
2022春节贺岁档电影开分,水门桥不理想,四海崩了!用Python一探究竟
↑ 关注 + 星标 ,每天学Python新技能
↑ 关注 + 星标 ,每天学Python新技能
后台回复【大礼包】送你Python自学大礼包
后台回复【大礼包】送你Python自学大礼包
尽管受到疫情影响,部分地区被迫关闭了电影院,但从大年初一中国影史第二单日总票房的数据来看,2022 年春节期间大家的观影热情还是十分高涨的。
大年初一上映当天,从票房数据来看,《长津湖之水门桥》一马当先,《四海》《这个杀手不太冷静》《奇迹·笨小孩》你追我赶,动画片《熊出没》表现强势,《狙击手》令人遗憾。
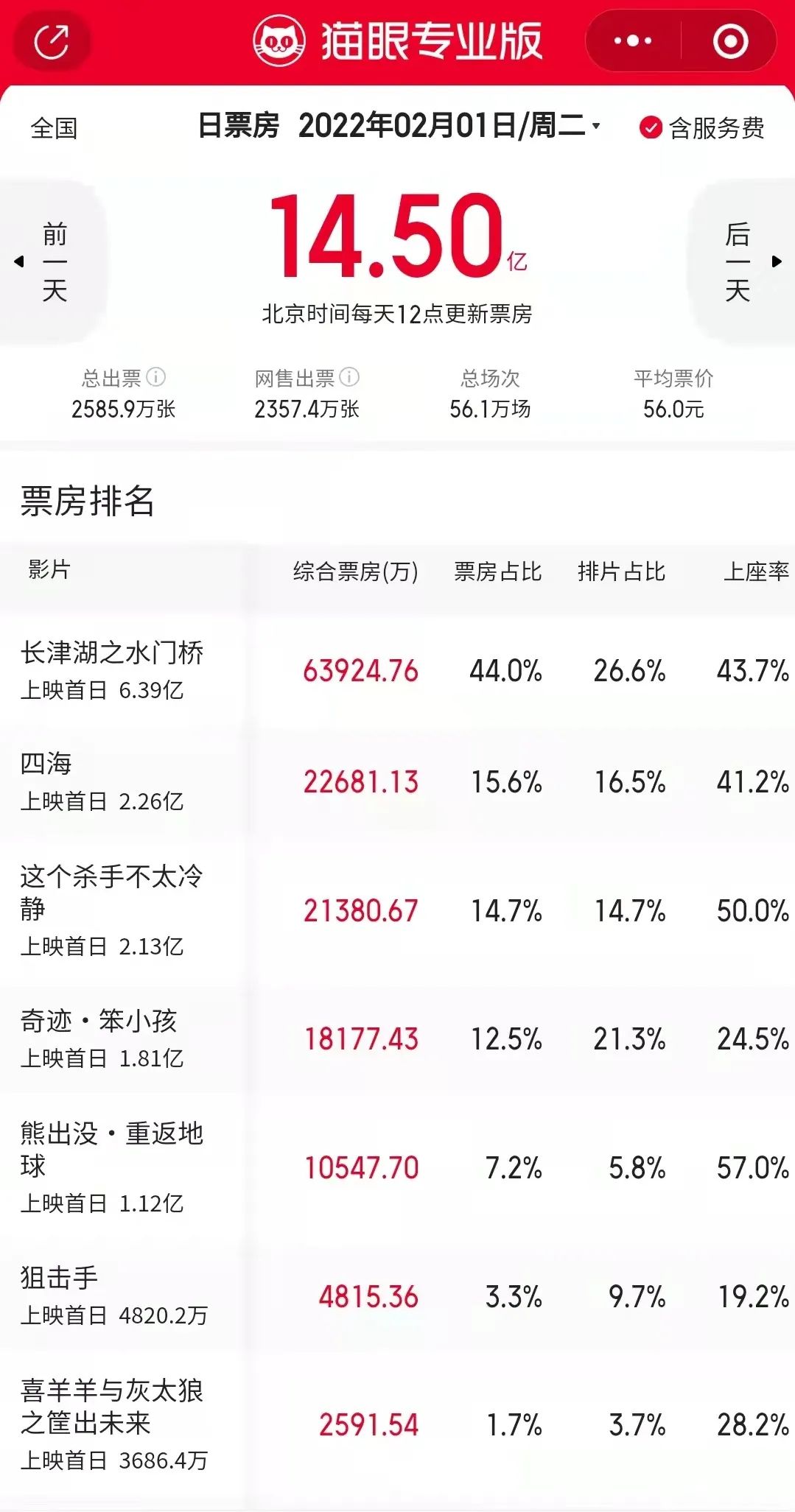
目前,几部真人电影豆瓣已经开分了。

本文我们用 Python 爬取这几部豆瓣开分的电影评论,爬取的具体分析过程这里就不说了,不了解的可以参考一下:豆瓣影评爬取参考,主要实现代码如下:
def spider():
url = 'https://accounts.douban.com/j/mobile/login/basic'
headers = {"User-Agent": 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)'}
# 龙岭迷窟网址,为了动态翻页,start 后加了格式化数字,短评页面有 20 条数据,每页增加 20 条
url_comment = 'https://movie.douban.com/subject/35215390/comments?start=%d&limit=20&sort=new_score&status=P'
data = {
'ck': '',
'name': '用户名',
'password': '密码',
'remember': 'false',
'ticket': ''
}
session = requests.session()
session.post(url=url, headers=headers, data=data)
# 初始化 4 个 list 分别存用户名、评星、时间、评论文字
users = []
stars = []
times = []
content = []
# 抓取 500 条,每页 20 条,这也是豆瓣给的上限
for i in range(0, 500, 20):
# 获取 HTML
data = session.get(url_comment % i, headers=headers)
# 状态码 200 表是成功
print('第', i, '页', '状态码:',data.status_code)
# 暂停 0-1 秒时间,防止IP被封
time.sleep(random.random())
# 解析 HTML
selector = etree.HTML(data.text)
# 用 xpath 获取单页所有评论
comments = selector.xpath('//div[@class="comment"]')
# 遍历所有评论,获取详细信息
for comment in comments:
# 获取用户名
user = comment.xpath('.//h3/span[2]/a/text()')[0]
# 获取评星
star = comment.xpath('.//h3/span[2]/span[2]/@class')[0][7:8]
# 获取时间
date_time = comment.xpath('.//h3/span[2]/span[3]/@title')
# 有的时间为空,需要判断下
if len(date_time) != 0:
date_time = date_time[0]
date_time = date_time[:10]
else:
date_time = None
# 获取评论文字
comment_text = comment.xpath('.//p/span/text()')[0].strip()
# 添加所有信息到列表
users.append(user)
stars.append(star)
times.append(date_time)
content.append(comment_text)
# 用字典包装
comment_dic = {'user': users, 'star': stars, 'time': times, 'comments': content}
# 转换成 DataFrame 格式
comment_df = pd.DataFrame(comment_dic)
# 保存数据
comment_df.to_csv('data.csv')
有了评论数据,我们再通过词云直观的感受一下,主要代码实现如下:
df = pd.read_csv("comment.csv", index_col = 0)
cts_list = df['comments'].values.tolist()
cts_str ="".join([str(i).replace('\n', '').replace(' ', '') for i in cts_list])
stop_words = []
with open('stop_words.txt', 'r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
stop_words.append(line.strip())
# jieba 分词
word_list = jieba.cut(cts_str)
words = []
for word in word_list:
if word not in stop_words:
words.append(word)
cts_str = ','.join(words)
print(cts_str)
stylecloud.gen_stylecloud(text=cts_str, max_words=300,
collocations=False,
font_path="SIMLI.TTF",
icon_name="fas fa-arrow-circle-right",
size=800,
output_name="comment.png")
Image(filename="comment.png")
首先我们来看《四海》,《四海》的口碑为什么没有纵横四海?看看观众怎么说的:

接着看《这个杀手不太冷静》,作为一部喜剧片,豆瓣这个评分还算可以,看看观众怎么说的:

再接着看《长津湖之水门桥》,目前评分是低于第一部的,看看观众怎么说的:

再接着看《奇迹·笨小孩》,评分和票房都算是中规中矩,看看观众怎么说的:

再接着看《狙击手》,国师父女指导,票房不佳,评分暂列第一,看看观众怎么说的:

源码已经打包整理好了,有需要的小伙伴可以在下方公众号Python高手之旅后台(非本号)回复水门桥直接获取~
推荐阅读
您看此文用 
分

秒,转发只需1秒哦
评论