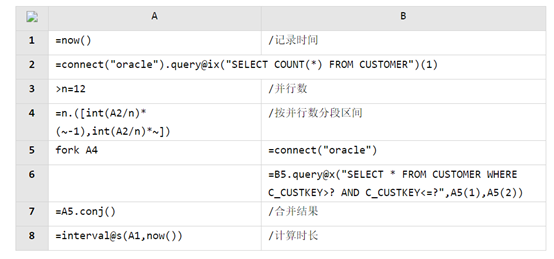
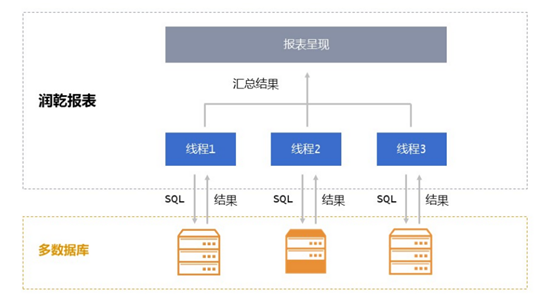
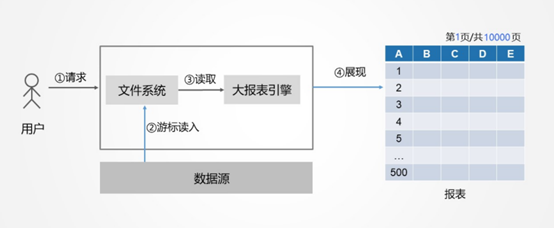
从前面所述的几个优化过程中可以看出,大部分性能问题,都是在报表工具外做的优化,数据准备在报表外,数据传输在报表外,表内计算慢时,大部分也可以挪到报表外,只有呈现这一个环节是报表内的所以单凭一个报表工具想完全解决报表的性能问题是不太可能的,要真正彻底的解决性能难题,除了看报表本身的性能外,更需要重点看工具有没有外围的计算引擎来协助,报表本身能力强,又有计算引擎帮忙(类似内置了开源 SPL 的润乾报表),一套组合拳打下来,报表性能问题才能真正解决如果报表工具本身性能就很普通,还没有其他计算引擎辅助,那是谁也不可能把老爷车的发动机优化到 F1 赛车的马力的




 下载APP
下载APP