
HTTP/2协议“多路复用”实现原理
1.HTTP/2较HTTP/1.1优化亮点
HTTP/2是一个二进制协议,其基于“帧”的结构设计,改进了很多HTTP/1.1痛点问题。下面列举一些最常被津津乐道的改进之处:
多路复用的流
头部压缩
资源优先级和依赖设置
服务器推送
流量控制
重置消息
以上列举的每一项都值得做深入细致的研究,这里就只针对“多路复用”功能的实现进行深入的学习。
2.“多路复用”的原理解析
2.1 什么是多路复用?
网络上有一张图能清晰的解释这个问题:
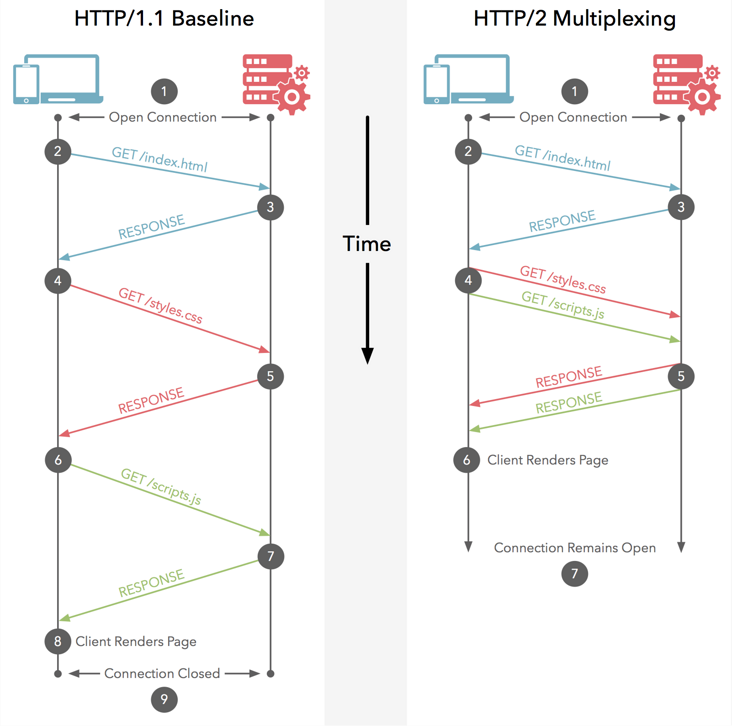
HTTP/1.1协议的请求-响应模型大家都是熟悉的,我们用“HTTP消息”来表示一个请求-响应的过程,那么HTTP/1.1中的消息是“管道串形化”的:只有等一个消息完成之后,才能进行下一条消息;而HTTP/2中多个消息交织在了一起,这无疑提高了“通信”的效率。这就是多路复用:在一个HTTP的连接上,多路“HTTP消息”同时工作。
2.2 为什么HTTP/1.1不能实现“多路复用”?
简单回答就是:HTTP/2是基于二进制“帧”的协议,HTTP/1.1是基于“文本分割”解析的协议。
看一个HTTP/1.1简单的GET请求例子:
GET / HTTP/1.1
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Accept-Encoding:gzip, deflate, br
Accept-Language:zh-CN,zh;q=0.9,en;q=0.8
Cache-Control:max-age=0
Connection:keep-alive
Cookie:imooc_uuid=b2076a1d-6a14-4cd5-91b0-17a9a2461cf4; imooc_isnew_ct=1517447702; imooc_isnew=2; zg_did=%7B%22did%22%3A%20%221662d799f3f17d-0afe8166871b85-454c092b-100200-1662d799f4015b%22%7D; loginstate=1; apsid=Y4ZmEwNGY3OTUwMTdjZTk0ZTc4YzBmYThmMDBmZDYAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAANDEwNzI4OQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA5NTMzNjIzNjVAcXEuY29tAAAAAAAAAAAAAAAAAAAAADBmNmM5MzczZTVjMTk3Y2VhMDE2ZjUxNmQ0NDUwY2IxIDPdWyAz3Vs%3DYj; Hm_lvt_fb538fdd5bd62072b6a984ddbc658a16=1541222935,1541224845; Hm_lvt_f0cfcccd7b1393990c78efdeebff3968=1540010199,1541222930,1541234759; zg_f375fe2f71e542a4b890d9a620f9fb32=%7B%22sid%22%3A%201541297212384%2C%22updated%22%3A%201541297753524%2C%22info%22%3A%201541222929083%2C%22superProperty%22%3A%20%22%7B%5C%22%E5%BA%94%E7%94%A8%E5%90%8D%E7%A7%B0%5C%22%3A%20%5C%22%E6%85%95%E8%AF%BE%E7%BD%91%E6%95%B0%E6%8D%AE%E7%BB%9F%E8%AE%A1%5C%22%2C%5C%22%E5%B9%B3%E5%8F%B0%5C%22%3A%20%5C%22web%5C%22%7D%22%2C%22platform%22%3A%20%22%7B%7D%22%2C%22utm%22%3A%20%22%7B%7D%22%2C%22referrerDomain%22%3A%20%22%22%2C%22cuid%22%3A%20%22Jph3DQ809OQ%2C%22%7D; PHPSESSID=h5jn68k1fcaadn61bpoqa9hch2; cvde=5be7a057c314b-1; IMCDNS=1
Host:www.imooc.com
Referer:https://www.imooc.com/
Upgrade-Insecure-Requests:1
User-Agent:Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36以上就是HTTP/1.1发送请求消息的文本格式:以换行符分割每一条key:value的内容,解析这种数据用不着什么高科技,相反的,解析这种数据往往速度慢且容易出错。“服务端”需要不断的读入字节,直到遇到分隔符(这里指换行符,代码中可能使用/n或者/r/n表示),这种解析方式是可行的,并且HTTP/1.1已经被广泛使用了二十多年,这事已经做过无数次了,问题一直都是存在的:
一次只能处理一个请求或响应,因为这种以分隔符分割消息的数据,在完成之前不能停止解析。
解析这种数据无法预知需要多少内存,这会带给“服务端”很大的压力,因为它不知道要把一行要解析的内容读到多大的“缓冲区”中,在保证解析效率和速度的前提下:内存该如何分配?
2.3 HTTP/2帧结构设计和多路复用实现
前边提到:HTTP/2设计是基于“二进制帧”进行设计的,这种设计无疑是一种“高超的艺术”,因为它实现了一个目的:一切可预知,一切可控。
帧是一个数据单元,实现了对消息的封装。下面是HTTP/2的帧结构:
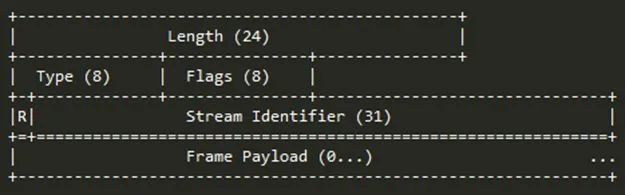
帧的字节中保存了不同的信息,前9个字节对于每个帧都是一致的,“服务器”解析HTTP/2的数据帧时只需要解析这些字节,就能准确的知道整个帧期望多少字节数来进行处理信息。我们先来了解一下帧中每个字段保存的信息:
| 名称 | 长度 | 描述 |
|---|---|---|
| Length | 3 字节 | 表示帧负载的长度,默认最大帧大小2^14 |
| Type | 1 字节 | 当前帧的类型,下面会做介绍 |
| Flags | 1 字节 | 具体帧的标识 |
| R | 1 字节 | 保留位,不需要设置,否则可能带来严重后果 |
| Stream Identifier | 31 位 | 每个流的唯一ID |
| Frame Payload | 不固定 | 真实帧的长度,真实长度在Length中设置 |
如果使用HTTP/1.1的话,你需要发送完上一个请求,才能发送下一个;由于HTTP/2是分帧的,请求和响应可以交错甚至可以复用。
为了能够发送不同的“数据信息”,通过帧数据传递不同的内容,HTTP/2中定义了10种不同类型的帧,在上面表格的Type字段中可对“帧”类型进行设置。下表是HTTP/2的帧类型:
| 名称 | ID | 描述 |
|---|---|---|
| DATA | 0x0 | 传输流的核心内容 |
| HEADERS | 0x1 | 包含HTTP首部,和可选的优先级参数 |
| PRIORITY | 0x2 | 指示或者更改流的优先级和依赖 |
| RST_STREAM | 0x3 | 允许一端停止流(通常是由于错误导致的) |
| SETTINGS | 0x4 | 协商连接级参数 |
| PUSH_PROMISE | 0x5 | 提示客户端,服务端要推送些东西 |
| PING | 0x6 | 测试连接可用性和往返时延(RTT) |
| GOAWAY | 0x7 | 告诉另外一端,当前端已结束 |
| WINDOW_UPDATE | 0x8 | 协商一端要接收多少字节(用于流量控制) |
| CONTINUATION | 0x9 | 用以拓展HEADER数据块 |
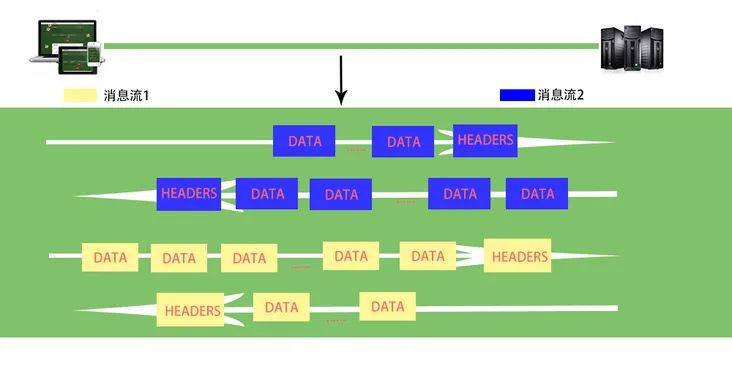
有了以上对HTTP/2帧的了解,我们就可以解释多路复用是怎样实现的了,不过在这之前我们先来了解“流”的概念:HTTP/2连接上独立的、双向的帧序列交换。流ID(帧首部的6-9字节)用来标识帧所属的流
下面两张图分别表示了HTTP/2协议上POST请求数据流“复用”的过程,很容易看的明白:
3. 更多特性与简介
由于HTTP/2消息中“帧”的设计,客户端和服务端在通信的过程中能够彼此了解更多的信息。下面再简单说一下其他几点比较重要的特性,算是一个学习引导方向吧。
3.1 流量控制
HTTP/2的新特性之一是基于流的流量控制。不同于HTTP/1.1,只要客户端可以处理,服务端就会尽可能快的发送数据,HTTP/2提供了客户端调整传输速度的能力(服务端也可以)。WINDOW_UPDATE帧用来完成这件事情,每个帧告诉对方,发送方想要接收多少字节,它将发送一个WINDOW_UPDATE帧以指示其更新后的处理字节能力。
3.2 设置资源优先级和依赖关系
流的一个重要特性是可以设置优先级和资源数据的依赖关系。HTTP/2通过流的依赖可以实现这些功能。通过HEADERS帧和PRIORITY帧,客户端可以明确的告诉服务端它最需要什么,这是通过声明依赖关系和权重实现的。
依赖关系为客户端提供了一种能力,通过指明某些对象对另外一些对象的依赖,告知服务器哪些资源应该被优先传输。
权重让客户端告诉服务器如何具体确定具有共同依赖关系对象的优先级。
3.3 服务端推送
《孙子兵法》中有一句名言:“兵马未到,粮草先行”。服务端推送功能就可以实现这样一个功能。当页面还没有开始请求具体的资源时,服务端就已经把一些资源(像css和js)已经推送到客户端了。当浏览器要渲染页面时,资源已经在缓存中了,听起来是一件很酷的事情,实际上也正是这样。服务端推送是通过PUSH_PROMISE帧实现的,当然其实现的细节是非常复杂的,感兴趣的同学可以研究一下。
HTTP/2的“多路复用”问题已经说明白了,还补充了一些新特性的介绍。当然想要深入了解HTTP/2的一些原理,有太多太多的内容需要阅读,实践。比如“首部压缩”算法HPACK是HTTP/2的关键元素之一,是HTTP/2制定开发组长时间的研究成果,其思想内容也是特别值得学习借鉴的。本节所设计到的东西只是HTTP/2协议中的冰山一角,RFC7540可以帮助你充分了解该协议的方方面面。
❤️爱心三连击
1.看到这里了就点个在看支持下吧,你的「点赞,在看」是我创作的动力。
2.关注公众号
前端名狮,回复「1」加入前端交流群,一起学习进步!3.也可添加微信【qq1248351595】,一起成长。
“在看转发”是最大的支持