
超融合数据中心网络技术
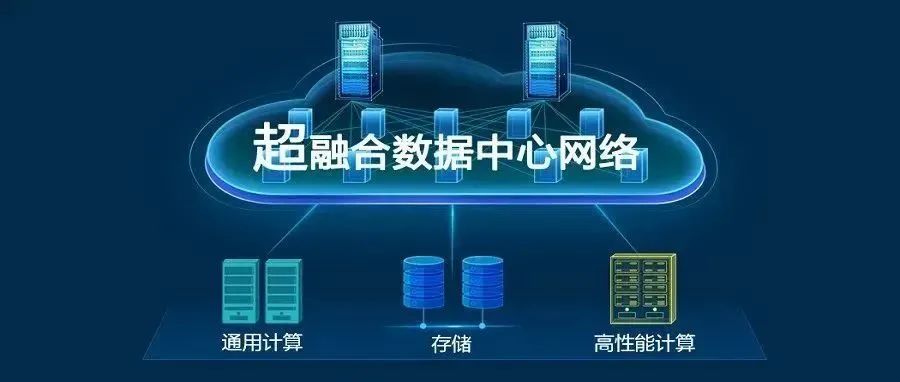

摘要:现如今,数据中心正成为算力中心,为千行百业提供数字化底座,并基于海量数据挖掘其中的商业价值。超融合数据中心网络以全无损以太网来构建新型的数据中心网络,使通用计算、高性能计算、存储三大业务均能融合部署在同一张以太网上,同时实现全生命周期自动化和全网智能运维,可在服务器规模不变的情况下,显著提升数据中心的整体算力水平。
01 智能时代促使数据中心向算力中心演进
人类社会正迈入万物感知、万物互联、万物智能的智能时代,物联网、大数据、5G、AI等新技术和各类创新应用层出不穷。
我国在《中华人民共和国国民经济和社会发展第十四个五年规划和2035年远景目标纲要》中再一次明确了“加快数字化发展,打造数字经济新优势,协同推进数字产业化和产业数字化转型,加快数字社会建设步伐,提高数字政府建设水平,营造良好数字生态,建设数字中国”的战略方针。
作为构建数字化社会的信息基石——数据中心,他承担着各类应用的数据存储、数据分析与数据计算的重任。从数据中挖掘商业价值已成为企业经营的核心任务之一,因此数据中心也越来越聚焦对数据的高效处理,这种处理能力我们通常称为“算力”。算力成为衡量现代数字生产力的重要指标。大家熟知的人脸识别、无人驾驶汽车、智慧工厂等,其背后都是数据中心对数字基础设施的高效整合与使用,并将其转化为某种应用维度的算力。从这个意义上说,数据中心又可以被称为“算力中心”。
数据中心算力是服务器对数据进行处理后实现结果输出的能力,这是数据中心内计算、存储、网络三大资源协同能力的综合衡量指标。
根据ODCC(Open Data Center Committee,开放数据中心委员会)的定义,数据中心算力指标包含4大核心要素,即:通用计算能力、高性能计算能力、存储能力、网络能力。在服务器规模不变的情况下,提升网络能力可显著改善数据中心单位能耗下的算力水平。
02 什么是超融合数据中心网络
数据中心内存在三大资源区:通用计算区、高性能计算(HPC)区和存储区。
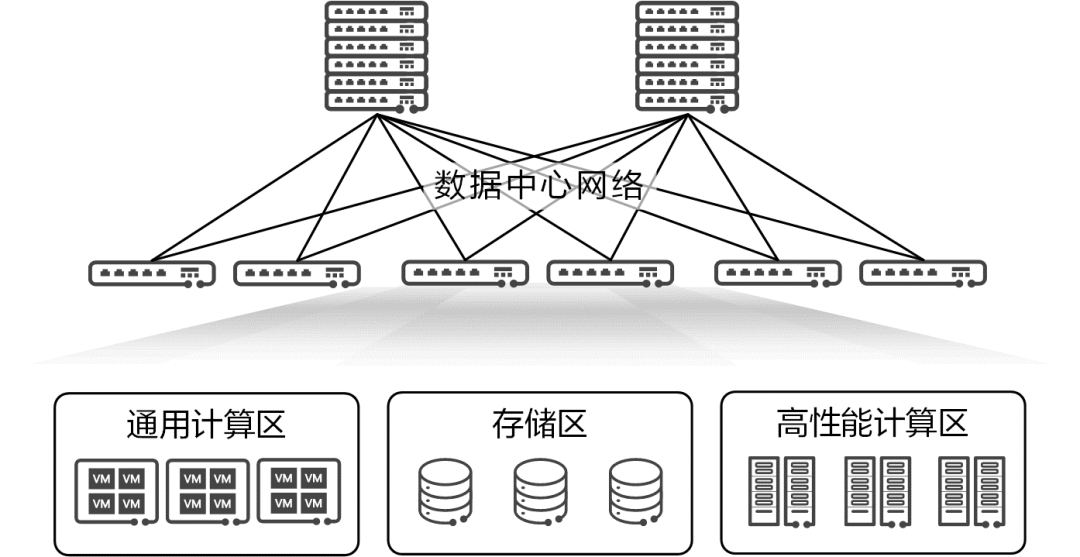
通用计算区:与数据中心外部的用户对接,提供指定的应用服务。这个区域中的服务器大量使用虚拟化、容器等技术,形成灵活的资源池来承载应用。本区域中的网络被称为应用网络、业务网络或前端网络,当前部署的是以太网。 高性能计算区:配备了专用的高性能单元(如CPU、GPU)的服务器,完成指定的高性能计算任务或AI训练。这个区域中的服务器一般很少使用虚拟技术。本区域中的网络被称为高性能计算互联网络,当前部署的是IB(InfiniBand)网络。 存储区:采用专用的存储服务器,对各类数据进行存储、读写和备份。本区域中的网络一般被称为存储网络,通常部署的是FC(Fibre Channel)网络。
算力持续稳定的输出,离不开三大资源区的相互配合。作为联接数据中心各类资源的大动脉,数据中心网络承载着保障数据高效流通的职责。
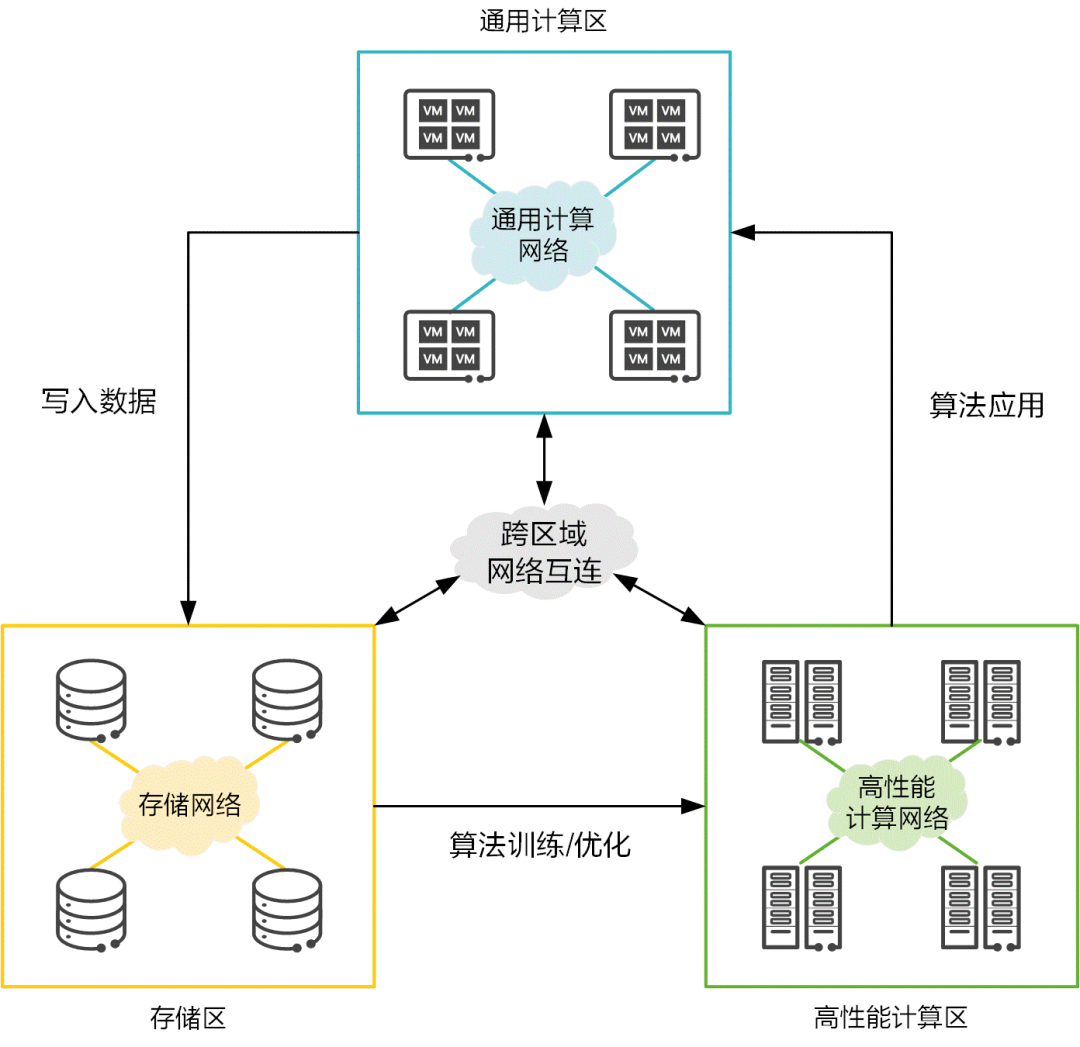
当前,通用计算区部署的传统以太网、高性能计算区部署的IB网、存储区部署的FC网,是三张异构网络,他们协议各异、架构割裂,带来了运维困难、专网生态封闭、成本高、无法实现全生命周期管理等问题。数据中心里这三张网络的融合,成为算力提升的必然要求。
华为超融合数据中心网络以全无损以太网来构建新型的数据中心网络,使通用计算、高性能计算、存储三大业务均能融合部署在同一张以太网上,同时实现全生命周期自动化和全网智能运维。
当前一些新兴的应用,如区块链、工业仿真、人工智能、大数据等,基本都建立在云计算的底座中。近些年,企业各类业务上云的步伐不断加速,云可以提供按需自助服务、快速弹性伸缩、多租户安全隔离、降低项目前期投资等价值优势。另外,在企业的数字化转型中,以金融和互联网企业为代表,大量的应用系统逐渐迁移到分布式系统上,也就是通过海量的 PC 平台来替代传统的小型机。这么做带来了高性价比、易扩展、自主可控等好处,但分布式系统架构同时也带来了服务器节点之间大量的网络互通需求。以太网已经成为云化分布式场景中的事实网络标准:
以太网已具有很高的开放性,可以与各种云融合部署、可被云灵活调用管理。
以太网具有很好的扩展性、互通性、弹性、敏捷性和多租户安全能力。
以太网可以满足新业务超大带宽的需求。
以太网从业人员多,用户基础好。
而传统数据中心高性能计算使用的 IB 网络,以及集中式存储使用的 FC 网络,生态封闭,资源割裂,演进缓慢,已无法匹配云化的发展诉求。根据 IDC 数据显示,近年来 FC 和 IB 市场逐步萎缩,数据中心的云化趋势助长了对以太网的需求,以太网是当前以及未来主要的数据中心内部网络互联技术。
以人工智能为代表的一系列创新应用正在快速发展,而人工智能后台算法依赖海量的样本数据和高性能的计算能力。为了满足海量数据训练的大算力要求,一方面可以提升 CPU 单核性能,但是目前单核芯片工艺在 3nm 左右,且成本较高;另外一方面,可以叠加多核来提升算力,但随着核数的增加,单位算力功耗也会显著增长,且总算力并非线性增长。据测算,当 128 核增至 256 核时,总算力水平无法提升 1.2倍。
随着算力需求的不断增长,从 P 级(PFLOPS,一秒 1015 次浮点运算)向 E 级 (EFLOPS,一秒 1018 次浮点运算)演进,计算集群的规模不断扩大,对集群之间互联的网络性能要求也越来越高,这使得计算和网络深度融合成为必然。
在计算处理器上,传统的 PCIe 的总线标准由于单通道传输带宽有限,且通道扩展数量也有限,已经无法满足目前大吞吐高性能计算场景的要求。当前业界的主流是在计算处理器内集成 RoCE(Remote Direct Memory Access over Converged Ethernet,基于融合以太的远程内存直接访问协议)以太端口,从而让数据通过标准以太网在传输速度和可扩展性上获得了巨大的提升。
这里的 Remote Direct Memory Access(RDMA)是相对于 TCP 而言的,如下图所示,在服务器内部,传统的 TCP 协议栈在接收/发送报文,以及对报文进行内部处理时,会产生数十微秒的固定时延,这使得在 AI 数据运算这类微秒级系统中,TCP 协议栈时延成为最明显的瓶颈。另外,随着网络规模的扩大和带宽的提高,宝贵的 CPU 资源越来越地多被用于传输数据。

RDMA 允许应用与网卡之间的直接数据读写,将服务器内的数据传输时延降低到接近 1μs。同时,RDMA 允许接收端直接从发送端的内存读取数据,极大地减少了 CPU 的负担。
在 高 性 能 计 算 场 景 中 , 当 前 有 两 种 主 流 方 案 来 承 载 RDMA :专用 IB(InfiniBand)网络和以太网络。然而,IB 网络采用私有协议,架构封闭,难以与现网大规模的 IP 网络实现很好的兼容互通,同时 IB 网络运维复杂,OPEX 居高不下。用以太网承载 RDMA 数据流,即上文提到的 RoCE,已应用在越来越多的高性能计算场景。
新业务对海量数据的存储和读写需求,催生了存储介质的革新,由 HDD(Hard Disk Drive,机械硬盘)快速向 SSD(Solid-State Drive,固态硬盘)切换,这带来了存储性能近 100 倍的提升。在此过程中,出现了 NVMe(Non-Volatile Memory express,非易失性内存主机控制器接口规范)存储协议,NVMe 极大提升了存储系统内部的存储吞吐性能,降低了传输时延。
相比而言,原来承载存储业务的 FC 网络,无论从带宽还是时延上,均已经成为当前存储网络的瓶颈。完成革新后的全新存储系统,需要一个更快、更高质量的网络。为此,存储与网络从架构和协议层进行了深度重构,新一代存储网络技术 NVMe over Fabric(简称 NVMe-oF)应运而生。NVMe-oF 将 NVMe 协议应用到服务器主机前端,作为存储阵列与前端主机连接的通道,可端到端取代 SAN 网络中的 SCSI(Small Computer System Interface,小型计算机系统接口)协议。
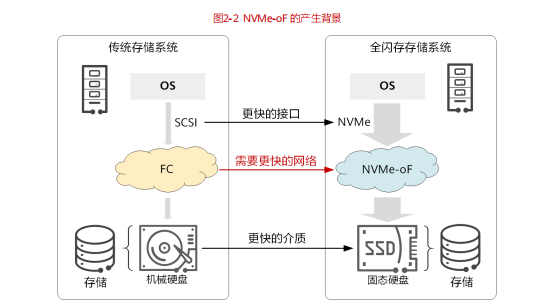
NVMe over Fabric 中的“Fabric”,是 NVMe 的承载网络,这个网络可以是FC、TCP 或 RMDA。
对于 FC,其技术封闭、产业生态不及以太网;产业规模有限,技术发展相对迟缓,带宽不及以太网;从业人员稀缺、运维成本高、故障排除效率低。
对于 TCP,在追求应用高性能的网络大潮中,RDMA 替换 TCP 已成为大势所趋。
对于 RDMA,主流技术是 RoCE(RDMA over Converged Ethernet),即 NVMe over RoCE,他是基于融合以太网的 RDMA 技术来承载 NVMe。
综上所述,基于以太网的 RoCE 比 FC 性能更高(更高的带宽、更低的时延),同时兼具 TCP 的优势(全以太化、全 IP 化),因此 NVMe over RoCE 作为新一代存储网络已经脱颖而出,成为业界 NVMe-oF 的主流技术。
在数据中心网络,当前存在几个较为突出的问题与挑战:
管理难:数据中心网络里常常存在多个厂商的不同设备,接口不统一,很难统一管控。
易出错:新业务的下发或老业务的变更,工作流程复杂,往往涉及多部门联动设计、调测,人工操作不仅效率低,而且容易出错。
定位慢:如果发生异常,据统计,故障的定位平均时长达 76 分钟,严重影响业务的连续性,给企业带来损失。
这些都呼唤一个全新的数据中心网络的到来。华为超融合数据中心网络,在实现“三网合一”的基础上,在开放性、业务部署、运维层面进行变革,全方位应对上述挑战。
来源:智能计算芯世界
转载申明:转载本号文章请注明作者和来源,本号发布文章若存在版权等问题,请留言联系处理,谢谢。
推荐阅读
更多架构相关技术知识总结请参考“架构师全店铺技术资料打包”相关电子书(37本技术资料打包汇总详情可通过“阅读原文”获取)。
全店内容持续更新,现下单“全店铺技术资料打包(全)”,后续可享全店内容更新“免费”赠阅,价格仅收198元(原总价350元)。
温馨提示:
扫描二维码关注公众号,点击阅读原文链接获取“架构师技术全店资料打包汇总(全)”电子书资料详情。
