
新闻推荐实战(一):MySQL基础
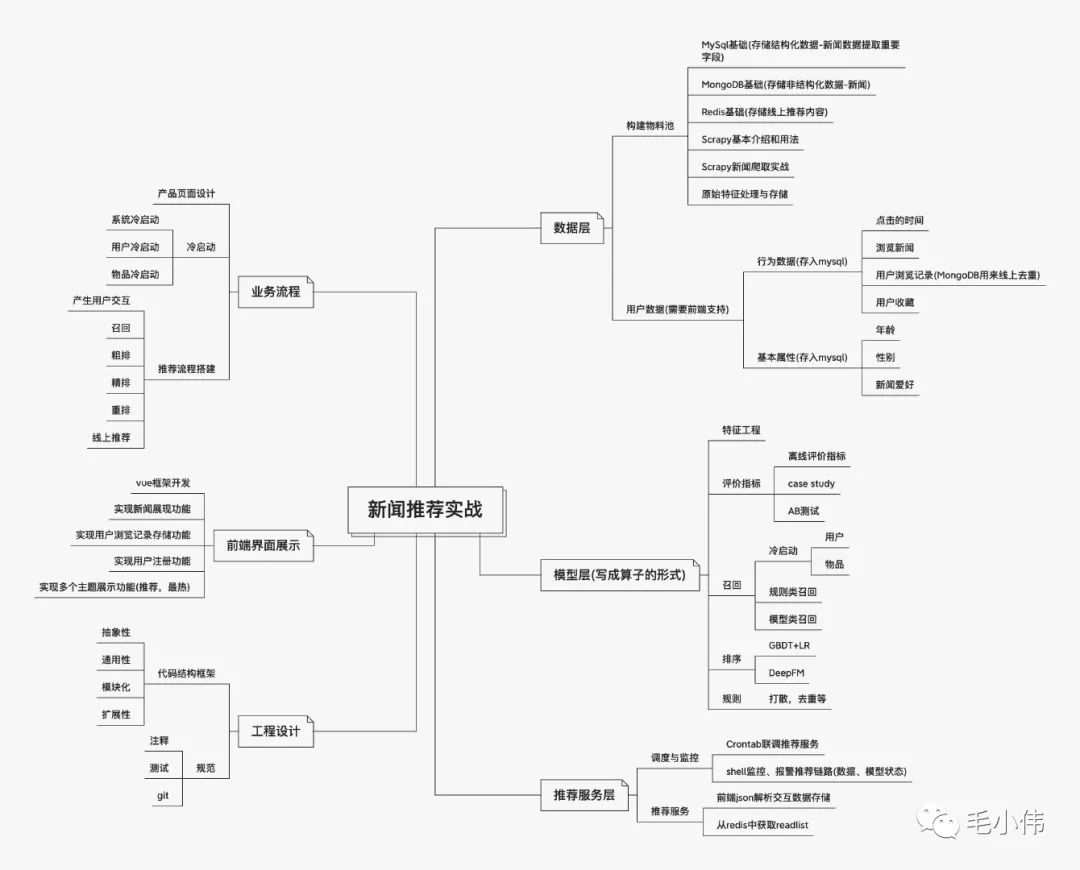
本文属于新闻推荐实战—数据层—构建物料池之MySQL。MySQL数据库在该项目中会用来存储结构化的数据(用户、新闻特征),作为算法工程师需要了解常用的MySQL语法(比如增删改查,排序等),因为在实际的工作经常会用来统计相关数据或者抽取相关特征。本着这个目的,本文对MySQL常见的语法及Python操作MySQL进行了总结,方便大家快速了解。文末附上参考资料
本文目录如下:
1.1 安装
1.2 配置MySQL的安全性
1.3 以root用户登录
1.4 修改密码
1.5 撤销用户授权
1.6 删除用户
2.1 SQL书写规范
2.2 命名规则
2.3 数据类型
(1)数值类型
(2)日期和时间类型
(3)字符串类型
3.1 数据库的创建
3.2 数据库的查看
3.3 选择数据库
3.4 删除数据库
4.1 表的创建
4.2 表的删除
4.3 表的更新
4.4 表的查询
4.5 表的复制
5.1 算术运算符
5.2 比较运算符
5.3 逻辑运算符
6.1 聚合函数
6.2 对表分组
6.3 使用WHERE语句
6.4 为聚合结果指定条件
6.5 对表的查询结果进行排序
7.1 数据的插入
7.2 数据的删除
7.3 数据的更新
8.1 安装pymysql
8.2 连接数据库
8.3 创建游标
8.4 类方法
8.5 实战
前言 MySQL简介
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,属于 Oracle 旗下产品。MySQL 是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一。
MySQL在过去由于性能高、成本低、可靠性好,已经成为最流行的开源数据库,因此被广泛地应用在Internet上的中小型网站中。随着MySQL的不断成熟,它也逐渐用于更多大规模网站和应用,比如维基百科、Google和Facebook等网站。非常流行的开源软件组合LAMP中的“M”指的就是MySQL。
一、 Ubuntu下安装MySQL
安装教程是在Ubuntu20.04下进行的,安装的MySQL版本为8.0.27。
1.1 安装
首先,在终端输入如下的命令:
sudo apt install mysql-server mysql-client
再输入y即可开始安装。
安装完成后,通过运行命令mysql -V查看版本号:
lyons@ubuntu:~$ mysql -V
mysql Ver 8.0.27-0ubuntu0.20.04.1 for Linux on x86_64 ((Ubuntu))
验证MySQL服务正在运行,命令行下输入:
sudo service mysql status
如果正在运行,则会显示:
● mysql.service - MySQL Community Server
Loaded: loaded (/lib/systemd/system/mysql.service; enabled; vendor preset: enabled)
Active: active (running) since Wed 2021-10-27 10:27:59 CST; 9h ago
Main PID: 6179 (mysqld)
Status: "Server is operational"
Tasks: 39 (limit: 4599)
Memory: 348.9M
CGroup: /system.slice/mysql.service
└─6179 /usr/sbin/mysqld
10月 27 10:27:59 ubuntu systemd[1]: Starting MySQL Community Server...
10月 27 10:27:59 ubuntu systemd[1]: Started MySQL Community Server.
Active栏显示active(running)表示MySQL正在运行。之后,输入Ctrl+C退出。
1.2 配置MySQL的安全性
首先,在终端运行命令
mysql_secure_installation:sudo mysql_secure_installationVALIDATE PASSWORD COMPONENT设置验证密码插件。它被用来测试
MySQL用户的密码强度,并且提高安全性。如果想设置验证密码插件,请输入y:Connecting to MySQL using a blank password.
VALIDATE PASSWORD COMPONENT can be used to test passwords
and improve security. It checks the strength of password
and allows the users to set only those passwords which are
secure enough. Would you like to setup VALIDATE PASSWORD component?
Press y|Y for Yes, any other key for No: y接下来,将进行密码验证等级设置,根据数字设置对应等级,这里设置为0:
There are three levels of password validation policy:
LOW Length >= 8
MEDIUM Length >= 8, numeric, mixed case, and special characters
STRONG Length >= 8, numeric, mixed case, special characters and dictionary file
Please enter 0 = LOW, 1 = MEDIUM and 2 = STRONG: 0设置密码
为MySQL root用户设置密码,设置过程中密码不会显示。如果需要设置验证密码插件,请输入
y,在后面将会显示密码的强度。Please set the password for root here.
New password:
Re-enter new password:
Estimated strength of the password: 25
Do you wish to continue with the password provided?(Press y|Y for Yes, any other key for No) : y移除匿名用户
默认情况下,MySQL安装有一个匿名用户,允许任何人登录MySQL,而不必为他们创建用户帐户。输入
y进行删除:By default, a MySQL installation has an anonymous user,
allowing anyone to log into MySQL without having to have
a user account created for them. This is intended only for
testing, and to make the installation go a bit smoother.
You should remove them before moving into a production
environment.
Remove anonymous users? (Press y|Y for Yes, any other key for No) : y
Success.禁止远程root用户登录
输入
y后按enter,将会禁止root用户登录。Normally, root should only be allowed to connect from
'localhost'. This ensures that someone cannot guess at
the root password from the network.
Disallow root login remotely? (Press y|Y for Yes, any other key for No) : y
Success.删除测试库
输入
y后按enter,将会删除测试库。By default, MySQL comes with a database named 'test' that
anyone can access. This is also intended only for testing,
and should be removed before moving into a production
environment.
Remove test database and access to it? (Press y|Y for Yes, any other key for No) : y
- Dropping test database...
Success.重新加载特权表
输入
y后按enter,将会重新加载特权表。- Removing privileges on test database...
Success.
Reloading the privilege tables will ensure that all changes
made so far will take effect immediately.
Reload privilege tables now? (Press y|Y for Yes, any other key for No) : y
Success.
All done!至此,配置完成。
1.3 以root用户登录
在MySQL 8.0上,root 用户默认通过auth_socket插件授权。auth_socket插件通过 Unix socket 文件来验证所有连接到localhost的用户。
这意味着你不能通过提供密码,验证为 root。此时,输入mysql -uroot -p可能会被拒绝访问:
lyons@ubuntu:~$ mysql -uroot -p
mysql: [Warning] Using a password on the command line interface can be insecure.
ERROR 1698 (28000): Access denied for user 'root'@'localhost'
若要以 root 用户身份登录 MySQL服务器,输入sudo mysql,如下:
# 登录密码为linux系统用户的root密码
lyons@ubuntu:~$ sudo mysql
[sudo] lyons 的密码:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 55
Server version: 8.0.27-0ubuntu0.20.04.1 (Ubuntu)
Copyright (c) 2000, 2021, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
退出MySQL,请输入exit命令:
mysql> exit
Bye
lyons@ubuntu:~$
如果你想以 root 身份登录 MySQL 服务器,使用其他的程序,有两个选择。
方式1
修改登录root用户的密码验证方法从auth_socket修改成mysql_native_password。
首先通过sudo mysql进入MySQL,然后在MySQL下将密码的验证方式设置为mysql_native_password,命令如下:
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '你的密码';
FLUSH PRIVILEGES;
示例:
-- 首先要以root的身份登录mysql
-- sudo mysql
-- 设置root用户的登陆密码,方式为mysql_native_password
mysql> ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'mysql123';
Query OK, 0 rows affected (0.00 sec)
-- 刷新系统权限
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.01 sec)
-- 退出
mysql> exit
Bye
通过mysql -uroot -p登录:
# 登录密码为前面设置的mysql123
lyons@ubuntu:~$ mysql -uroot -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 57
Server version: 8.0.27-0ubuntu0.20.04.1 (Ubuntu)
Copyright (c) 2000, 2021, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
如果要改回通过sudo mysql验证root用户登录,将root用户的密码验证方式改为auth_socket即可:
ALTER USER 'root'@'localhost' IDENTIFIED WITH auth_socket BY '你的密码';
方式2
推荐的选项,就是创建一个新的独立管理用户,拥有所有数据库的访问权限。核心命令如下:
-- 1. 创建用户admin
CREATE USER 'admin'@'localhost' IDENTIFIED BY '你的密码';
-- 2. 赋予admin用户
-- with gran option表示该用户可给其它用户赋予权限,但不可能超过该用户已有的权限
GRANT ALL PRIVILEGES ON *.* TO 'admin'@'localhost' with grant option;
其中,'admin'@'localhost'中,admin为用户名,你可以自定义。localhost指本地才可连接,可以将其换成%指任意ip都能连接,也可以指定ip连接。
示例:
-- 首先要以root的身份登录mysql
mysql> CREATE USER 'admin'@'localhost' IDENTIFIED BY 'mysql123';
Query OK, 0 rows affected (0.01 sec)
mysql> GRANT ALL PRIVILEGES ON *.* TO 'admin'@'localhost' with grant option;
Query OK, 0 rows affected (0.00 sec)
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.01 sec)
-- 此时再查看mysql下的user表
-- 会发现多了一名用户admin
mysql> SELECT user, host FROM mysql.user;
+------------------+-----------+
| user | host |
+------------------+-----------+
| admin | localhost |
| debian-sys-maint | localhost |
| mysql.infoschema | localhost |
| mysql.session | localhost |
| mysql.sys | localhost |
| root | localhost |
+------------------+-----------+
6 rows in set (0.00 sec)
退出root用户,使用admin用户登陆:
lyons@ubuntu:~$ mysql -uroot -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 17
Server version: 8.0.26 MySQL Community Server - GPL
Copyright (c) 2000, 2021, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
1.4 修改密码
将用户admin的登录密码修改为mysql321:
ALTER USER 'admin'@'localhost' IDENTIFIED WITH mysql_native_password BY '你的密码';
你可以根据自己对应的用户名和host去修改密码,mysql_native_password指定的是密码验证方式。
1.5 撤销用户授权
以用户admin举例,撤销该用户的权限:
-- 查看用户的权限
SHOW GRANTS FOR 'admin'@'localhost';
-- 撤销用户所有的权限
REVOKE ALL PRIVILEGES ON *.* FROM 'admin'@'localhost';
示例:
-- 查看权限
mysql> SHOW GRANTS FOR 'admin'@'localhost' \G
*************************** 1. row ***************************
Grants for admin@localhost: GRANT SELECT, INSERT, UPDATE, DELETE, CREATE, DROP, RELOAD, SHUTDOWN, PROCESS, FILE, REFERENCES, INDEX, ALTER, SHOW DATABASES, SUPER, CREATE TEMPORARY TABLES, LOCK TABLES, EXECUTE, REPLICATION SLAVE, REPLICATION CLIENT, CREATE VIEW, SHOW VIEW, CREATE ROUTINE, ALTER ROUTINE, CREATE USER, EVENT, TRIGGER, CREATE TABLESPACE, CREATE ROLE, DROP ROLE ON *.* TO `admin`@`localhost` WITH GRANT OPTION
*************************** 2. row ***************************
Grants for admin@localhost: GRANT APPLICATION_PASSWORD_ADMIN,AUDIT_ADMIN,BACKUP_ADMIN,BINLOG_ADMIN,BINLOG_ENCRYPTION_ADMIN,CLONE_ADMIN,CONNECTION_ADMIN,ENCRYPTION_KEY_ADMIN,FLUSH_OPTIMIZER_COSTS,FLUSH_STATUS,FLUSH_TABLES,FLUSH_USER_RESOURCES,GROUP_REPLICATION_ADMIN,INNODB_REDO_LOG_ARCHIVE,INNODB_REDO_LOG_ENABLE,PERSIST_RO_VARIABLES_ADMIN,REPLICATION_APPLIER,REPLICATION_SLAVE_ADMIN,RESOURCE_GROUP_ADMIN,RESOURCE_GROUP_USER,ROLE_ADMIN,SERVICE_CONNECTION_ADMIN,SESSION_VARIABLES_ADMIN,SET_USER_ID,SHOW_ROUTINE,SYSTEM_USER,SYSTEM_VARIABLES_ADMIN,TABLE_ENCRYPTION_ADMIN,XA_RECOVER_ADMIN ON *.* TO `admin`@`localhost` WITH GRANT OPTION
2 rows in set (0.00 sec)
-- 取消用户的权限
mysql> REVOKE ALL PRIVILEGES ON *.* FROM 'admin'@'localhost';
Query OK, 0 rows affected (0.01 sec)
-- 再次查看权限
mysql> SHOW GRANTS FOR 'admin'@'localhost' \G
*************************** 1. row ***************************
Grants for admin@localhost: GRANT USAGE ON *.* TO `admin`@`localhost`
1 row in set (0.00 sec)
1.6 删除用户
以用户admin举例,删除该用户:
-- 删除用户后,无法再用该用户登陆
DROP USER 'admin'@'localhost';
注:MySQL 8.0版本和5.0部分命令有所改掉,上述语法都是在8.0版本下运行通过的;请务必检查自己的MySQL版本号。
二、MySQL预备知识
在正式学习MySQL之前,我们先来了解一下SQL语句的书写规范以及命名规则等。
2.1 SQL书写规范
在写SQL语句时,要求按照如下规范进行:
SQL 语句要以分号(;)结尾
SQL 不区分关键字的大小写 ,这对于表名和列名同样适用。
插入到表中的数据是区分大小写的。例如,数据Computer、COMPUTER 或computer,三者是不一样的。
常数的书写方式是固定的,在SQL 语句中直接书写的字符串、日期或者数字等称为常数。常数的书写方式如下所示。
SQL 语句中含有字符串的时候,需要像'abc'这样,使用单引号(')将字符串括起来,用来标识这是一个字符串。 SQL 语句中含有日期的时候,同样需要使用单引号将其括起来。日期的格式有很多种('26 Jan 2010' 或者'10/01/26' 等)。 在SQL 语句中书写数字的时候,不需要使用任何符号标识,直接写成1000 这样的数字即可。 单词之间需要用半角空格或者换行来分隔。
SQL中的注释主要采用
--和/* ... */的方式,第二种方式可以换行。在MySQL下,还可以通过#来进行注释。
2.2 命名规则
在数据库中,只能使用半角英文字母、数字、下划线(_)作为数据库、表和列的名称 。 名称必须以半角英文字母作为开头。 名称不能重复,同一个数据库下不能有2张相同的表。
2.3 数据类型
MySQL 支持所有标准 SQL 数值数据类型,包括:
(1)数值类型
数值包含的类型如下:
整型数据:
TINYINT、INTEGER、SMALLINT、MEDIUMINT、DECIMAL、NUMERIC和BIGINT。浮点型数据:
DECIMAL、FLOAT、REAL和DOUBLE PRECISION)。
其中,关键字INT是INTEGER的同义词,关键字DEC是的同义词。
不同关键字的主要区别就是表示的范围或精度不一样。具体如下表:
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| TINYINT | 1 Bytes | (-128,127) | (0,255) | 小整数值 |
| SMALLINT | 2 Bytes | (-32 768,32 767) | (0,65 535) | 大整数值 |
| MEDIUMINT | 3 Bytes | (-8 388 608,8 388 607) | (0,16 777 215) | 大整数值 |
| INT或INTEGER | 4 Bytes | (-2 147 483 648,2 147 483 647) | (0,4 294 967 295) | 大整数值 |
| BIGINT | 8 Bytes | (-9,223,372,036,854,775,808,9 223 372 036 854 775 807) | (0,18 446 744 073 709 551 615) | 极大整数值 |
| FLOAT | 4 Bytes | (-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) | 0,(1.175 494 351 E-38,3.402 823 466 E+38) | 单精度 浮点数值 |
| DOUBLE | 8 Bytes | (-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 双精度 浮点数值 |
| DECIMAL | 对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 | 依赖于M和D的值 | 依赖于M和D的值 | 小数值 |
(2)日期和时间类型
表示时间值的日期和时间类型为DATETIME、DATE、TIMESTAMP、TIME和YEAR。具体如下表:
| 类型 | 大小 ( bytes) | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | '-838:59:59'/'838:59:59' | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:00/2038结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07 | YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
(3)字符串类型
字符串类型指CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM和SET。具体如下表:
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 0-255 bytes | 定长字符串 |
| VARCHAR | 0-65535 bytes | 变长字符串 |
| TINYBLOB | 0-255 bytes | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255 bytes | 短文本字符串 |
| BLOB | 0-65 535 bytes | 二进制形式的长文本数据 |
| TEXT | 0-65 535 bytes | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215 bytes | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295 bytes | 极大文本数据 |
char声明的是定长字符串。若实际中字符串长度不足,则会在末尾使用空格进行填充至声明的长度。varchar声明的是可变长字符串。存储过程中,只会按照字符串的实际长度来存储。另加一个字节来记录长度(如果字段声明的长度超过255,则使用两个字节)。
三、 数据库的基本操作
首先,我们来学习在MySQL下如何操作数据库。
3.1 数据库的创建
通过CREATE命令,可以创建指定名称的数据库,语法结构如下:
CREATE DATABASE [IF NOT EXISTS] <数据库名称>;
MySQL 的数据存储区将以目录方式表示 MySQL 数据库,因此数据库名称必须符合操作系统的文件夹命名规则,不能以数字开头,尽量要有实际意义。
MySQL下不运行存在两个相同名字的数据库,否则会报错。如果使用IF NOT EXISTS(可选项),可以避免此类错误。
示例:
-- 创建名为shop的数据库。
CREATE DATABASE shop;
3.2 数据库的查看
查看所有存在的数据库
SHOW DATABASES [LIKE '数据库名'];;
LIKE从句是可选项,用于匹配指定的数据库名称。LIKE 从句可以部分匹配,也可以完全匹配。
示例:
SHOW DATABASES;
-- 结果如下:
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| shop |
| sys |
+--------------------+
5 rows in set (0.01 sec)
-- %表示任意0个或多个字符,可匹配任意类型和长度的字符。
SHOW DATABASES LIKE 'S%';
-- 结果如下
+---------------+
| Database (S%) |
+---------------+
| shop |
| sys |
+---------------+
2 rows in set (0.00 sec)
查看创建的数据库
SHOW CREATE DATABASE <数据库名>;
示例:
SHOW CREATE DATABASE shop;
-- 或者
SHOW CREATE DATABASE shop \G
-- 结果如下
*************************** 1. row ***************************
Database: shop
Create Database: CREATE DATABASE `shop` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */
1 row in set (0.00 sec)
CHARACTER SET utf8mb4表示编码字符集为utf8mb4。
3.3 选择数据库
在操作数据库前,必须指定所要操作的数据库。通过USE命令,可以切换到对应的数据库下。
USE <数据库名>
示例:
-- 切换到数据库shop下。
USE shop;
-- 结果如下
Database changed
3.4 删除数据库
通过DROP命令,可以将相应数据库进行删除。
DROP DATABASE [IF EXISTS] <数据库名>
其中,IF EXISTS为可选性,用于防止数据库不存在时报错。
示例:
DROP DATABASE shop;
SHOW DATABASES;
考虑到后面表的操作都是shop数据库下,在实验完DROP删除数据库命令后,请从新创建数据库shop并通过USE命令切换到该数据库下。
四、表的基本操作
表相当于文件,表中的一条记录就相当于文件的一行内容,不同的是,表中的一条记录有对应的标题,称为表的字段。
4.1 表的创建
创建表的语法结构如下:
CREATE TABLE <表名> (<字段1> <数据类型> <该列所需约束>,
<字段2> <数据类型> <该列所需约束>,
<字段3> <数据类型> <该列所需约束>,
<字段4> <数据类型> <该列所需约束>,
.
.
.
<该表的约束1>, <该表的约束2>,……);
示例:
-- 创建一个名为Product的表
CREATE TABLE Product(
product_id CHAR(4) NOT NULL,
product_name VARCHAR(100) NOT NULL,
product_type VARCHAR(32) NOT NULL,
sale_price INT,
purchase_price INT,
regist_date DATE,
PRIMARY KEY (product_id)
);
在第二章中,我们介绍过不同的数据类型:
CHAR为定长字符,这里CHAR旁边括号里的数字表示该字段最长为多少字符,少于该数字将会使用空格进行填充。VARCHAR表示变长字符,括号里的数字表示该字段最长为多少字符,存储时只会按照字符的实际长度来存储,但会使用额外的1-2字节来存储值长度。
简单介绍一下该语句中出现的约束条件:
PRIMARY KEY:主键,表示该字段对应的内容唯一且不能为空。NOT NULL:在NULL之前加上了表示否定的NOT,表示该字段不能输入空白。
关于各类约束条件的具体含义和用法,可以参考菜鸟SQL教程中的约束,文末附有参考链接。
通过SHOW TABLES命令来查看当前数据库下的所有的表名:
SHOW TABLES;
-- 结果如下
+----------------+
| Tables_in_shop |
+----------------+
| Product |
+----------------+
1 rows in set (0.00 sec)
通过DESC <表名>来查看表的结构:
DESC Product;
-- 结果如下
+----------------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------------+--------------+------+-----+---------+-------+
| product_id | char(4) | NO | PRI | NULL | |
| product_name | varchar(100) | NO | | NULL | |
| product_type | varchar(32) | NO | | NULL | |
| sale_price | int | YES | | NULL | |
| purchase_price | int | YES | | NULL | |
| regist_date | date | YES | | NULL | |
+----------------+--------------+------+-----+---------+-------+
6 rows in set (0.00 sec)
4.2 表的删除
删除表的语法结构如下:
DROP TABLE <表名>;
-- 例如:DROP TABLE Product;
说明:通过DROP删除的表示无法恢复的,在删除表的时候请谨慎。
4.3 表的更新
通过ALTER TABLE语句,我们可以对表字段进行不同的操作,下面通过示例来具体学习用法。
示例:
创建一张名为Student的表
CREATE TABLE Student(
id INT PRIMARY KEY,
name CHAR(15)
);
DESC student;
-- 结果如下
+-------+----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+----------+------+-----+---------+-------+
| id | int | NO | PRI | NULL | |
| name | char(15) | YES | | NULL | |
+-------+----------+------+-----+---------+-------+
2 rows in set (0.00 sec)
更改表名
通过
RENAME命令,将表名从Student => Students。
ALTER TABLE Student RENAME Students;
插入新的字段
通过
ADD命令,新增字段sex和age。
-- 不同的字段通过逗号分开
ALTER TABLE Students ADD sex CHAR(1), ADD age INT;
其它插入技巧:
-- 通过FIRST在表首插入字段stu_num
ALTER TABLE Students ADD stu_num INT FIRST;
-- 指定在字段sex后插入字段height
ALTER TABLE Students ADD height INT AFTER sex;
DESC Students;
-- 结果如下
+---------+----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+----------+------+-----+---------+-------+
| stu_num | int | YES | | NULL | |
| id | int | NO | PRI | NULL | |
| name | char(15) | YES | | NULL | |
| sex | char(1) | YES | | NULL | |
| height | int | YES | | NULL | |
| age | int | YES | | NULL | |
+---------+----------+------+-----+---------+-------+
6 rows in set (0.00 sec)
字段的删除
通过
DROP命令,可以对不在需要的字段进行删除。
-- 删除字段stu_num
ALTER TABLE Students DROP stu_num;
字段的修改
通过
MODIFY修改字段的数据类型。
-- 修改字段age的数据类型
ALTER TABLE Students MODIFY age CHAR(3);
通过CHANGE命令,修改字段名或类型
-- 修改字段name为stu_name,不修改数据类型
ALTER TABLE Students CHANGE name stu_name CHAR(15);
-- 修改字段sex为stu_sex,数据类型修改为int
ALTER TABLE Students CHANGE sex stu_sex INT;
DESC Students;
-- 结果如下
+----------+----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+----------+------+-----+---------+-------+
| id | int | NO | PRI | NULL | |
| stu_name | char(20) | YES | | NULL | |
| stu_sex | int | YES | | NULL | |
| height | int | YES | | NULL | |
| age | char(3) | YES | | NULL | |
+----------+----------+------+-----+---------+-------+
5 rows in set (0.00 sec)
4.4 表的查询
通过SELECT语句,可以从表中取出所要查看的字段的内容:
SELECT <字段名>, ……
FROM <表名>;
如要直接查询表的全部字段:
SELECT *
FROM <表名>;
其中,**星号(*)**代表全部字段的意思。
示例:
建表并插入数据
在MySQL中,我们通过
INSERT语句往表中插入数据,该语句在后面会详细介绍,该小节的重点是学会使用SELECT。
-- 向Product表中插入数据
INSERT INTO Product VALUES
('0001', 'T恤衫', '衣服', 1000, 500, '2009-09-20'),
('0002', '打孔器', '办公用品', 500, 320, '2009-09-11'),
('0003', '运动T恤', '衣服', 4000, 2800, NULL),
('0004', '菜刀', '厨房用具', 3000, 2800, '2009-09-20'),
('0005', '高压锅', '厨房用具', 6800, 5000, '2009-01-15'),
('0006', '叉子', '厨房用具', 500, NULL, '2009-09-20'),
('0007', '擦菜板', '厨房用具', 880, 790, '2008-04-28'),
('0008', '圆珠笔', '办公用品', 100, NULL,'2009-11-11')
;
查看表的内容
-- 查看表的全部内容
SELECT *
FROM Product;
-- 结果如下
+------------+--------------+--------------+------------+----------------+-------------+
| product_id | product_name | product_type | sale_price | purchase_price | regist_date |
+------------+--------------+--------------+------------+----------------+-------------+
| 0001 | T恤衫 | 衣服 | 1000 | 500 | 2009-09-20 |
| 0002 | 打孔器 | 办公用品 | 500 | 320 | 2009-09-11 |
| 0003 | 运动T恤 | 衣服 | 4000 | 2800 | NULL |
| 0004 | 菜刀 | 厨房用具 | 3000 | 2800 | 2009-09-20 |
| 0005 | 高压锅 | 厨房用具 | 6800 | 5000 | 2009-01-15 |
| 0006 | 叉子 | 厨房用具 | 500 | NULL | 2009-09-20 |
| 0007 | 擦菜板 | 厨房用具 | 880 | 790 | 2008-04-28 |
| 0008 | 圆珠笔 | 办公用品 | 100 | NULL | 2009-11-11 |
+------------+--------------+--------------+------------+----------------+-------------+
8 rows in set (0.00 sec)
-- 查看部分字段包含的内容
SELECT
product_id,
product_name,
sale_price
FROM Product;
-- 结果如下
+------------+--------------+------------+
| product_id | product_name | sale_price |
+------------+--------------+------------+
| 0001 | T恤衫 | 1000 |
| 0002 | 打孔器 | 500 |
| 0003 | 运动T恤 | 4000 |
| 0004 | 菜刀 | 3000 |
| 0005 | 高压锅 | 6800 |
| 0006 | 叉子 | 500 |
| 0007 | 擦菜板 | 880 |
| 0008 | 圆珠笔 | 100 |
+------------+--------------+------------+
8 rows in set (0.00 sec)
对查看的字段从新命名
通过
AS语句对展示的字段另起别名,这不会修改表内字段的名字。
SELECT
product_id AS ID,
product_type AS TYPE
FROM Product;
-- 结果如下
+------+--------------+
| ID | TYPE |
+------+--------------+
| 0001 | 衣服 |
| 0002 | 办公用品 |
| 0003 | 衣服 |
| 0004 | 厨房用具 |
| 0005 | 厨房用具 |
| 0006 | 厨房用具 |
| 0007 | 厨房用具 |
| 0008 | 办公用品 |
+------+--------------+
8 rows in set (0.00 sec)
设定汉语别名时需要使用双引号(")括起来,英文字符则不需要。
SELECT
product_id AS "产品编号",
product_type AS "产品类型"
FROM Product;
常数的查询
SELECT子句中,除了可以写字段外,还可以写常数。
SELECT
'商品' AS string,
'2009-05-24' AS date,
product_id,
product_name
FROM Product;
-- 结果如下
+--------+------------+------------+--------------+
| string | date | product_id | product_name |
+--------+------------+------------+--------------+
| 商品 | 2009-05-24 | 0001 | T恤衫 |
| 商品 | 2009-05-24 | 0002 | 打孔器 |
| 商品 | 2009-05-24 | 0003 | 运动T恤 |
| 商品 | 2009-05-24 | 0004 | 菜刀 |
| 商品 | 2009-05-24 | 0005 | 高压锅 |
| 商品 | 2009-05-24 | 0006 | 叉子 |
| 商品 | 2009-05-24 | 0007 | 擦菜板 |
| 商品 | 2009-05-24 | 0008 | 圆珠笔 |
+--------+------------+------------+--------------+
8 rows in set (0.00 sec)
删除重复行
在
SELECT语句中使用DISTINCT可以去除重复行。
SELECT
DISTINCT regist_date
FROM Product;
-- 结果如下
+-------------+
| regist_date |
+-------------+
| 2009-09-20 |
| 2009-09-11 |
| NULL |
| 2009-01-15 |
| 2008-04-28 |
| 2009-11-11 |
+-------------+
6 rows in set (0.01 sec)
在使用DISTINCT 时,NULL也被视为一类数据。NULL存在于多行中时,会被合并为一条NULL数据。
还可以通过组合使用,来去除列组合重复的数据。DISTINCT关键字只能用在第一个列名之前。
SELECT
DISTINCT product_type, regist_date
FROM Product;
-- 结果如下,列出了所有的组合
+--------------+-------------+
| product_type | regist_date |
+--------------+-------------+
| 衣服 | 2009-09-20 |
| 办公用品 | 2009-09-11 |
| 衣服 | NULL |
| 厨房用具 | 2009-09-20 |
| 厨房用具 | 2009-01-15 |
| 厨房用具 | 2008-04-28 |
| 办公用品 | 2009-11-11 |
+--------------+-------------+
7 rows in set (0.00 sec)
指定查询条件
首先通过
WHERE子句查询出符合指定条件的记录,然后再选取出SELECT语句指定的列,语法结构如下:
SELECT <字段名>, ……
FROM <表名>
WHERE <条件表达式>;
示例:
SELECT product_name
FROM Product
WHERE product_type = '衣服';
-- 结果如下
+--------------+
| product_name |
+--------------+
| T恤衫 |
| 运动T恤 |
+--------------+
2 rows in set (0.01 sec)
注意,WHERE子句要紧跟在FROM子句之后。
4.5 表的复制
表的复制可以将表结构与表中的数据全部复制,或者只复制表的结构。
-- 将整个表复制过来
CREATE TABLE Product_COPY1
SELECT * FROM Product;
SELECT * FROM Product_COPY1;
-- 结果如下
+------------+--------------+--------------+------------+----------------+-------------+
| product_id | product_name | product_type | sale_price | purchase_price | regist_date |
+------------+--------------+--------------+------------+----------------+-------------+
| 0001 | T恤衫 | 衣服 | 1000 | 500 | 2009-09-20 |
| 0002 | 打孔器 | 办公用品 | 500 | 320 | 2009-09-11 |
| 0003 | 运动T恤 | 衣服 | 4000 | 2800 | NULL |
| 0004 | 菜刀 | 厨房用具 | 3000 | 2800 | 2009-09-20 |
| 0005 | 高压锅 | 厨房用具 | 6800 | 5000 | 2009-01-15 |
| 0006 | 叉子 | 厨房用具 | 500 | NULL | 2009-09-20 |
| 0007 | 擦菜板 | 厨房用具 | 880 | 790 | 2008-04-28 |
| 0008 | 圆珠笔 | 办公用品 | 100 | NULL | 2009-11-11 |
+------------+--------------+--------------+------------+----------------+-------------+
8 rows in set (0.00 sec)
-- 通过LIKE复制表结构
CREATE TABLE Product_COPY2
LIKe Product;
SELECT * FROM Product_COPY2;
-- 结果如下
Empty set (0.00 sec) -- 表为空的
DESC Product_COPY2;
-- 结果如下
-- 表结构已复制过来
+----------------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------------+--------------+------+-----+---------+-------+
| product_id | char(4) | NO | PRI | NULL | |
| product_name | varchar(100) | NO | | NULL | |
| product_type | varchar(32) | NO | | NULL | |
| sale_price | int | YES | | 0 | |
| purchase_price | int | YES | | NULL | |
| regist_date | date | YES | | NULL | |
+----------------+--------------+------+-----+---------+-------+
6 rows in set (0.01 sec)
五、运算符
5.1 算术运算符
我们可以在SELECT语句中使用计算表达式:
SELECT
product_name,
sale_price,
sale_price * 2 AS "sale_price_x2"
FROM Product;
-- 结果如下
+--------------+------------+---------------+
| product_name | sale_price | sale_price_x2 |
+--------------+------------+---------------+
| T恤衫 | 1000 | 2000 |
| 打孔器 | 500 | 1000 |
| 运动T恤 | 4000 | 8000 |
| 菜刀 | 3000 | 6000 |
| 高压锅 | 6800 | 13600 |
| 叉子 | 500 | 1000 |
| 擦菜板 | 880 | 1760 |
| 圆珠笔 | 100 | 200 |
+--------------+------------+---------------+
8 rows in set (0.00 sec)
四则运算所使用的运算符**(+、-、*、/)**称为算术运算符。
在运算表达式中,也可以使用**()**,括号中的运算表达式优先级会得到提升。
NULL的计算结果,仍然还是NULL。
5.2 比较运算符
在 WHERE 子句中通过使用比较运算符可以组合出各种各样的条件表达式。
SELECT product_name, product_type
FROM Product
WHERE sale_price = 500;
常见比较运算符如下表:
| 运算符 | 含义 |
|---|---|
| = | 相等 |
| <> | 不相等 |
| >= | 大于等于 |
| > | 大于 |
| <= | 小于等于 |
| < | 小于 |
不能对NULL使用任何比较运算符,只能通过 IS NULL语句来判断:
SELECT
product_name,
purchase_price
FROM Product
WHERE purchase_price IS NULL;
希望选取不是 NULL 的记录时,需要使用IS NOT NULL运算符。
对字符串使用比较符
MySQL中字符串的排序与数字不同,典型的规则就是按照字典顺序进行比较,也就是像姓名那样,按照条目在字典中出现的顺序来进行排序。例如:
'1' < '10' < '11' < '2' < '222' < '3'
5.3 逻辑运算符
使用 NOT否认某一条件:
SELECT
product_name,
product_type,
sale_price
FROM Product
WHERE NOT sale_price >= 1000;
AND运算符合OR运算符
SELECT product_type, sale_price
FROM Product
WHERE product_type = '厨房用具'
AND sale_price >= 3000;
-- 结果如下
+--------------+------------+
| product_type | sale_price |
+--------------+------------+
| 厨房用具 | 3000 |
| 厨房用具 | 6800 |
+--------------+------------+
2 rows in set (0.00 sec)
SELECT product_type, sale_price
FROM Product
WHERE product_type = '厨房用具'
OR sale_price >= 3000;
-- 结果如下
+--------------+------------+
| product_type | sale_price |
+--------------+------------+
| 衣服 | 4000 |
| 厨房用具 | 3000 |
| 厨房用具 | 6800 |
| 厨房用具 | 500 |
| 厨房用具 | 880 |
+--------------+------------+
5 rows in set (0.00 sec)
逻辑运算符和真值
符NOT、AND 和 OR 称为逻辑运算符;
真值就是值为真(TRUE)或假 (FALSE);
在查询NULL时,SQL中存在第三种真值,不确定(UNKNOWN),NULL和任何值做逻辑运算结果都是不确定;
考虑 NULL 时的条件判断也会变得异常复杂,因此尽量给字段加上NOT NULL的约束。
六、分组查询
6.1 聚合函数
通过 SQL 对数据进行某种操作或计算时需要使用函数。
COUNT:计算表中的记录数(行数)SUM: 计算表中数值列中数据的合计值AVG: 计算表中数值列中数据的平均值MAX: 求出表中任意列中数据的最大值MIN: 求出表中任意列中数据的最小值
示例:
-- 计算全部数据的行数
SELECT COUNT(*) FROM Product;
-- 结果如下
+----------+
| COUNT(*) |
+----------+
| 8 |
+----------+
1 row in set (0.00 sec)
注意点1:除了COUNT可以将*作为参数,其它的函数均不可以。
-- 计算最高的销售价格
SELECT MAX(sale_price) FROM Product;
-- 结果如下
+-----------------+
| MAX(sale_price) |
+-----------------+
| 680000 |
+-----------------+
1 row in set (0.00 sec)
**注意点2:**当将字段名作为参数传递给函数时,只会计算不包含NULL的行。
示例:
-- purchase_price字段是包含NULL值的
SELECT purchase_price FROM Product;
-- 结果如下
+----------------+
| purchase_price |
+----------------+
| 500 |
| 320 |
| 2800 |
| 700 |
| 1250 |
| NULL |
| 198 |
| NULL |
+----------------+
8 rows in set (0.00 sec)
以*为参数传递给COUNT函数
SELECT COUNT(*) FROM Product;
-- 结果如下
+----------+
| COUNT(*) |
+----------+
| 8 |
+----------+
1 row in set (0.00 sec)
以purchase_price为参数传递给COUNT函数
SELECT COUNT(purchase_price) FROM Product;
-- 结果如下
+-----------------------+
| COUNT(purchase_price) |
+-----------------------+
| 6 |
+-----------------------+
1 row in set (0.00 sec)
可以看到结果并不一样,函数忽略了值为NULL的行。
SUM,AVG函数时也一样,计算时会直接忽略,**并不会当做0来处理!**特别注意AVG函数,计算时分母也不会算上NULL行。
注意点3:MAX/MIN函数几乎适用于所有数据类型的列,包括字符和日期。SUM/AVG函数只适用于数值类型的列。
注意点4:在聚合函数删除重复值
SELECT COUNT(DISTINCT product_type)
FROM Product;
-- 结果如下
+------------------------------+
| COUNT(DISTINCT product_type) |
+------------------------------+
| 3 |
+------------------------------+
1 row in set (0.01 sec)
DISTINCT必须写在括号中。这是因为必须要在计算行数之前删除 product_type 字段中的重复数据。
6.2 对表分组
如果对Python的Pandas熟悉,那么大家应该很了解groupby函数,可以根据指定的列名,对表进行分组。在MySQL中,也存在同样作用的函数,即GROUP BY。
语法结构如下:
SELECT <列名1>, <列名2>, <列名3>, ……
FROM <表名>
GROUP BY <列名1>, <列名2>, <列名3>, ……;
示例:
SELECT product_type, COUNT(*)
FROM Product
GROUP BY product_type;
-- 结果如下
+--------------+----------+
| product_type | COUNT(*) |
+--------------+----------+
| 衣服 | 2 |
| 办公用品 | 2 |
| 厨房用具 | 4 |
+--------------+----------+
3 rows in set (0.01 sec)
在该语句中,我们首先通过
GROUP BY函数对指定的字段product_type进行分组。分组时,product_type字段中具有相同值的行会汇聚到同一组。最后通过
COUNT函数,统计不同分组的包含的行数。
简单来理解:
例如做操时,老师将不同身高的同学进行分组,相同身高的同学会被分到同一组,分组后我们又统计了每个小组的学生数。
将这里的同学可以理解为表中的一行数据,身高理解为表的某一字段。
分组操作就是
GROUP BY,GROUP BY后面接的字段等价于按照身高分组,统计学生数就等价于在SELECT后用了COUNT(*)函数。
注意:GROUP BY子句的位置一定要写在FROM 语句之后(如果有 WHERE 子句的话需要写在 WHERE 子句之后)
1. SELECT → 2. FROM → 3. WHERE → 4. GROUP BY
当被聚合的键中,包含NULL时,在结果中会以“不确定”行(空行)的形式表现出来,也就是字段中为NULL的数据会被聚合为一组。
6.3 使用WHERE语句
在对表进行分组之前,也可以是先使用WHERE对表进行条件过滤,然后再进行分组处理。语法结构如下:
SELECT <列名1>, <列名2>, <列名3>, ……
FROM <表名>
WHERE
GROUP BY <列名1>, <列名2>, <列名3>, ……;
示例:
-- WHERE语句先将表中类型为衣服的行筛选出来
-- 然后再按照purchase_price来进行分组
SELECT purchase_price, COUNT(*)
FROM Product
WHERE product_type = '衣服'
GROUP BY purchase_price;
-- 结果如下
+----------------+----------+
| purchase_price | COUNT(*) |
+----------------+----------+
| 500 | 1 |
| 2800 | 1 |
+----------------+----------+
2 rows in set (0.01 sec)
该语法实际的执行顺序为:
FROM → WHERE → GROUP BY → SELECT
使用 GROUP BY子句时,SELECT子句中不能出现聚合键之外的字段名。即,若GROUP BY选中purchase_price字段进行分组,则在SELECT语句中只能选中purchase_price字段,其它字段如product_id等均不行。WHERE语句中,不可以使用聚合函数。WHERE子句只能指定记录(行)的条件,而不能用来指定组的条件。即WHERE MAX(purchase_price) > 1000这样的语句是非法的。
6.4 为聚合结果指定条件
前面提到了WHERE语句中不能使用聚合函数,但是实际操作时需要通过聚合函数来进行过滤怎么办呢?这就要用到HAVING语句了。语法结构如下:
SELECT <列名1>, <列名2>, <列名3>, ……
FROM <表名>
GROUP BY <列名1>, <列名2>, <列名3>, ……
HAVING <分组结果对应的条件>
在HAVING的子句中能够使用的 3 种要素如下所示:
● 常数
● 聚合函数
● GROUP BY子句中指定的字段名(即聚合键)
示例:
-- 不使用HAVING语句
SELECT product_type, AVG(sale_price)
FROM Product
GROUP BY product_type;
-- 结果如下
+--------------+-----------------+
| product_type | AVG(sale_price) |
+--------------+-----------------+
| 衣服 | 2500.0000 |
| 办公用品 | 300.0000 |
| 厨房用具 | 279500.0000 |
+--------------+-----------------+
3 rows in set (0.00 sec)
-- 使用HAVING语句
-- 通过HAVING语句将销售平均价格大于等于2500的组给保留了
SELECT product_type, AVG(sale_price)
FROM Product
GROUP BY product_type
HAVING AVG(sale_price) >= 2500;
-- 结果如下
+--------------+-----------------+
| product_type | AVG(sale_price) |
+--------------+-----------------+
| 衣服 | 2500.0000 |
| 厨房用具 | 279500.0000 |
+--------------+-----------------+
2 rows in set (0.00 sec)
可以看到使用HAVING语句后,输出的结果有所变化。大致流程如下:
首先, FROM语句会选中表Product;然后, GROUP BY语句会选中字段product_type进行分组;之后,通过 HAVING语句将销售平均价格大于等于2500的组保留下来;最后,通过 SELECT语句将保留下的组的产品类型和平均价格显示出来;
如果是对表的行进行条件指定,WHERE和HAVING都可以生效。
-- 下面两条语句执行结果一致
SELECT product_type, COUNT(*)
FROM Product
GROUP BY product_type
HAVING product_type = '衣服';
SELECT product_type, COUNT(*)
FROM Product
WHERE product_type = '衣服'
GROUP BY product_type;
-- 结果如下
+--------------+----------+
| product_type | COUNT(*) |
+--------------+----------+
| 衣服 | 2 |
+--------------+----------+
1 row in set (0.01 sec)
但是,一般而言如果是对表的行进行条件指定,最好还是使用WHERE语句,因为WHERE的执行速度更快。
6.5 对表的查询结果进行排序
如果希望对表的查询结果根据某指定的字段进行排序,可以使用ORDER BY语句。语法结构如下:
SELECT <列名1>, <列名2>, <列名3>, ……
FROM <表名>
ORDER BY <排序基准列1>, <排序基准列2>, ……
示例:
SELECT product_id, product_name, sale_price, purchase_price
FROM Product;
-- 结果如下
+------------+--------------+------------+----------------+
| product_id | product_name | sale_price | purchase_price |
+------------+--------------+------------+----------------+
| 0001 | T恤衫 | 1000 | 500 |
| 0002 | 打孔器 | 500 | 320 |
| 0003 | 运动T恤 | 4000 | 2800 |
| 0004 | 菜刀 | 300000 | 700 |
| 0005 | 高压锅 | 680000 | 1250 |
| 0006 | 叉子 | 50000 | NULL |
| 0007 | 擦菜板 | 88000 | 198 |
| 0008 | 圆珠笔 | 100 | NULL |
+------------+--------------+------------+----------------+
8 rows in set (0.01 sec)
-- 根据字段sale_price的值进行排序
SELECT product_id, product_name, sale_price, purchase_price
FROM Product
ORDER BY sale_price;
-- 结果如下
+------------+--------------+------------+----------------+
| product_id | product_name | sale_price | purchase_price |
+------------+--------------+------------+----------------+
| 0008 | 圆珠笔 | 100 | NULL |
| 0002 | 打孔器 | 500 | 320 |
| 0001 | T恤衫 | 1000 | 500 |
| 0003 | 运动T恤 | 4000 | 2800 |
| 0006 | 叉子 | 50000 | NULL |
| 0007 | 擦菜板 | 88000 | 198 |
| 0004 | 菜刀 | 300000 | 700 |
| 0005 | 高压锅 | 680000 | 1250 |
+------------+--------------+------------+----------------+
8 rows in set (0.00 sec)
可以看到ORDER BY默认是按照升序的方式进行排序的,正式的书写方式应该是在字段后加上关键字ASC,即ORDER BY sale_price ASC。
如果我们希望按照降序的方式,可以通过DESC关键词进行指定。
SELECT product_id, product_name, sale_price, purchase_price
FROM Product
ORDER BY sale_price DESC;
-- 结果如下
+------------+--------------+------------+----------------+
| product_id | product_name | sale_price | purchase_price |
+------------+--------------+------------+----------------+
| 0005 | 高压锅 | 680000 | 1250 |
| 0004 | 菜刀 | 300000 | 700 |
| 0007 | 擦菜板 | 88000 | 198 |
| 0006 | 叉子 | 50000 | NULL |
| 0003 | 运动T恤 | 4000 | 2800 |
| 0001 | T恤衫 | 1000 | 500 |
| 0002 | 打孔器 | 500 | 320 |
| 0008 | 圆珠笔 | 100 | NULL |
+------------+--------------+------------+----------------+
8 rows in set (0.00 sec)
前面展示了指定一个字段来对表进行排序,实际上我们可以指定多个字段来进行排序。
示例:
SELECT regist_date, product_id, sale_price, purchase_price
FROM Product
ORDER BY regist_date, product_id;
-- 结果如下
+-------------+------------+------------+----------------+
| regist_date | product_id | sale_price | purchase_price |
+-------------+------------+------------+----------------+
| 2009-10-10 | 0002 | 500 | 320 |
| 2009-10-10 | 0003 | 4000 | 2800 |
| 2009-10-10 | 0004 | 300000 | 700 |
| 2009-10-10 | 0005 | 680000 | 1250 |
| 2009-10-10 | 0006 | 50000 | NULL |
| 2009-10-10 | 0007 | 88000 | 198 |
| 2009-10-10 | 0008 | 100 | NULL |
| 2021-10-30 | 0001 | 1000 | 500 |
+-------------+------------+------------+----------------+
可以看到先按照regist_date的大小进行排序,在字段regist_date中具有相同的值的行,接着会按照product_id进行排序。
使用含有 NULL 的列作为排序键时,NULL 会在结果的开头或末尾汇总显示。
在ORDER BY子句中可以使用SELECT子句中定义的别名。
-- 将product_id命名为ID,然后按照ID进行排序
SELECT product_id as ID, product_name, sale_price, purchase_price
FROM Product
ORDER BY ID;
-- 结果如下
+------+--------------+------------+----------------+
| ID | product_name | sale_price | purchase_price |
+------+--------------+------------+----------------+
| 0001 | T恤衫 | 1000 | 500 |
| 0002 | 打孔器 | 500 | 320 |
| 0003 | 运动T恤 | 4000 | 2800 |
| 0004 | 菜刀 | 300000 | 700 |
| 0005 | 高压锅 | 680000 | 1250 |
| 0006 | 叉子 | 50000 | NULL |
| 0007 | 擦菜板 | 88000 | 198 |
| 0008 | 圆珠笔 | 100 | NULL |
+------+--------------+------------+----------------+
8 rows in set (0.00 sec)
为什么ORDER BY中可以使用SELECT定义的别名呢?
这是因为在MySQL中,ORDER BY的执行次序在SELECT之后。
七、数据的插入及更新
7.1 数据的插入
通过命令INSERT,可以向表中插入数据:
-- 往表中插入一行数据
INSERT INTO <表名> (字段1, 字段2, 字段3, ……) VALUES (值1, 值2, 值3, ……);
-- 往表中插入多行数据
INSERT INTO <表名> (字段1, 字段2, 字段3, ……) VALUES
(值1, 值2, 值3, ……),
(值1, 值2, 值3, ……),
...
;
示例:
创建表并插入数据
-- 创建表
CREATE TABLE ProductIns
(product_id CHAR(4) NOT NULL,
product_name VARCHAR(100) NOT NULL,
product_type VARCHAR(32) NOT NULL,
sale_price INTEGER DEFAULT 0, -- DEFAULT 0:表示将字段sale_price的默认值设为0
purchase_price INT ,
regist_date DATE ,
PRIMARY KEY (product_id));
-- 通过单行方式插入
INSERT INTO
ProductIns(product_id, product_name, product_type, sale_price, purchase_price, regist_date)
VALUES ('0001', '打孔器', '办公用品', 500, 320, '2009-09-11');
-- 当对表插入全字段时,可以省略表后的字段清单
INSERT INTO ProductIns VALUES('0002', '高压锅', '厨房用具', 6800, 5000, '2009-01-15');
-- 通过多行方式插入
INSERT INTO ProductIns VALUES
('0003', '菜刀', '厨房用具', 3000, 2800, '2009-09-20'),
('0004', '订书机', '办公用品', 100, 50, '2009-09-11'),
('0005', '裙子', '衣服', 4100, 3200, '2009-01-23'),
('0006', '运动T恤', '衣服', 4000, 2800, NULL),
('0007', '牙刷', '日用品', 20, 10, '2010-03-22');
SELECT * FROM ProductIns;
-- 结果如下
+------------+--------------+--------------+------------+----------------+-------------+
| product_id | product_name | product_type | sale_price | purchase_price | regist_date |
+------------+--------------+--------------+------------+----------------+-------------+
| 0001 | 打孔器 | 办公用品 | 500 | 320 | 2009-09-11 |
| 0002 | 高压锅 | 厨房用具 | 6800 | 5000 | 2009-01-15 |
| 0003 | 菜刀 | 厨房用具 | 3000 | 2800 | 2009-09-20 |
| 0004 | 订书机 | 办公用品 | 100 | 50 | 2009-09-11 |
| 0005 | 裙子 | 衣服 | 4100 | 3200 | 2009-01-23 |
| 0006 | 运动T恤 | 衣服 | 4000 | 2800 | NULL |
| 0007 | 牙刷 | 日用品 | 20 | 10 | 2010-03-22 |
+------------+--------------+--------------+------------+----------------+-------------+
7 rows in set (0.00 sec)
插入NULL
INSERT语句中想给某一列赋予NULL值时,可以直接在VALUES子句的值清单中写入NULL。
INSERT INTO ProductIns VALUES ('0008', '叉子', '厨房用具', 500, NULL, '2009-09-20');
插入默认值
在前面我们创建表时,字段sale_price包含了一条约束条件,默认为0。我们在插入数据时,可以直接用
DEFAULT对该字段赋值。前提是,该字段被指定了默认值。
-- 通过显式方法设定默认值
INSERT INTO
ProductIns (product_id, product_name, product_type, sale_price, purchase_price, regist_date)
VALUES ('0009', '擦菜板', '厨房用具', DEFAULT, 790, '2009-04-28');
-- 通过隐式方法插入默认值
INSERT INTO
ProductIns (product_id, product_name, product_type, purchase_price, regist_date)
VALUES ('0010', '擦菜板', '厨房用具', 790, '2009-04-28');
7.2 数据的删除
通过DROP TABLE或者DELETE语句,可以对表进行删除,但二者存在一定的区别。
DROP TABLE语句可以将表完全删除。DELETE语句会留下表结构,而删除表中的全部数据。
无论通过哪种方式删除,数据都是难以恢复的。
通过
DROP进行删除语法结构为:
DROP <表名>;
通过
DELETE进行删除语法结构如下,记得要加
FROM:
DELETE FROM <表名>;
同时,也可以通过WHERE语句来指定删除的条件:
DELETE FROM <表名>
WHERE <条件>;
需要注意的是,DELETE语句的删除对象并不是表或者列,而是记录(行)。
示例:
SELECT * FROM Product;
-- 结果如下
mysql> SELECT * FROM Product;
+------------+--------------+--------------+------------+----------------+-------------+
| product_id | product_name | product_type | sale_price | purchase_price | regist_date |
+------------+--------------+--------------+------------+----------------+-------------+
| 0001 | T恤衫 | 衣服 | 1000 | 500 | 2009-09-20 |
| 0002 | 打孔器 | 办公用品 | 500 | 320 | 2009-09-11 |
| 0003 | 运动T恤 | 衣服 | 4000 | 2800 | NULL |
| 0004 | 菜刀 | 厨房用具 | 3000 | 2800 | 2009-09-20 |
| 0005 | 高压锅 | 厨房用具 | 6800 | 5000 | 2009-01-15 |
| 0006 | 叉子 | 厨房用具 | 500 | NULL | 2009-09-20 |
| 0007 | 擦菜板 | 厨房用具 | 880 | 790 | 2008-04-28 |
| 0008 | 圆珠笔 | 办公用品 | 100 | NULL | 2009-11-11 |
+------------+--------------+--------------+------------+----------------+-------------+
8 rows in set (0.00 sec)
-- 删除销售价格大于等于4000的行
DELETE FROM Product
WHERE sale_price >= 4000;
-- 结果如下
mysql> SELECT * FROM Product;
+------------+--------------+--------------+------------+----------------+-------------+
| product_id | product_name | product_type | sale_price | purchase_price | regist_date |
+------------+--------------+--------------+------------+----------------+-------------+
| 0001 | T恤衫 | 衣服 | 1000 | 500 | 2009-09-20 |
| 0002 | 打孔器 | 办公用品 | 500 | 320 | 2009-09-11 |
| 0004 | 菜刀 | 厨房用具 | 3000 | 2800 | 2009-09-20 |
| 0006 | 叉子 | 厨房用具 | 500 | NULL | 2009-09-20 |
| 0007 | 擦菜板 | 厨房用具 | 880 | 790 | 2008-04-28 |
| 0008 | 圆珠笔 | 办公用品 | 100 | NULL | 2009-11-11 |
+------------+--------------+--------------+------------+----------------+-------------+
6 rows in set (0.00 sec)
通过
TRUNCATE进行删除在MySQL中,还存在一种删除表的方式,就是利用
TRUNCATE语句。它的功能和DROP类似,但是不能通过WHERE指定条件,优点是速度比DROP快得多。
TRUNCATE Product;
-- 结果如下
mysql> SELECT * FROM Product;
Empty set (0.00 sec)
mysql> DESC Product;
+----------------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------------+--------------+------+-----+---------+-------+
| product_id | char(4) | NO | PRI | NULL | |
| product_name | varchar(100) | NO | | NULL | |
| product_type | varchar(32) | NO | | NULL | |
| sale_price | int | YES | | NULL | |
| purchase_price | int | YES | | NULL | |
| regist_date | date | YES | | NULL | |
+----------------+--------------+------+-----+---------+-------+
6 rows in set (0.00 sec)
7.3 数据的更新
当我们使用INSERT语句插入错误的数据后,若我们不想删除后从新插入,那就要使用到UPDATE语句。
基本用法
UPDATE的语法结构如下:
UPDATE <表名>
SET <字段名> = <表达式>;
示例:
-- 由于前面演示删除语句时,表Product的内容已清空
-- 所以,这里从新进行数据插入
INSERT INTO Product VALUES
('0001', 'T恤衫', '衣服', 1000, 500, '2009-09-20'),
('0002', '打孔器', '办公用品', 500, 320, '2009-09-11'),
('0003', '运动T恤', '衣服', 4000, 2800, NULL),
('0004', '菜刀', '厨房用具', 3000, 2800, '2009-09-20'),
('0005', '高压锅', '厨房用具', 6800, 5000, '2009-01-15'),
('0006', '叉子', '厨房用具', 500, NULL, '2009-09-20'),
('0007', '擦菜板', '厨房用具', 880, 790, '2008-04-28'),
('0008', '圆珠笔', '办公用品', 100, NULL,'2009-11-11')
;
-- 修改表中所有行regist_date的值
UPDATE Product
SET regist_date = '2009-10-10';
-- 结果如下
mysql> SELECT * FROM Product;
+------------+--------------+--------------+------------+----------------+-------------+
| product_id | product_name | product_type | sale_price | purchase_price | regist_date |
+------------+--------------+--------------+------------+----------------+-------------+
| 0001 | T恤衫 | 衣服 | 1000 | 500 | 2009-10-10 |
| 0002 | 打孔器 | 办公用品 | 500 | 320 | 2009-10-10 |
| 0003 | 运动T恤 | 衣服 | 4000 | 2800 | 2009-10-10 |
| 0004 | 菜刀 | 厨房用具 | 3000 | 2800 | 2009-10-10 |
| 0005 | 高压锅 | 厨房用具 | 6800 | 5000 | 2009-10-10 |
| 0006 | 叉子 | 厨房用具 | 500 | NULL | 2009-10-10 |
| 0007 | 擦菜板 | 厨房用具 | 880 | 790 | 2009-10-10 |
| 0008 | 圆珠笔 | 办公用品 | 100 | NULL | 2009-10-10 |
+------------+--------------+--------------+------------+----------------+-------------+
8 rows in set (0.00 sec)
指定条件
UPDATE <表名>
SET <列名> = <表达式>
WHERE <条件>;
示例:
UPDATE Product
SET regist_date = '2021-10-30'
WHERE product_id = '0001';
注意,你也可是使用NULL对表进行更新,不过更新的字段必须满足没有主键和NOT NULL的约束条件。
多列更新
多列更新只需要用逗号(,)连接更改的字段即可。
UPDATE Product
SET
sale_price = sale_price * 10,
purchase_price = purchase_price / 2
WHERE product_type = '厨房用具';
八、Pymysql的使用
在正式介绍pymysql的用法之前,我们先思考一件事,我们希望借助pymysql完成什么事情?
之前,我们在命令行下,通过输入SQL语句来完成对数据库和表的增删改查。那么,我们也希望能够在Python下能够完成同样的操作,并且能够返回相应的反馈。具体任务包括:
登陆并连接到MySQL下的用户; 切换到相应的数据库下; 完成对表的增删改查;
接下来的内容将围绕这3部分来介绍。
8.1 安装pymysql
通过pip,我们可以完成对pymysql的安装:
python3 -m pip install PyMySQL
8.2 连接数据库
如果希望在Python中操作MySQL数据库,那么首先就要登陆到MySQL下的用户。
我们通过创建库pymysql下的类connect的一个实例来登陆到数据库。
示例:
import pymysql
# 这里登陆到我之前创建的admin账户
db = pymysql.connect(
host='localhost',
user='admin',
password='mysql123',
database='shop',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor
)
参数解释:
host:数据库服务器地址,默认localhost;user:所要登陆的用户名;password:用户的登录密码;database:所要连接的数据库库名;charset:使用的字符类型;cursorclass:定义游标使用的类型,通过指定游标使用的类型,在返回输出的结果时将按照指定的类型进行返回。例如,这里设置为字典游标。
8.3 创建游标
关于游标,可以理解为在命令行中的光标。在命令行中,我们是在光标处键入语句的。这里游标的起到类似作用。
# 创建游标
cursor = db.cursor()
实际上,除了在初始化connect的实例时指定游标类型,我们在初始化游标时也可以指定游标类型,默认为元组类型。
cursor = db.cursor(cursor=pymysql.cursors.DictCursor)
cursors共支持四类游标:
Cursor: 默认,元组类型;DictCursor: 字典类型;SSCursor: 无缓冲元组类型;SSDictCursor: 无缓冲字典类型;
8.4 类方法
初始化完类connect和cursor的实例后,我们先来了解一下这两个类下包含的部分方法。了解这些方法有利于我们后面在python下操作mysql:
pymysql.connect下的类方法:close():在完成操作后,需要断开与数据库之间的连接;commit():如果执行语句中发生了数据更改,需要提交更改到稳定的存储器;cursor(cursor=None):创建一个游标,前面我们在初始化connect类是指定了游标类型,通过cursor初始化游标时,也可以进行游标类型指定;rollback():事务回滚;pymysql.cursors下的类方法:mode=absolute:绝对位置移动,控制游标位置到上一次查询的第value条数据,最小值为0;mode=relative:相对位置移动,基于当前位置,跳过value条数据;close():结束时,关闭游标;execute():通过游标执行语句;executemany():通过游标执行多条语句;fetchone():获取单条数据;fetchmany(size=None):获取size条数据;fetchall():获取单条数据;scroll(value, mode):数据的查询操作都是基于游标,可以通过scroll控制游标的位置。
更详细的资料,可参考官方的API或者Github,见文末。
8.5 实战
示例1:
在这个示例中,我们将做两件事情:创建表和插入数据。
import pymysql
# 以admin身份连接到数据库shop
connection = pymysql.connect(
host='localhost',
user='admin',
password='mysql123',
database='shop',
charset='utf8mb4',
)
# 创建游标
cursor = connection.cursor(cursor=pymysql.cursors.DictCursor)
# 1. 创建了一个表
sql = """
CREATE TABLE Employee(
id INT PRIMARY KEY,
name CHAR(15) NOT NULL
)
"""
# 提交执行
cursor.execute(sql)
# 2. 往表中插入数据
sql = "INSERT INTO Employee (id, name) VALUES (%s, %s)"
values = [(1, 'XiaoBai'),
(2, 'XiaoHei'),
(3, 'XiaoHong'),
(4, 'XiaoMei'),
(5, 'XiaoLi')]
try:
# 通过executemany可以插入多条数据
cursor.executemany(sql, values)
# 提交事务
connection.commit()
except:
connection.rollback()
# 3. 关闭光标及连接
cursor.close()
connection.close()
示例2
在示例1的基础上,我们继续执行查询工作。
import pymysql
# 以admin身份连接到数据库shop
connection = pymysql.connect(
host='localhost',
user='admin',
password='mysql123',
database='shop',
charset='utf8mb4',
)
with connection:
# 创建游标
cursor = connection.cursor(cursor=pymysql.cursors.DictCursor)
# 1. 通过fetchone只查询一条
cursor.execute("SHOW CREATE TABLE Employee")
result = cursor.fetchone()
print(f'查询结果1: \n{result}')
# 2. 通过fetchmany查询size条
cursor.execute("DESC Employee")
result = cursor.fetchmany(size=2)
print(f'查询结果2: \n{result}')
# 3. 通过fetchall查询所有
cursor.execute("SELECT * FROM Employee")
result = cursor.fetchall()
print(f'查询结果3: \n{result}')
# 4. 通过scroll回滚到第0条进行查询
cursor.scroll(0, mode='absolute')
result = cursor.fetchone()
print(f'查询结果4: \n{result}')
# 5. 通过scroll跳过2条进行查询
cursor.scroll(2, mode='relative')
result = cursor.fetchone()
print(f'查询结果5: \n{result}')
cursor.close()
控制台打印结果如下:
查询结果1:
{'Table': 'Employee', 'Create Table': 'CREATE TABLE `Employee` (\n `id` int NOT NULL,\n `name` char(15) NOT NULL,\n PRIMARY KEY (`id`)\n) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci'}
查询结果2:
[{'Field': 'id', 'Type': 'int', 'Null': 'NO', 'Key': 'PRI', 'Default': None, 'Extra': ''}, {'Field': 'name', 'Type': 'char(15)', 'Null': 'NO', 'Key': '', 'Default': None, 'Extra': ''}]
查询结果3:
[{'id': 1, 'name': 'XiaoBai'}, {'id': 2, 'name': 'XiaoHei'}, {'id': 3, 'name': 'XiaoHong'}, {'id': 4, 'name': 'XiaoMei'}, {'id': 5, 'name': 'XiaoLi'}]
查询结果4:
{'id': 1, 'name': 'XiaoBai'}
查询结果5:
{'id': 4, 'name': 'XiaoMei'}
示例3:
该示例将演示SQL注入的问题。先建立一个表并插入数据:
import pymysql
# 以admin身份连接到数据库shop
connection = pymysql.connect(
host='localhost',
user='admin',
password='mysql123',
database='shop',
charset='utf8mb4',
)
# 创建游标
cursor = connection.cursor(cursor=pymysql.cursors.DictCursor)
sql = """
CREATE TABLE UserInfo(
id INT PRIMARY KEY,
name VARCHAR(15),
password CHAR(15) NOT NULL
)
"""
cursor.execute(sql)
sql = "INSERT INTO UserInfo (id, name, password) VALUES (%s, %s, %s)"
values = [(1, 'XiaoBai', '123'),
(2, 'XiaoHei', '234'),
(3, 'XiaoHong', '567'),
(4, 'XiaoMei', '321'),
(5, 'XiaoLi', '789')]
cursor.executemany(sql, values)
connection.commit()
再写一个程序,根据输入判定登陆是否成功:
import pymysql
# 以admin身份连接到数据库shop
connection = pymysql.connect(
host='localhost',
user='admin',
password='mysql123',
database='shop',
charset='utf8mb4',
)
# 创建游标
cursor = connection.cursor(cursor=pymysql.cursors.DictCursor)
while True:
user = input("输入用户:").strip()
password = input("输入密码:").strip()
sql = "select name, password from UserInfo where name='%s' and password='%s' " % (user, password)
cursor.execute(sql)
# 打印用户和密码
result=cursor.fetchone()
print(result)
if result:
print("成功登陆\n")
else:
print("登陆失败\n")
在控制台下,我们进行了三组用户和密码的验证:
输入用户:XiaoBai
输入密码:123
{'name': 'XiaoBai', 'password': '123'}
成功登陆
输入用户:XiaoBai
输入密码:321
None
登陆失败
输入用户:XiaoBai' -- dsd
输入密码:321
{'name': 'XiaoBai', 'password': '123'}
成功登陆
可以看出,第1组和第2组验证正常,但是第三组出现了异常,输入错误的密码却可以正确登陆。
这是因为在MySQL中--的含义是注释,如果通过字符串进行拼接:
select name, password from UserInfo where name='XiaoBai' -- dsd' and password='321'
实际等价于:
select name, password from UserInfo where name='XiaoBai'
这其实是一个MySQL注入问题,通过绕开用户密码进行登录查询。那么如何抵御SQL注入的问题?
解决办法:通过execute或者executemany来进行拼接。将语句:
sql = "select name, password from UserInfo where name='%s' and password='%s' " % (user, password)
cursor.execute(sql)
改为:
sql = "select name, password from UserInfo where name=%s and password=%s"
cursor.execute(sql, (user, password))
防止SQL注入,我们需要注意以下几个要点:
永远不要信任用户的输入。对用户的输入进行校验,可以通过正则表达式,或限制长度;对单引号和 双"-"进行转换等。 永远不要使用动态拼装SQL,可以使用参数化的SQL或者直接使用存储过程进行数据查询存取。 永远不要使用管理员权限的数据库连接,为每个应用使用单独的权限有限的数据库连接。 不要把机密信息直接存放,加密或者hash掉密码和敏感的信息。 应用的异常信息应该给出尽可能少的提示,最好使用自定义的错误信息对原始错误信息进行包装 SQL注入的检测方法一般采取辅助软件或网站平台来检测,软件一般采用SQL注入检测工具jsky,网站平台就有亿思网站安全平台检测工具。
参考资料
[日], MICK著.《SQL基础教程 第2版》,人民邮电出版社 菜鸟MySQL教程:https://www.runoob.com/mysql/mysql-tutorial.html 菜鸟SQL教程:https://www.runoob.com/sql/sql-tutorial.html 林海峰MySQL系列:https://www.cnblogs.com/linhaifeng/articles/7356064.html Ubuntu20.04下安装MySQL:https://devanswers.co/install-secure-mysql-server-ubuntu-20-04/ PyMySQL Github:https://github.com/PyMySQL/PyMySQL PyMySQL Document:https://pymysql.readthedocs.io/en/latest/modules/index.html#
我们的文章到此就结束啦~记得点赞
如何找到我: