
机 器 学 习 中 的 数 学 意 义
↑↑↑点击上方蓝字,回复资料,10个G的惊喜
英语原文:
Digit Significance in Machine Learning
翻译:雷锋字幕组(听风1996) 编辑:AI研习社
机器学习中的用于声称性能的指标标准很少被讨论。由于在这个问题上似乎没有一个明确的、广泛的共识,因此我认为提供我一直在倡导并尽可能遵循的标准可能会很有趣。它源于这个简单的前提,这是我的科学老师从中学开始就灌输给我的:
科学报告的一般规则是,您写下的每个数字都应为“ 真”的,因为“ 真”的定义是什么。
让我们来研究一下这对测试性能等统计量意味着什么。当你在科学出版物中写下以下陈述时:
测试准确率为52.34%。你所表达的是,据你所知,你的模型在从测试分布中提取的未见数据上成功的概率在0.52335和0.52345之间。
这是一个非常强有力的声明。
考虑你的测试集是从正确的测试分布中抽取的N个样本IID组成的。成功率可以表示为一个二项式变量,其平均概率p由样本平均值估计:p ≅ s / N
其标准差为:σ=√p(1-p)。
其中当p=0.5时,其上限为0.5。
在正态近似下,估计量的标准差为:δ=σ/√N。
这个精度估计上的误差δ 是这样的,在最坏的情况下,有约50%的精度:
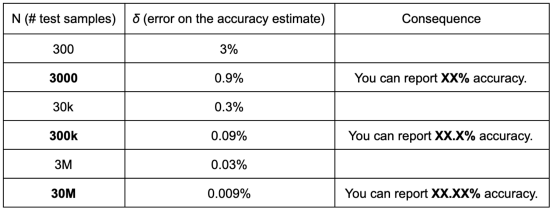
换句话说,为了保证上述报告中例子52.34%的准确率,你的测试集的大小至少应该在30M样本的数量级上!这种粗略的分析很容易转化为除了准确率以外的任何可计算的数量,尽管不能转化为像似然率或困惑度这样的连续数字。
下面是一些常见的机器学习数据集的说明。
在ImageNet上可以合理地报告多少位数的精度?准确率在80%左右,测试集是15万张图片:
√(0.8*0.2/150000) = 0.103%
这意味着你几乎可以报告XX.X%的数字,而实际上每个人都是这样做的。
MNIST呢,准确率在99%:
√(0.99*0.01/10000) = 0.099%
噗,也报个XX.X%就OK了!
然而,最值得注意的是,在大多数情况下,性能数据并不是单独呈现的,而是用来比较同一测试集上的多种方法。在这种情况下,实验之间的抽样方差会被抵消,即使在样本量较小的情况下,它们之间的准确度差异也可能在统计学上很显著。估计图方差的一个简单方法是执行bootstrap重采样。更严格、通常更严格的检验包括进行配对差异检验或更普遍的方差分析。
报告超出其内在精度的数字可能很具有极大的吸引力,因为在与基线进行比较的情况下,或者当人们认为测试集是一成不变的情况下,同时也不是从测试分布中抽取的样本时,性能数字往往更加重要。当在生产中部署模型时,这种做法会让人感到惊讶,并且固定的测试集假设突然消失了,还有一些无关紧要的改进。更普遍的是,这种做法会直接导致对测试集进行过拟合。
那么,在我们的领域中数字为“真”意味着什么?好吧,这确实很复杂。对于工程师而言,很容易辩称不应该报告的尺寸超出公差。或者对于物理学家来说,物理量不应超过测量误差。对于机器学习从业者,我们不仅要应对测试集的采样不确定性,而且还要应对独立训练运行,训练数据的不同初始化和改组下的模型不确定性。
按照这个标准,在机器学习中很难确定哪些数字是 "真 "的。解决办法当然是尽可能地报告其置信区间。置信区间是一种更精细的报告不确定性的方式,可以考虑到所有随机性的来源,以及除简单方差之外的显着性检验。它们的存在也向你的读者发出信号,表明你已经考虑过你所报告的内容的意义,而不仅仅是你的代码所得到的数字。用置信区间表示的数字可能会被报告得超出其名义上的精度,不过要注意的是,你现在必须考虑用多少位数来报告不确定性,正如这篇博文所解释的那样。一路走来都是乌龟。
数字少了,杂乱无章的东西就少了,科学性就强了。
避免报告超出统计学意义的数字结果,除非你为它们提供一个明确的置信区间。这理所当然地被认为是科学上的不良行为,尤其是在没有进行配对显著性测试的情况下,用来论证一个数字比另一个数字好的时候。仅凭这一点就经常有论文被拒绝。一个良好的习惯是对报告中带有大量数字的准确率数字始终持怀疑态度。还记得3000万、30万和30万的经验法则对最坏情况下作为“嗅觉测试”的统计显著性所需样本数量的限制吗?它会让你避免追逐统计上的“幽灵”。
↓↓↓我的朋友圈更精彩↓
推荐阅读
(点击标题可跳转阅读)
老铁,三连支持一下,好吗?↓↓↓
推荐阅读
(点击标题可跳转阅读)
老铁,三连支持一下,好吗?↓↓↓