
这三个NLP项目写进简历,网申通过率提高50%


01
三大企业级项目
项目一
京东智能对话系统项目
项目简介:智能客服机器人已经成为了客服系统的重要组成部分,帮助人工客服提升工作效率,为企业降低人工成本。作为智能客服的行业先驱,京东多年来致力打造全链路的客服机器人,最大化提升商家的接待效率和用户体验。目前智能机器人的对话生成策略已经在“京小智”、“京东JIMI“等智能客服机器广泛应用,在用户购买商品的售前以及售后环节,为数千万用户以及数十万商家进行服务,为商家降本增效,为用户提升购物客服体验。
项目二
京东智能营销文本生成项目
项目三
京东同类商品竞价搜索项目
对课程有意向的同学
可扫描二维码咨询
👇👇👇
课程覆盖了从经典的机器学习、文本处理技术、序列模型、深度学习、预训练模型、知识图谱、图神经网络所有必要的技术,30+项目案例帮助你在实战中学习成长。5个月时间博导级大咖全程辅导答疑、帮你告别疑难困惑。
▶第二部分:文本处理篇
第5章:分词、词的标准化、过滤 文本分析流程 中英文的分词 最大匹配算法 基于语言模型的分词 Stemming和Lemmazation 停用词的使用 拼写纠错问题 编辑距离的实现 暴力搜索法 基于后验概率的纠错 | 第6章:文本的表示 单词的独热编码表示 句子的独热编码表示 tf-idf表示 句子相似度比较 独热编码下的单词语义相似度 从独热编码到词向量 词向量的可视化、句子向量 |
第7章:【项目作业】豆瓣电影评分预测 数据描述以及任务 中文分词 独热编码、tf-idf 分布式表示与Word2Vec BERT向量 句子向量 | 第8章:词向量技术 独热编码表示的优缺点 独热编码与分布式表示的比较 静态词向量与动态词向量 学习词向量 - 分布式假设 SkipGram与CBOW SkipGram模型的目标 负采样(Negative Sampling) 基于矩阵分解的词向量学习 基于Glove的词向量学习 在非欧式空间中的词向量学习 |
第9章:【项目作业】智能客服问答系统 问答系统和应用场景 问答系统搭建流程 文本的向量化表示 FastText 倒排表技术 问答系统中的召回、排序 | 第10章:语言模型 语言模型的必要性 马尔科夫假设 Unigram语言模型 Bigram、Trigram语言模型 语言模型的评估 语言模型的平滑技术 |
▶第三部分:自然语言处理与深度学习
第11章:深度学习基础 理解神经网络 各类常见的激活函数 理解多层神经网络 反向传播算法 神经网络中的过拟合 浅层模型与深层模型对比 深度学习中的层次表示 | 第12章:Pytorch的使用 环境安装 Pytorch与Numpy的语法比较 Pytorch中的Autograd用法 Pytorch的Forward函数 |
第13章:RNN与LSTM 从HMM到RNN模型 RNN中的梯度问题 解决梯度爆炸问题 梯度消失与LSTM LSTM到GRU 双向LSTM模型 基于LSTM的生成 练习:利用Pytorch实现RNN/LSTM | 第14章:Seq2Seq模型与注意力机制 Seq2Seq模型 Greedy Decoding Beam Search 长依赖所存在的问题 注意力机制 注意力机制的不同实现 |
第15章:【项目实战】京东智能营销文案生成 构建Seq2Seq模型 Beam Search的改造 模型调优 Length Normalization Coverage Normalization 评估标准 Rouge Pointer-Generator Network PGN与Seq2Seq的融合 | 第16章:动态词向量与ELMo技术 基于上下文的词向量技术 图像识别中的层次表示 文本领域中的层次表示 深度BI-LSTM ELMo模型简介及优缺点 ELMo的训练与测试 |
第17章:自注意力机制与Transformer 基于LSTM模型的缺点 Transformer结构概览 理解自注意力机制 位置信息的编码 理解Encoder与Decoder区别 理解Transformer的训练和预测 Transformer的缺点 | 第18章:BERT与ALBERT 自编码器介绍 Transformer Encoder Masked LM BERT模型及其不同训练方式 ALBERT |
第19章:【项目实战】京东智能客服系统项目 对话系统的分类方法 检索方式与生成方式 对话系统架构 意图识别分类器 闲聊引擎的搭建 Transformer与BERT的使用 | 第20章:GPT与XLNet Transformer Encoder回顾 GPT-1,GPT-2,GPT-3 ELMo的缺点 语言模型下同时考虑上下文 Permutation LM 双流自注意力机制 Transformer-XL |
▶第四部分、信息抽取
第21章:命名实体识别与实体消歧 信息抽取的应用和关键技术 命名实体识别 NER识别常用技术 实体消歧技术 实体消歧常用技术 实体统一技术 指代消解 | 第22章:关系抽取 关系抽取的应用 基于规则的方法 基于监督学习方法 Bootstrap方法 Distant Supervision方法 |
第23章:依存文法分析 从语法分析到依存文法分析 依存文法分析的应用 使用依存文法分析 基于图算法的依存文法分析 基于Transtion-based的依存文法分析 其他依存文法分析方法论 | 第24章:知识图谱 知识图谱以及重要性 知识图谱中的实体和关系 利用非结构化数据构造知识图谱 知识图谱的设计 |
第25章:【项目实战】京东同类商品竞价搜索项目 Entity Linking介绍 Entity Linking技术概览 从商品描述、商品标题中抽取关键实体 搭建商品知识图谱 基于GNN学习商品的词嵌入 商品的ranking以及相似度计算 |
▶第五部分:图神经网络以及其他前沿主题
第26章:模型的压缩 模型压缩的必要性 常见的模型压缩算法总览 基于矩阵分解的压缩技术 从BERT到ALBERT的压缩 基于贝叶斯模型的压缩技术 模型的量化 模型的蒸馏方法 | 第27章:图神经网络 卷积神经网络的回顾 图神经网络发展历程 图卷积神经网络(GCN) GAT详解 |
对课程有意向的同学
可扫描二维码咨询
👇👇👇
03
教学体系
▶01 项目讲解&实战帮助
▲节选往期部分课程安排
▶02最佳工业实战
▲源自京东智联云AI某模块架构图
▶03专业的论文解读

▲节选往期部分论文安排
▶04代码解读&实战

▲BERT模型代码实战讲解
▶05行业案例分享

▲专家分享
▶06日常社群答疑
▲社群内老师专业的解答
▶07日常作业&讲解

▲课程学习中的小作业
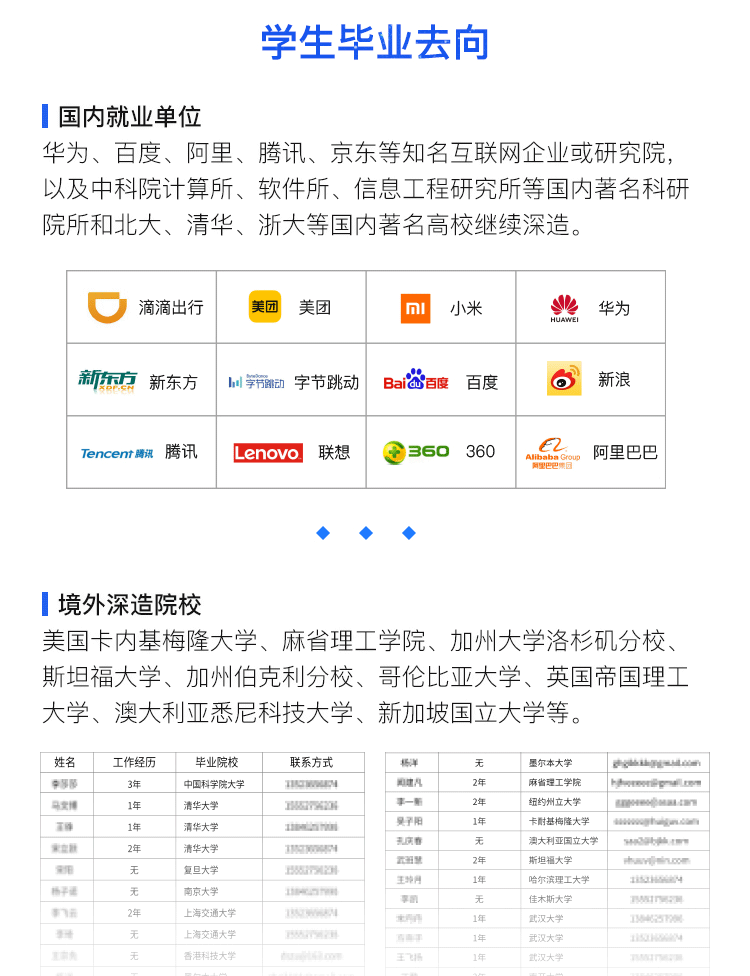
▶08学员毕业去向
04
课程适合哪些学员呐?
大学生:
计算机或者信息领域相关的本科/研究/博士生,毕业后希望从事AI相关的工作;
希望在真实工业场景中磨炼技术,提升职场竞争力;
毕业之后希望申请国内外名校的硕士或者博士。
在职人士:
具备良好的工程研发背景,希望从事AI相关的项目或者工作;
从事AI工作,希望进一步提升NLP实战经验;
从事NLP工作,希望深入了解模型机理;
AI developer, 希望突破技术瓶颈, 了解NLP前沿信息。
入学标准
1.理工科专业相关本科生,硕士生或博士生或者IT领域的在职人士;
2.具备很强的动手能力、熟练使用Python编程;
3.具备良好的英文文献阅读能力,至少达到CET-4级水平。
对课程有意向的同学
可扫描二维码咨询
👇👇👇