
Transformer哪家强?Google爸爸辨优良!

极市导读
Google出面提出了Long Range Arena,试图从核心问题场景长文本分析入手,提出评价模型的6个标准、6大任务,逐一比较各个新兴xformer和原始Transformer的表现。本文展示了6个标准和任务的具体内容以及最终的结果,最终显示各xformer都具有其适合的优势,大家应当根据自己的需求去选择合适的模型。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

2017年Attention is all you need横空出世,Transformer横扫机器翻译,隔年诞生的BERT建立在层层堆叠的Transformer之上,凭借这个平平无奇的Attention点乘模型一举刷新了各种沉积许久的榜单,一夜间仿佛不懂Transformer,都不敢说自己是NLPer了,曾经最心爱的RNN也瞬间黯然失色。
Transformer有着简易的的结构、SOTA的能力,搭配CUDA矩阵并行运算,不仅效果上比RNN胜出一筹,在运算效率上也遥遥领先。于是,无数论文纷至沓来,留给RNN的时间已经不多了。
Reformer (https://arxiv.org/abs/2001.04451):通过Locality Sensitive Hashing类似于桶排序,将相似向量归为一类,计算同类向量之间的点积,复杂度为。 Linformer (https://arxiv.org/abs/2006.04768):认为注意力机制是低秩,信息集中在前k大的奇异值中,通过线性映射将复杂度降为,当足够小,模型接近线性时间。 Sinkhorn Transformers (https://arxiv.org/abs/2002.11296.pdf):将输入分块,并基于Sinkhorn对输入键值对进行重新排序,并应用基于块的局部注意力机制来学习稀疏模式。 Performers (https://arxiv.org/abs/2009.14794):通过正交随机特征算法加速注意力计算,改用Positive Orthogonal Random Features对常规softmax注意力进行鲁棒且无偏的估计。 Synthesizers (https://arxiv.org/abs/2005.00743):没有保持“token对token”形式的注意力形式,抛弃了原有注意力的动态特点,利用线性变换得到注意力矩阵。 Linear Transformers (https://arxiv.org/abs/2006.16236):通过使用核函数并且替换掉SoftMax,来简化Attention的计算过程,使复杂度降至。 BigBird (https://proceedings.neurips.cc//paper/2020/hash/c8512d142a2d849725f31a9a7a361ab9-Abstract.html):在Longformer的滑动窗口和膨胀窗口的基础上增加了Random attention,当前长序列建模的SOTA,刷新了QA和摘要的SOTA,同时也被证明是图灵完备的。
6个标准
通用性:所有Transformer都能使 简易性:无需数据增强、预训练等繁琐的准备步骤 挑战性:任务足够难,人人都90%+就没意思了(能卷起来) 长输入:Long Range Arena,输入自然要长一点,测试场景就是长输入下的表现 多方面:方方面面都需要考察到,如长距离依赖、泛化能力等等 轻计算:“妈妈再也不用担心我没有工业级显卡了”
6个任务
Long ListOps
 这个任务看起来神似前缀表达式,考虑
这个任务看起来神似前缀表达式,考虑max、min、median、sum_mod四种运算外带括号形成的hierarchical structure,考察xformer对长序列层次结构的理解能力。Byte-level Text Classification、Byte-level Document Retrieval这两个任务主要关注对长文本的概括能力,测试xformer能否提取到长文本的足够信息量用于分类和匹配,值得注意的是,Google选取了Byte-level的输入,即字符级别的输入,轻松构造出长达4k的输入。
Image Classification on Sequences of PixelsGoogle还企图将Transformer用于CV的任务中,这个任务将的图片拉成的像素序列,当作文本去做分类任务。因为输入直接抹去了二维信息,这个任务不仅考察了xformer对序列特征的捕捉能力,同时考察了对层次结构的感知力。
PathFinder (Long-Range Spatial Dependency)、PathFinder-X (Long-Range Spatial Dependencies with Extreme Lengthts)


结果!
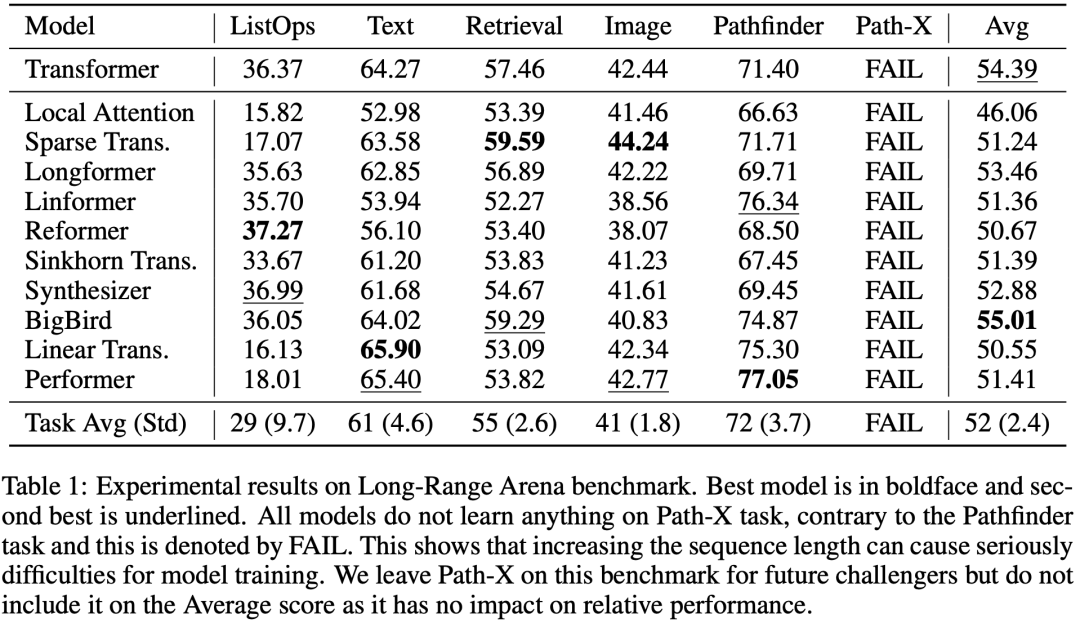
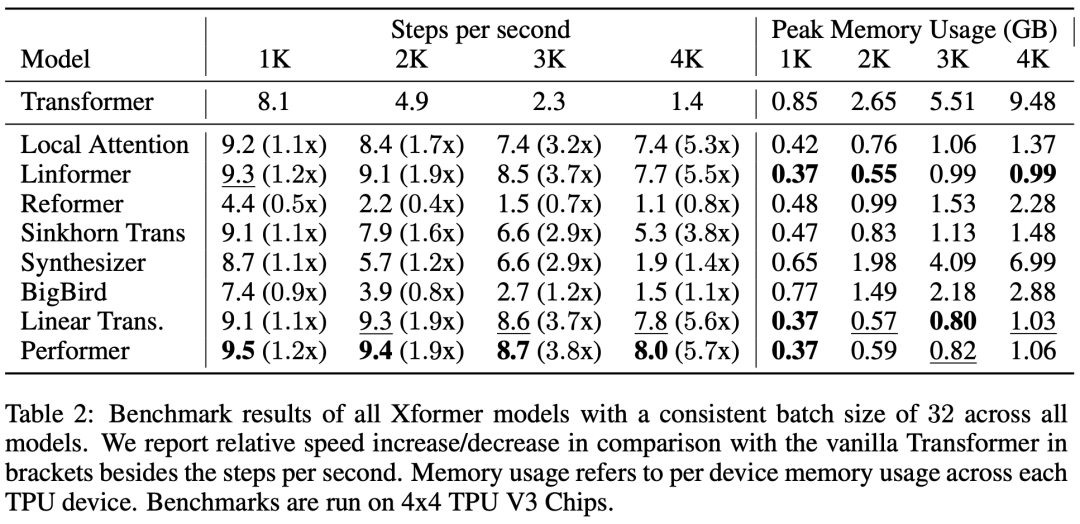
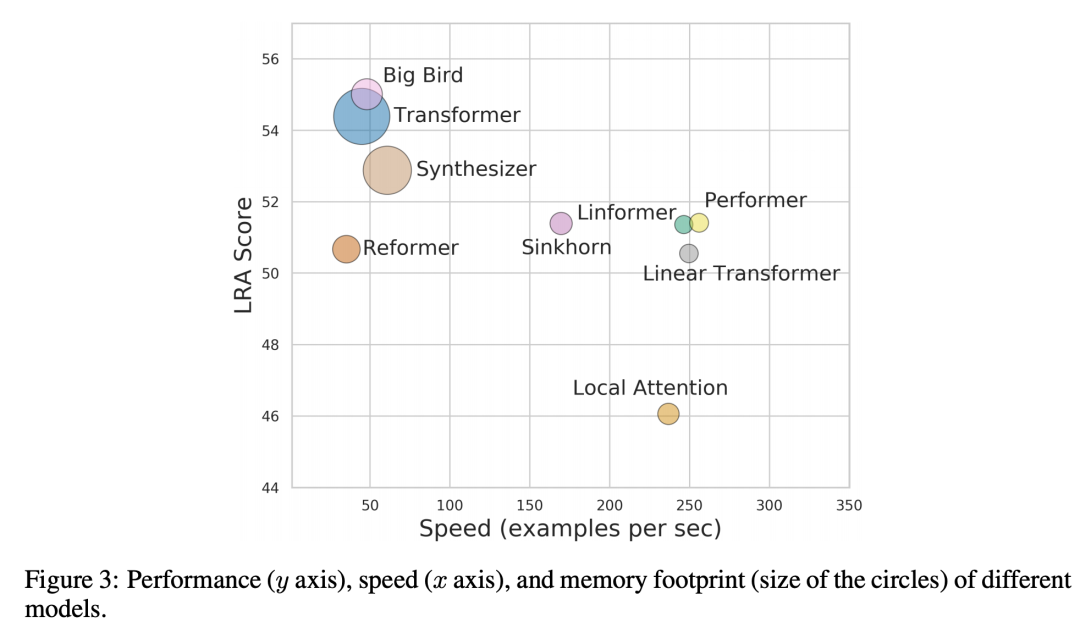
有的模型在个别任务上表现惊艳,却无法兼顾所有,例如Performers和Linear Transformers,虽然个别任务上相比原始Transformer有所下降,但是速度上提升极大 有的模型在各个任务上平均成绩出色,却一个第一也拿不到,例如BigBird,虽然号称线性复杂度,但是在实际测试环境中速度和原始Transformer差不多,性能却得到了一定的加强。 有的模型利用了复杂的技巧,但是速度却没有优势,性能可能有明显的下降,例如reformer、synthesizer。
推荐阅读
卷积神经网络与Transformer结合,东南大学提出视频帧合成新架构 2020 谷歌最新研究综述:Efficient Transformers: A Survey 丢弃Transformer,FCN也可以实现E2E检测
