
详细解读Google新作 | 教你How to train自己的Transfomer模型?
↑ 点击蓝字 关注极市平台

作者丨ChaucerG
来源丨集智书童
编辑丨极市平台
极市导读
本文第一次系统的、大规模的研究在训练Vision Transformer之前,正则化、数据增强、模型大小和训练数据大小之间的相互作用,包括它们各自对达到一定性能水平所需的计算预算的影响。>>加入极市CV技术交流群,走在计算机视觉的最前沿

1 简介
Vision Transformers(Vision transformer, ViT)在图像分类、目标检测和语义分割等视觉应用中得到了具有竞争力得性能。
与卷积神经网络相比,当在较小的训练数据集上训练时,通常发现Vision Transformer较弱的归纳偏差导致对模型正则化或数据增强(简称AugReg)的依赖增加。为了更好地理解训练数据量、AugReg、模型大小和计算预算之间的相互作用,作者进行了系统的实验研究。
研究的一个结果是,作者发现增加的计算和AugReg相结合,可以产生与在更多训练数据上训练的模型具有相同性能的模型:在ImageNet-21k数据集上训练各种大小的ViT模型,这些模型与在更大的JFT-300M数据集上训练的模型比较甚至可以得到更好得结果。
2 论文作者主要说了什么?
第一次系统的、大规模的研究在训练Vision Transformer之前,正则化、数据增强、模型大小和训练数据大小之间的相互作用,包括它们各自对达到一定性能水平所需的计算预算的影响。
通过迁移学习的视角来评估预训练模型。因此,作者描述了一个相当复杂的训练设置训练前的Vision Transformer跨越不同的模型尺寸。实验得出了许多关于各种技术的影响的令人惊讶的见解,以及什么时候增强和正则化是有益的,什么时候无益的情况。
作者还对Vision Transformer的迁移学习配置进行了深入分析。结论是在广泛的数据集中,即使下游数据似乎与用于前训练的数据只有微弱的关联,迁移学习仍然是最佳的可用选择。作者分析还表明,在执行类似的预训练模型中,对于迁移学习来说,具有更多训练数据的模型可能比具有更多数据增强的模型更受青睐。
本文研究将有助于指导未来的Vision Transformer的研究,并将成为一个有效的训练设置的有用来源,以寻求在给定的计算预算下优化他们的最终模型性能。
3 Findings
3.1 Scaling datasets with AugReg and compute
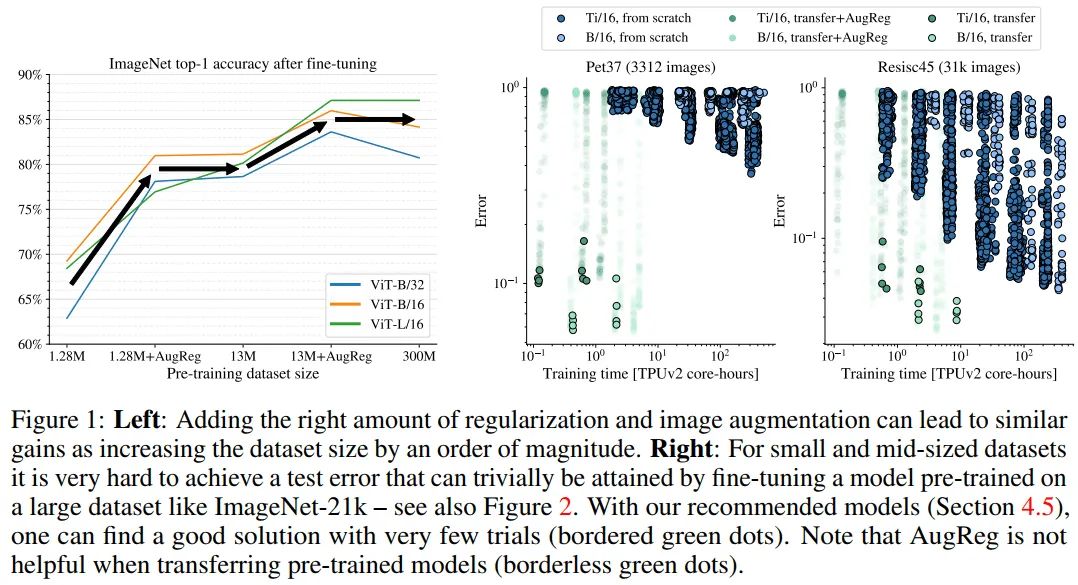
研究的一个主要发现(如图1(左)所示)是,通过使用图像增强和模型正则化预训练一个模型,使其达到与增加数据集大小约一个数量级相同的精度。更准确地说,在AugReg ImageNet-1k上训练的最佳模型的性能与在10倍大的普通ImageNet-21k数据集上训练的相同模型的性能差不多。
类似地,在AugReg ImageNet-21k上训练的最佳模型,当计算量也增加时,将匹配或优于在普通JFT-300M数据集上训练的模型。因此,可以将这些结果与公开可用的数据集进行匹配,可以想象,在JFT-300M上进行更长时间的训练和使用AugReg可能会进一步提高性能。
当然,这些结果不能适用于任意小的数据集。只对ImageNet-1k的10%进行大量数据增强的ResNet50训练可以改善结果,但不能恢复对完整数据集的训练。
3.2 Transfer is the better option
在这里,作者调查了对于从业者可能遇到的合理规模的数据集,是否建议尝试使用AugReg从头开始进行训练,或者是否把时间和金钱花在迁移预训练模型上更好。其结果是,就大多数实际目的而言,迁移预先训练的模型不仅成本效益更高,而且会带来更好的结果。
作者在一个与ImageNet-1k数据集相似大小的数据集上对小的ViT-Ti/16模型进行了搜索,寻找一个好的训练策略。Resisc45包含大约3万幅训练图像,由一种非常不同的卫星图像组成,ImageNet-1k或ImageNet-21k都没有很好地覆盖这些图像。图1(右)和图2显示了这一广泛搜索的结果。
最惊人的发现是,无论花费多少训练时间,对于微小的Pet37数据集,似乎不可能从头开始训练ViT模型,使其达到接近迁移模型的精度。此外,由于预训练模型可以免费获取,所以从业者的预训练成本实际上为零,只有用于迁移学习的计算损失,因此迁移预训练的模型同时也大大便宜。
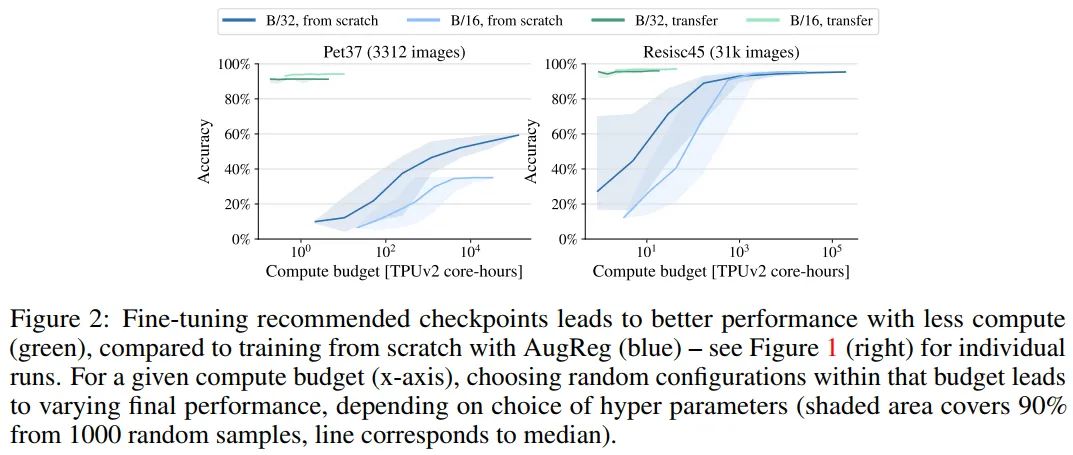
对于更大的Resisc45数据集,这个结果仍然成立,尽管多花费2个数量级的计算和执行大量搜索可能接近(但达不到)预先训练的模型的精度。
值得注意的是,这并没有考虑到很难量化的“exploration cost”。对于训练前的模型,我们强调那些在训练前验证集上表现最好的模型,可以称为推荐模型。可以看到,使用推荐的模型有很高的可能性在几次尝试中就能获得良好的结果。
3.3 More data yields more generic models
通过将预训练模型迁移到下游任务来研究预训练数据集大小的影响。作者在VTAB上评估了训练前的模型,包括19个不同的任务。
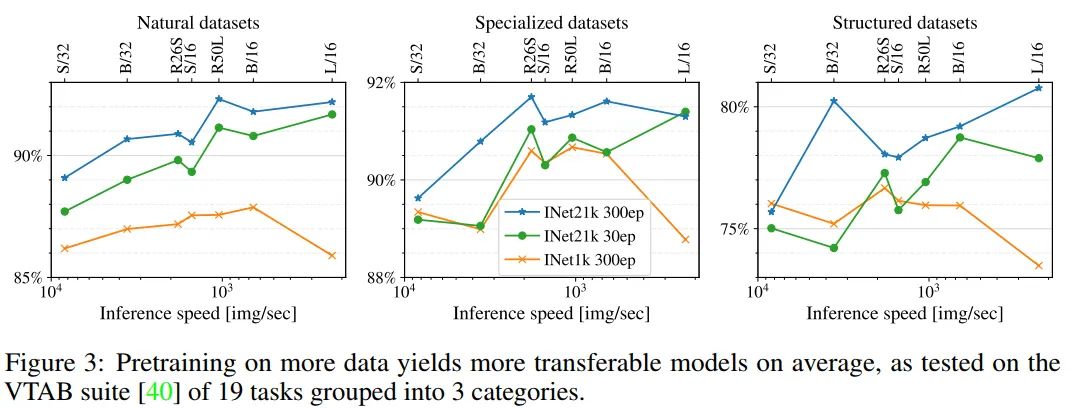
图3显示了3个VTAB类别的结果:natural、specialized和structured。模型按推理时间进行排序,模型越大推理速度越慢。
首先比较使用相同计算预算的2个模型,唯一的区别是ImageNet-1k(1.3M图像)和ImageNet-21k (13M图像)的数据集大小。作者实验对比ImageNet-1k训练300个epoch的模型和ImageNet-21k上训练30个epoch模型发现,在ImageNet-21k上进行预训练的模型3个VTAB类别上都明显优于ImageNet-1k。
随着计算预算的不断增长,作者观察到ImageNet-21k数据集在10倍长的调度上的一致改进。在一些几乎已经解决的任务中,例如花,获得的绝对数量很小。对于剩下的任务,与短期训练的模型相比,改进是显著的。
总的来说得出的结论是,数据越多,模型就越通用,这一趋势适用于不同的任务。作者建议设计选择使用更多的数据和一个固定的计算预算。
3.4 Prefer augmentation to regularization
目前尚不清楚在RandAugment和Mixup等数据增强和Dropout和randomdepth等模型正则化之间有哪些取舍。在本节的目标是发现这些通用模式,当将Vision transformer应用到一个新任务时,可以作为经验规则使用。
在图4中,作者展示了为每个单独设置获得的上游验证得分,即在更改数据集时,数字是不具有可比性的。
一个单元格的颜色编码其分数的改善或变差,与非正则化的,未增强的设置,即最左边的列。增强强度从左到右依次增大,模型容量从上到下依次增大。
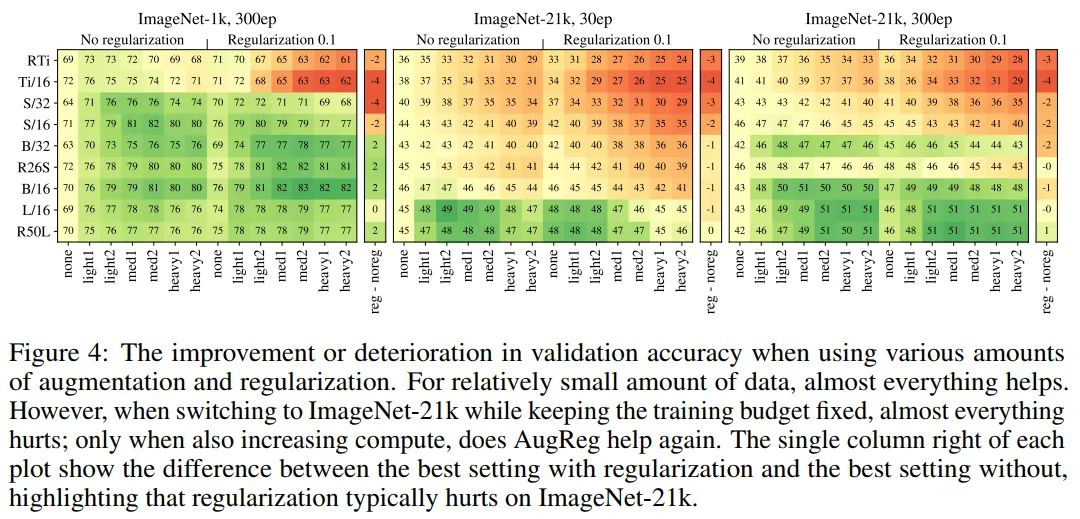
第1个可见的观察结果是,对于中等规模的ImageNet-1k数据集,任何类型的AugReg都有帮助。然而,当使用10倍大的ImageNet-21k数据集并保持计算固定时,即运行30个epoch,任何一种AugReg都会影响除最大模型之外的所有模型的性能。只有当计算预算增加到300个时,AugReg才帮助更多的模型,尽管即使那样,它也继续影响较小的模型。
一般来说,增加增广效果比增加正规化效果好得多。更具体地说,图4中每个映射右侧的细列显示,对于任何给定的模型,其最佳正则化分数减去最佳非正则化分数。
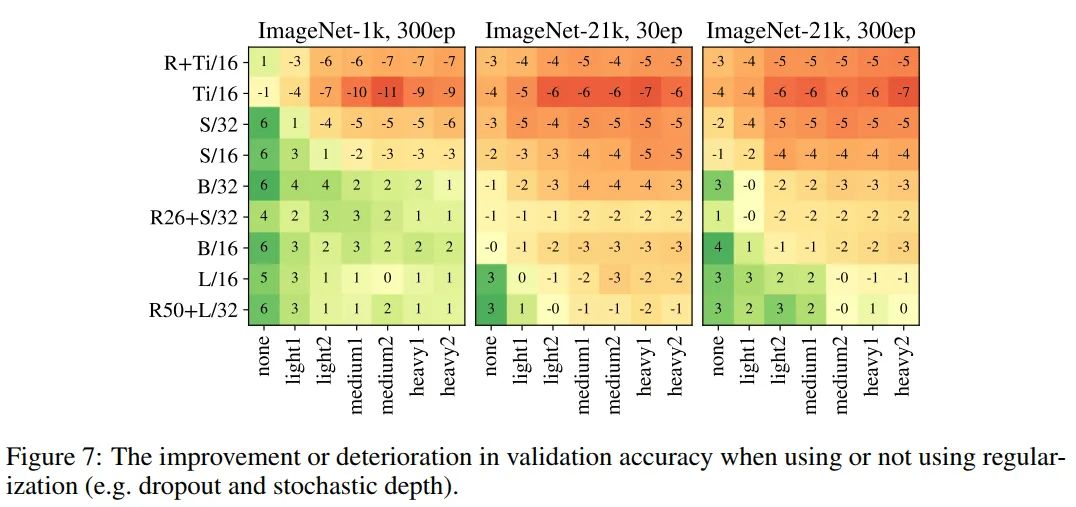
在图7中,作者通过dropout和random depth的方式向模型添加正则化时,显示了精度上的增益(绿色,正数)或损失(红色,负数)。在早期的实验中证实,两者结合(峰值)下降概率0.1确实是最好的设置。
这表明,模型正规化主要帮助较大的模型,但是当训练时间较长的情况下,特别是ImageNet-21的预训练,除了最大的模型它对所有的模型都有害的。
3.5 Choosing which pre-trained model to transfer
如上所述,在对ViT模型进行预训练时,各种正则化和数据增强设置会导致模型具有显著不同的性能。
然后,从实践者的观点来看,一个自然的问题出现了:如何选择一个模型进一步适应最终的应用程序?
一种方法是:对所有可用的预训练模型进行下游适应,然后根据下游任务的验证分数选择表现最好的模型。但是这在实践中可能是相当麻烦的。
另一种方法是:可以根据上游验证精度选择一个单独的预训练模型,然后只使用该模型进行自适应,这要简单得多。
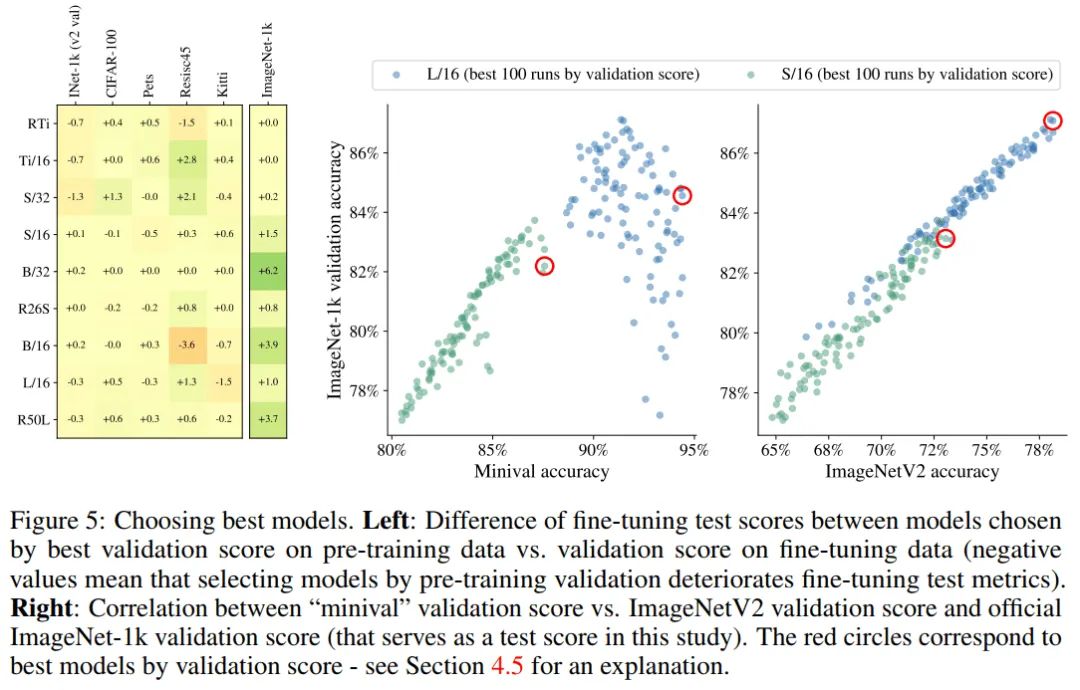
在这里作者将分析这2种策略之间的权衡。在5个不同的数据集上对它们进行了大量的预训练模型的比较。具体来说,在图5(左)中强调了只适应最好的预训练模型的简单策略和适应所有预训练模型(然后选择最好的)的复杂策略之间的性能差异。
结果好坏参半,但总体上反映出,在大多数情况下,成本较低的策略与成本较高的策略效果相同。然而,有一些显著的异常值,当它有利于适应所有的模型。
因此,作者得出结论,选择一个基于上游分数的单一预训练模型是一种具有成本效益的实用策略,并在整个论文中使用它。然而,作者也强调,如果有额外的计算资源可用,那么在某些情况下,可以通过微调额外的预训练模型来进一步提高自适应性能。
关于ImageNet-1k数据集验证数据的说明
在执行上述分析时,作者发现在ImageNet-21k上预先训练并迁移到ImageNet-1k数据集的模型存在一个微小但严重的问题。这些模型(特别是大型模型)的验证分数与观察到的测试性能没有很好的关联,见图5(左)。这是因为ImageNet-21k数据包含ImageNet-1k训练数据,作者使用训练数据的一个小split来进行评估(见3.1节)。
因此,在较长训练计划上的大型模型记忆了来训练集的数据,这使得在小评估集中计算的评估指标存在偏差。为了解决这个问题并支持公平的超参数选择,作者使用独立收集的ImageNetV2数据作为传输到ImageNet-1k的验证split。如图5(右)所示。作者没有在其他数据集中观察到类似的问题。
作者建议将ImageNet-21k模型迁移到ImageNet-1k的研究人员遵循这一策略。
3.6 Prefer increasing patch-size to shrinking model-size
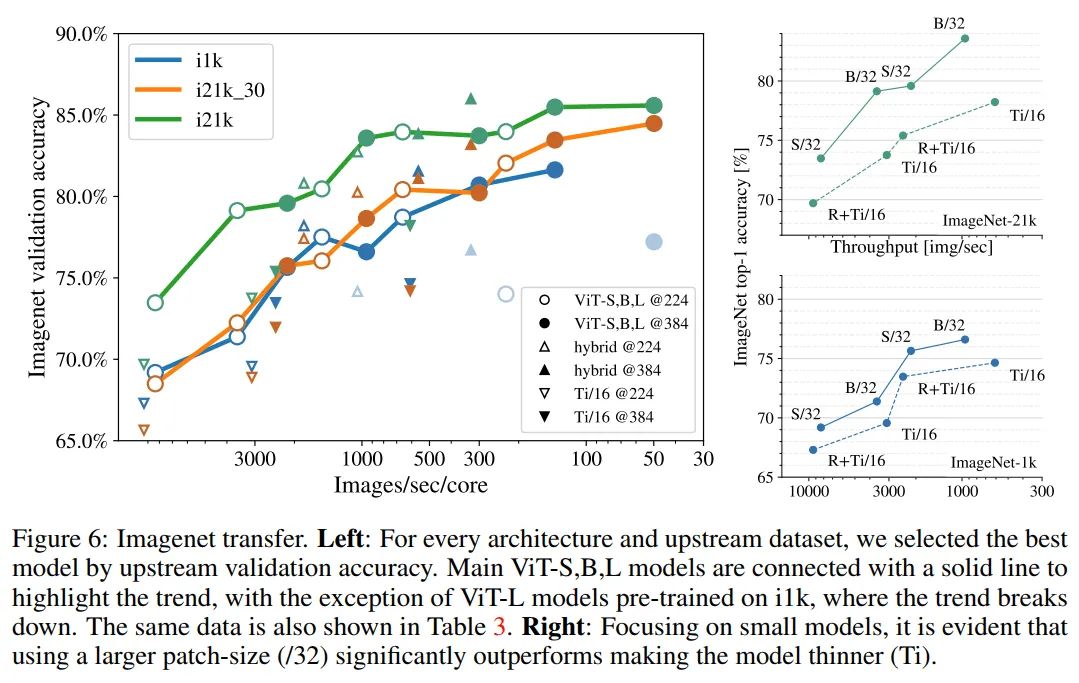
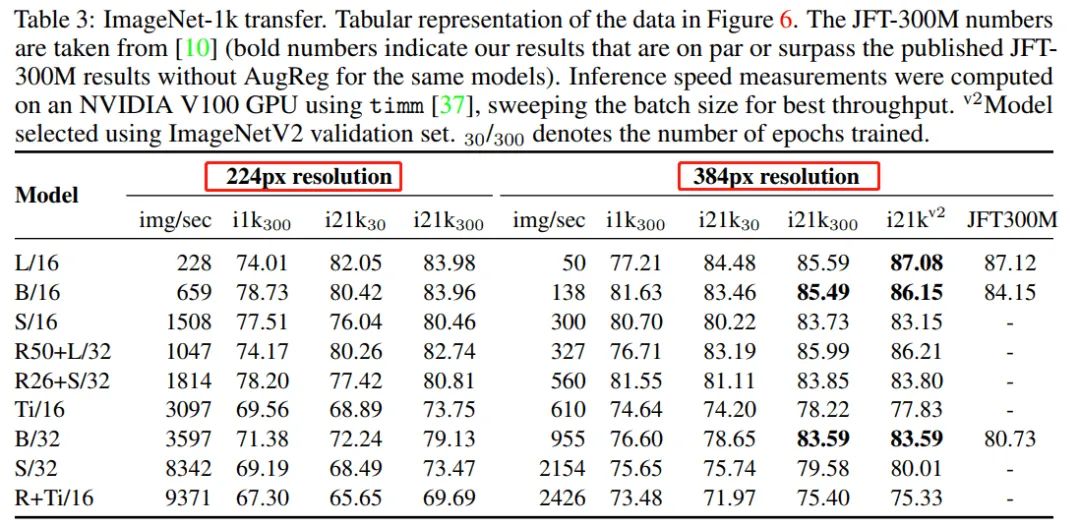
作者研究的一个意想不到的结果是,训练了几个模型,它们在推理吞吐量方面大致相等,但在质量方面差异很大。
具体地说,图6(右)显示了包含Tiny变体的模型比具有32-patch-size的类似快速的更大模型的性能要差得多。对于给定的分辨率,patch-size会影响self-attention执行的token数量,因此会影响模型容量,而参数计数并不能反映模型容量。参数计数既不反映速度,也不反映容量。
参考
[1].How to train your ViT? Data, Augmentation,and Regularization in Vision Transformers
本文亮点总结
1.研究的一个主要发现(如图1(左)所示)是,通过使用图像增强和模型正则化预训练一个模型,使其达到与增加数据集大小约一个数量级相同的精度。更准确地说,在AugReg ImageNet-1k上训练的最佳模型的性能与在10倍大的普通ImageNet-21k数据集上训练的相同模型的性能差不多。
2.选择一个基于上游分数的单一预训练模型是一种具有成本效益的实用策略,并在整个论文中使用它。然而,作者也强调,如果有额外的计算资源可用,那么在某些情况下,可以通过微调额外的预训练模型来进一步提高自适应性能。
如果觉得有用,就请分享到朋友圈吧!
△点击卡片关注极市平台,获取最新CV干货
公众号后台回复“目标检测竞赛”获取目标检测竞赛经验资源~
极市干货
YOLO教程:一文读懂YOLO V5 与 YOLO V4|大盘点|YOLO 系目标检测算法总览|全面解析YOLO V4网络结构
实操教程:PyTorch vs LibTorch:网络推理速度谁更快?|只用两行代码,我让Transformer推理加速了50倍|PyTorch AutoGrad C++层实现
算法技巧(trick):深度学习训练tricks总结(有实验支撑)|深度强化学习调参Tricks合集|长尾识别中的Tricks汇总(AAAI2021)
最新CV竞赛:2021 高通人工智能应用创新大赛|CVPR 2021 | Short-video Face Parsing Challenge|3D人体目标检测与行为分析竞赛开赛,奖池7万+,数据集达16671张!

# CV技术社群邀请函 #
△长按添加极市小助手
添加极市小助手微信(ID : cvmart2)
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
觉得有用麻烦给个在看啦~
