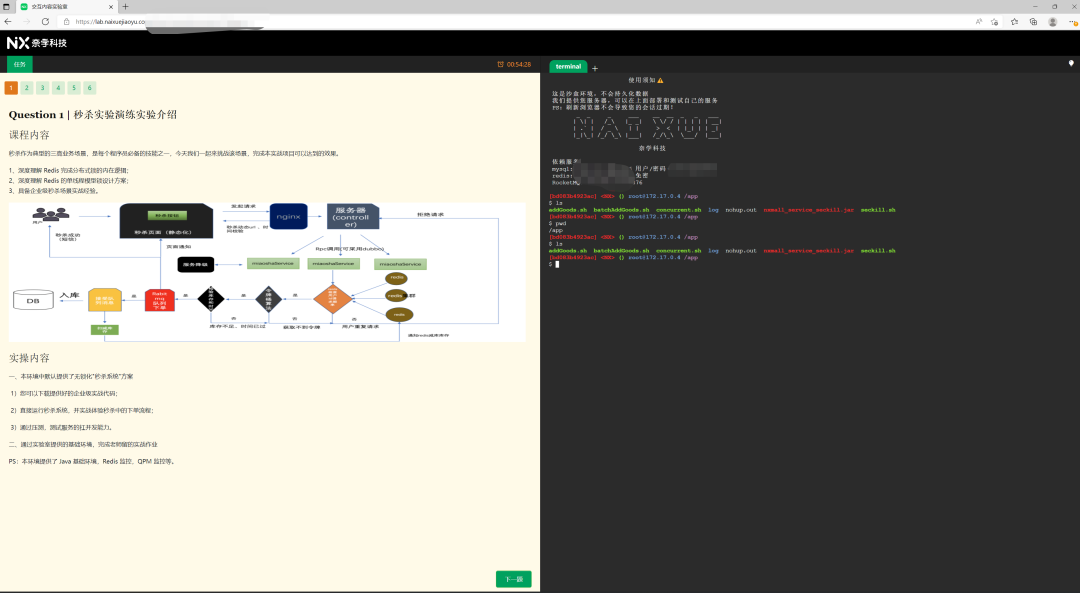
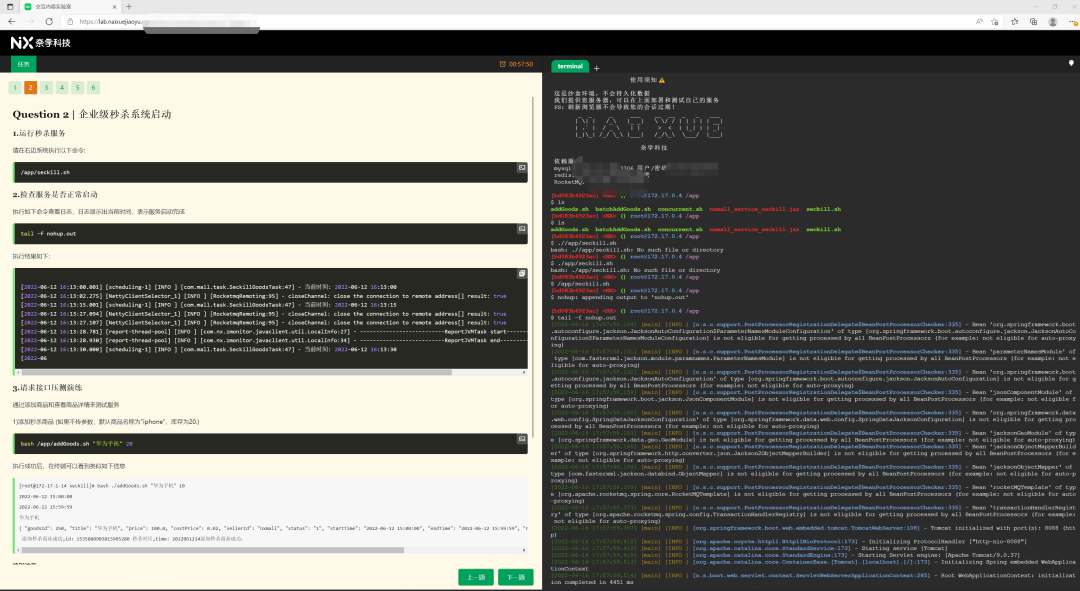
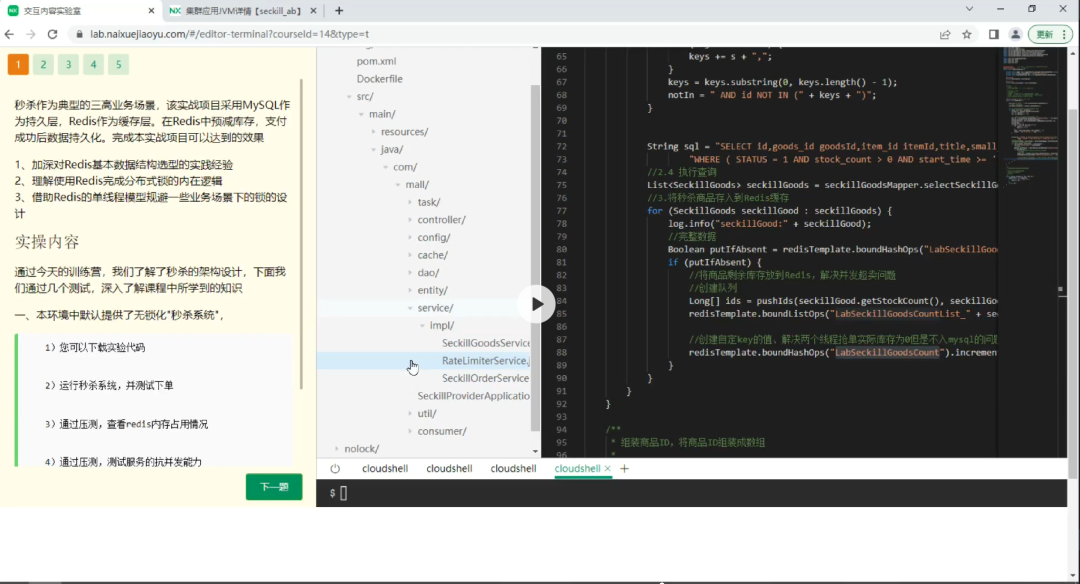
想要搞透一套架构方案,最根本的方法,就是去实践它。
可是,大部分程序员,遇不到这样的业务,接触不到这样的场景啊,怎么办呢?
有个朋友自动化的搭了一套,能让所有人瞬间体验与调优高并发的秒杀架构,分享给大家!
第一,将请求尽量拦截在系统上游,而不要让锁冲突落到数据库。传统秒杀系统之所以挂,是因为请求都压到了后端数据层,数据读写锁冲突严重,并发高响应慢,几乎所有请求都超时,访问流量大,下单成功的有效流量小。(2)余票查询,读,量大;
(3)下单和支付,写,量小;
秒杀业务,常见的系统分层架构如何?
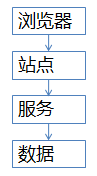
秒杀业务,可以使用典型的服务化分层架构,这四层分别应该如何优化呢?JS层面,可以限制用户在x秒之内只能提交一次请求,从而降低系统负载。
APP层面,可以做类似的事情,虽然用户疯狂的在摇微信抢红包,但其实x秒才向后端发起一次请求。
画外音:这就是所谓的“将请求尽量拦截在系统上游”,浏览器/APP层就能拦截80%+的请求。如何抗住程序员写for循环调用http接口,首先要确定用户的唯一标识,对于频繁访问的用户予以拦截。在站点层,对同一个uid的请求进行计数和限速,例如:一个uid,5秒只准透过1个请求,这样又能拦住99%的for循环请求。一个uid,5s只透过一个请求,其余的请求怎么办?缓存,页面缓存,5秒内到达站点层的其他请求,均返回上次返回的页面。服务层非常清楚业务的库存,非常清楚数据库的抗压能力,可以根据这两者进行削峰限速。例如,业务服务很清楚的知道,一列火车只有2000张车票,此时透传10w个请求去数据库,是没有意义的。画外音:假如数据库每秒只能抗500个写请求,就只透传500个。对于写请求,做请求队列,每次只透传有限的写请求去数据层(下订单,支付这样的写业务)。
只有2000张火车票,即使10w个请求过来,也只透传2000个去访问数据库:
(1)如果前一批请求均成功,再放下一批;
(2)如果前一批请求库存已经不足,则后续请求全部返回“已售罄”;
cache抗,不管是memcached还是redis,单机抗个每秒10w应该都是没什么问题的。如此削峰限流,只有非常少的写请求,和非常少的读缓存mis的请求会透到数据层去,又有99%的请求被拦住了。(1)浏览器拦截了80%请求;
(2)站点层拦截了99%请求,并做了页面缓存;
(3)服务层根据业务库存,以及数据库抗压能力,做了写请求队列与数据缓存;
你会发现,每次透传到数据库层的请求都是可控的。db基本就没什么压力了,闲庭信步。画外音:这类业务数据量不大,无需分库,数据库做一个高可用就行。按照上面的优化方案,其实压力最大的反而是站点层,假设真实有效的请求数是每秒100w,这部分的压力怎么处理?
(1)站点层水平扩展,通过加机器扩容,一台抗5W,20台搞定;那如何动手体验秒杀业务,搭建一套微服务分层秒杀系统架构呢?
(1)首先,在云上购买硬件资源;
(2)接着,搭建底层基础组件:存储系统(MySQL、MongoDB、TiDB等)、高性能缓存系统(Redis等)、高可靠消息系统(RocketMQ、Kafka、Pulsar等)、搜索引擎系统(Elasticsearch、Solr等)等众多基础组件;(3)第三步,搭建微服务管理平台:Docker 容器、Kubernetes管理平台等高并发弹性伸缩容器管理平台、CI/CD等开发部署一体化平台;
(4)第四步,搭建微服务分层架构:低代码微服务的秒杀业务架构设计、代码落地、测试验证;(5)第五步,调优三高设计:实施高性能、高可用、高可靠等设计保证,确保秒杀系统健壮性;(6)最后,搭建可视化性能管理后台:通过立体多维度可视化的方式就能方便看到系统全链路吞吐量情况,流量情况;画外音:抛开几十万的机器成本,全栈的20人架构团队,一年差不多能搭建一个雏形。
有没有快速体验的方法呢?
为了让更多的童鞋能快速体验“秒杀”系统架构,我的朋友@玄姐 创办了奈学,并带队经过2年的重金研发,独家打造了一套,工业级“秒杀架构”实验室,整合了上述所有功能,用户仅需要打开一个网页,就能体验并编码调优“秒杀架构”:(2)右侧:terminal直连服务器,可以操作ng,web-server,service等,可以直接修改代码,对架构进行调优;(3)同时:还有后台对架构进行管理,以及可视化监控。图二:左侧-操作说明,右侧-一键自动化搭建架构,查看日志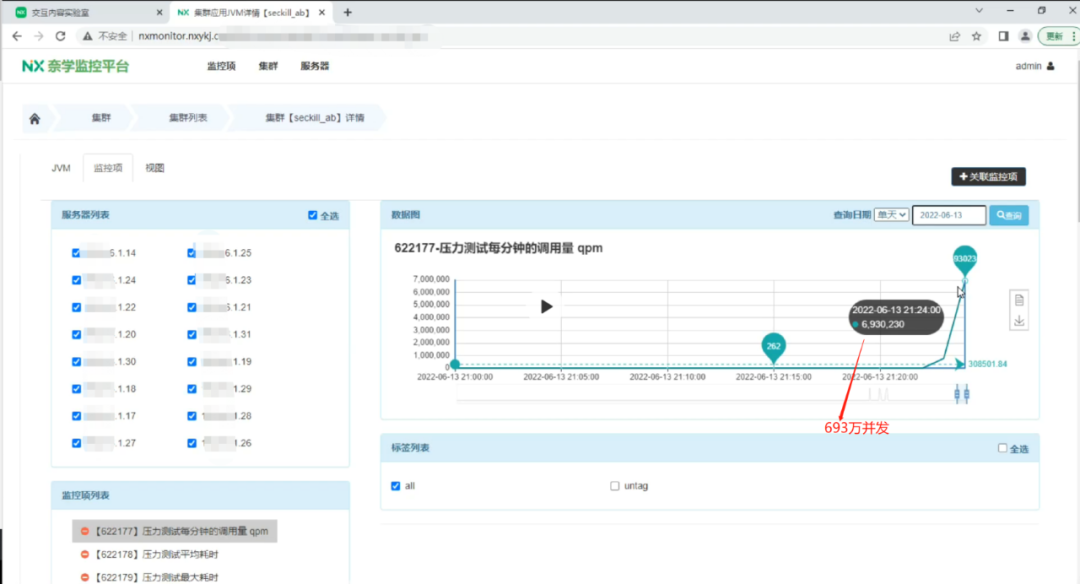 图四:可视化平台说明一下,由于工程级“秒杀架构”需要的服务器资源较大,账号有限,仅限前100人。阅读原文,立刻参与,亲自动手写代码优化,实战工业级“秒杀架构”。
图四:可视化平台说明一下,由于工程级“秒杀架构”需要的服务器资源较大,账号有限,仅限前100人。阅读原文,立刻参与,亲自动手写代码优化,实战工业级“秒杀架构”。