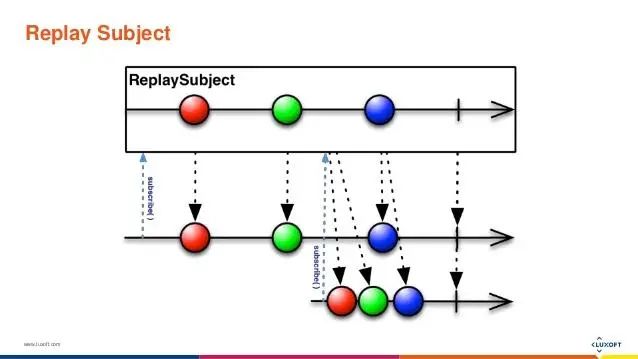
ReplaySubject
在理解了BehaviorSubject之后再来理解ReplaySubject就比较轻松了,ReplaySubject会保存所有值,然后回放给新的订阅者,同时它提供了入参用于控制重放值的数量(默认重放所有)。
 ]
]
什么?还不理解?看码:
const subject = new Rx.ReplaySubject(2);
subject.next(0);
subject.next(1);
subject.next(2);
subject.subscribe((value: number) => console.log('A:' + value))
// A:1
// A:2
subject.next(3);
// A:3
subject.next(4);
// A:4
setTimeout(() => {
subject.subscribe((value: number) => console.log('B:' + value))
// B:3
// B:4
}, 1000)
// 整体打印顺序:
// A:1
// A:2
// A:3
// A:4
// B:3
// B:4
我们先从构造函数传参来看,BehaviorSubject与ReplaySubject都需要传入一个参数,对BehaviorSubject来说是初始值,而对于ReplaySubject来说就是重放先前多少次的值,如果不传入重放次数,那么它将重放所有发射过的值。
从结果上看,如果你不传入确定的重放次数,那么实现的效果与之前介绍的单播效果几乎没有差别。
所以我们再分析代码可以知道在订阅的那一刻,观察者们就能收到源对象前多少次发送的值。
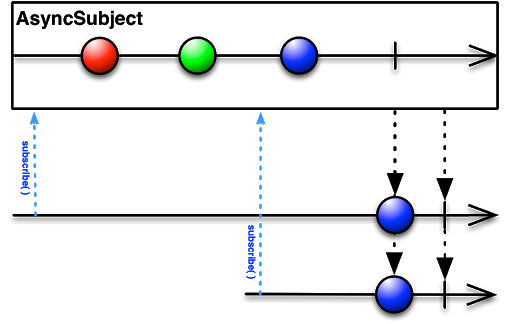
AsyncSubject
AsyncSubject 只有当 Observable 执行完成时(执行complete()),它才会将执行的最后一个值发送给观察者,如果因异常而终止,AsyncSubject将不会释放任何数据,但是会向Observer传递一个异常通知。
 ]
]
AsyncSubject一般用的比较少,更多的还是使用前面三种。
const subject = new Rx.AsyncSubject();
subject.next(1);
subject.subscribe(res => {
console.log('A:' + res);
});
subject.next(2);
subject.subscribe(res => {
console.log('B:' + res);
});
subject.next(3);
subject.subscribe(res => {
console.log('C:' + res);
});
subject.complete();
subject.next(4);
// 整体打印结果:
// A:3
// B:3
// C:3
从打印结果来看其实已经很好理解了,也就是说对于所有的观察者们来说,源对象只会在所有数据发送完毕也就是调用complete方法之后才会把最后一个数据返回给观察者们。
这就好比小说里经常有的,当你要放技能的时候,先要打一套起手式,打完之后才会放出你的大招。
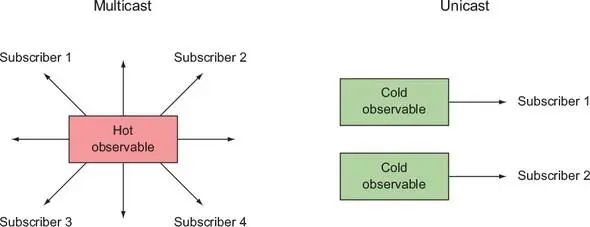
Cold-Observables与Hot-Observables
Cold Observables
Cold Observables 只有被 observers 订阅的时候,才会开始产生值。是单播的,有多少个订阅就会生成多少个订阅实例,每个订阅都是从第一个产生的值开始接收值,所以每个订阅接收到的值都是一样的。
如果大家想要参考
Cold Observables相关代码,直接看前面的单播示例就行了。
正如单播描述的能力,不管观察者们什么时候开始订阅,源对象都会从初始值开始把所有的数都发给该观察者。
Hot Observables
Hot Observables 不管有没有被订阅都会产生值。是多播的,多个订阅共享同一个实例,是从订阅开始接受到值,每个订阅接收到的值是不同的,取决于它们是从什么时候开始订阅。
这里有几种场景,我们可以逐一分析一下便于理解:
“加热”
首先可以忽略代码中出现的陌生的函数,后面会细说。
const source = Rx.Observable.of(1, 2).publish();
source.connect();
source.subscribe((value) => console.log('A:' + value));
setTimeout(() => {
source.subscribe((value) => console.log('B:' + value));
}, 1000);
这里首先用Rx的操作符of创建了一个Observable,并且后面跟上了一个publish函数,在创建完之后调用connect函数进行开始数据发送。
最终代码的执行结果就是没有任何数据打印出来,分析一下原因其实也比较好理解,由于开启数据发送的时候还没有订阅,并且这是一个Hot Observables,它是不会理会你是否有没有订阅它,开启之后就会直接发送数据,所以A和B都没有接收到数据。
当然你这里如果把
connect方法放到最后,那么最终的结果就是A接收到了,B还是接不到,因为A在开启发数据之前就订阅了,而B还要等一秒。
更直观的场景
正如上述多播所描述的,其实我们更多想看到的现象是能够A和B两个观察者能够都有接收到数据,然后观察数据的差别,这样会方便理解。
这里直接换一个发射源:
const source = Rx.Observable.interval(1000).take(3).publish();
source.subscribe((value: number) => console.log('A:' + value));
setTimeout(() => {
source.subscribe((value: number) => console.log('B:' + value));
}, 3000);
source.connect();
// A:0
// A:1
// A:2
// B:2
这里我们利用interval配合take操作符每秒发射一个递增的数,最多三个,然后这个时候的打印结果就更清晰了,A正常接收到了三个数,B三秒之后才订阅,所以只接收到了最后一个数2,这种方式就是上述多播所描述的并无一二。
两者对比
Cold Observables:举个栗子会比较好理解一点:比如我们上B站看番,更新了新番,我们不论什么时候去看,都能从头开始看到完整的剧集,与其他人看不看毫无关联,互不干扰。Hot Observables:这就好比我们上B站看直播,直播开始之后就直接开始播放了,不管是否有没有订阅者,也就是说如果你没有一开始就订阅它,那么你过一段时候后再去看,是不知道前面直播的内容的。
上述代码中出现的操作符解析
在创建Hot Observables时我们用到了publish与connect函数的结合,其实调用了publish操作符之后返回的结果是一个ConnectableObservable,然后该对象上提供了connect方法让我们控制发送数据的时间。
publish:这个操作符把正常的Observable(Cold Observables)转换成ConnectableObservable。ConnectableObservable:ConnectableObservable是多播的共享Observable,可以同时被多个observers共享订阅,它是Hot Observables。ConnectableObservable是订阅者和真正的源头Observables(上面例子中的interval,每隔一秒发送一个值,就是源头Observables)的中间人,ConnectableObservable从源头Observables接收到值然后再把值转发给订阅者。connect():ConnectableObservable并不会主动发送值,它有个connect方法,通过调用connect方法,可以启动共享ConnectableObservable发送值。当我们调用ConnectableObservable.prototype.connect方法,不管有没有被订阅,都会发送值。订阅者共享同一个实例,订阅者接收到的值取决于它们何时开始订阅。
其实这种手动控制的方式还挺麻烦的,有没有什么更加方便的操作方式呢,比如监听到有订阅者订阅了才开始发送数据,一旦所有订阅者都取消了,就停止发送数据?其实也是有的,让我们看看引用计数(refCount):
引用计数
这里主要用到了publish结合refCount实现一个“自动挡”的效果。
const source = Rx.Observable.interval(1000).take(3).publish().refCount();
setTimeout(() => {
source.subscribe(data => { console.log("A:" + data) });
setTimeout(() => {
source.subscribe(data => { console.log("B:" + data) });
}, 1000);
}, 2000);
// A:0
// A:1
// B:1
// A:2
// B:2
我们透过结果看本质,能够很轻松的发现,只有当A订阅的时候才开始发送数据(A拿到的数据是从0开始的),并且当B订阅时,也是只能获取到当前发送的数据,而不能获取到之前的数据。
不仅如此,这种“自动挡”当所有订阅者都取消订阅的时候它就会停止再发送数据了。
Schedulers(调度器)
用来控制并发并且是中央集权的调度员,允许我们在发生计算时进行协调,例如 setTimeout 或 requestAnimationFrame 或其他。
调度器是一种数据结构。它知道如何根据优先级或其他标准来存储任务和将任务进行排序。 调度器是执行上下文。它表示在何时何地执行任务(举例来说,立即的,或另一种回调函数机制(比如 setTimeout或process.nextTick),或动画帧)。调度器有一个(虚拟的)时钟。调度器功能通过它的 getter方法now()提供了“时间”的概念。在具体调度器上安排的任务将严格遵循该时钟所表示的时间。
学到这相信大家也已经或多或少对RxJS有一定了解了,不知道大家有没有发现一个疑问,前面所展示的代码示例中有同步也有异步,而笔者却没有显示的控制他们的执行,他们的这套执行机制到底是什么呢?
其实他们的内部的调度就是靠的Schedulers来控制数据发送的时机,许多操作符会预设不同的Scheduler,所以我们不需要进行特殊处理他们就能良好的进行同步或异步运行。
const source = Rx.Observable.create(function (observer: any) {
observer.next(1);
observer.next(2);
observer.next(3);
observer.complete();
});
console.log('订阅前');
source.observeOn(Rx.Scheduler.async) // 设为 async
.subscribe({
next: (value) => { console.log(value); },
error: (err) => { console.log('Error: ' + err); },
complete: () => { console.log('complete'); }
});
console.log('订阅后');
// 订阅前
// 订阅后
// 1
// 2
// 3
// complete
从打印结果上来看,数据的发送时机的确已经由同步变成了异步,如果不进行调度方式修改,那么“订阅后”的打印应该是在数据发送完毕之后才会执行的。
看完示例之后我们再来研究这个调度器能做哪几种调度:
queueasapasyncanimationFrame
queue
将每个下一个任务放在队列中,而不是立即执行
queue延迟使用调度程序时,其行为与async调度程序相同。
当没有延迟使用时,它将同步安排给定的任务-在安排好任务后立即执行。但是,当递归调用时(即在已调度的任务内部),将使用队列调度程序调度另一个任务,而不是立即执行,该任务将被放入队列并等待当前任务完成。
这意味着,当您使用 queue 调度程序执行任务时,您确定它会在该调度程序调度的其他任何任务开始之前结束。
这个同步与我们平常理解的同步可能不太一样,笔者当时也都困惑了一会。
还是用一个官方的例子来讲解这种调度方式是怎么理解吧:
import { queueScheduler } from 'rxjs';
queueScheduler.schedule(() => {
queueScheduler.schedule(() => console.log('second'));
console.log('first');
});
我们无需关注陌生的函数调用,我们这里着重于看这种调度方式与平常的同步调度的区别。
首先我们调用queueScheduler的schedule方法开始执行,然后函数内部又同样再以同样的方式调用(这里也可以改成递归,不过这里用这个示例去理解可能会好一点),并且传入一个函数,打印second。
然后继续看下面的语句,一个普通的console.log('first'),然后我们再来看看打印结果:
// first
// second
是不是有点神奇,如果没看明白为啥的,可以再回头看看前面queue对于递归执行的处理方式。也就是说如果递归调用,它内部会维护一个队列,然后等待先加入队列的任务先执行完成(也就是上面的console.log('first')执行完才会执行console.log('second'),因为console.log('second')这个任务是后加入该队列的)。
asap
内部基于Promise实现(Node端采用process.nextTick),他会使用可用的最快的异步传输机制,如果不支持Promise或process.nextTick或者Web Worker的 MessageChannel也可能会调用setTimeout方式进行调度。
async
与asap方式很像,只不过内部采用setInterval 进行调度,大多用于基于时间的操作符。
animationFrame
从名字看其实相信大家已经就能略知一二了,内部基于requestAnimationFrame来实现调度,所以执行的时机将与window.requestAnimationFrame保持一致,适用于需要频繁渲染或操作动画的场景。
Operators
Operator概念
采用函数式编程风格的纯函数 (pure function),使用像 map、filter、concat、flatMap 等这样的操作符来处理集合。也正因为他的纯函数定义,所以我们可以知道调用任意的操作符时都不会改变已存在的Observable实例,而是会在原有的基础上返回一个新的Observable。
尽管
RxJS的根基是Observable,但最有用的还是它的操作符。操作符是允许复杂的异步代码以声明式的方式进行轻松组合的基础代码单元。
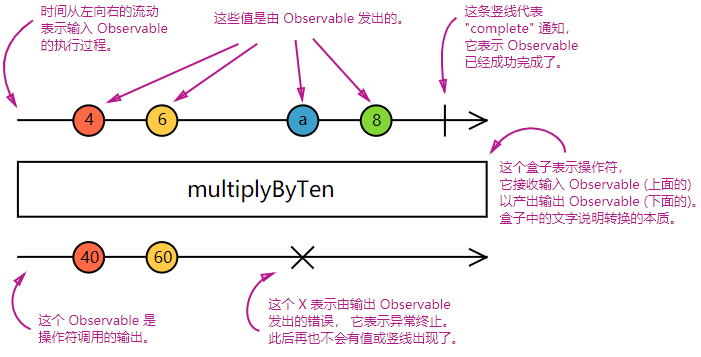
实现一个Operator
假设我们不使用RxJS提供的过滤操作符,那么让你自己实现又该怎么做呢?
function filter(source, callback) {
return Rx.Observable.create(((observer) => {
source.subscribe(
(v) => callback(v) && observer.next(v),
(err) => observer.error(err),
(complete) => observer.complete(complete)
);
}))
}
const source = Rx.Observable.interval(1000).take(3);
filter(source, (value) => value < 2).subscribe((value) => console.log(value));
// 0
// 1
这样就实现了一个简单的filter操作符,是不是很简洁,其实主要的做法还是像上面所说,基于传入的Observable,返回一个新的Observable。
代码中首先创建了一个Observable,接着用一个新的观察者订阅传入的源,并调用回调函数判断是否这个值需要继续下发,如果为false,则直接跳过,根据我们传入的源与过滤函数来看,源对象最终会发送三个数0、1、2,打印结果为0、1,2被过滤了。
当然我们也可以将其放置到Rx.Observable.prototype上以便以我们可以采用this的方式获取源:
Rx.Observable.prototype.filter = function (callback) {
return Rx.Observable.create(((observer) => {
this.subscribe(
(v) => callback(v) && observer.next(v),
(err) => observer.error(err),
(complete) => observer.complete(complete)
);
}))
}
Rx.Observable.interval(1000).take(3).filter((value) => value < 2).subscribe((value) => console.log(value));
// 0
// 1
这样是不会就更加简洁了,就像我们使用原生数组的filter方法一样。
要说这两种方式的区别,其实也比较好理解,一个是放在prototype中,能够被实例化的对象直接调用,另一个是定义了一个新的函数,可以用来导出给调用者使用(其实也可以直接挂载到Observable的静态属性上)。
看到这里估计会有读者已经猜到笔者接下来说讲解什么了。
实例操作符-静态操作符
实例操作符:通常是能被实例化的对象直接调用的操作符。我们一般更多会使用实例操作符多一点,比如 filter、map、concat等等。使用实例操作符可以更快乐的使用this,而省去一个参数,还能维持链式调用。静态操作符: Observable是一个class类,我们可以直接把操作符挂载到他的静态属性上,好处在于无需实例化即可调用,缺点在于就无法再使用this的方式进行目标对象调用了,而是需要把目标对象传入。
如果添加一个实例化属性上面已经有示例了,这里就不做过多赘述了。
将上述的filter例子改造一下,将其挂载到静态属性上:
Rx.Observable.filter = (source, callback) => {
return Rx.Observable.create(((observer) => {
source.subscribe(
(v) => callback(v) && observer.next(v),
(err) => observer.error(err),
(complete) => observer.complete(complete)
);
}))
}
创建型Operators
对于任何数据的处理或使用来说,我们首先会去关注的莫过于,它从哪里来,如何产生的,以及我们该怎么获取。
create
定义:
public static create(onSubscription: function(observer: Observer): TeardownLogic): Observable
经过前面代码的洗礼,相信大家对该操作符已经不陌生了。

create将onSubscription函数转化为一个实际的Observable。每当有人订阅该Observable的时候,onSubscription函数会接收Observer实例作为唯一参数执行。onSubscription应该 调用观察者对象的next,error和complete方法。
官方文档的描述其实已经很清晰了,相当于只要有人订阅该操作符创建出来的Observable,它则会通过调用订阅者本身的方法传递一系列值。
上图与演示代码并无直接关联。
const source = Rx.Observable.create(((observer: any) => {
observer.next(1);
observer.next(2);
setTimeout(() => {
observer.next(3);
}, 1000)
}))
// 方式一
source.subscribe(
{
next(val) {
console.log('A:' + val);
}
}
);
// 方式二
source.subscribe((val) => console.log('B:' + val));
// A:1
// A:2
// B:1
// B:2
//- 1s后:
// A:3
// B:3
打印结果自然是不用多提了,首先A和B都会分别打印,1、2,并在1s后打印出3。
这里我们可以注意一下,我们的在调用subscribe的时候可以使用这两种方式,以一个对象形式,该对象具备next、error、complete三个方法(都是可选的),或者直接传入函数的方式,参数前后分别为next、error、complete。
empty
定义:
public static empty(scheduler: Scheduler): Observable
顾名思义,该操作符创建一个什么数据都不发出,直接发出完成通知的操作符。
这里可能会有读者问了,那这玩意有啥用。
其实不然,在与某些操作符进行配合时,它的作用还真不可小觑,比如mergeMap,后面会进行配合讲解,等不及的小伙伴可以直接跳到mergeMap。
from
定义:
public static from(ish: ObservableInput, scheduler: Scheduler): Observable
从一个数组、类数组对象、Promise、迭代器对象或者类 Observable 对象创建一个 Observable.
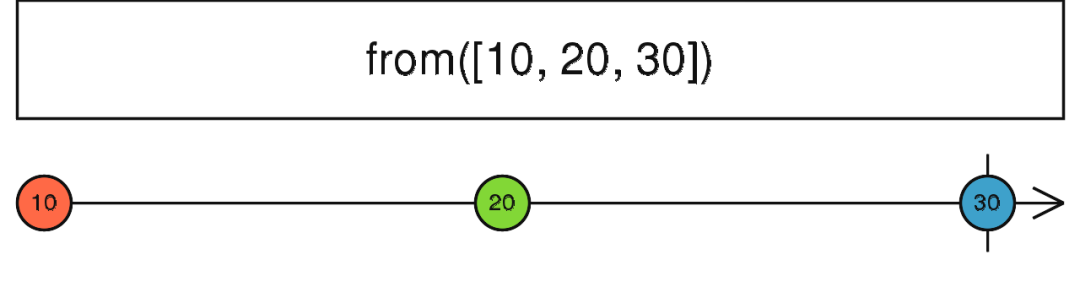
该方法就有点像js中的Array.from方法(可以从一个类数组或者可迭代对象创建一个新的数组),只不过在RxJS中是转成一个Observable给使用者使用。
const source = Rx.Observable.from([10, 20, 30]);
source.subscribe(v => console.log(v));
// 10
// 20
// 30
从示例代码来看,其实这个还是比较简单的用法,如果说你想对现有项目的一些数据(比如数组或类数组)采用RxJS来管理,那么from操作将是一个不错的选择。
fromEvent
定义:
public static fromEvent(target: EventTargetLike, eventName: string, options: EventListenerOptions, selector: SelectorMethodSignature): Observable
创建一个 Observable,该 Observable 发出来自给定事件对象的指定类型事件。可用于浏览器环境中的Dom事件或Node环境中的EventEmitter事件等。
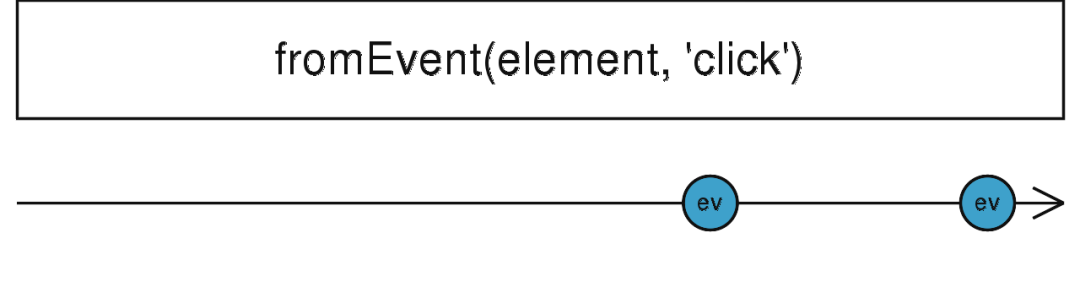
假设我们有一个这样的需求,监听按钮点击事件,并打印出来:
const click = Rx.Observable.fromEvent(document.getElementById('btn'), 'click');
click.subscribe(x => console.log(x));
对比我们使用addEventListener方式来监听是不是这种写法更为流畅。
fromPromise
定义:
public static fromPromise(promise: PromiseLike, scheduler: Scheduler): Observable
从命名上看其实已经很明显了,就是将Promise转换成Observable,这样我们在编写代码时就可以不用写.then、.catch之类的链式调用了。
如果 Promise resolves 一个值, 输出 Observable 发出这个值然后完成。如果 Promise 被 rejected, 输出 Observable 会发出相应的 错误。
const source = Rx.Observable.fromPromise(fetch('http://localhost:3000'));
source.subscribe(x => console.log(x), e => console.error(e));
这里为了演示效果,本地起了一个服务用于测试,自测的时候可以用别的。
这样我们就能轻松拿到该请求的返回值了。
interval
定义:
public static interval(period: number, scheduler: Scheduler): Observable
使用该操作符创建的Observable可以在指定时间内发出连续的数字,其实就跟我们使用setInterval这种模式差不多。在我们需要获取一段连续的数字时,或者需要定时做一些操作时都可以使用该操作符实现我们的需求。
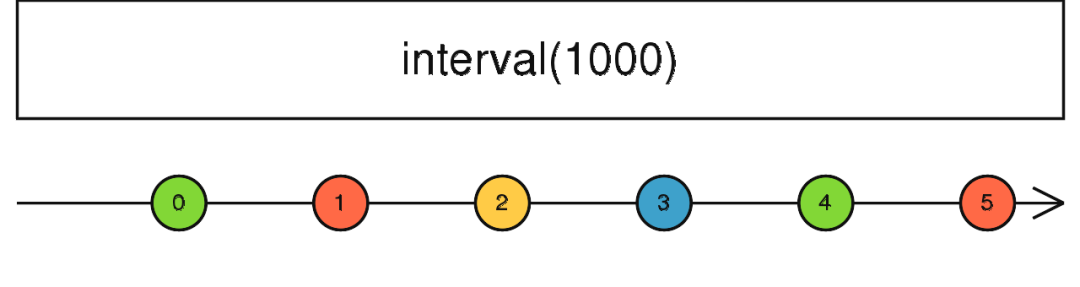
const source = Rx.Observable.interval(1000);
source.subscribe(v => console.log(v));
默认从0开始,这里设定的时间为1s一次,它会持续不断的按照指定间隔发出数据,一般我们可以结合take操作符进行限制发出的数据量。
of
定义:
public static of(values: ...T, scheduler: Scheduler): Observable
与from的能力差不太多,只不过在使用的时候是传入一个一个参数来调用的,有点类似于js中的concat方法。同样也会返回一个Observable,它会依次将你传入的参数合并并将数据以同步的方式发出。
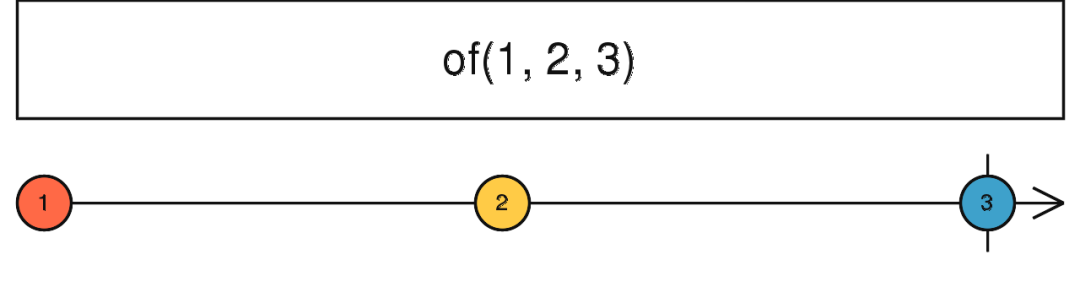
const source = Rx.Observable.of(1, 2, 3);
source.subscribe(v => console.log(v));
// 1
// 2
// 3
依次打印1、2、3.
repeat
定义:
public repeat(count: number): Observable
将数据源重复n次,n为你传入的数字类型参数。
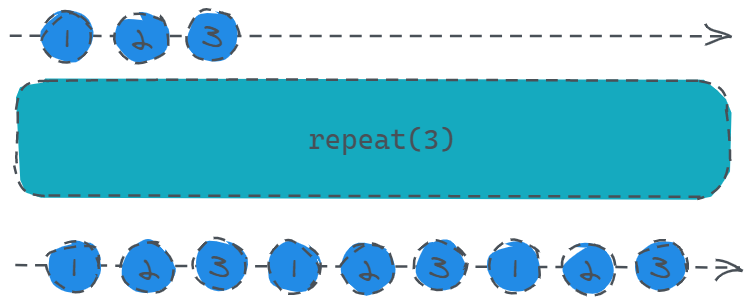
const source = Rx.Observable.of(1, 2, 3).repeat(3);
source.subscribe(v => console.log(v));
这里配合of操作符,打印结果为一次打印1、2、3、1、2、3、1、2、3,将原本只会打印一次的1、2、3转化成三次。
range
定义:
public static range(start: number, count: number, scheduler: Scheduler): Observable
创建一个 Observable ,它发出指定范围内的数字序列。
学过
Python的小伙伴有木有一点似曾相识的感觉。
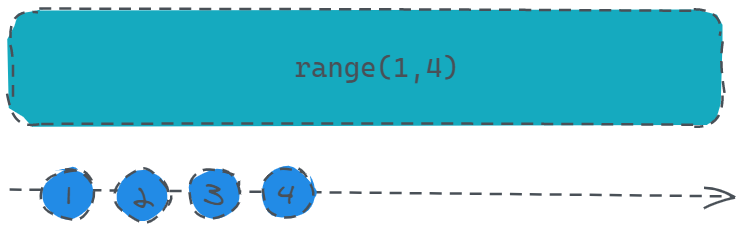
const source = Rx.Observable.range(1, 4);
source.subscribe(v => console.log(v));
打印结果:1、2、3、4。
是不是倍感简单呢。
转换操作符
那么什么是转换操作符呢,众所周知,我们在日常业务中,总是需要与各种各样的数据打交道,很多时候我们都不是直接就会对传输过来的数据进行使用,而是会对其做一定的转换,让他成为更加契合我们需求的形状,这就是转换操作符的作用所在了。
buffer
定义:
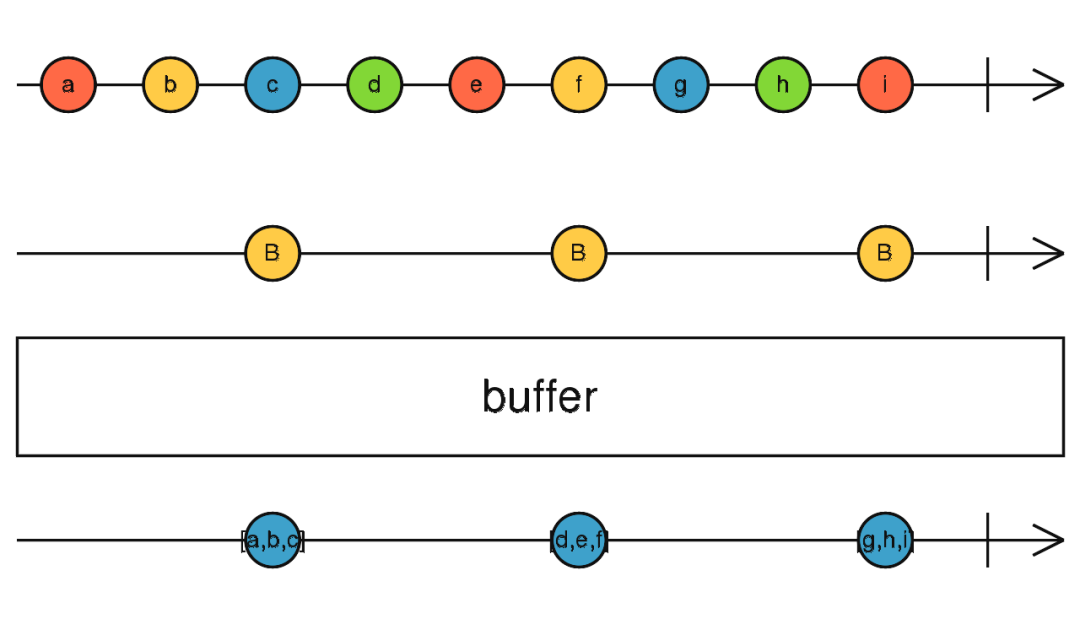
public buffer(closingNotifier: Observable): Observable
将过往的值收集到一个数组中,并且仅当另一个 Observable 发出通知时才发出此数组。这相当于有一个缓冲区,将数据收集起来,等到一个信号来临,再释放出去。
 ;
;
改操作符就有点像一个大水坝,一些时候我们会选择蓄水,等到特定时候,再由领导下命令打开水坝,让水流出去。
举个栗子:
假设我们有这样一个需求,我们有一个接口是专门用于获取特定数据的,但是呢该接口一次性只返回一个数据,这让我们很苦恼,因为产品想让数据量达到特定值再控制进行操作,也就是他点击一下某个按钮,再去将这些数据渲染出来,那该怎么办呢?
这个时候就需要我们的buffer操作符大展身手了:
const btn = document.createElement('button');
btn.innerText = '你点我啊!'
document.body.appendChild(btn);
const click = Rx.Observable.fromEvent(btn, 'click');
const interval = Rx.Observable.interval(1000);
const source = interval.buffer(click);
source.subscribe(x => console.log(x));
这里我们直接用
interval来演示接口获取数据,然后再配合buffer进行功能实现。
这里我们等四秒之后再点击一下按钮,打印出来的值为:[0, 1, 2, 3],然后再等8秒,点击按钮:[4, 5, 6, 7, 8, 9, 10, 11]。
从现象看,我们不难看出,我们已经实现了通过按钮来控制数据的发送。同时我们可以发现另一个现象,发送出去的数据就直接会在缓冲区中被清空,然后重新收集新的数据。
这其实也不难理解,我们还是用水坝来举例,我们打开水坝放水一段时间之后,然后关闭它继续蓄水,那么我第二次打开水坝放出去的水自然是我新蓄的水。
concatMap
定义:
public concatMap(project: function(value: T, ?index: number): ObservableInput, resultSelector: function(outerValue: T, innerValue: I, outerIndex: number, innerIndex: number): any): Observable
这个操作符还是有点意思的,我们先看看官网的描述:
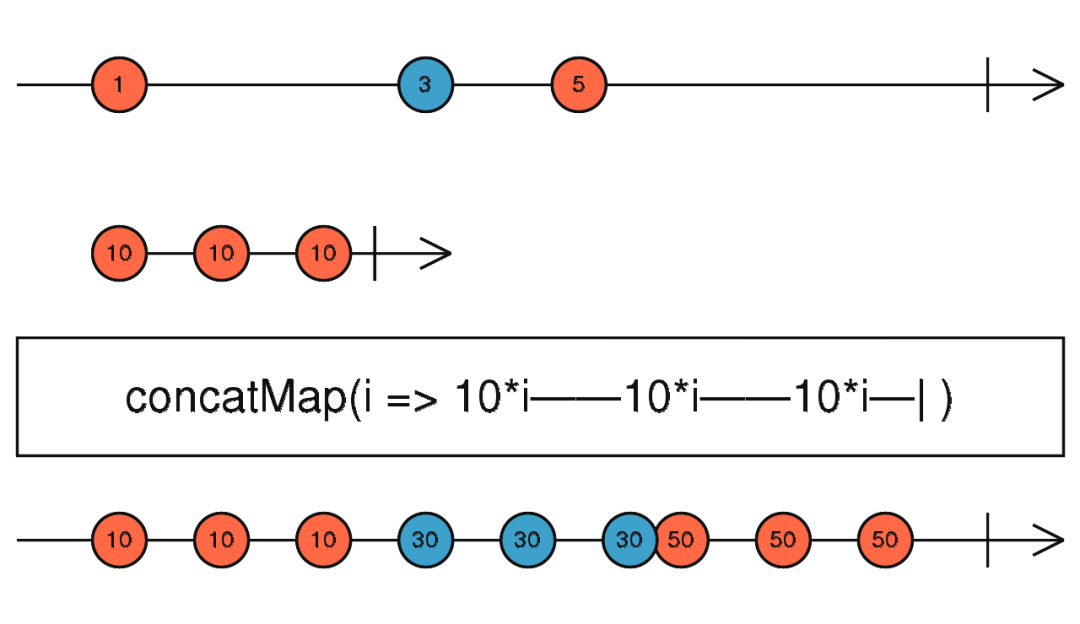
将源值投射为一个合并到输出
Observable的Observable,以串行的方式等待前一个完成再合并下一个Observable。
不知道各位读者是否感受到了“一丝丝”的不好理解呢,不过等笔者举个小例子就能轻松的搞懂了:
假设你遇到了这样一个场景,你和女朋友一起在小吃街逛街,但是呢女朋友有个不好的毛病,她总喜欢这家买完吃一口然后剩下让你吃,然后另一家买一点吃一口然后剩下还是让你吃,而你呢每次吃东西也是要时间的,一般会心疼男朋友的女朋友就会等你吃完再去买下一家的,这种情况下,你还是能吃完再休息会;另一种情况呢,女朋友不管你吃完没,她继续买买买,然后你手里的吃的越来越多,你吃的速度完全赶不上女朋友买的速度,那这个时候呢就会导致你负重越来越大,最后顶不住心态爆炸了。
以上情景包含了concatMap的几个核心点以及需要注意的地方:
源值发送一个数据,然后你传入的内部 Observable就会开始工作或者是发送数据,订阅者就能收到数据了,也就是内部的Observable相当于总是要等源对象发送一个数据才会进行新一轮工作,并且要等本轮工作完成了才能继续下一轮。如果本轮工作还未完成又接受到了源对象发送的数据,那么将会用一个队列保存,然后等本轮完成立即检查该队列里是否还有,如果有则立马开启下一轮。 如果内部 Observable的工作时间大于源对象发送的数据的间隔时间,那么就会导致缓存队列越来越大,最后造成性能问题
其实通俗点理解就是,一个工厂流水线,一个负责发材料的,另一个负责制作产品的,发材料的就是源对象,制作产品的就是这个内部Observable,这个工厂里产出的只会是成品也就是制作完成的,所以订阅者要等这个制作产品的人做完一个才能拿到一个。
如果发材料的速度比制作的人制作一个产品要快就会产生材料堆积,那么随着时间推移就会越堆越多,导致工厂装不下。
借助代码理解:
const source = Rx.Observable.interval(3000);
const result = source.concatMap(val => Rx.Observable.interval(1000).take(2));
result.subscribe(x => console.log(x));
首先分析一下代码结构,我们先创建了一个每隔三秒发送一个数据的源对象,接着调用实例方法concatMap,并给该方法传入一个返回Observable对象的函数,最终获得经过concatMap转化后的Observable对象,并对其进行订阅。
运行结果为:首先程序运行的第三秒source会发送第一个数据,然后这时我们传入的内部Observable,开始工作,经过两秒发送两个递增的数,接着订阅函数逐步打印出这两个数,等待一秒后也就是程序运行的第6秒,source发送第二个数,这个时候重复上述流程。
map
定义:
public map(project: function(value: T, index: number): R, thisArg: any): Observable
如果说你使用js中数组的map方法较多的话,可能这里基本就不用看了,用法完全一致。
你只需要传入一个函数,那么函数的第一个参数就是数据源的每个数据,第二个参数就是该数据的索引值,你只需要返回一个计算或者其他操作之后的返回值即可作为订阅者实际获取到的值。
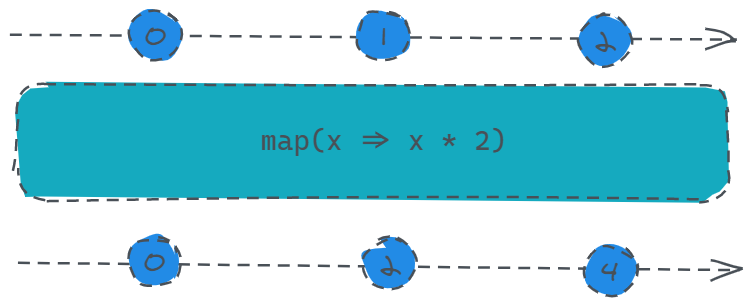
const source = Rx.Observable.interval(1000).take(3);
const result = source.map(x => x * 2);
result.subscribe(x => console.log(x));
take操作符其实也就是限定拿多少个数就不在发送数据了。
这里用于演示将每个数据源的值都乘以2然后发送给订阅者,所以打印的值分别为:0、2、4。
mapTo
定义:
public mapTo(value: any): Observable
忽略数据源发送的数据,只发送指定的值(传参)。
就像是一个你讨厌的人让你帮忙传话,他说了一大堆表白的话,然后让你传给某个妹子,你因为讨厌他所以不想帮他,于是跟那个妹子说我喜欢你,最后你们幸福的生活在一起了。
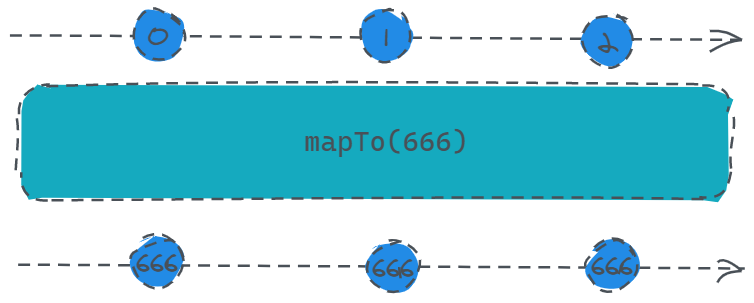
const source = Rx.Observable.interval(1000).take(3);
const result = source.mapTo(666);
result.subscribe(x => console.log(x));
就像这段代码,数据源发送的是0、1、2,而订阅者实际收到的是三个666。
mergeMap
定义:
public mergeMap(project: function(value: T, ?index: number): ObservableInput, resultSelector: function(outerValue: T, innerValue: I, outerIndex: number, innerIndex: number): any, concurrent: number): Observable
这个定义看上有点吓人,不过我们不要慌,我们只需要了解他得大多数情况的用法即可。
这里你是否还记得前面在
empty操作符介绍的部分提到的,笔者留了个坑没补,就是演示mergeMap与empty是如何进行配合的?这里就把这个坑填上。
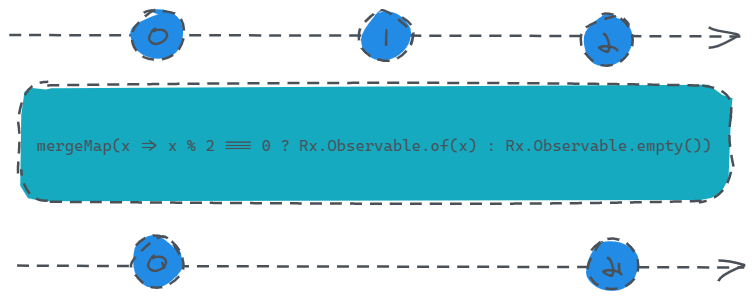
const source = Rx.Observable.interval(1000).take(3);
const result = source.mergeMap(x => x % 2 === 0 ? Rx.Observable.of(x) : Rx.Observable.empty());
result.subscribe(x => console.log(x));
输入源是一个会发送0、1、2三个数的数据源,我们调用mergeMap操作符,并传入一个函数,该函数的功能就是,如果输入源发送的当前值是偶数则发送给订阅者,否则就不发送。
这里面mergeMap主要做了一个整合的能力,我们可以将它与map进行对比,我们可以发现map的返回值必须是一个数值,而mergeMap返回值是要求是一个Observable,也就是说,我们可以返回任意转换或具备其他能力的Observable。
pluck
定义:
public pluck(properties: ...string): Observable
用于选择出每个数据对象上的指定属性值。
就比如某个数据源发送的数据是一个对象,对象上面有一个name属性,并且订阅者指向知道这个name属性,那么就可以使用该操作符来提取该属性值给用户。
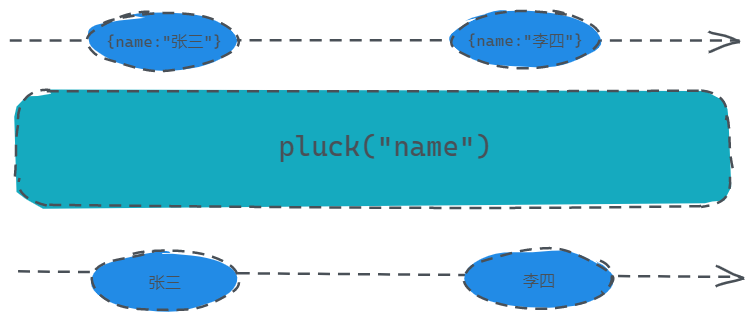
const source = Rx.Observable.of({name: '张三'}, {name: '李四'});
const result = source.pluck('name');
result.subscribe(x => console.log(x));
// 张三
// 李四
毫无疑问,这个操作符就是为了提取属性来的,相当于我们使用map操作符来处理一下提取出name再返回给订阅者。
scan
定义:
public scan(accumulator: function(acc: R, value: T, index: number): R, seed: T | R): Observable
累加器操作符,可以用来做状态管理,用处挺多。
就用法来看,我们可以参考一下
js中数组的reduce函数。
假设我们现在有一个需求,我们想要将数据源发送过来的数据累加之后再返回给订阅者,这又该怎么做呢?
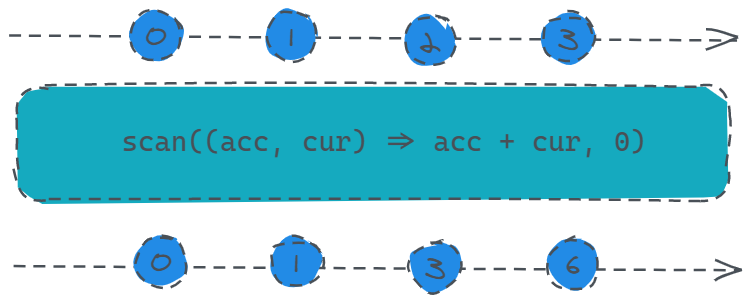
const source = Rx.Observable.interval(1000).take(4);
const result = source.scan((acc, cur) => acc + cur, 0);
result.subscribe(x => console.log(x));
从代码上看,数据源发送了四个值:0、1、2、3,而订阅者每次收到的值将分别是前面已接收到的数与当前数的和也就是:0、1、3、6。
然后再看用法,我们给scan操作符第一个参数传入了一个函数,接收两个值:acc(前一次累加的结果或初始值)、cur(当前值),第二个参数则是计算的初始值。
switchMap
定义:
public switchMap(project: function(value: T, ?index: number): ObservableInput, resultSelector: function(outerValue: T, innerValue: I, outerIndex: number, innerIndex: number): any): Observable
其实也就是
switch操作符与map操作符的结合,switch操作符会在组合操作符中讲到。
主要作用首先会对多个Observable进行合并,并且具备打断能力,也就是说合并的这个几个Observable,某个Observable最先开始发送数据,这个时候订阅者能正常的接收到它的数据,但是这个时候另一个Observable也开始发送数据了,那么第一个Observable发送数据就被打断了,只会发送后来者发送的数据。
用通俗的话来说就是,有人在说话,突然你大声开始说话,人家就被你打断了,这个时候大家就只能听到你说话了。
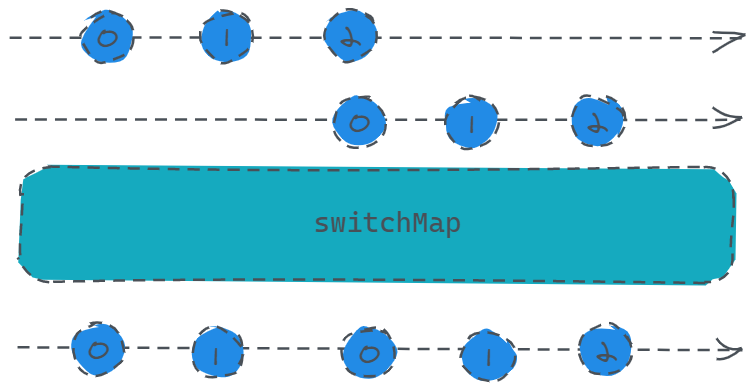
const btn = document.createElement('button');
btn.innerText = '我要发言!'
document.body.appendChild(btn);
const source = Rx.Observable.fromEvent(btn, 'click');
const result = source.switchMap(x => Rx.Observable.interval(1000).take(3));
result.subscribe(x => console.log(x));
代码实现的功能就是,当某位同学点击按钮,则开始从0开始发送数字,这个时候如果同学一还没发送完数据,同学二再点一下,则同学一的数据就不会再发了,开始发同学二的。
假设同学一点完之后,第二秒同学二点击了一下按钮,则打印结果:0、1、0、1、2,这里从第二个0开始就是同学二发送的数据了。
其他转换操作符
官网传送门:转换操作符 https://cn.rx.js.org/manual/overview.html#h311
bufferCountbufferTimebufferTogglebufferWhenconcatMapToexhaustMapexpandgroupBymergeMapTomergeScanpairwisepartitionswitchMapTowindowwindowCountwindowTimewindowTogglewindowWhen
过滤操作符
debounceTime
定义:
public debounceTime(dueTime: number, scheduler: Scheduler): Observable
可能对于有过一定js开发经验的小伙伴应该会知道debounce防抖函数,那么这个时候会有小伙伴问了,它不会就和debounce差不多吧?没错,他的功能与debounce防抖函数差不多,不过还是有一点差别的。
只有在特定的一段时间经过后并且没有发出另一个源值,才从源 Observable 中发出一个值。
也就是说,假设一个数据源每隔一秒发送一个数,而我们使用了debounceTime操作符,并设置了延时时间,那么在数据源发送一个新数据之后,如果在延时时间内数据源又发送了一个新数据,这个新的数据就会被先缓存住不会发送,等待发送完数据之后并等待延时时间结束才会发送给订阅者,不仅如此,在延时时间未到的时候并且已有一个值在缓冲区,这个时候又收到一个新值,那么缓冲区就会把老的数据抛弃,放入新的,然后重新等待延时时间到达然后将其发送。
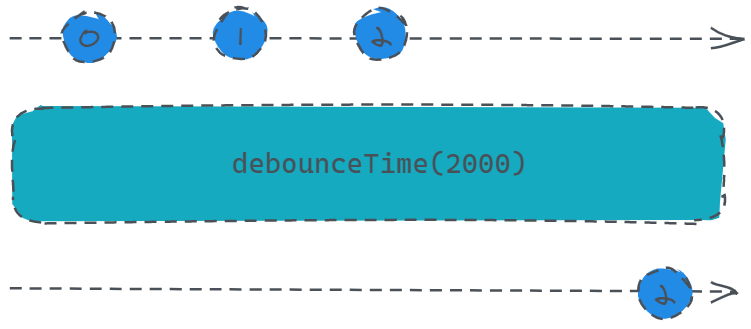
const source = Rx.Observable.interval(1000).take(3);
const result = source.debounceTime(2000);
result.subscribe(x => console.log(x));
从代码来看,我们不妨猜测一下,最后打印的结果是什么?
首先我们创建了一个每秒发送一个数字并且只会发三次的数据源,然后用debounceTime处理了一下,并设置延时时间为2秒,这个时候我们观察打印的数据会发现,程序启动之后的前三秒没有数据打印,等到五秒到了之后,打印出一个2,接着就没有再打印了,这是为什么?
答案是数据源会每秒依次发送三个数0、1、2,由于我们设定了延时时间为2秒,那么也就是说,我们在数据发送完成之前都是不可能看到数据的,因为发送源的发送频率为1秒,延时时间却有两秒,也就是除非发送完,否则不可能满足发送源等待两秒再发送新数据,每次发完新数据之后要等两秒之后才会有打印,所以不论我们该数据源发送多少个数,最终订阅者收到的只有最后一个数。
throttleTime
定义:
public throttleTime(duration: number, scheduler: Scheduler): Observable
介绍了防抖怎么能忘了它的老伙伴节流呢?
该操作符主要能力跟我们认知的节流函数也是一致的,就是它会控制一定时间内只会发送一个数据,多余的会直接抛弃掉。唯一和防抖操作符不一致的地方就在于它对于第一个值是不会阻塞的。
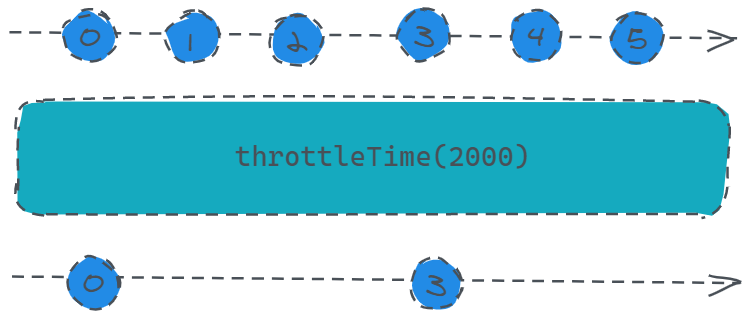
const source = Rx.Observable.interval(1000).take(6);
const result = source.throttleTime(2000);
result.subscribe(x => console.log(x));
// 0
// 3
打印结果如上所示,其实效果也很容易解释,代码中创建了一个数据源每秒发送一个从0开始递增的数,总共发送6个也就是0-5,并使用throttleTime设置两秒,订阅者接收第一个值时不会被阻塞,而是接收完一个之后的两秒里都拿不到值,也就是在第四秒的时候才能拿到3。
distinct
定义:
public distinct(keySelector: function, flushes: Observable): Observable
这个操作符也十分好理解,一句话可以概括,使用了该操作符,那么订阅者收到的数据就不会有重复的了,也就是它是用来过滤重复数据的。
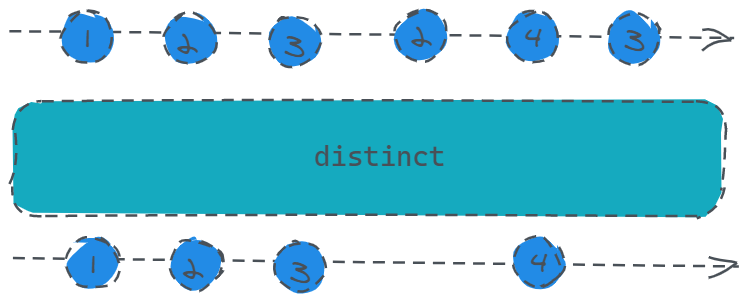
const source = Rx.Observable.from([1, 2, 3, 2, 4, 3]);
const result = source.distinct();
result.subscribe(x => console.log(x));
最终程序运行结果为:1、2、3、4,重复的数直接被过滤了。
filter
定义:
public filter(predicate: function(value: T, index: number): boolean, thisArg: any): Observable
这种基本应该没啥好介绍的了,与我们理解的数组filter方法并无差别,只是用的地方不一致。
const source = Rx.Observable.from([1, 2, 3, 2, 4, 3]);
const result = source.filter(x => x !== 3);
result.subscribe(x => console.log(x));
程序运行结果就是除了3以外的其他值都被打印出来。
first
定义:
public first(predicate: function(value: T, index: number, source: Observable): boolean, resultSelector: function(value: T, index: number): R, defaultValue: R): Observable
只发出由源 Observable 所发出的值中第一个(或第一个满足条件的值)。
这个也和上面差不多,基本看介绍就能懂,这里就不再多赘述了。
take
定义:
public take(count: number): Observable
只发出源 Observable 最初发出的的N个值 (N = count)。
这个操作符可谓是在前面出现了很多次了,还挺常见的,用于控制只获取特定数目的值,跟interval这种会持续发送数据的配合起来就能自主控制要多少个值了。
skip
定义:
public skip(count: Number): Observable
返回一个 Observable, 该 Observable 跳过源 Observable 发出的前N个值(N = count)。
举个栗子来说就是,假设这个数据源发送6个值,你可以使用skip操作符来跳过前多少个。
const source = Rx.Observable.from([1, 2, 3, 2, 4, 3]);
const result = source.skip(2);
result.subscribe(x => console.log(x));
打印结果为:3、2、4、3,跳过了前面两个数。
其他过滤操作符
官方提供的操作符还是挺多的,这里就不一一介绍了,感兴趣可以去官网查看:过滤操作符 https://cn.rx.js.org/manual/overview.html#h310
debouncedistinctKeydistinctUntilChangeddistinctUntilKeyChangedelementAtignoreElementsauditauditTimelastsamplesampleTimesingleskipLastskipUntilskipWhiletakeLasttakeUntiltakeWhilethrottle
组合操作符
concatAll
定义:
public concatAll(): Observable
顾名思义,该操作符有点像我们js中数组方法concat,用于将多个Observable合成一个,不过它有个注意点在于它是串行的,也就是合并了两个Observable,那订阅者在获取值的时候会先获取完第一个Observable,之后才开始接收到后一个Observable的值。
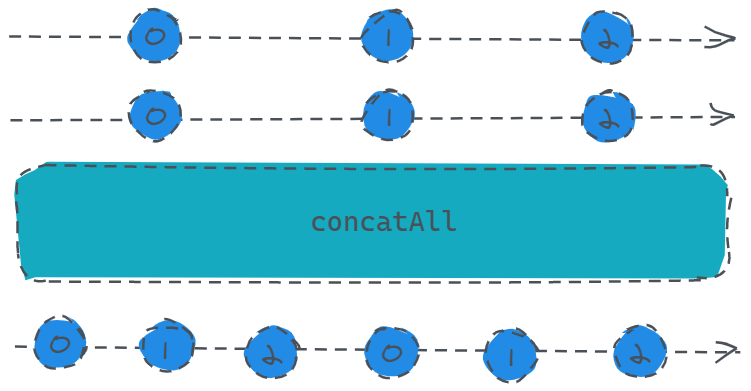
const source1 = Rx.Observable.of(1, 2);
const source2 = source1.map(x => Rx.Observable.interval(1000).take(3));
const result = source2.concatAll();
result.subscribe(x => console.log(x));
根据上面的文字介绍,相信大家对于这段代码应该也能多少看得懂一些,没错,这段代码的含义就是我们的数据源发送了两个数,并且采用map操作符处理完返回了一个新的Observable,这个时候为了订阅者能够正常的接收多个Observable,则采用concatAll合并一下,并且最终订阅者收到的结果依次为:0、1、2、0、1、2。
mergeAll
定义:
public mergeAll(concurrent: number): Observable
与concatAll几乎没太大差别,唯一不同的就是它是并行的,也就是合并的多个Observable发送数据时是不分先后的。
combineLatest
定义:
public combineLatest(other: ObservableInput, project: function): Observable
组合多个 Observables 来创建一个 Observable ,该 Observable 的值根据每个输入 Observable 的最新值计算得出的。
这个操作符光从简介来看不太好理解,我们来结合实例进行讲解吧。
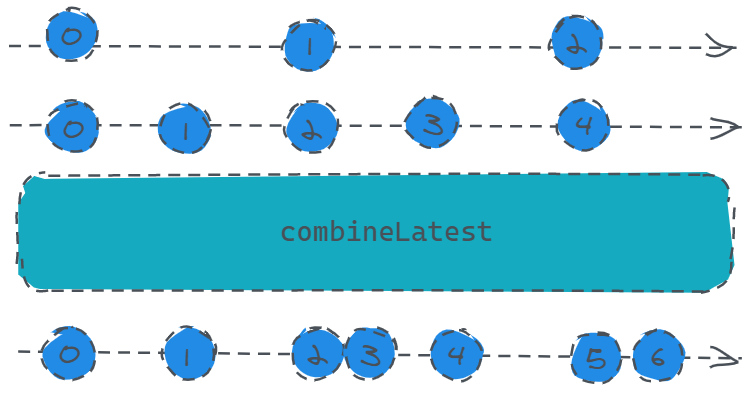
const s1 = Rx.Observable.interval(2000).take(3);
const s2 = Rx.Observable.interval(1000).take(5);
const result = s1.combineLatest(s2, (a, b) => a + b);
result.subscribe(x => console.log(x));
打印结果依次是:0、1、2、3、4、5、6。
首先我们看这个combineLatest的使用方式,它是一个实例操作符,这里演示的是将s1与s2结合到一起,并且第二个参数需要传入回调,对结合的值进行处理,由于我们这里只结合了两个,故只接收a、b两个参数,该回调函数的返回值即为订阅者获取到的值。
从结果看其实也看不出来啥,主要是这个过程如下:
s2发送一个0,而此时s1未发送值,则我们传入的回调不会执行,订阅者也不会接收到值。s1发送一个0,而s2最后一次发送的值为0,故调用回调函数,并把这两个参数传入,最终订阅者收到s2发送一个1,而s1最后一次发送的为0,故结果为1。s1发送一个1,而s2最后一次发送的值为1,故结果为2。s2发送一个值为2,而s1最后一次发送的值为1,故结果为3。s2发送一个值为3,而s1最后一次发送的值为1,故结果为4。...重复上述步骤。
这里有个注意点,我们会发现
s1、s2在某些时候会同时发送数据,但是这个也会有先后顺序的,所以这个时候就看他们谁先定义那么谁就会先发送,从上面步骤中你们应该也能发现这个现象。
其实也就是结合的多个源之间存在一种依赖关系,也就是两个源都至少发送了一个值,订阅者才会收到消息,等到两个源都发送完毕,最后才会发出结束信号。
zip
定义:
public static zip(observables: *): Observable
将多个 Observable 组合以创建一个 Observable,该 Observable 的值是由所有输入 Observables 的值按顺序计算而来的。如果最后一个参数是函数, 这个函数被用来计算最终发出的值.否则, 返回一个顺序包含所有输入值的数组.
通俗点说就是多个源之间会进行顺位对齐计算,跟前面的combineLatest有点差别。
话不多说,上码:
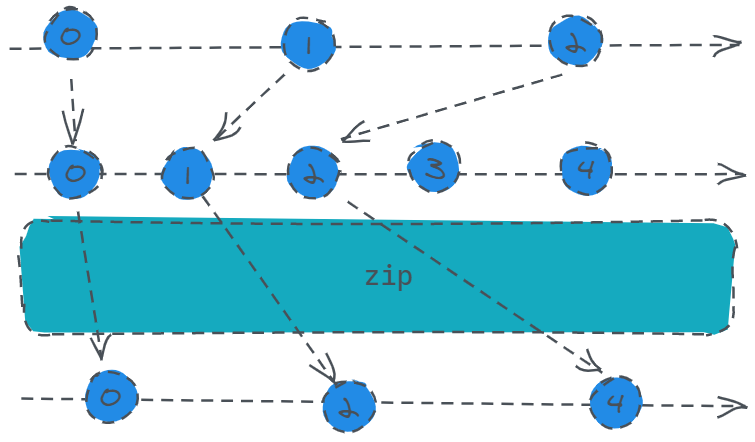
const s1 = Rx.Observable.interval(1000).take(3);
const s2 = Rx.Observable.interval(2000).take(5);
const result = s1.zip(s2, (a, b) => a + b);
result.subscribe(x => console.log(x));
打印结果依次是:0、2、4。
怎么理解呢,首先我们记住一句话,多个源之间用来计算的数是顺位对齐的,也就是说s1的第一个数对齐s2的第一个数,这种一一对应的计算,最终订阅者收到的就是将多个对齐的数传入我们在调用zip的最后一个回调函数,也就是用来计算完值最终返回给用户的结果,这是可选的。
等到两个源中的任意一个源结束了之后,整体就会发出结束信号,因为后续不存在可以对齐的数了。
startWidth
定义:
public startWith(values: ...T, scheduler: Scheduler): Observable
返回的 Observable 会先发出作为参数指定的项,然后再发出由源 Observable 所发出的项。
怎么理解呢,其实很好举例,比如有一串糖葫芦,整体都是一个颜色,你觉得不好看,于是你在这串糖葫芦的前面插了几个颜色不一样的糖葫芦,这个时候用户吃的时候就会先吃到你插在最前面的糖葫芦。
const source = Rx.Observable.interval(1000).take(3);
const result = source.startWith(666)
result.subscribe(x => console.log(x));
打印结果为:666、0、1、2。
是不是很好理解呢。
switch
定义:
public switch(): Observable
通过只订阅最新发出的内部 Observable ,将高阶 Observable 转换成一阶 Observable 。
对于该操作符的用法其实前面我们在介绍switchMap这个转换操作符时就已经说到了,相当于map+switch=switchMap。
举个栗子:
const btn = document.createElement('button');
btn.innerText = '我要发言!'
document.body.appendChild(btn);
const source = Rx.Observable.fromEvent(btn, 'click');
const source2 = source.map(x => Rx.Observable.interval(1000).take(3));
const result = source2.switch();
result.subscribe(x => console.log(x));
上述代码实现的效果与switchMap一致,当用户点击按钮时会开始发送数据,当这次数据发送未完成时,再次点击按钮,则会开始一个新的发射数据流程,将原先的发射数据流程直接抛弃。
其他组合操作符
官网传送门:组合操作符 https://cn.rx.js.org/manual/overview.html#h312
combineAllconcatexhaustforkJoinmergeracewithLatestFromzipAll
多播操作符
官网传送门:多播操作符 https://cn.rx.js.org/manual/overview.html#h313
cachemulticastpublishpublishBehaviorpublishLastpublishReplayshare
待完善...
错误处理操作符
官网传送门:错误处理操作符 https://cn.rx.js.org/manual/overview.html#h314
catchretryretryWhen
待完善...
工具操作符
官网传送门:工具操作符https://cn.rx.js.org/manual/overview.html#h315
dodelaydelayWhendematerializefinallyletmaterializeobserveOnsubscribeOntimeIntervaltimestamptimeouttimeoutWithtoArraytoPromise
待完善...
条件和布尔操作符
官网传送门:条件和布尔操作符:https://cn.rx.js.org/manual/overview.html#h316
defaultIfEmptyeveryfindfindIndexisEmpty
待完善...
数学和聚合操作符
官网传送门:数学和聚合操作符https://cn.rx.js.org/manual/overview.html#h317
countmaxminreduce
待完善...
总结
总体来说,对于RxJS这种数据流形式来处理我们日常业务中错综复杂的数据是十分有利于维护的,并且在很多复杂的数据运算上来说,RxJS能够给我们带来许多提高效率的操作符,同时还给我们带来了一种新颖的数据操作理念。
我们可以将RxJS比喻做可以发射事件的一种lodash库,封装了很多复杂的操作逻辑,让我们在使用过程中能够以更优雅的方式来进行数据转换与操作。
专注分享当下最实用的前端技术。关注前端达人,与达人一起学习进步!
长按关注"前端达人"
