
听声辨位,一个让我感到毛骨悚然的 GitHub 项目!
了解更多网络安全技术,
了解更多网络安全技术,
加入网络安全交流群!
不定期分享网安技术
扫码添加黑客小助手免费获取入群资格。
想必你永远不会想到,有一天你也会被自己的键盘出卖。
对,就是你每日敲击的键盘。当指尖在键盘上跳跃,清脆的噼啪声此起彼落时,你输入的所有信息,包括那些情真意切的词句,那些不欲人知的心事,还有你的网络账户、银行密码…… 全都被它泄露了。
键盘,还能被黑???
前不久,一个叫做 Keytap 的 “黑科技” 在国外火了。Keytap 通过监听你敲击键盘的声音,就能还原出你输入的内容。
而且,只需要通过你电脑里的麦克风,就能完成声波采集的任务。
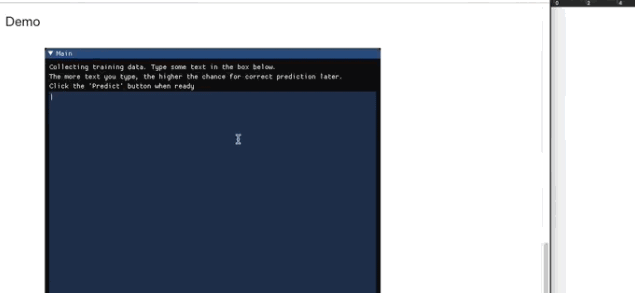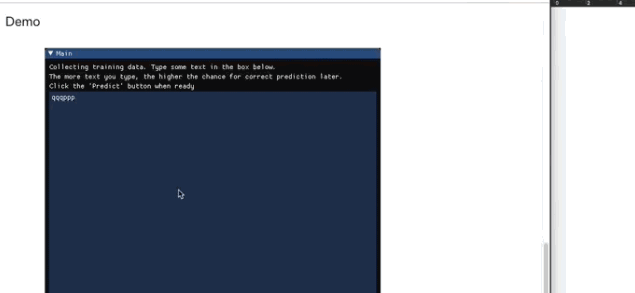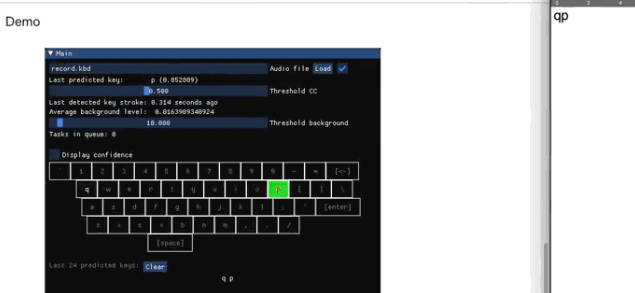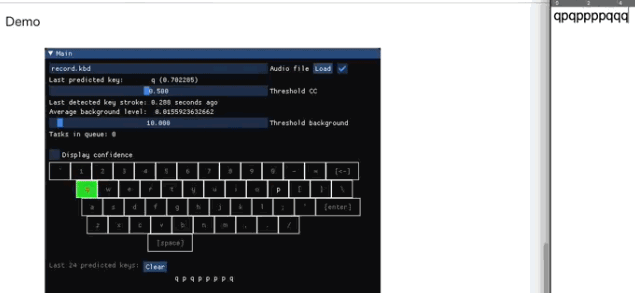
在一段发布于网上的 Demo 里,Keytap 作者展示了在 iMac+Filco 机械键盘环境中,这个算法的优秀程度,请看:
四步偷窥大法
搭建这样一个 “偷窥” 打字的模型并不难,Keytap 算法也已经开源了。跟着做,只要如下四步:
一是,收集训练数据;
二是,搭建预测模型,学习一下数据;
三是,检测出有人在敲键盘;
四是,检测出 ta 在打什么字。
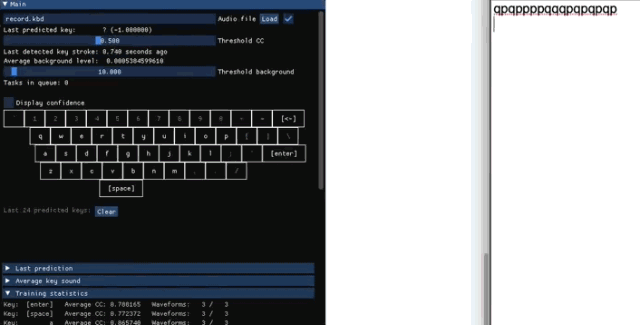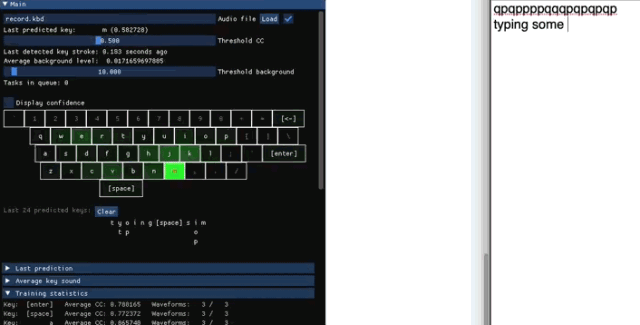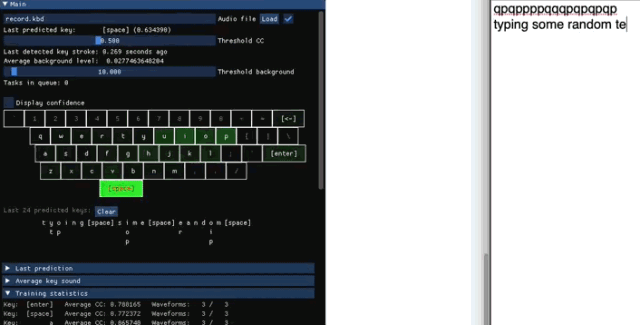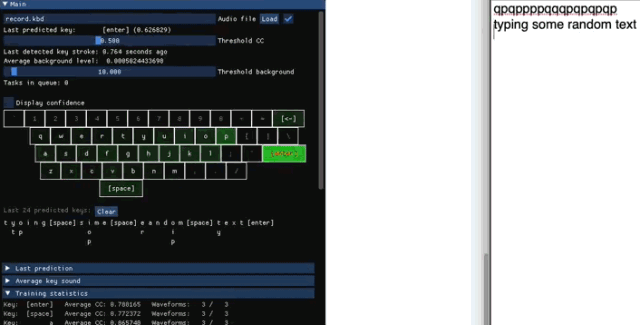
收集训练数据
Keytap 收集数据时,只保留每次敲击前后 75-100 毫秒的音频。
这就是说,并非连续取样,两次敲击之间有一部分是忽略的。
这种做法是会牺牲一些信息量的。
从敲下按键,到程序受到指令,这之间有随机延时,与硬件和软件都有关系。
比如,按下 g 键的完整波形长这样:
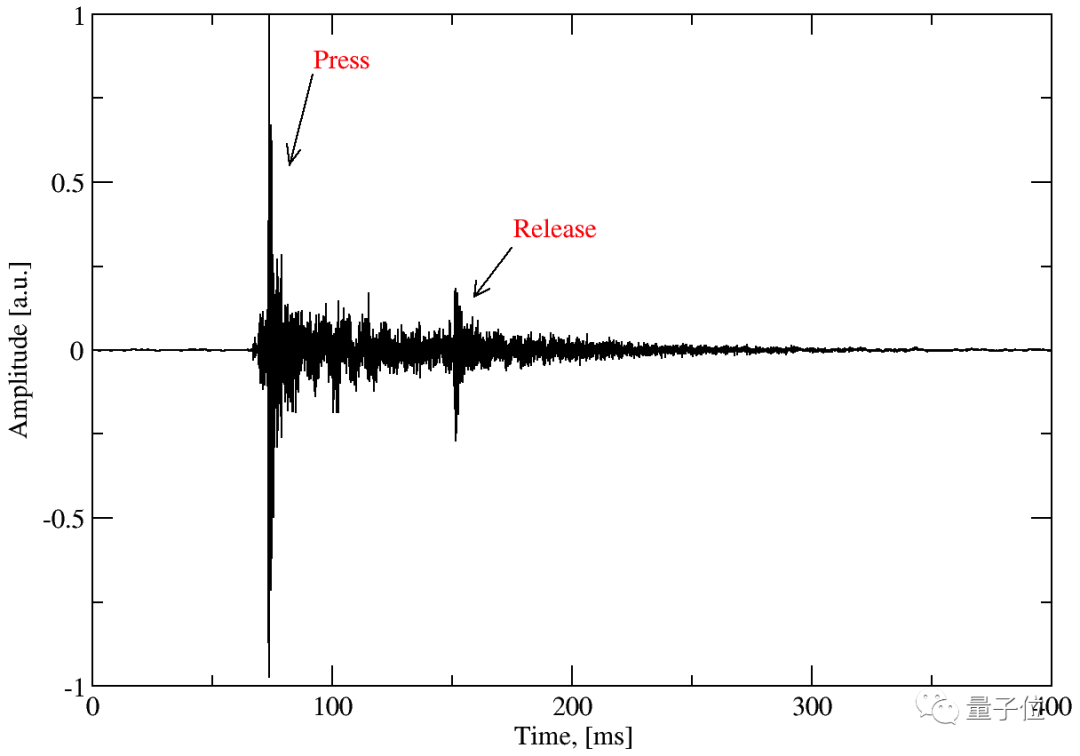
看图像可以发现,敲击时出现了一个峰值,而再过大约 150 毫秒,又有一个按键被抬起的小峰值。
这样说来,100 毫秒之外的信息也可能有用,不过这里为了简便就忽略了。
最终,收集到的数据长这样:
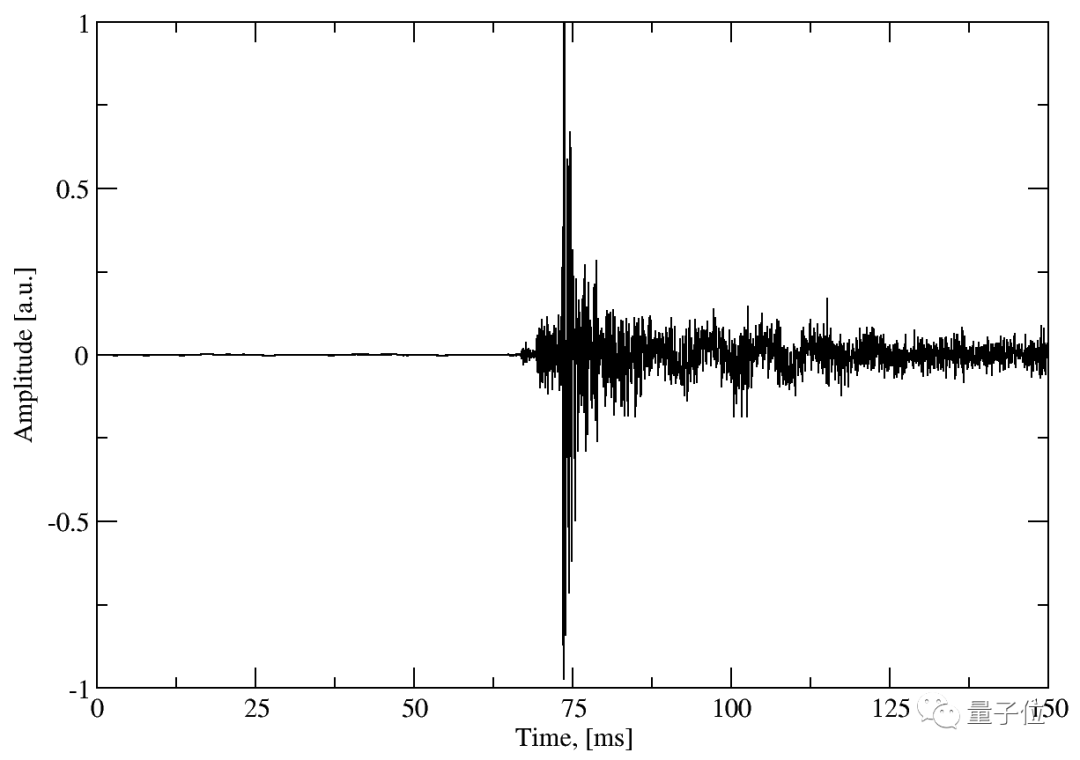
除此之外,局限性还在于,如果两次按键之间相隔不久,后者落在前者的后 75 毫秒之内,那数据可能就有些混杂了。
搭个预测模型
这个部分是最能发挥创造力的部分。Keytap 用了一个非常简单的方法,分为三步:
1. 把收集到的波形的峰值对齐。这样可以避免延时带来的影响。
2. 基于相似度指标 (Similarity Metric) ,更精细地对齐波形。
需要更精确的对齐方法,是因为有时候峰值未必是最好的判断依据。
那么,可不可以跳过峰值对齐呢?
之所以第 2 步之前要先做第 1 步,是因为相似度指标的计算很占 CPU。而第 1 步可以有效缩小对齐窗口 (Alignment Window) ,减少计算量。
3. 对齐后,做简单加权平均。权重也是用相似度指标来定义的。
完成第 3 步之后,每一个按键都会得出一个平均波形 (a Single Averaged Waveform) ,用来和实时捕捉的数据做比对。
Keytap 用的相似度指标是互相关 (Cross Correlation, CC) ,长这样:
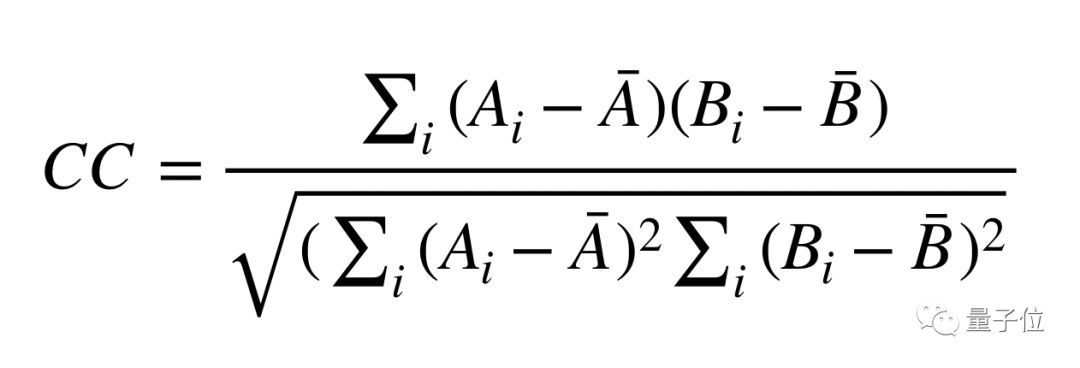
这里,Ai 和 Bi 都是某个按键的波形样本,比对就在它们之间进行。CC 值越高,表示两者越相似。
当然,也可以用其他相似度指标来做。
顺便一说,两次按键之间的间隔时长,其实也可以用来预测的,但开发者怕麻烦就省略了,勇敢的少年可以去源代码基础上自行实验。
检测出在敲键盘
平均波形和比对标准都有了,可是麦克风实时收录的声音连绵不绝,该和哪一段来比对呢?
这就需要从连续的音频里,找到敲击键盘的声音。
Keytap 用了一个非常简单的阈值方法,在原始音频里监测敲击动作:
按下去的时候,会有一个大大的峰值,这就是侦测目标。
不过,这个阈值不是固定的,是自适应 (Adaptive) 的:根据过去数百毫秒之内的平均样本强度来调整的。
检测打了什么字
当系统发现有人在敲键盘,就用相似度指标来测到底按了哪个键,CC 值最高的就是答案。方法就像上文说的那样。
现在,代码实现已经开源了,传送门见文底。
不过,作者在博客中说,这个方法目前只有机械键盘适用。
“薯片间谍”
听音识字的研究不止这一个,去年一篇 Don’t Skype & Type!Acoustic Eavesdropping in Voice-Over-IP 的论文,也提出了 Skype & Type(S&T)键盘声音识别算法。
和这个研究类似,根据网络电话 Skepe 中传出的打字按键声音,在了解了被测者的打字风格和设备类型后,系统能复原敲下了什么。
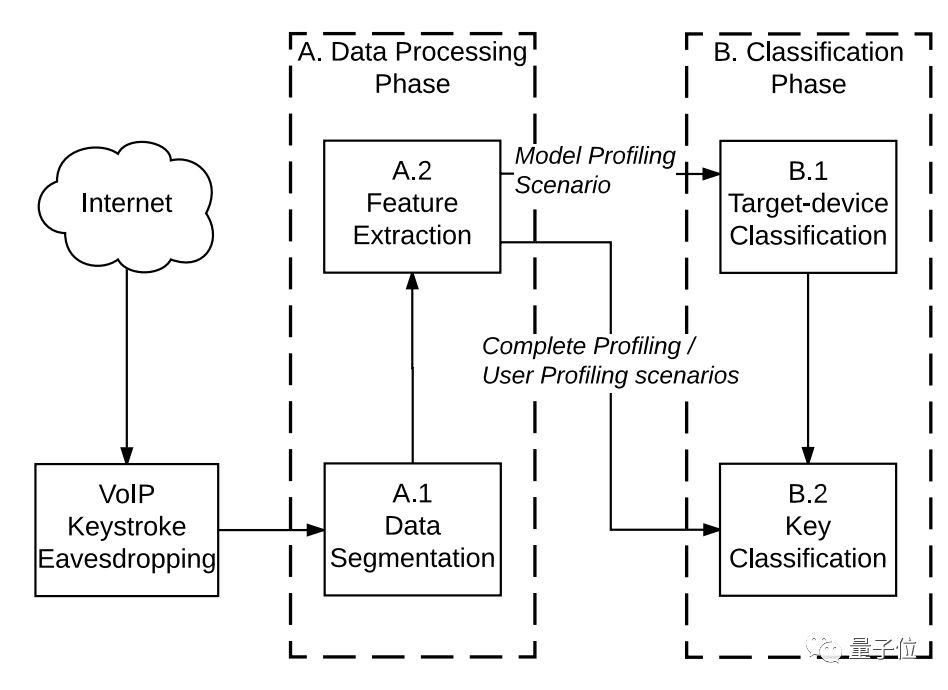
整个算法搭建过程只有三步:收集信息、数据处理与数据分类。
研究人员事先收集语音电话中键盘敲击声,将这些声音分为两类,即按下声与松开回弹声,随后提取它们的特征。
当听到键盘声时,算法先识别设备类型,再去识别为键盘中的哪个键。和 Keytap 不同的是,S&T 也能适用于非机械键盘了。
研究人员表示,在预测的最可能的前 5 个字母中,包含正确字母的准确率达到了 91.7%。
这篇论文发表在 ACM 亚洲计算机和通讯安全大会(ASIACCS 2017)上,地址:
https://www.math.unipd.it/~dlain/papers/2017-skype.pdf
推测人类讲了什么,AI 需要甚至只是一包薯片。
什么,觉得太离谱了?Naive。
MIT、微软和 Adobe 开发的这种看似天方夜谭的算法,只需高速相机透过隔音玻璃,拍摄出薯片袋的振动,算法就会判断说话人是男是女,甚至还原出说了什么。

研究人员表示,声音传播时触碰到周围的物体,会震动形成一股微妙的视觉信号,肉眼无法识别,但高速相机(每秒帧数 2000~6000 FPS)可以敏锐捕捉。

除了薯片袋子,研究人员还用铝箔、水杯甚至植物盆栽进行了试验,效果 “一如既往的好”。
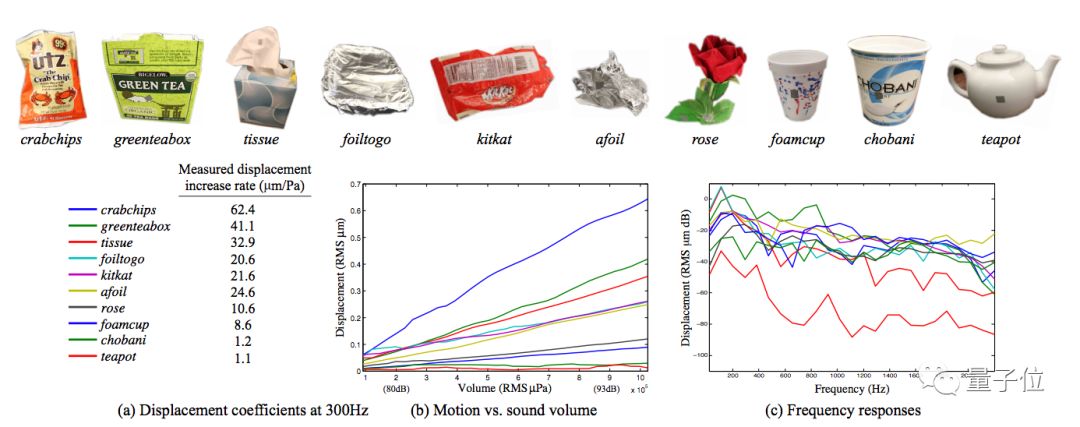
这不是野生研究,相关论文 The Visual Microphone:Passive Recovery of Sound from Video 还登上了 2014 年的 Siggraph 计算机图形学大会。
论文地址(注意科学前往):http://t.cn/EyZEZYI
传送门
方法虽多,如果想自己动手搞一个,这些 Keytap 相关资源还是要收好:
博客地址:
https://ggerganov.github.io/jekyll/update/2018/11/30/keytap-description-and-thoughts.html
代码地址:
https://github.com/ggerganov/kbd-audio
Demo:
https://ggerganov.github.io/jekyll/update/2018/11/24/keytap.html
嘘,掩好口鼻,轻声撤退。
评论