
8000字,详解数据建模的方法、模型、规范和工具!

OLAP中的ER模型,与OLTP中的有所区别。其本质差异是站在企业角度面向主题的抽象,而不是针对某个具体业务流程的实体对象关系的抽象。
多维模型,是维度模型的另一种实现。当数据被加载到OLAP多维数据库时,对这些数据的存储的索引,采用了为维度数据涉及的格式和技术。性能聚集或预计算汇总表通常由多维数据库引擎建立并管理。由于采用预计算、索引策略和其他优化方法,多维数据库可实现高性能查询。
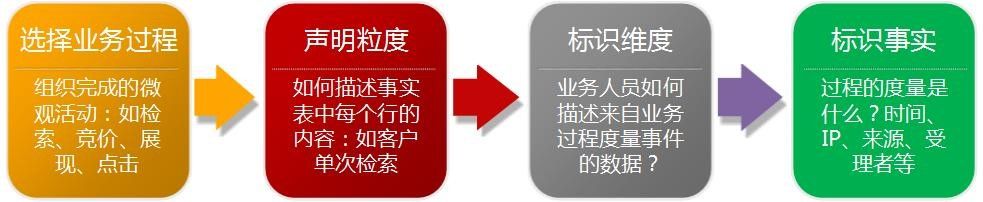
【粒度】:每笔订单(拆分为单个物品)
【维度】:地域、年龄、渠道等(可供分析的角度)
【事实/度量】:订单金额等(可用于分析的数据)
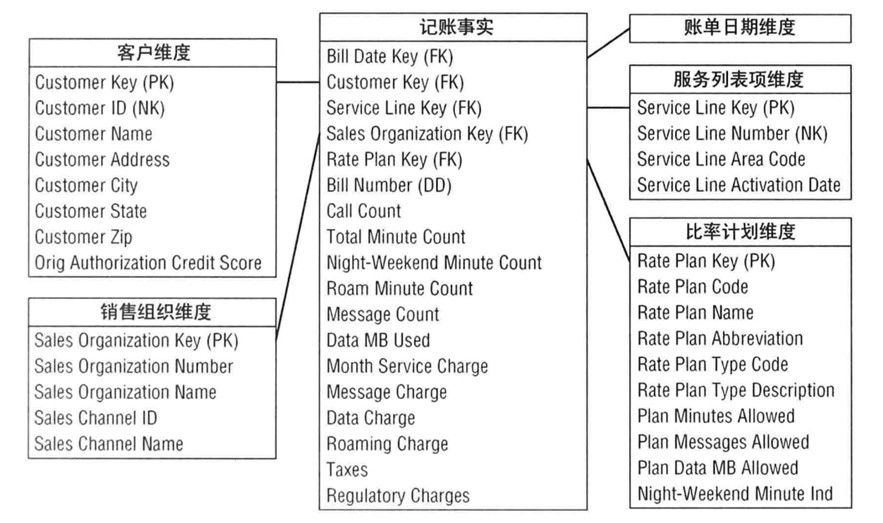
ODS:Operational Data Store,操作数据层,在结构上其与源系统的增量或者全量数据基本保持 一致。
它相当于一个数据准备区,同时又承担着基础数据的记录以及历史变化。其主要作用是把基础数据引入到MaxCompute。CDM:Common Data Model,公共维度模型层,又细分为DWD和DWS。它的主要作用是完成数据加工与整合、建立一致性的维度、构建可复用的面向分析和统计的明细事实表以及汇总公共粒度的指标。
DWD:Data Warehouse Detail,明细数据层。
DWS:Data Warehouse Summary,汇总数据层。
ADS:Application Data Service,应用数据层。
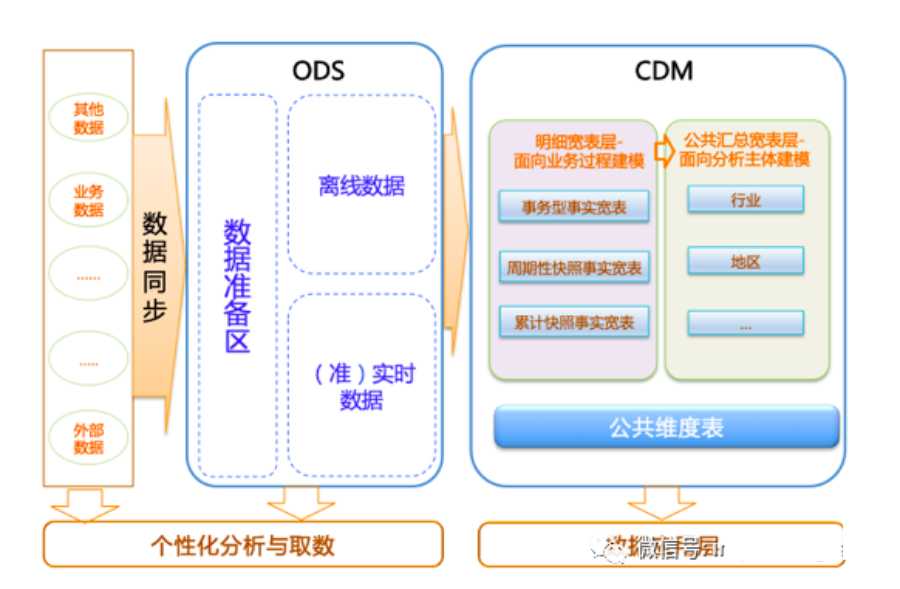
公共维度层:
基于维度建模理念思想,建立整个企业的一致性维度。明细粒度事实层:
以业务过程为建模驱动,基于每个具体业务过程的特点,构建最细粒度的明细层事实表。
可以结合企业的数据使用特点,将明细事实表的某些重要维度属性字段做适当的冗余,即宽表化处理。公共汇总粒度事实层:
以分析的主题对象为建模驱动,基于上层的应用和产品的指标需求,构建公共粒度的汇总指标事实表,以宽表化手段来物理化模型。
按业务划分:
命名时按主要的业务划分,以指导物理模型的划分原则、命名原则及使用的ODS project。
例如,按业务定义英文缩写,阿里的“淘宝”英文缩写可以定义为“tb”。按数据域划分:
命名时按照CDM层的数据进行数据域划分,以便有效地对数据进行管理,以及指导数据表的命名。
例如,“交易”数据的英文缩写可定义为“trd”。按业务过程划分:
当一个数据域由多个业务过程组成时,命名时可以按业务流程划分。
业务过程是从数据分析角度看客观存在的或者抽象的业务行为动作。
例如,交易数据域中的“退款”这个业务过程的英文缩写可约定命名为“rfd_ent”。
(1)高内聚和低耦合
(2)核心模型与扩展模型分离
(3)公共处理逻辑下沉及单一
(4)成本与性能平衡
(5)数据可回滚
(6)一致性
(7)命名清晰可理解
一个模型无法满足所有的需求。 需合理选择数据模型的建模方式。 通常,设计顺序依次为:概念模型->逻辑模型->物理模型。
维度属性尽量丰富,为数据使用打下基础。 给出详实的、富有意义的文字描述。 沉淀通用维度属性,为建立一致性维度做好铺垫。 严格区分事实与维度,通过使用场景进行区分。
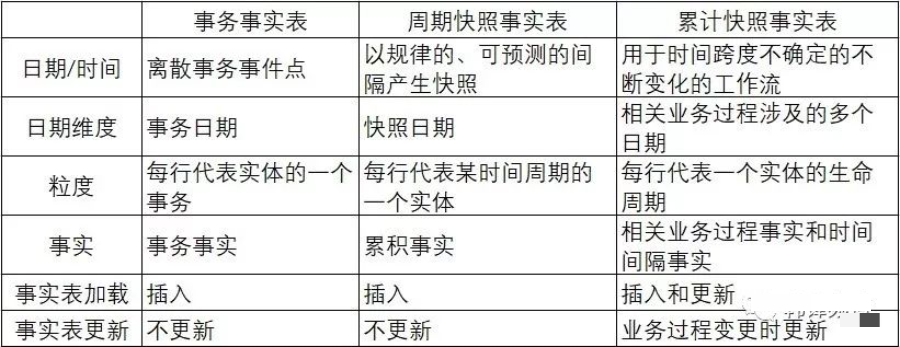
选择一种适合的事实表类型。 事实尽可能完整,包含整个业务过程的全部事实。 确保每一个事实度量都是一致性,反复计算都会得到相同的结果。尽量记录一些“原子”事实,而不是加工后的结果。 可适当做些”维度退化属性”,提高事实表的查询性能。 为提高聚合性能,可适度做些上卷汇聚事实表。
推荐阅读:
不是你需要中台,而是一名合格的架构师(附各大厂中台建设PPT)