
2022 年 Python “十级”试题(全国卷A)-答案解析

试题来源:Python之美
试题作者:间歇性出现的小明
答案作者:古明地觉

第一题

问题:

答案解析:
本题有两个要点,第一个是 Python 对数字进行语法解析的时候,正负号和数字之间允许有空格。
num = - 1
print(num) # -1
# 以下也是合法的
# +1 和 1 等价,可以将 + 忽略掉
# 然后负负得正,所以结果是 1
num = - - - + + - - - 1
print(num) # 1第二个要点是增强运算符,num = num + 1 可以写成 num += 1。
所以题目中的第二行相当于 score = score - -1,由于初始值为 10,因此最终结果为 11,答案是 B。
第二题
问题:

答案解析:
本题考察了 Python3.8 新增的海象运算符,它可以让变量赋值和表达式合为一体,举个例子:
if (age := 18) >= 18:
print("已成年")
# 上述代码等价于如下
age = 18
if age > 18:
print("已成年")但需要注意的是,海象运算符的优先级是最低的,需要使用括号进行限定。
if age := 18 >= 18:
print("已成年")
# 不加括号,等价于如下
age = 18 >= 18
if age:
print("已成年")此时 age 就变成了布尔值 True。
那么海象运算符有什么用呢?其实它最大的用处就是简化代码,比如当你需要用一个变量接收函数的返回值,并加以判断时,就可以使用它。
def some_func():
"""
返回一个整数
:return:
"""
import random
return random.randint(1, 100)
val = some_func()
if val > 50:
# do something
pass
# 使用海象运算符
if (val := some_func()) > 50:
# do something
pass再举个例子:
# data 保存了子节点到父节点的映射
# 显然每个父节点又是其它节点的子节点
data = {
1: 4,
4: 11,
11: 7,
7: 20,
20: 15
}
# 现在给定一个节点 node
# 找到它最顶层的父节点
# 做法一:
node = 1
while True:
if node in data:
node = data[node]
else:
break
print(node) # 15
# 做法二:
node = 1
while data.get(node) is not None:
node = data[node]
print(node) # 15
# 做法三:
node = 1
while (val := data.get(node)) \
is not None:
node = val
print(node)做法二和做法三要更简洁一些。
回到题目,海象表达式一般出现在 if while 语句中,当然它也可以单独用来赋值。
(x := 3)
# 等价于如下
x = 3
x 如果单独用来赋值的话,那么周围必须用小括号括起来,否则会报出语法错误。因此这道题答案是 A。
最后再说一句,由于海象运算符的存在,我们可以写出很恶心人的代码。
x = (y := 1)
# 等价于如下
y = 1
x = y
x = (x := (y := (z := 4) + z) + y)
# 等价于如下
z = 4
y = z + z
x = y + y
x = x所以海象运算符不要滥用,否则代码可读性很容易变差。
第三题
问题:
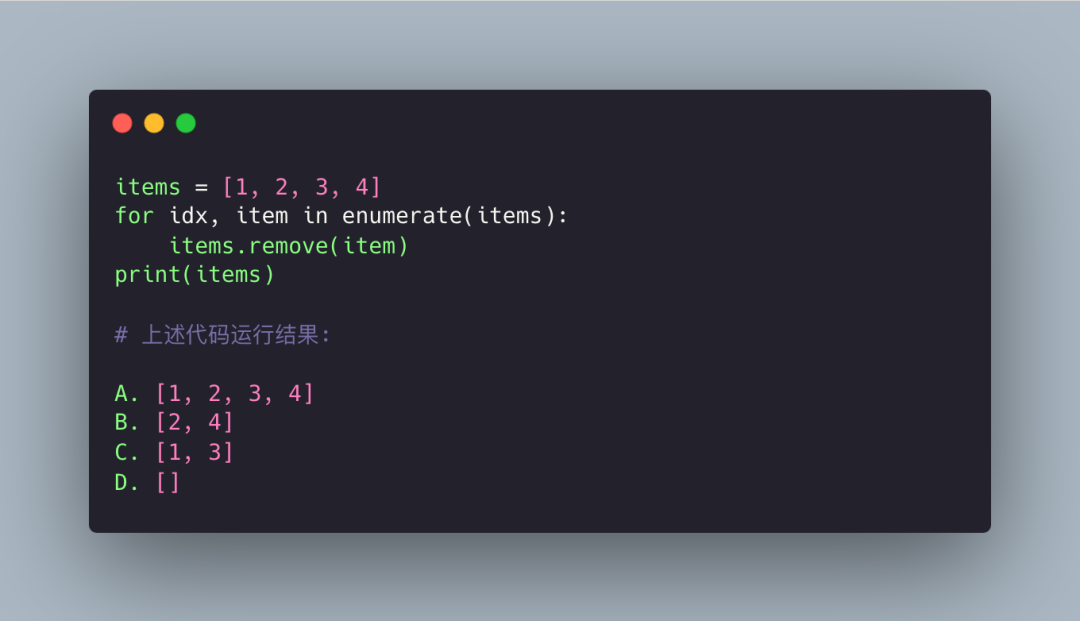
答案解析:
首先题目存在干扰,上面的 for 循环完全可以写成 for item in items。而解答本题首先要明白两点,第一个是 for 循环的迭代原理,第二个是列表是可变对象,支持本地修改。
我们先来介绍第一点,for 循环在遍历可迭代对象时,会先调用可迭代对象内部的 __iter__ 方法得到迭代器,然后不断地调用迭代器内部的 __next__ 方法,将值一个个迭代出来。当迭代器没有元素可以迭代了,则抛出 StopIteration 异常,for 循环捕获,然后结束。
所以如果迭代器包含 10 个元素,那么需要迭代 11 次才能够结束。
再来说说迭代器本身,Python 的迭代器看起来挺神奇,但底层实现非常的简单,简单到甚至有一点 low。由于题目中的 items 是列表,我们就以列表对应的迭代器为例:
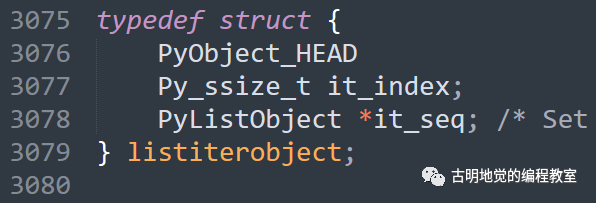
这就是相应的底层结构,就是将列表和索引进行一层封装,所谓的元素迭代还是基于索引获取。每迭代一次,索引自增 1,当索引达到列表长度时就知道迭代完毕了,于是会将 it_seq 设置为 NULL,抛出 StopIteration。我们用 Python 模拟一下这个过程:
class ListIterator:
def __init__(self, it_seq):
self.__it_seq = it_seq
self.__index = 0
def __iter__(self):
return self
def __next__(self):
# 如果为空,直接抛出异常
if self.__it_seq is None:
raise StopIteration
# 索引小于长度时,返回迭代结果
if self.__index < len(self.__it_seq):
result = self.__it_seq[self.__index]
self.__index += 1
return result
# 执行到这里,说明迭代结束
# 将 self.__it_seq 设置为 None
# 并抛出异常
self.__it_seq = None
raise StopIteration
def my_iter(lst):
return ListIterator(lst)
items = [1, 2, 3, 4]
it = my_iter(items)
print(next(it)) # 1
print(next(it)) # 2
print(next(it)) # 3
print(next(it)) # 4
try:
next(it)
except StopIteration:
print("迭代结束")
"""
迭代结束
"""
# 迭代器只能迭代一次
# 所以 sum(it) 是 0
print(sum(it)) # 0以上就是迭代器的实现原理,迭代器内部有一个索引 it_index,所谓迭代,本质上还是基于索引获取。
然后列表是可变对象,题目中的变量 items 和迭代器内部的 it_seq 都指向同一个列表。
回到问题,初始 items 为 [1, 2, 3 ,4],我们来解析一下整个过程:
第一次迭代,迭代器内部索引 it_index 为 0,迭代出的 item 为 1。然后 it_index 自增 1,变为 1,remove(item) 之后 items 变成 [2, 3, 4]。
第二次迭代,迭代器内部索引 it_index 为 1,注意:此时迭代出的 item 就是 3。然后 it_index 自增 1 变为 2,remove(item) 之后 items 变成 [2, 4]。
第三次迭代,迭代器内部索引 it_index 为 2,列表长度也为 2,两者相等。所以抛出 StopIteration,迭代结束。
最终 items 为 [2, 4],因此答案是 B。
第四题
问题:
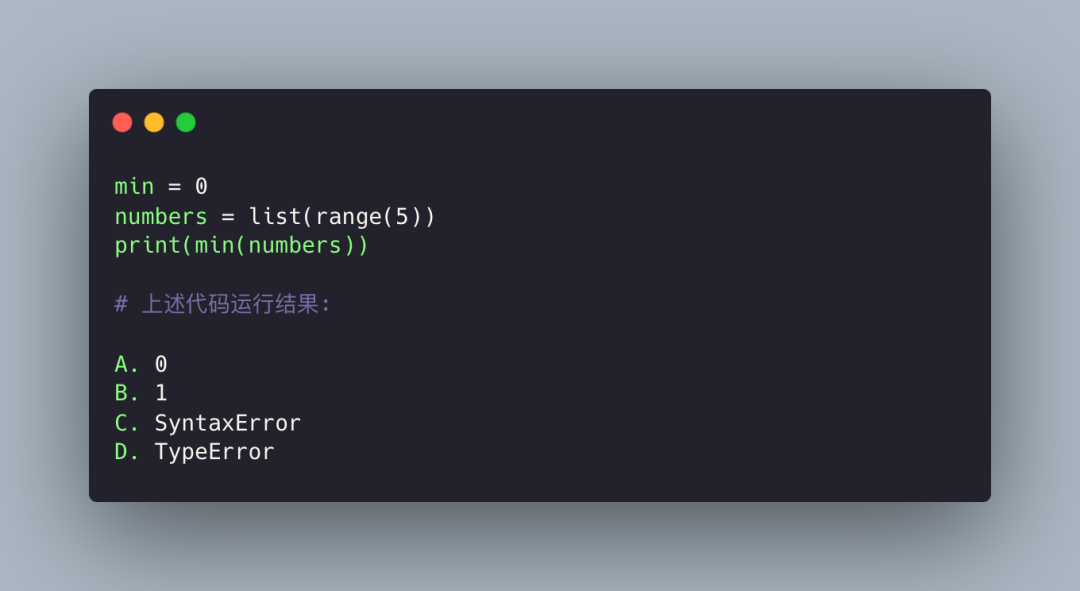
答案解析:
这题就比较简单了,Python 在变量查找的时候遵循 LEGB 规则,而题目将 min 替换成了 0。由于整数不是一个 callable,所以会抛出 TypeError,答案是 D。
通过这道题我想再引出一个问题,在 Python2 中 while 1 比 while True 要快一点点,这是为什么?
很简单,在 Python2 里面 True 不是一个关键字,解释器要花时间检测程序有没有将 True 作为变量使用。但在 Python3 里面两者效率就一致了,因为 True 变成了关键字,和整数 1 一样,都会作为常量加载。
第五题
问题:
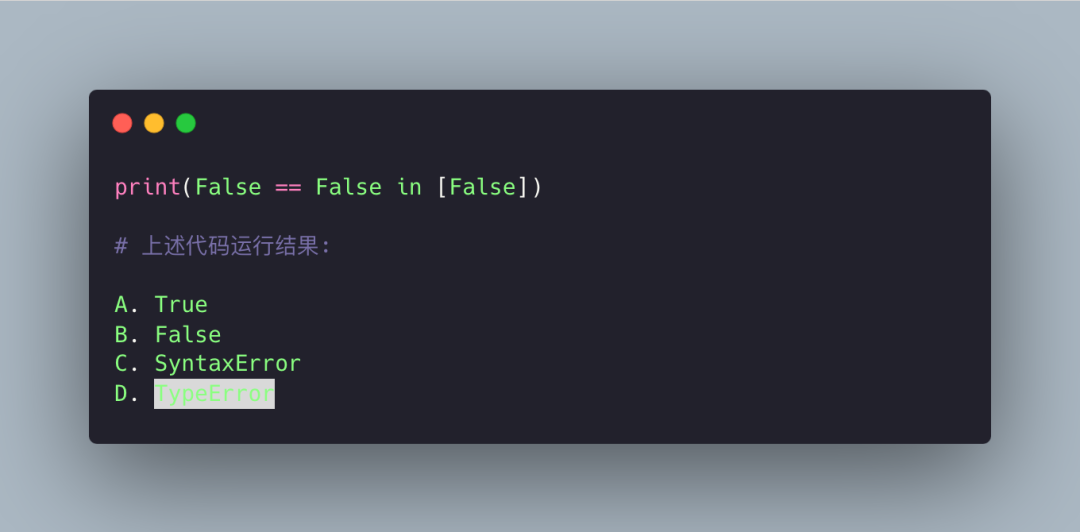
答案解析:
本题考察的是 Python 的链式比较。
a = 3
b = 0
c = 1
print(a > b < c) # True
# 等价于
print(
a > b and b < c
) # True
# 但如果使用括号括起来
# 意义就不一样了
print(
(a > b) < c
) # False
# 此时相当于
result = a > b
print(
result < c
) # False
# result 是 True,相当于 1
# 而 1 < c 不成立
# 链式比较不仅用于比较运算符
# 还可以用于 in 语句
print(
"x" in ["x"] in [["x"]]
) # True因此题目答案显而易见了,False == False 成立,False in [False] 也成立,所以结果为 True,答案是 A。
第六题
问题:
答案解析:
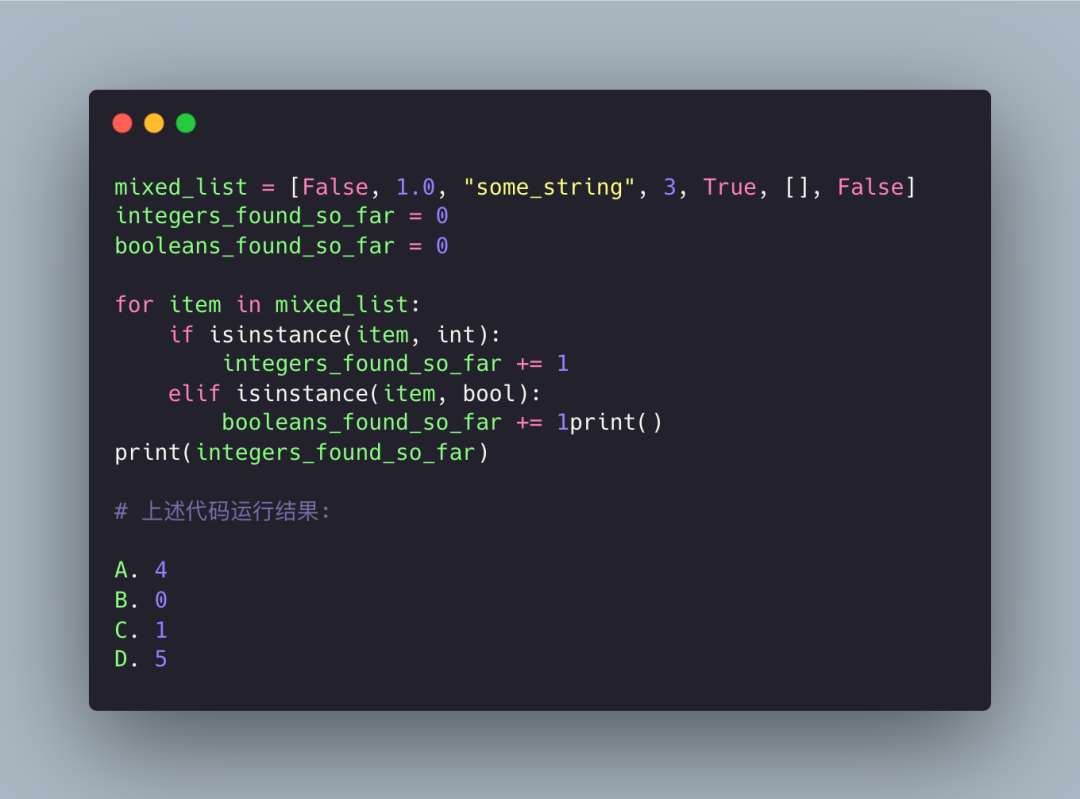
忽略掉 elif 语句里面的 print(),应该是笔误。
本题考察的是对布尔值的理解,bool 是 int 的子类,所以结果为 4,答案是 A。
这里再延伸一下,True 可以看成 1,False 可以看成是 0,在运算时它们的表现也确实如此。
# 统计 lst 中元素为 True 的个数
lst = [True, False, True, True]
# 可以先将为 True 的元素过滤出来
# 然后统计元素个数
print(
len([item for item in lst if item])
) # 3
# 更简单的做法是直接求和即可
print(sum(lst)) # 3这种做法在 numpy 和 pandas 中非常常用。
第七题
问题:
答案解析:
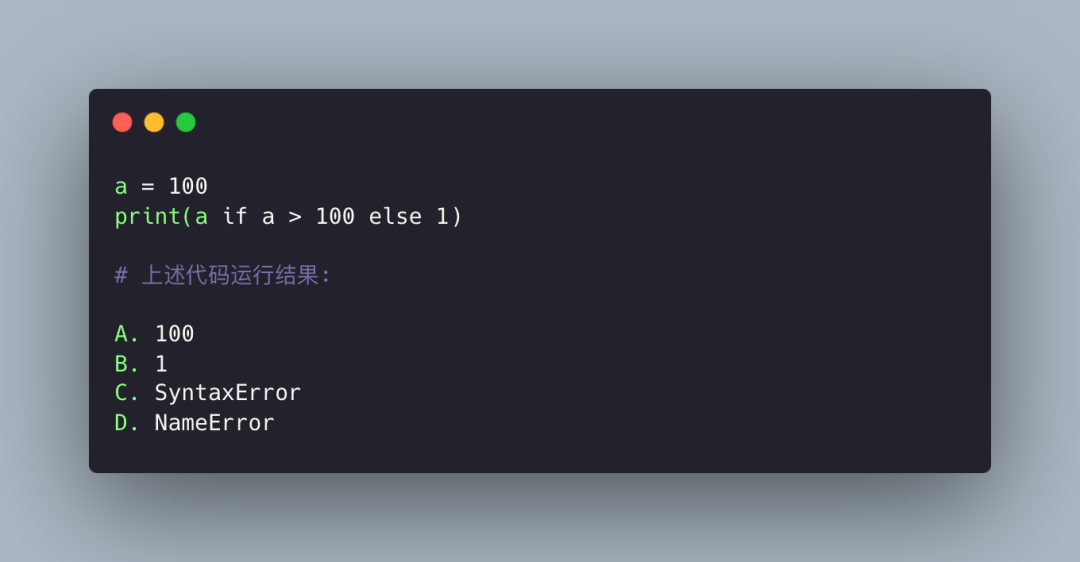
本题考察的是三元运算符,比较简单,答案是 B。
这里额外补充一个优先级的问题:
x = 111 if True else 222, 333
# 以上等价于
x = (111 if True else 222), 333
print(x) # (111, 333)
y = 111 if True else 222 + 333
# 以上等价于
y = 111 if True else (222 + 333)
print(y) # 111另外三元表达式,也可以写的更复杂。
score = 90
if score > 95:
grade = "A"
elif score > 80:
grade = "B"
elif score > 60:
grade = "C"
else:
grade = "D"
# 如果用三元表达式
grade = ("A" if score > 95 else "B"
if score > 80 else "C"
if score > 60 else "D")第八题
问题:
答案解析:
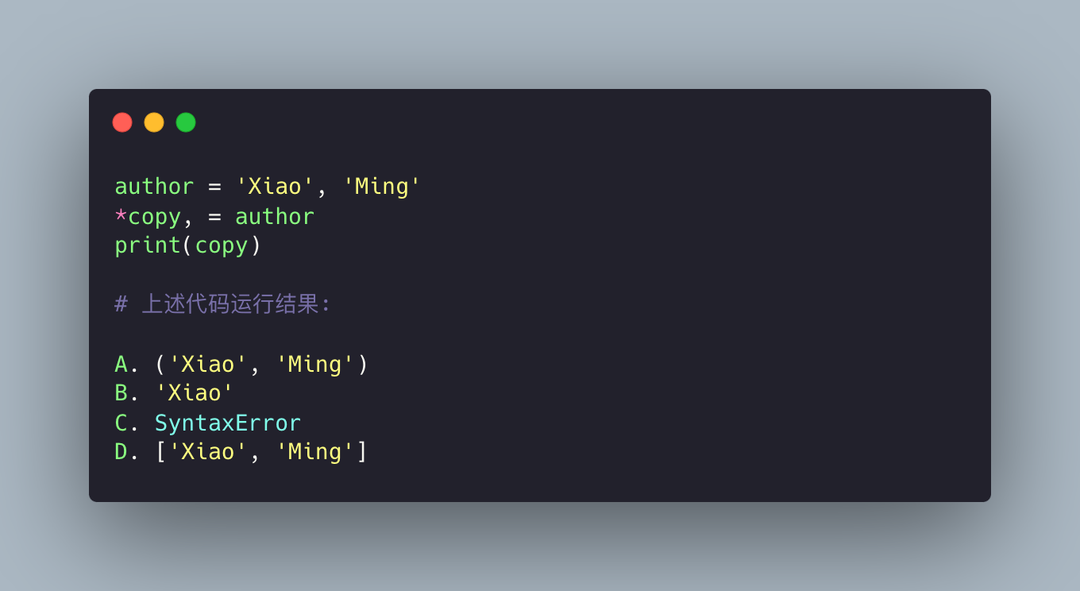
本题考察的是变量的赋值操作,或者也可以理解为序列的解包操作。
vals = (1, 2, 3, 4, 5)
a, *b, c = vals
print(a) # 1
print(b) # [2, 3, 4]
print(c) # 5
*a, b = vals
print(a) # [1, 2, 3, 4]
print(b) # 5
a, *b, c, d, e = vals
print(a) # 1
print(b) # [2]
print(c) # 3
print(d) # 4
print(e) # 5
# *b = vals 不合法
[*b] = vals
print(b) # [1, 2, 3, 4, 5]
# 或者写成
(*b,) = vals
# 和下面等价
*b, = vals
print(b) # [1, 2, 3, 4, 5]
# 更简单的做法是
b = list(vals)关于这部分内容可以参考我前面介绍的文章:如何优雅地遍历可迭代对象?,点击查看即可。因此这道题答案是 D。
第九题
问题:

答案解析:
1.0 和 1 的哈希值相同,所以字典里面只会有一个元素。由于哈希表在更新的时候只会替换 value,不会替换 key,所以答案是 C。
我们实际举个例子:
class A:
def __init__(self, name):
self.name = name
def __hash__(self):
return 123
def __eq__(self, other):
return True
def __repr__(self):
return "古明地觉"
d = {A("古明地觉"): 1}
print(d) # {古明地觉: 1}
# 哈希值一样,所以更新 value
# 但是 key 不会更新
d[A("古明地恋")] = 2
print(d) # {古明地觉: 2}第十题
问题:
答案解析:
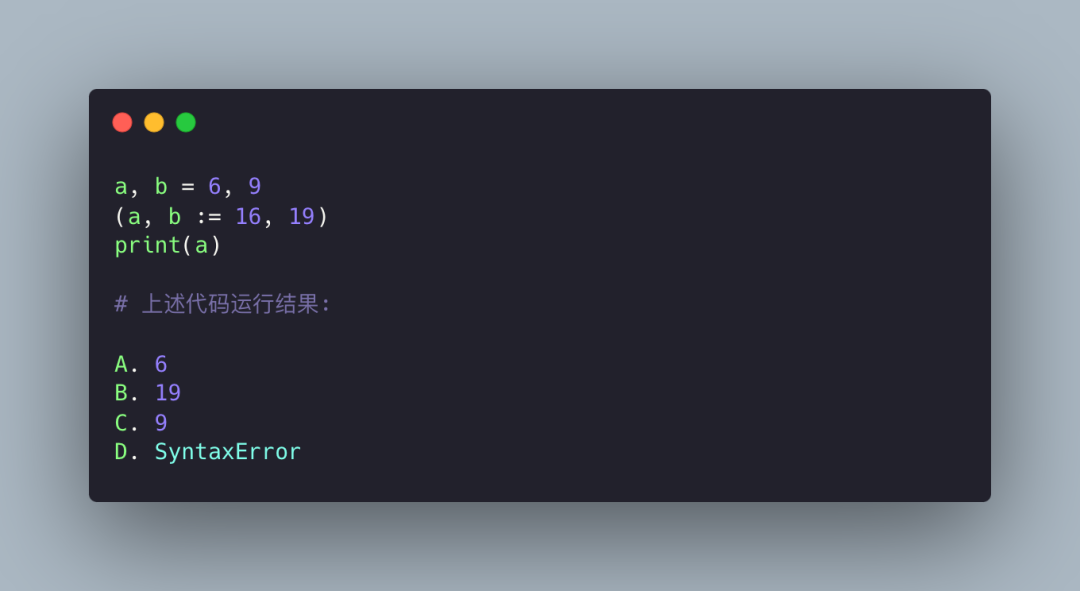
依旧是海象运算符,它的优先级是最低的。
a, b = 6, 9
# (a, b := 16, 19) 等价于如下
b = 16
(a, b, 19)
print(a) # 6答案是 A,没有什么可说的。
小结
总的来说比较简单,后续如果还有这样的题,我再继续做解析。
往期推荐 1、为什么不建议用 from xxx import * 2、Win11系统禁用了IE浏览器,可一直有人试图唤醒它 3、13 个非常有用的 Python 代码片段,建议收藏! 4、Adobe突然查封中国账号,设计社区Behance无权访问! 5、一首歌曲竟然导致WinXP崩溃?时隔近20年获得CVE官方漏洞编号(文末送书)


点击关注公众号,阅读更多精彩内容
