
亲手验证:如何充分激发CPU的AI加速潜能
黑格尔曾说:“没有冲突不成戏剧。”观察一下现在的AI行业实践,可能有助于你理解这句话内味儿。
就在大家认为AI还只是个遥不可及的梦想时,深度学习技术的出现让大家重拾希望;当人们认为AI会在实验室里停留更长时间时,它已不声不响地走进了众多行业的实践;当大家还在争论,跑AI,到底是GPU好,还是应该开发更多种类、更专用的AI加速芯片时,有人却说:“为什么不先试试CPU呢?”,真是戏剧性、转折感爆棚。
说出最后这句话的,正是IT圈儿的老朋友英特尔。
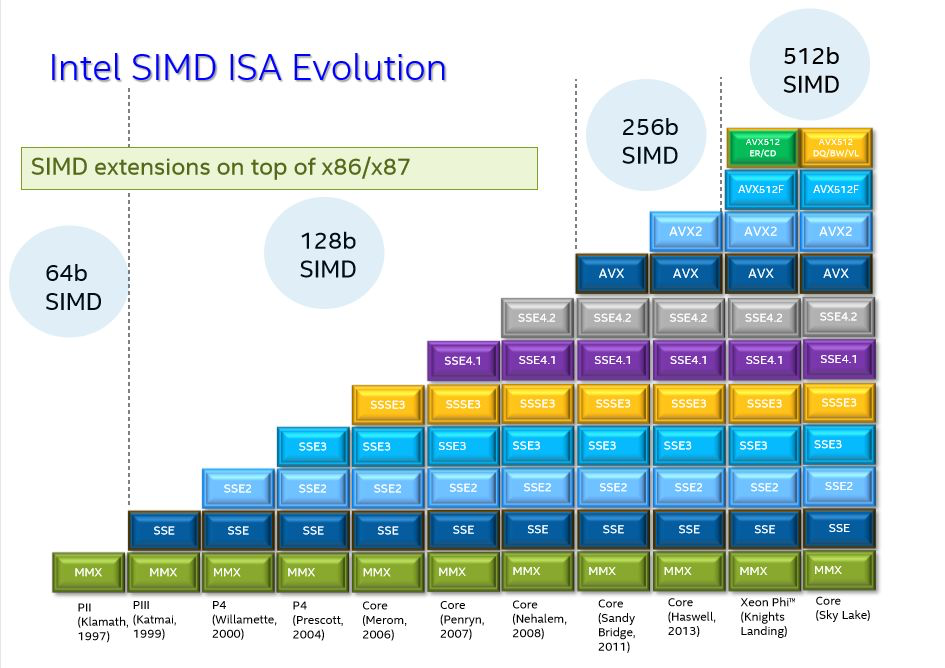
从2017年第一代至强可扩展处理器集成AVX-512,开始基于CPU对AI训练和推理提供加速支持,到2018年第二代至强可扩展处理器在AVX-512技术之上扩展出深度学习加速技术,主打INT8推理加速,再到2020年面向多路服务器的第三代至强可扩展处理器新增BF16加速,开始兼顾推理和训练的加速,最后再到今年发布的面向单路和双路服务器的第三代至强可扩展处理器(Ice Lake)进一步强化INT8推理加速,将推理能力提升到上一代产品的1.74倍,这一套连贯的动作下来,足以证明英特尔“用CPU跑AI”并非口嗨。

不少英特尔的客户也在说“用CPU跑AI效果不错”。但作为极具折腾精神的E企研究院,我们更希望为大家亲手验证:
至强可扩展处理器,尤其是它最新一代产品,真地能为AI提供出色的加速效果么?
还有我们需要用什么样的“姿势”,才能用好CPU的这项新能力?
E企研究院这次用长城超云的双路服务器平台---Ice Lake架构的第三代英特尔至强可扩展处理器——36核心72线程的至强铂金8360Y处理器来进行验证。需要说明的是,这次测试只使用了单颗CPU。

摸出底线
我们先来测试CPU在无特别优化的情况下,跑AI应用时的性能表现。
我们把自己代入成一家主要用AI做推理的企业,具体场景是基于训练好的模型,使用来自多个传感器收集的图像或语音数据做推理的过程,因此出场的模型,我们选中了经过预训练的ResNet50推理模型。
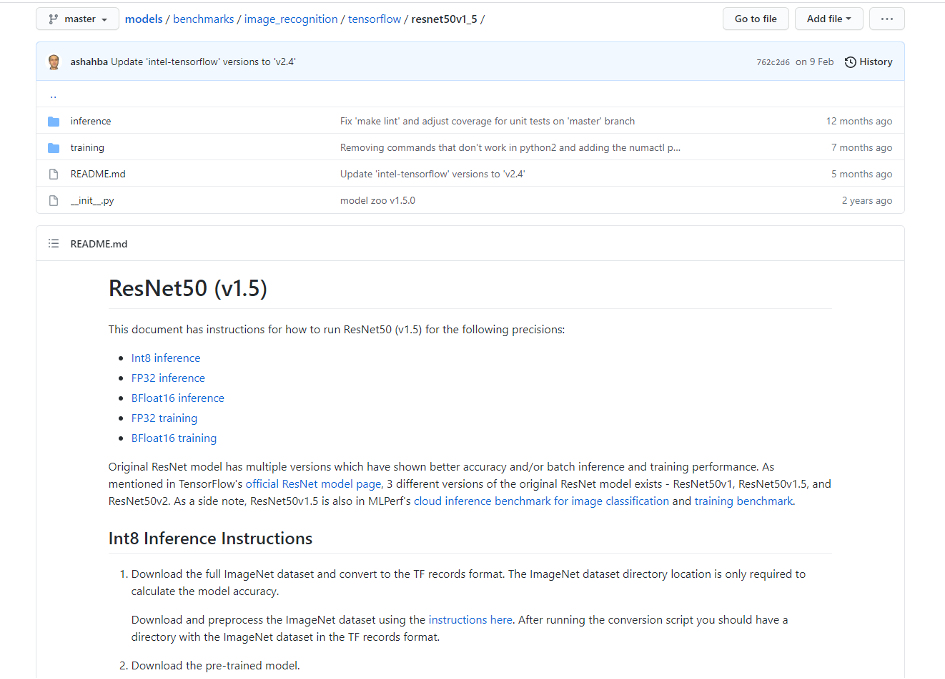
测试的主要流程是:在测试环境中安装TensorFlow 2.5版本,并使用主流的ImageNet 2012数据库,并将CPU设置为性能优先模式,然后运行ResNet 50推理模型。
结果是每秒处理超过72张图片,平均时延在14ms以内,这个……也太没吸引力了吧!

先别急,CPU运行ResNet 50推理模型的性能根本还没发挥出来呢。
优化动作开始
我们修改一下测试命令,同一个平台,吞吐性能超过每秒172张图片,时延也减少到6ms以内,性能一下提升到之前的2.37倍。

一句简单的命令居然有这么大威力?原因何在?
秘密就是:即便是在原生版的TensorFlow中,英特尔也贡献了不少优化代码,其中很多都是来自oneDNN,这是英特尔开发和开源的面向深度神经网络的数学核心函数库,包含了高度矢量化和线程化的构建模块,可帮助深度神经网络调优,来充分利用英特尔架构CPU集成的AI加速能力。上面这句命令的作用就是开启了oneDNN的优化功能,可大大提升CPU运行AI推理类应用的效率。

再进一步会怎样
还有更多、更神奇的功能吗?
接下来,我们使用英特尔自已发布的,专门且更为全面地面向英特尔架构优化的TensorFlow框架,切换到这个环境再来运行ResNet 50推理模型。
性能果然又有提升,又涨了约17%。
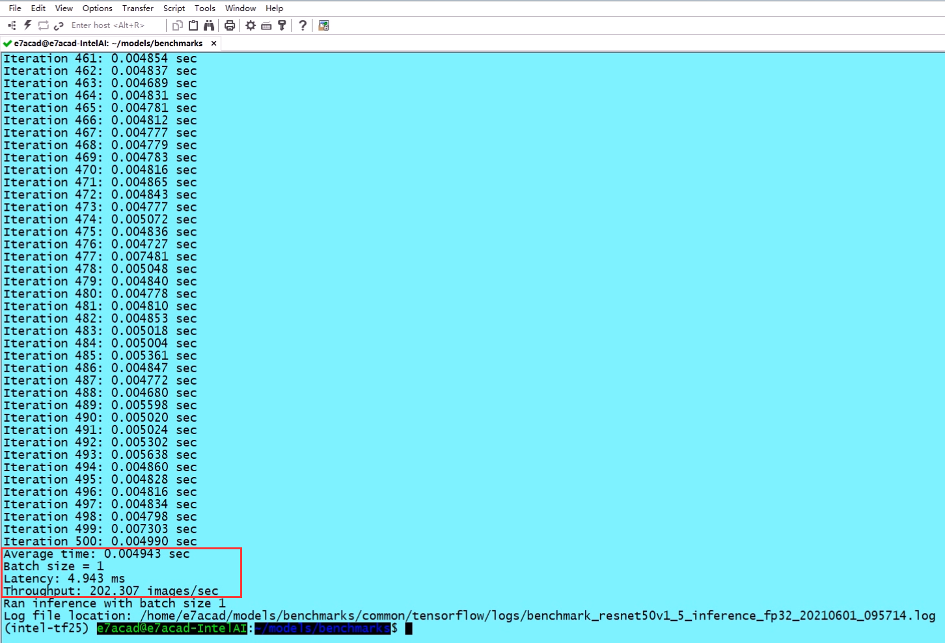
图注:在面向英特尔架构优化的TensorFlow框架上运行ResNet50(v1.5)推理模型,吞吐性能提升到每秒超202张图像,平均时延不到5ms。这种充分优化后的TensorFlow框架及模型库(model zoo)都已开源在GitHub上,任何人都可下载使用。安装和使用方式与原生TensorFlow并无区别
让我们再算算:与最开始的、未经优化的TensorFlow环境相比,在面向英特尔架构优化的TensorFlow框架的加持下,运行ResNet 50的推理性能,已达到前者的2.77倍以上。
上述三轮测试考验的,都是ResNet 50模型在全新第三代至强可扩展处理器上运行时的FP32性能。不难看出,只要优化动作到位,性能提升也会立即到位,况且这还只是单颗CPU的性能表现。
这意味着,企业用户基本不需要对既有的IT基础设施做大的改动,也不需要急着导入异构,只要你现在用的CPU是至强可扩展处理器,那么,你就具备了执行AI推理的主要条件。
再放大招,大大招
你以为这就结束了么?并没有,接下来才是大招。
我们将开始在CPU上执行INT8推理加速的测试。由于很多企业在使用AI推理时,并不需要FP32这么高的精度,我们可以把数据格式转变为INT8,在确保准确率不明显下降的情况下,看看性能会发生怎样的变化。
这轮测试我们必须要激活英特尔深度学习加速,也就是DL Boost技术中的INT8加速功能,同样基于面向英特尔架构优化的TensorFlow框架。结果是,时延降至3ms内,吞吐则超过了每秒391 张图片。
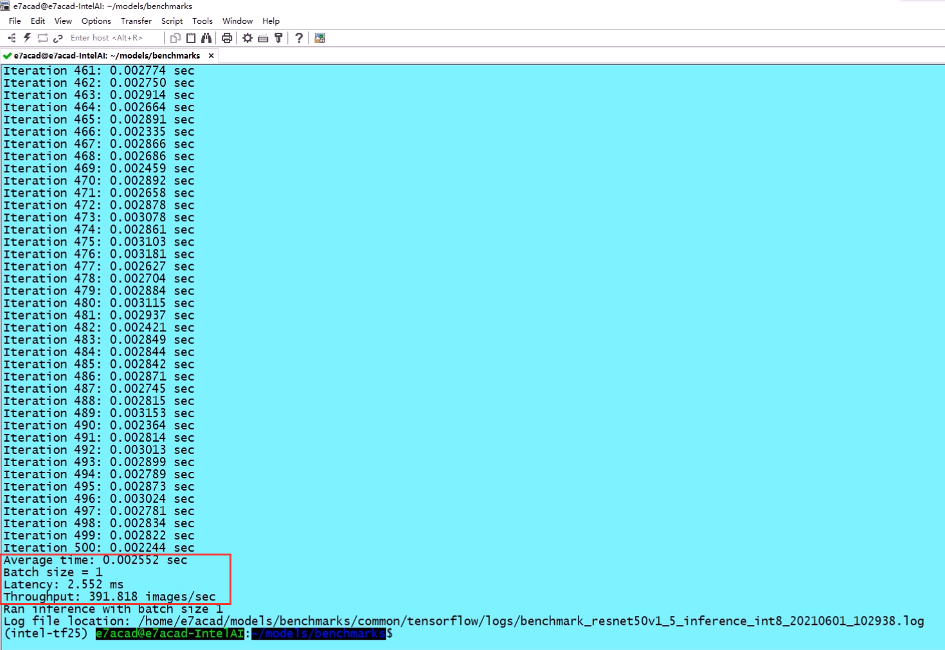
图注:在面向英特尔架构优化的TensorFlow中使用ResNet50(v1.5)运行INT8推理的结果
终于,我们迎来了最后一轮测试。由于上面多轮测试都在考虑单路推理的性能,而在实际应用中,很多用户都会跑多路推理,那么在这种情况下,用户更希望在可接受的时延水平——譬如30ms上下——尽可能提升吞吐性能。
这组测试中我们使用的至强铂金8360Y处理器终于火力全开,单颗CPU 36个物理核心对应36个INT8实例。
结果是:平均时延约为27ms,但总计吞吐能力超过每秒1300张图片,这意味着用户真地能用可接受的时延提升,换回3倍以上的性能输出,多核威力有目共睹。
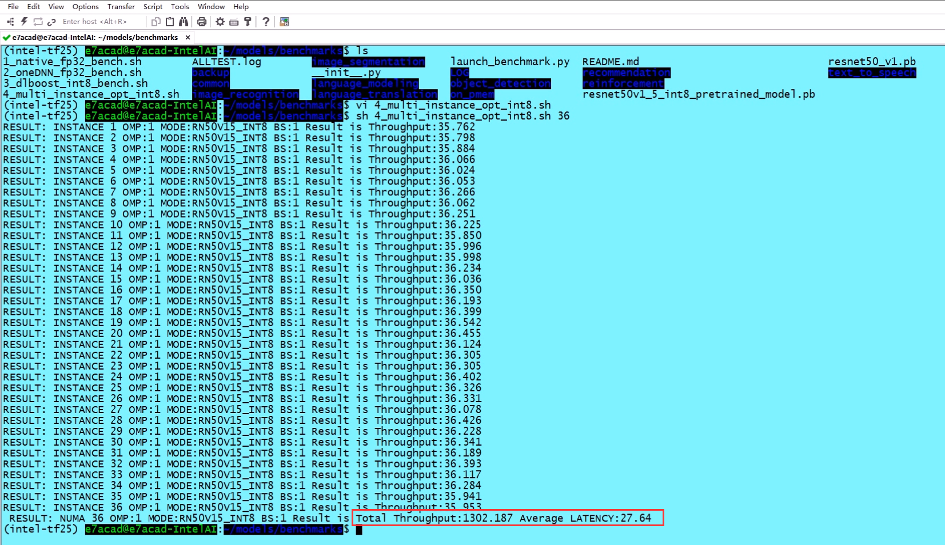
图注:使用36个INT8实例并行运行(所使用的英特尔至强铂金8360Y处理器具有36核心,每核心运行一个INT8实例)的测试结果
要知道,直到现在我们使用的都是单颗至强铂金8360Y处理器,如果在一个双路服务器中采用两颗全上的策略,那么性能理论上是能够翻倍,可见英特尔官宣的AI加速性能指标绝非空穴来风。
看到这里,你对至强CPU的AI加速能力是否有了更为直观的体验呢?你是否也有使用CPU加速AI应用的独到经验或问题呢?欢迎大家和我们分享,也欢迎大家一起动手探索验证。
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看![]()