
“十问”向量数据库

1、能否用最通俗的语言介绍下什么是向量,什么是向量数据库,它和传统数据库有什么区别?
向量数据库因为AI大模型最近很火。向量数据库是一种专门用于存储、 管理、查询、检索向量的数据库,主要应用于人工智能、机器学习、数据挖掘等领域。向量是一组数值,可以表示一个点在多维空间中的位置。
简单理解就是在AI的世界中,处理的所有数据都是向量的形式,比如“我爱吃荔枝”,在大模型处理的过程中,计算机会转化为向量的形式:
我:[0.1, 0.3, -0.2, ..., -0.1]
喜欢:[-0.3, 0.5, 0.2, ..., 0.4]
吃:[0.4, -0.1, 0.2, ..., -0.3]
荔枝:[-0.4, 0.3, 0.2, ..., 0.3]。
相对传统数据库,向量数据库不仅能够完成基本的 CRUD(添加、 读取查询、更新、删除),标量数据过滤、范围查询等操作,还能够对向量数据进行更快速的相似性搜索。
2、向量数据库和大模型什么关系?为什么说向量数据库是大模型的黄金搭档?
向量数据库通常被认为是大模型的“海马体”或者“记忆海绵”。
目前的大模型都是预训练模型,对于训练截止日之后发生的事情一无所知。第一是没有实时的数据,第二是缺乏私域数据或者企业数据,向量数据库可以通过存储最新信息或者企业数据有效弥补了这些不足,让大模型突破在时间和空间上的限制,加速大模型落地行业场景。同时,通过向量数据的本地存储,还能够协助解决目前企业界最担忧的大模型泄露隐私的问题。
3、向量数据库背后有哪些核心技术?打造一款向量数据库主要的门槛是什么?
要打造一款高效的向量数据库,背后涉及众多的底层技术,其中主要包括:
向量索引技术:向量索引是向量数据库的核心技术之一,它通过构建高效的索引结构来实现快速的向量检索。常见的向量索引包括FLAT、HNSW、IVF等。
向量相似度计算技术:向量相似度计算是向量数据库的另一个核心技术,它用于度量向量之间的相似度。常见的向量相似度计算方法包括余弦相似度、欧几里得距离等。
Embedding技术:利用Embedding技术将高维度的数据(例如文字、图片、 音频)映射到低维度空间,即把图片、音频和文字转化为向量来表示,将这些向量存储起来就构成向量数据库。
4、向量数据库在LLM中有什么用?目前有哪些典型的落地?
向量数据库可以用于存储和管理大规模的文本向量数据,原始的长文本内容可以通过文本分割转换成文本段,再由Embedding模型生成对应的向量并存储在向量数据库中,从而构建起外部知识库。
在使用LLM进行训练或预测时,可以从向量数据库中快速地加载和查询需要的文本向量数,这些数据可以作为大模型的外部知识输入,帮助大模型生成更加准确、包含更多私域知识的答案。同时,向量数据库还可以使用一些特殊的算法和数据结构,例如向量索引和相似度计算等,来提高LLM的查询精度和效率。目前,向量数据库已经在很多知名的大模型中应用。
5、目前国内外向量数据库市场的情况是怎样的?
据第三方调研数据预测,全球向量数据库到2030年预计将迎来超过500亿美元的市场。国内也将以每年超过20%的速度在增长。目前全球已有的向量数据库产品主要包括 Pinecone、Milvus、Weaviate、Vespa 、Tencent Cloud VectorDB等。其中,超过一半的向量数据库具有云化部署的能力。
6、腾讯发布的向量数据库有哪些核心能力?
腾讯云刚刚发布的向量数据库Tencent Cloud VectorDB主要具备以下能力:
高性能向量存储、检索:腾讯云向量数据库具备高性能的向量存储和检索能力,单索引能够轻松支持10亿级别的向量规模。在分布式弹性扩展的架构下,单实例可支持百万级别QPS,AI场景下向量检索的P99响应延迟可控制在20ms以内,能够覆盖绝大多数AI场景对向量存储和检索的业务需求。
可视化数据管理:在向量存储、检索能力之上,腾讯云向量数据库还提供了可视化的数据管理界面,进一步降低向量数据库的接入和使用门槛。用户可以通过控制台进行数据库、集合层面的数据管理,还可以快速执行向量检索等常用操作。此外,腾讯云向量数据库还提供了可视化的数据上传能力,帮助用户快速构建专属知识库。
一站式向量检索方案:为了进一步提升产品的易用性,腾讯云向量数据库会提供一站式的向量检索方案,实现从文本输入到文本搜索的端到端检索能力,用户可以直接上传.pdf、.txt等原始文本文件,通过平台自动化地执行文本分割、embedding向量化,全托管地完成知识构建和检索任务。
7、腾讯云发布的向量数据库有什么特点?技术架构是什么样的?
Tencent Cloud VectorDB从性能上看,具备高性能、高可用、低成本等优势,比如单索引支持10亿级向量规模,最快支持毫秒级数据实时更新,适用于AI运算、检索,数据接入AI的效率比传统方案提升10倍。
同时,提供多副本高可用特性,提高容灾能力,确保数据库在面临节点故障和负载变化等挑战时仍能正常运行。架构层面支持水平扩展,单实例可支持百亿级向量数据规模,轻松满足AI场景下的向量存储与检索需求。目前已经在腾讯内部近40个业务线上稳定运行,日均处理的搜索请求高达千亿次。
对于企业开发者来说,只需在管理控制台中单击几下,即可快速创建向量数据库实例,全流程平台托管,无需进行任何安装、部署、运维操作,减少机器成本、运维成本、人力成本开销。
此外, VectorDB支持丰富的向量检索能力,用户通过RESTful API即可快速操作数据库,开发效率高。同时控制台提供了完善的数据管理和监控能力,操作简单便捷。
技术架构上,腾讯云向量数据库基于腾讯集团每日处理千亿次检索的向量引擎OLAMA,底层采用Raft分布式存储,通过Master节点进行集群管理和调度,实现系统的高效运行。同时,腾讯云向量数据库支持设置多分片和多副本,进一步提升了负载均衡能力,使得向量数据库能够在处理海量向量数据的同时,实现高性能、高可扩展性和高容灾能力。
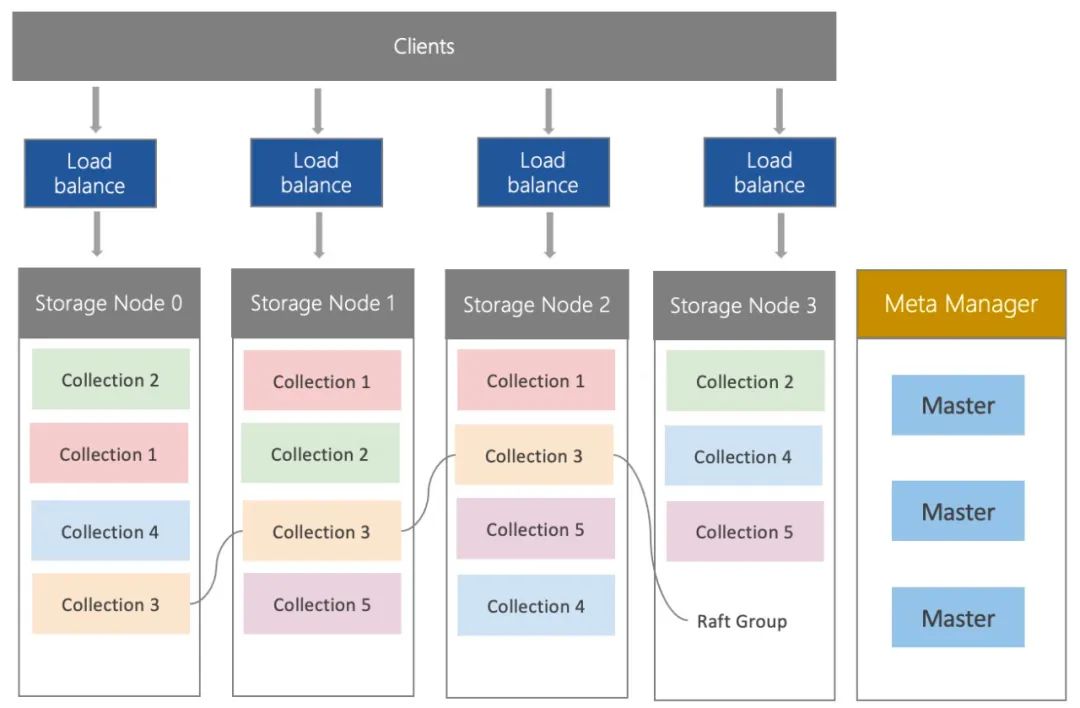
8、腾讯内部有哪些业务已经在使用向量数据库?效果怎么样?
腾讯云向量数据库基于腾讯集团每日处理千亿次检索的向量引擎(OLAMA),经过腾讯内部海量场景的实践,数据接入AI的效率比传统方案提升10倍,运行稳定性高达99.99%,目前已经应用在了腾讯视频、QQ浏览器、QQ音乐等30多款产品中。
腾讯云向量数据库能有效助力产品提升运营效率。
数据显示,使用腾讯云向量数据库后,QQ音乐人均听歌时长提升3.2%、腾讯视频有效曝光人均时长提升1.74%、QQ浏览器成本降低37.9%。
以腾讯视频的应用为例,视频库中的图片、音频、标题文本等内容使用腾讯云向量数据库,月均完成的检索和计算量高达200亿次,有效满足了版权保护、原创识别、相似性检索等场景需求。
9、如何理解腾讯云向量数据库的AI Native开发范式?
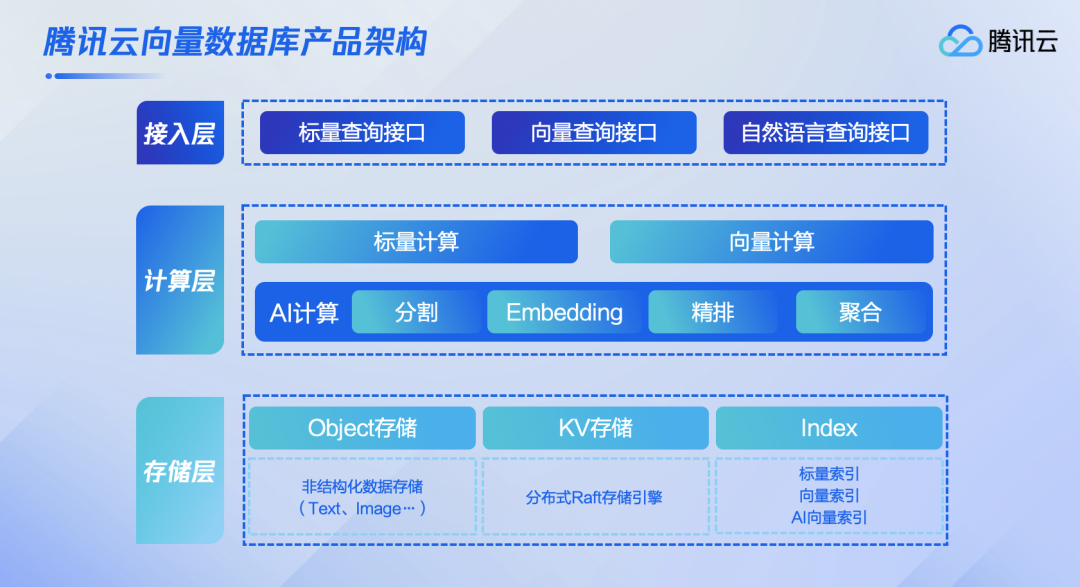
腾讯云向量数据库提供了接入层、计算层、存储层的全面AI化解决方案,使用户在使用向量数据库的全生命周期,都能应用到AI能力。
在接入层,腾讯云向量数据库支持自然语言文本的输入,同时采用“标量+向量”的查询方式,支持全内存索引,最高支持每秒百万的查询量(QPS);在计算层,AI Native开发范式能实现全量数据AI计算,一站式解决企业在搭建私域知识库时的文本切分(segment)、向量化(embedding)等难题;在存储层,腾讯云向量数据库支持数据智能存储分布,助力企业存储成本降低50%。
10、你认为向量数据库赛道未来竞争的核心是什么?
性能上会持续突破,包括能处理百亿甚至千亿条数据量;毫秒级的响应时间和数百万的QPS;更低的成本,在相同资源消耗的情况下提供更强大的性能。此外,在应用场景方面,向量数据库在推荐系统、搜索引擎、图像识别等领域都有着广泛的应用。未来随着新的应用场景的出现,向量数据库需要适应不同的应用场景,提供更加灵活和多样化的解决方案,从而满足不同用户的需求。
评论