
再见 for 循环!pandas 速度提升315倍!
大邓和他的Python
共 11226字,需浏览 23分钟
· 2023-08-20

骚操作拉满的pandas进阶玩法 + 8个数据分析实战项目,500页图文笔记 👉 pandas进阶宝典
for 是所有编程语言的基础语法,初学者为了快速实现功能,依懒性较强。但如果从运算时间性能上考虑可能不是特别好的选择。 本次东哥介绍几个常见的提速方法,一个比一个快,了解 pandas 本质,才能知道如何提速。
>>> import pandas as pd基于上面的数据,我们现在要增加一个新的特征,但这个新的特征是基于一些时间条件生成的,根据时长(小时)而变化,如下:
# 导入数据集
>>> df = pd.read_csv('demand_profile.csv')
>>> df.head()
date_time energy_kwh
0 1/1/13 0:00 0.586
1 1/1/13 1:00 0.580
2 1/1/13 2:00 0.572
3 1/1/13 3:00 0.596
4 1/1/13 4:00 0.592
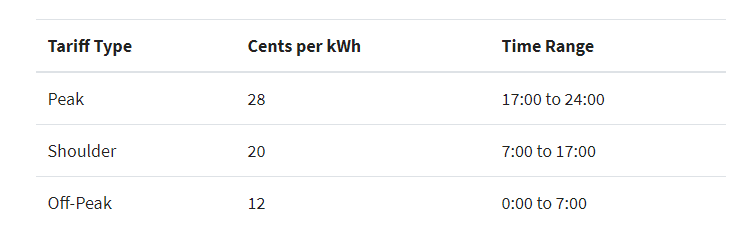
因此,如果你不知道如何提速,那正常第一想法可能就是用 apply 方法写一个函数,函数里面写好时间条件的逻辑代码。
def apply_tariff(kwh, hour):然后使用
"""计算每个小时的电费"""
if 0 <= hour < 7:
rate = 12
elif 7 <= hour < 17:
rate = 20
elif 17 <= hour < 24:
rate = 28
else:
raise ValueError(f'Invalid hour: {hour}')
return rate * kwh
for 循环来遍历 df ,根据 apply 函数逻辑添加新的特征,如下:
>>> # 不赞同这种操作对于那些写
>>> @timeit(repeat=3, number=100)
... def apply_tariff_loop(df):
... """用for循环计算enery cost,并添加到列表"""
... energy_cost_list = []
... for i in range(len(df)):
... # 获取用电量和时间(小时)
... energy_used = df.iloc[i]['energy_kwh']
... hour = df.iloc[i]['date_time'].hour
... energy_cost = apply_tariff(energy_used, hour)
... energy_cost_list.append(energy_cost)
... df['cost_cents'] = energy_cost_list
...
>>> apply_tariff_loop(df)
Best of 3 trials with 100 function calls per trial:
Function `apply_tariff_loop` ran in average of 3.152 seconds.
Pythonic 风格的人来说,这个设计看起来很自然。然而,这个循环将会严重影响效率。原因有几个: 首先,它需要初始化一个将记录输出的列表。 其次,它使用不透明对象范围 (0,len(df)) 循环,然后再应用 apply_tariff() 之后,它必须将结果附加到用于创建新 DataFrame 列的列表中。另外,还使用 df.iloc [i]['date_time'] 执行所谓的链式索引,这通常会导致意外的结果。 这种方法的最大问题是计算的时间成本。对于8760行数据,此循环花费了3秒钟。 接下来,一起看下优化的提速方案。
一、使用 iterrows循环
第一种可以通过 pandas 引入 iterrows 方法让效率更高。这些都是一次产生一行的 生成器 方法,类似 scrapy 中使用的 yield 用法。 .itertuples 为每一行产生一个 namedtuple ,并且行的索引值作为元组的第一个元素。 nametuple 是 Python 的 collections 模块中的一种数据结构,其行为类似于 Python 元组,但具有可通过属性查找访问的字段。 .iterrows 为 DataFrame 中的每一行产生 (index,series) 这样的元组。 在这个例子中使用 .iterrows ,我们看看这使用 iterrows 后效果如何。
>>> @timeit(repeat=3, number=100)这样的语法更明确,并且行值引用中的混乱更少,因此它更具可读性。 时间成本方面:快了近5倍! 但是,还有更多的改进空间,理想情况是可以用
... def apply_tariff_iterrows(df):
... energy_cost_list = []
... for index, row in df.iterrows():
... # 获取用电量和时间(小时)
... energy_used = row['energy_kwh']
... hour = row['date_time'].hour
... # 添加cost列表
... energy_cost = apply_tariff(energy_used, hour)
... energy_cost_list.append(energy_cost)
... df['cost_cents'] = energy_cost_list
...
>>> apply_tariff_iterrows(df)
Best of 3 trials with 100 function calls per trial:
Function `apply_tariff_iterrows` ran in average of 0.713 seconds.
pandas 内置更快的方法完成。
二、pandas的apply方法
我们可以使用 .apply 方法而不是 .iterrows 进一步改进此操作。 pandas 的 .apply 方法接受函数 callables 并沿 DataFrame 的轴(所有行或所有列)应用。下面代码中, lambda 函数将两列数据传递给 apply_tariff() :
>>> @timeit(repeat=3, number=100)
... def apply_tariff_withapply(df):
... df['cost_cents'] = df.apply(
... lambda row: apply_tariff(
... kwh=row['energy_kwh'],
... hour=row['date_time'].hour),
... axis=1)
...
>>> apply_tariff_withapply(df)
Best of 3 trials with 100 function calls per trial:
Function `apply_tariff_withapply` ran in average of 0.272 seconds.
apply 的语法优点很明显,行数少,代码可读性高。在这种情况下,所花费的时间大约是 iterrows 方法的一半。 但是,这还不是“非常快”。一个原因是 apply() 将在内部尝试循环遍历 Cython 迭代器。但是在这种情况下,传递的 lambda 不是可以在 Cython 中处理的东西,因此它在Python中调用并不是那么快。 如果我们使用 apply() 方法获取10年的小时数据,那么将需要大约15分钟的处理时间。如果这个计算只是大规模计算的一小部分,那么真的应该提速了。这也就是矢量化操作派上用场的地方。
三、矢量化操作:使用.isin选择数据
什么是矢量化操作? 如果你不基于一些条件,而是可以在一行代码中将所有电力消耗数据应用于该价格: df ['energy_kwh'] * 28 ,类似这种。那么这个特定的操作就是矢量化操作的一个例子,它是在 pandas 中执行的最快方法。 但是如何将条件计算应用为 pandas 中的矢量化运算? 一个技巧是:根据你的条件,选择和分组DataFrame ,然后对每个选定的组应用矢量化操作。 在下面代码中,我们将看到如何使用 pandas 的 .isin() 方法选择行,然后在矢量化操作中实现新特征的添加。在执行此操作之前,如果将 date_time 列设置为 DataFrame 的索引,会更方便:
# 将date_time列设置为DataFrame的索引我们来看一下结果如何。
df.set_index('date_time', inplace=True)
@timeit(repeat=3, number=100)
def apply_tariff_isin(df):
# 定义小时范围Boolean数组
peak_hours = df.index.hour.isin(range(17, 24))
shoulder_hours = df.index.hour.isin(range(7, 17))
off_peak_hours = df.index.hour.isin(range(0, 7))
# 使用上面apply_traffic函数中的定义
df.loc[peak_hours, 'cost_cents'] = df.loc[peak_hours, 'energy_kwh'] * 28
df.loc[shoulder_hours,'cost_cents'] = df.loc[shoulder_hours, 'energy_kwh'] * 20
df.loc[off_peak_hours,'cost_cents'] = df.loc[off_peak_hours, 'energy_kwh'] * 12
>>> apply_tariff_isin(df)提示,上面
Best of 3 trials with 100 function calls per trial:
Function `apply_tariff_isin` ran in average of 0.010 seconds.
.isin() 方法返回的是一个布尔值数组,如下:
[False, False, False, ..., True, True, True]布尔值标识了
DataFrame 索引 datetimes 是否落在了指定的小时范围内。然后把这些布尔数组传递给 DataFrame 的 .loc ,将获得一个与这些小时匹配的 DataFrame 切片。然后再将切片乘以适当的费率,这就是一种快速的矢量化操作了。 上面的方法完全取代了我们最开始自定义的函数 apply_tariff() ,代码大大减少,同时速度起飞。 运行时间比Pythonic的for循环快315倍,比iterrows快71倍,比apply快27倍!
四、还能更快?
太刺激了,我们继续加速。 在上面 apply_tariff_isin 中,我们通过调用 df.loc 和 df.index.hour.isin 三次来进行一些手动调整。如果我们有更精细的时间范围,你可能会说这个解决方案是不可扩展的。但在这种情况下,我们可以使用 pandas 的 pd.cut() 函数来自动完成切割:
@timeit(repeat=3, number=100)上面代码
def apply_tariff_cut(df):
cents_per_kwh = pd.cut(x=df.index.hour,
bins=[0, 7, 17, 24],
include_lowest=True,
labels=[12, 20, 28]).astype(int)
df['cost_cents'] = cents_per_kwh * df['energy_kwh']
pd.cut() 会根据 bin 列表应用分组。 其中 include_lowest 参数表示第一个间隔是否应该是包含左边的。 这是一种完全矢量化的方法,它在时间方面是最快的:
>>> apply_tariff_cut(df)到目前为止,使用pandas处理的时间上基本快达到极限了!只需要花费不到一秒的时间即可处理完整的10年的小时数据集。 但是,最后一个其它选择,就是使用
Best of 3 trials with 100 function calls per trial:
Function `apply_tariff_cut` ran in average of 0.003 seconds.
NumPy ,还可以更快!
五、使用Numpy继续加速
使用 pandas 时不应忘记的一点是 Pandas 的 Series 和 DataFrames 是在 NumPy 库之上设计的。并且, pandas 可以与 NumPy 阵列和操作无缝衔接。 下面我们使用 NumPy 的 digitize() 函数更进一步。它类似于上面 pandas 的 cut() ,因为数据将被分箱,但这次它将由一个索引数组表示,这些索引表示每小时所属的 bin 。然后将这些索引应用于价格数组:
@timeit(repeat=3, number=100)与
def apply_tariff_digitize(df):
prices = np.array([12, 20, 28])
bins = np.digitize(df.index.hour.values, bins=[7, 17, 24])
df['cost_cents'] = prices[bins] * df['energy_kwh'].values
cut 函数一样,这种语法非常简洁易读。
>>> apply_tariff_digitize(df)0.002秒! 虽然仍有性能提升,但已经很边缘化了。
Best of 3 trials with 100 function calls per trial:
Function `apply_tariff_digitize` ran in average of 0.002 seconds.
以上就是本次加速的技巧分享。
精选内容
70G数据集 | 3571万条专利申请数据集(1985-2022年)
数据集 | 2001-2022年A股上市公司年报&管理层讨论与分析
管理世界 | 用正则表达式、文本向量化、线性回归算法从md&a数据中计算 「企业融资约束指标」
PNAS | 14000+篇心理学顶刊论文可复现性调研(含代码)
网络爬虫 | 使用Python披露采集 Up 主视频详情信息
评论
只写后台管理的前端要怎么提升自己
大厂技术 高级前端 Node进阶点击上方 程序员成长指北,关注公众号回复1,加入高级Node交流群本人写了五年的后台管理。每次面试前就会头疼,因为写的页面除了表单就是表格。抱怨过苦恼过也后悔过(虽然我现在已经心安理得的摆烂),但是站在现在的时间点
程序员成长指北
1
【第128期】提升编程效率VSCode变量命名插件推荐
概述 在编程的世界里,一个好的变量名不仅能够提升代码的可读性,还能反映出程序员的专业水平。Visual Studio Code(VSCode)作为一个广受欢迎的代码编辑器,拥有丰富的插件生态系统,其中不乏能够帮助我们高效命名变量的工具。今天,我们就来介绍几款VSCode上能够提升变量命名效率的插件
前端微服务
0
提升思维,格局就打开了
每个人,都需要打破困住自己的牢笼不是因为很厉害才会变得快乐和自由而是要首先勇于冲破那个困住你的牢笼先让自己自由了才会渐渐变得快乐才会找回真正的自己才会变得越来越厉害.🌿哲学家叔本华说:世界上最大的监狱,是人的思维。回想我们过往犯过的错误,或者失去的机会,你会发现:绝大多数都是“思维牢笼”带来的,人一
小Q聊产品
1
怎么才能用pandas删除第一列第0行?
点击上方“Python共享之家”,进行关注回复“资源”即可获赠Python学习资料今日鸡汤乡书不可寄,秋雁又南回。大家好,我是皮皮。一、前言前几天在Python白银交流群【unswervingly】问了一个Pandas处理的问题,提问截图如下:问题截图如下:二、实现过程这里【dcpeng】给了一个思
IT共享之家
0
全新 SOTA backbone | 2024年了,再见ViT系列Backbone,实数难得,不知道效果如何?
点击上方“小白学视觉”,选择加"星标"或“置顶”重磅干货,第一时间送达在构建用于精确匹配的深度固定长度表示时,确定指纹上的密集特征点,特别是在像素 Level 上,具有重大意义。为了探索指纹匹配的可解释性,作者提出了一种多阶段可解释的指纹匹配网络,名为通过视觉 Transformer 进行指纹匹配的
小白学视觉
10
登云股份拟并购地信企业「速度科技」
图源:《纸钞屋》剧照撰文 | 刘立编辑 | 神璐璐审核 | 刘玉琳封面 | 《纸钞屋》剧照4月14日晚间,登云股份公告,公司正在筹划发行股份及支付现金收购速度科技股份有限公司(简称“速度科技”)的控股权,因有关事项尚存不确定性,公司股票自4月15日开市时起开始停牌。值得一提的是,
泰伯网
5
再见八股文,我要去卷Vue3了。。。
本文推荐最近在考虑新机会的小伙伴阅读!前言上周和部门BP聊天,她说最近在boss上放出一个初级前端岗位,平均每天都能收到500多份简历。前端市场越来越卷,跳槽前做好技术进阶突击,才能稳拿offer。资料内容展示三个维度:资料框架 + 八股文+ Vue3面试题+算法题部分
前端达人
10
Python-3.12.3 新版本发布 & 性能提升
概要2024 年 4 月 Python 发布了 python-3.12.3 版本,看了下它的更新日志,还是有不少提升的。让我感觉比较有意思的是 re 这个老模块也得到了性能提升,下面我们一起看一下新版本的 re 性能提升了多少。场景在网络上我们经常发现,有些人如果使用了比较有攻击性的辞藻,这些敏感词
Python猫
28