
用python干活,让别人无活可干!
大家好,欢迎来到 Crossin的编程教室 !
事情是这样的,元旦前有朋友向我寻求帮助,吐槽老板在放假前给他安排一个苦逼的差事,想问问我能不能帮个忙,要不然假期都过不好了
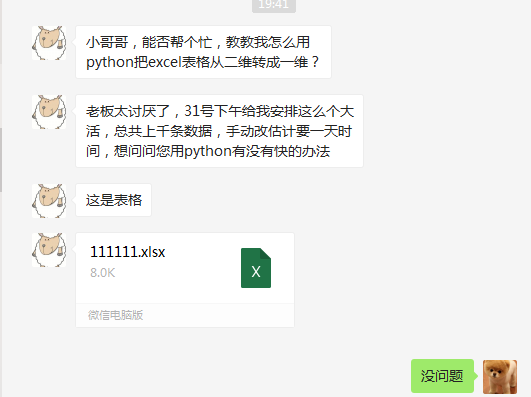
工作的具体内容是需要把一个二维表格转成一维表格。将问题简化抽象,大致是这么个意思(数据为示例):
原表格
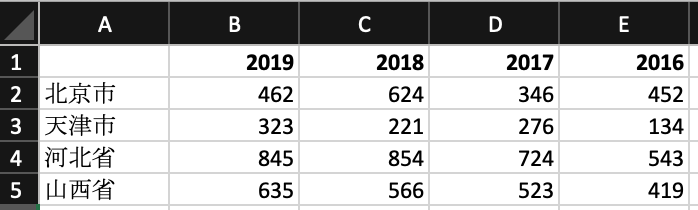
新表格
这问题简单啊,强大的pandas库一定可以搞定!于是我简单网上搜索了一下,就找到函数和参考样例了。而且仅用三行代码就搞定了,惊得朋友直呼python好家伙!
下面给大家详细介绍一下整个过程。
1.正确读取表格
首先按照传统的方式读表格:
import pandas as pd
data1 = pd.read_excel('高中生数量.xlsx')
data1
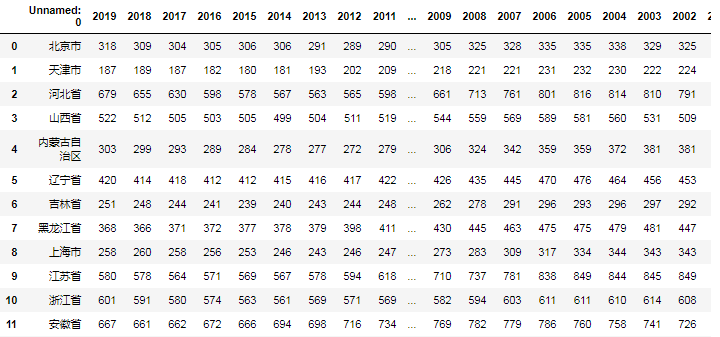
发现索引列没有被识别,产生了Unnamed: 0列,所以我们应该把第一列设置为索引列,代码如下:
import pandas as pd
data1 = pd.read_excel('高中生数量.xlsx',index_col=0) #index_col用来设置索引列
data1
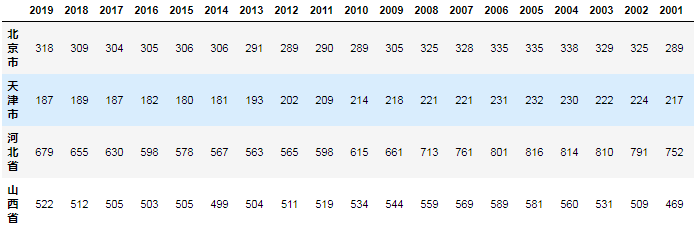
这样就正常读取并识别表格了
2.重置索引
这一步主要是将索引列重置,变为普通列,便于下步,代码如下
data2=data1.reset_index()
data2

可以发现,之前的索引列变成‘index’列了
3.将列名转换为列数据
这一步是整个工作的关键步骤,主要用到pandas的melt函数。melt是逆转操作函数,可以将列名转换为列数据(columns name → column values),重构DataFrame,用法如下:
pandas.melt(frame, id_vars=None, value_vars=None, var_name=None, value_name='value', col_level=None)参数解释:
frame:要处理的数据集;id_vars:不需要被转换的列名;value_vars:需要转换的列名,如果剩下的列全部都要转换,就不用写了;var_name和value_name是自定义设置对应的列名;col_level :如果列是MultiIndex,则使用此级别。
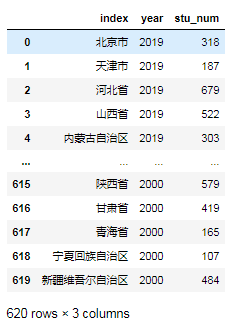
我们把'index'列保留,并把转换后的列命名为'year',value命名为'stu_num':
data3=data2.melt(id_vars='index', var_name='year',value_name='stu_num')
data3
4.把第一列设置为索引列
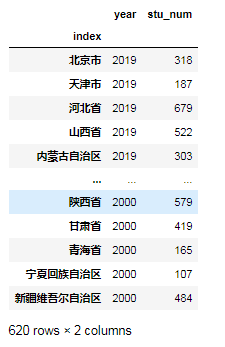
为了防止保存后的表格带有数字索引,需要把第一列设置为索引列:
data4=data3.set_index('index')
data4
5.保存表格
data4.to_excel('转换后表格.xlsx')
大功告成,上述代码可以用1行代码搞定:
data=data.reset_index().melt('index', var_name='col').set_index('index')
是不是很强悍!
幸福就是这么简单,在这里哥想说一句,不是哥优秀,而是python太强大,哈哈!
如果文章对你有帮助,欢迎转发/点赞/收藏!
_往期文章推荐_
评论