
【深度学习】一文看懂 (Transfer Learning)迁移学习(pytorch实现)
前言
你会发现聪明人都喜欢”偷懒”, 因为这样的偷懒能帮我们节省大量的时间, 提高效率. 还有一种偷懒是 “站在巨人的肩膀上”. 不仅能看得更远, 还能看到更多. 这也用来表达我们要善于学习先辈的经验, 一个人的成功往往还取决于先辈们累积的知识. 这句话, 放在机器学习中, 这就是今天要说的迁移学习了, transfer learning.
什么是迁移学习?
迁移学习通俗来讲,就是运用已有的知识来学习新的知识,核心是找到已有知识和新知识之间的相似性,用成语来说就是举一反三。由于直接对目标域从头开始学习成本太高,我们故而转向运用已有的相关知识来辅助尽快地学习新知识。比如,已经会下中国象棋,就可以类比着来学习国际象棋;已经会编写Java程序,就可以类比着来学习C#;已经学会英语,就可以类比着来学习法语;等等。世间万事万物皆有共性,如何合理地找寻它们之间的相似性,进而利用这个桥梁来帮助学习新知识,是迁移学习的核心问题。
为什么需要迁移学习?
 现在的机器人视觉已经非常先进了, 有些甚至超过了人类. 99.99%的识别准确率都不在话下. 这样的成功, 依赖于强大的机器学习技术, 其中, 神经网络成为了领军人物. 而 CNN 等, 像人一样拥有千千万万个神经联结的结构, 为这种成功贡献了巨大力量. 但是为了更厉害的 CNN, 我们的神经网络设计, 也从简单的几层网络, 变得越来越多, 越来越多, 越来越多… 为什么会越来越多?
现在的机器人视觉已经非常先进了, 有些甚至超过了人类. 99.99%的识别准确率都不在话下. 这样的成功, 依赖于强大的机器学习技术, 其中, 神经网络成为了领军人物. 而 CNN 等, 像人一样拥有千千万万个神经联结的结构, 为这种成功贡献了巨大力量. 但是为了更厉害的 CNN, 我们的神经网络设计, 也从简单的几层网络, 变得越来越多, 越来越多, 越来越多… 为什么会越来越多?
因为计算机硬件, 比如 GPU 变得越来越强大, 能够更快速地处理庞大的信息. 在同样的时间内, 机器能学到更多东西. 可是, 不是所有人都拥有这么庞大的计算能力. 而且有时候面对类似的任务时, 我们希望能够借鉴已有的资源.
如何做迁移学习?
 这就好比, Google 和百度的关系, facebook 和人人的关系, KFC 和 麦当劳的关系, 同一类型的事业, 不用自己完全从头做, 借鉴对方的经验, 往往能节省很多时间. 有这样的思路, 我们也能偷偷懒, 不用花时间重新训练一个无比庞大的神经网络, 借鉴借鉴一个已经训练好的神经网络就行.
这就好比, Google 和百度的关系, facebook 和人人的关系, KFC 和 麦当劳的关系, 同一类型的事业, 不用自己完全从头做, 借鉴对方的经验, 往往能节省很多时间. 有这样的思路, 我们也能偷偷懒, 不用花时间重新训练一个无比庞大的神经网络, 借鉴借鉴一个已经训练好的神经网络就行.
 比如这样的一个神经网络, 我花了两天训练完之后, 它已经能正确区分图片中具体描述的是男人, 女人还是眼镜. 说明这个神经网络已经具备对图片信息一定的理解能力. 这些理解能力就以参数的形式存放在每一个神经节点中. 不巧, 领导下达了一个紧急任务,
比如这样的一个神经网络, 我花了两天训练完之后, 它已经能正确区分图片中具体描述的是男人, 女人还是眼镜. 说明这个神经网络已经具备对图片信息一定的理解能力. 这些理解能力就以参数的形式存放在每一个神经节点中. 不巧, 领导下达了一个紧急任务,
要求今天之内训练出来一个预测图片里实物价值的模型. 我想这可完蛋了, 上一个图片模型都要花两天, 如果要再搭个模型重新训练, 今天肯定出不来呀.
这时, 迁移学习来拯救我了. 因为这个训练好的模型中已经有了一些对图片的理解能力, 而模型最后输出层的作用是分类之前的图片, 对于现在计算价值的任务是用不到的, #所以我将最后一层替换掉, 变为服务于现在这个任务的输出层. #接着只训练新加的输出层, 让理解力保持始终不变. 前面的神经层庞大的参数不用再训练, 节省了我很多时间, 我也在一天时间内, 将这个任务顺利完成.
 但并不是所有时候我们都需要迁移学习. 比如神经网络很简单, 相比起计算机视觉中庞大的 CNN 或者语音识别的 RNN, 训练小的神经网络并不需要特别多的时间, 我们完全可以直接重头开始训练. 从头开始训练也是有好处的.
但并不是所有时候我们都需要迁移学习. 比如神经网络很简单, 相比起计算机视觉中庞大的 CNN 或者语音识别的 RNN, 训练小的神经网络并不需要特别多的时间, 我们完全可以直接重头开始训练. 从头开始训练也是有好处的.
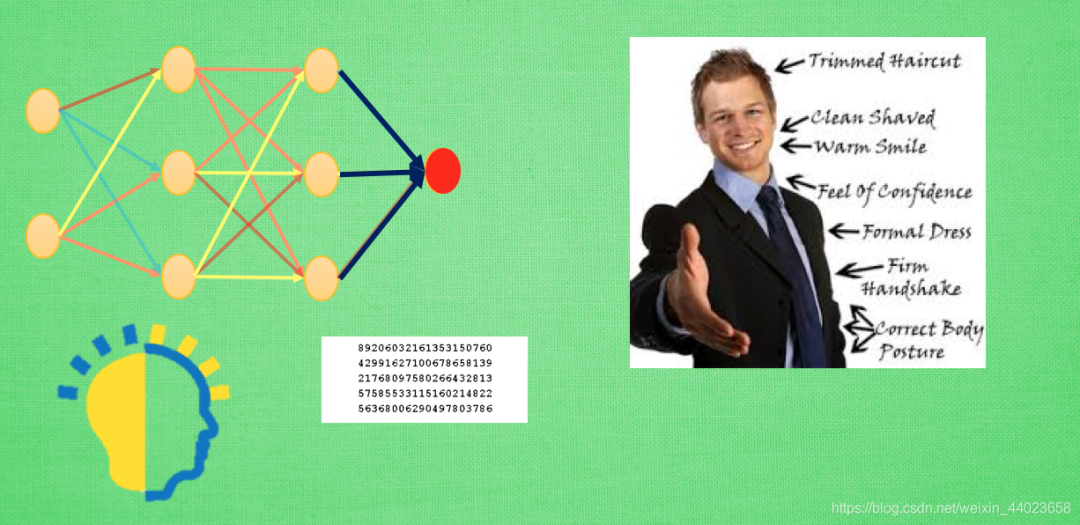 如果固定住之前的理解力, 或者使用更小的学习率来更新借鉴来的模型, 就变得有点像认识一个人时的第一印象, 如果迁移前的数据和迁移后的数据差距很大, 或者说我对于这个人的第一印象和后续印象差距很大, 我还不如不要管我的第一印象, 同理, 这时, 迁移来的模型并不会起多大作用, 还可能干扰我后续的决策.
如果固定住之前的理解力, 或者使用更小的学习率来更新借鉴来的模型, 就变得有点像认识一个人时的第一印象, 如果迁移前的数据和迁移后的数据差距很大, 或者说我对于这个人的第一印象和后续印象差距很大, 我还不如不要管我的第一印象, 同理, 这时, 迁移来的模型并不会起多大作用, 还可能干扰我后续的决策.
迁移学习的限制
比如说,我们不能随意移除预训练网络中的卷积层。但由于参数共享的关系,我们可以很轻松地在不同空间尺寸的图像上运行一个预训练网络。这在卷积层和池化层和情况下是显而易见的,因为它们的前向函数(forward function)独立于输入内容的空间尺寸。在全连接层(FC)的情形中,这仍然成立,因为全连接层可被转化成一个卷积层。所以当我们导入一个预训练的模型时,网络结构需要与预训练的网络结构相同,然后再针对特定的场景和任务进行训练。
常见的迁移学习方式:
载权重后训练所有参数 载入权重后只训练最后几层参数 载入权重后在原网络基础上再添加一层全链接层,仅训练最后一个全链接层
衍生
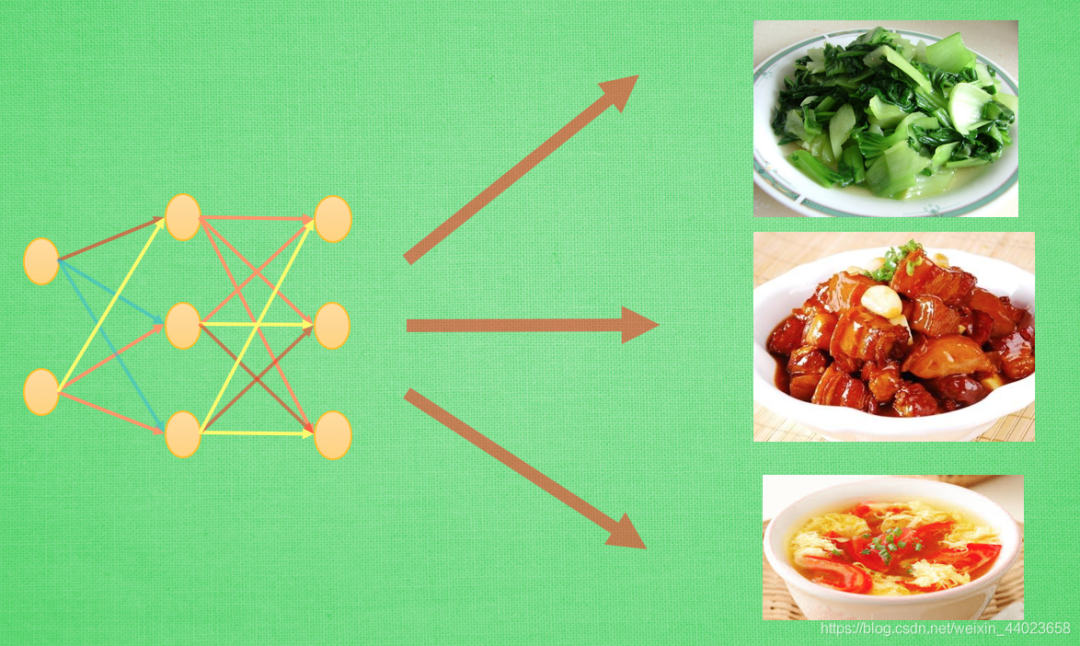 了解了一般的迁移学习玩法后, 我们看看前辈们还有哪些新玩法. 多任务学习, 或者强化学习中的 learning to learn, 迁移机器人对运作形式的理解, 解决不同的任务. 炒个蔬菜, 红烧肉, 番茄蛋花汤虽然菜色不同, 但是做菜的原则是类似的.
了解了一般的迁移学习玩法后, 我们看看前辈们还有哪些新玩法. 多任务学习, 或者强化学习中的 learning to learn, 迁移机器人对运作形式的理解, 解决不同的任务. 炒个蔬菜, 红烧肉, 番茄蛋花汤虽然菜色不同, 但是做菜的原则是类似的.
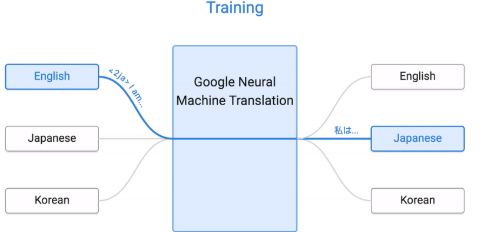
又或者 google 的翻译模型, 在某些语言上训练, 产生出对语言的理解模型, 将这个理解模型当做迁移模型在另外的语言上训练. 其实说白了, 那个迁移的模型就能看成机器自己发明的一种只有它自己才能看懂的语言. 然后用自己的这个语言模型当成翻译中转站, 将某种语言转成自己的语言, 然后再翻译成另外的语言. 迁移学习的脑洞还有很多, 相信这种站在巨人肩膀上继续学习的方法, 还会带来更多有趣的应用.
使用图像数据进行迁移学习
牛津 VGG 模型(http://www.robots.ox.ac.uk/~vgg/research/very_deep/) 谷歌 Inception模型(https://github.com/tensorflow/models/tree/master/inception) 微软 ResNet 模型(https://github.com/KaimingHe/deep-residual-networks)
可以在 Caffe Model Zoo(https://github.com/BVLC/caffe/wiki/Model-Zoo)中找到更多的例子,那里分享了很多预训练的模型。
实例:
注:如何获取官方的.pth文件,以resnet为例子
import torchvision.models.resnet
在脚本中输入以上代码,将鼠标对住resnet并按ctrl键,发现改变颜色,点击进入resnet.py脚本,在最开始有url,如下图所示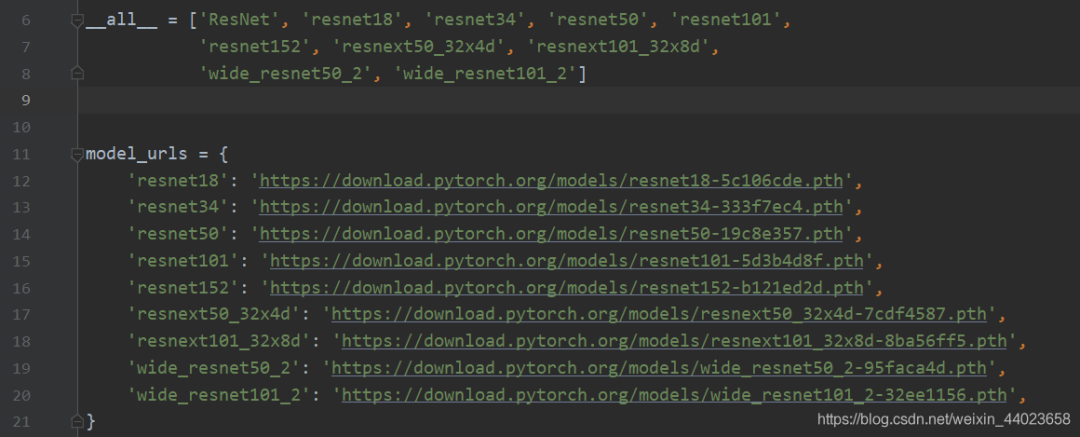 选择你要下载的模型,copy到浏览器即可,若是觉得慢可以用迅雷等等。
选择你要下载的模型,copy到浏览器即可,若是觉得慢可以用迅雷等等。
ResNet详细讲解在这篇博文里:ResNet——CNN经典网络模型详解(pytorch实现)
#train.py
import torch
import torch.nn as nn
from torchvision import transforms, datasets
import json
import matplotlib.pyplot as plt
import os
import torch.optim as optim
from model import resnet34, resnet101
import torchvision.models.resnet
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),#来自官网参数
"val": transforms.Compose([transforms.Resize(256),#将最小边长缩放到256
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
data_root = os.getcwd()
image_path = data_root + "/flower_data/" # flower data set path
train_dataset = datasets.ImageFolder(root=image_path + "train",
transform=data_transform["train"])
train_num = len(train_dataset)
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
batch_size = 16
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=0)
validate_dataset = datasets.ImageFolder(root=image_path + "/val",
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
num_workers=0)
net = resnet34()
# net = resnet34(num_classes=5)
# load pretrain weights
model_weight_path = "./resnet34-pre.pth"
missing_keys, unexpected_keys = net.load_state_dict(torch.load(model_weight_path), strict=False)#载入模型参数
# for param in net.parameters():
# param.requires_grad = False
# change fc layer structure
inchannel = net.fc.in_features
net.fc = nn.Linear(inchannel, 5)
net.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0001)
best_acc = 0.0
save_path = './resNet34.pth'
for epoch in range(3):
# train
net.train()
running_loss = 0.0
for step, data in enumerate(train_loader, start=0):
images, labels = data
optimizer.zero_grad()
logits = net(images.to(device))
loss = loss_function(logits, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
# print train process
rate = (step+1)/len(train_loader)
a = "*" * int(rate * 50)
b = "." * int((1 - rate) * 50)
print("\rtrain loss: {:^3.0f}%[{}->{}]{:.4f}".format(int(rate*100), a, b, loss), end="")
print()
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
for val_data in validate_loader:
val_images, val_labels = val_data
outputs = net(val_images.to(device)) # eval model only have last output layer
# loss = loss_function(outputs, test_labels)
predict_y = torch.max(outputs, dim=1)[1]
acc += (predict_y == val_labels.to(device)).sum().item()
val_accurate = acc / val_num
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('[epoch %d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, running_loss / step, val_accurate))
print('Finished Training')
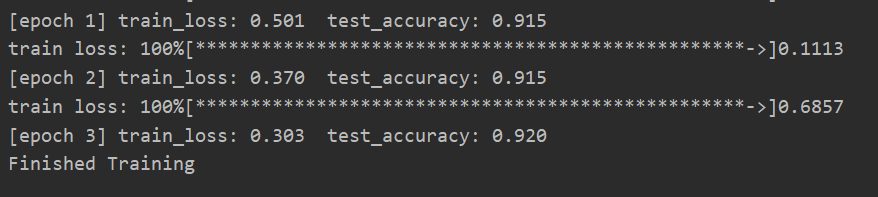 未使用迁移学习
未使用迁移学习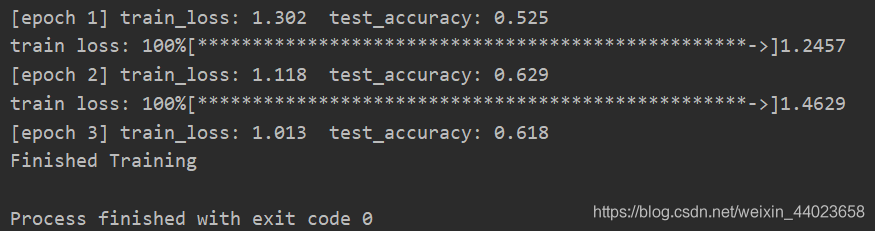 VGG16
VGG16
#train.py
import torch.nn as nn
from torchvision import transforms, datasets
import json
import os
import torch.optim as optim
from model import vgg
import torch
import time
import torchvision.models.vgg
from torchvision import models
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
#数据预处理,从头
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
data_root = os.path.abspath(os.path.join(os.getcwd(), "../../..")) # get data root path
image_path = data_root + "/data_set/flower_data/" # flower data set pathh
train_dataset = datasets.ImageFolder(root=image_path + "/train",
transform=data_transform["train"])
train_num = len(train_dataset)
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
batch_size = 20
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=0)
validate_dataset = datasets.ImageFolder(root=image_path + "val",
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
num_workers=0)
# test_data_iter = iter(validate_loader)
# test_image, test_label = test_data_iter.next()
# model
# = models.vgg16(pretrained=True)
#
# model_name = "vgg16"
# net = vgg(model_name=model_name, init_weights=True)
# load pretrain weights
net = models.vgg16(pretrained=False)
pre = torch.load("./vgg16.pth")
net.load_state_dict(pre)
for parma in net.parameters():
parma.requires_grad = False
net.classifier = torch.nn.Sequential(torch.nn.Linear(25088, 4096),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(4096, 4096),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(4096, 5))
# model_weight_path = "./vgg16.pth"
# missing_keys, unexpected_keys = net.load_state_dict(torch.load(model_weight_path), strict=False)#载入模型参数
# # for param in net.parameters():
# # param.requires_grad = False
# # change fc layer structure
#
# inchannel = 512
# net.classifier = nn.Linear(inchannel, 5)
loss_function = torch.nn.CrossEntropyLoss()
optimizer = optim.Adam(net.classifier.parameters(), lr=0.001)
# loss_function = nn.CrossEntropyLoss()
# optimizer = optim.Adam(net.parameters(), lr=0.0001) #learn rate
net.to(device)
best_acc = 0.0
#save_path = './{}Net.pth'.format(model_name)
save_path = './vgg16Net.pth'
for epoch in range(15):
# train
net.train()
running_loss = 0.0 #统计训练过程中的平均损失
t1 = time.perf_counter()
for step, data in enumerate(train_loader, start=0):
images, labels = data
optimizer.zero_grad()
#with torch.no_grad(): #用来消除验证阶段的loss,由于梯度在验证阶段不能传回,造成梯度的累计
outputs = net(images.to(device))
loss = loss_function(outputs, labels.to(device)) #得到预测值与真实值的一个损失
loss.backward()
optimizer.step()#更新结点参数
# print statistics
running_loss += loss.item()
# print train process
rate = (step + 1) / len(train_loader)
a = "*" * int(rate * 50)
b = "." * int((1 - rate) * 50)
print("\rtrain loss: {:^3.0f}%[{}->{}]{:.3f}".format(int(rate * 100), a, b, loss), end="")
print()
print(time.perf_counter() - t1)
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():#不去跟踪损失梯度
for val_data in validate_loader:
val_images, val_labels = val_data
#optimizer.zero_grad()
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += (predict_y == val_labels.to(device)).sum().item()
val_accurate = acc / val_num
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('[epoch %d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, running_loss / step, val_accurate))
print('Finished Training')
densenet121
#train.py
import torch
import torch.nn as nn
from torchvision import transforms, datasets
import json
import matplotlib.pyplot as plt
from model import densenet121
import os
import torch.optim as optim
import torchvision.models.densenet
import torchvision.models as models
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),#来自官网参数
"val": transforms.Compose([transforms.Resize(256),#将最小边长缩放到256
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
data_root = os.path.abspath(os.path.join(os.getcwd(), "../../..")) # get data root path
image_path = data_root + "/data_set/flower_data/" # flower data set path
train_dataset = datasets.ImageFolder(root=image_path + "train",
transform=data_transform["train"])
train_num = len(train_dataset)
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
batch_size = 16
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=0)
validate_dataset = datasets.ImageFolder(root=image_path + "/val",
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
num_workers=0)
#迁移学习
net = models.densenet121(pretrained=False)
model_weight_path="./densenet121-a.pth"
missing_keys, unexpected_keys = net.load_state_dict(torch.load(model_weight_path), strict= False)
inchannel = net.classifier.in_features
net.classifier = nn.Linear(inchannel, 5)
net.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0001)
#普通
# model_name = "densenet121"
# net = densenet121(model_name=model_name, num_classes=5)
best_acc = 0.0
save_path = './densenet121.pth'
for epoch in range(12):
# train
net.train()
running_loss = 0.0
for step, data in enumerate(train_loader, start=0):
images, labels = data
optimizer.zero_grad()
logits = net(images.to(device))
loss = loss_function(logits, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
# print train process
rate = (step+1)/len(train_loader)
a = "*" * int(rate * 50)
b = "." * int((1 - rate) * 50)
print("\rtrain loss: {:^3.0f}%[{}->{}]{:.4f}".format(int(rate*100), a, b, loss), end="")
print()
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
for val_data in validate_loader:
val_images, val_labels = val_data
outputs = net(val_images.to(device)) # eval model only have last output layer
# loss = loss_function(outputs, test_labels)
predict_y = torch.max(outputs, dim=1)[1]
acc += (predict_y == val_labels.to(device)).sum().item()
val_accurate = acc / val_num
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('[epoch %d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, running_loss / step, val_accurate))
print('Finished Training')
使用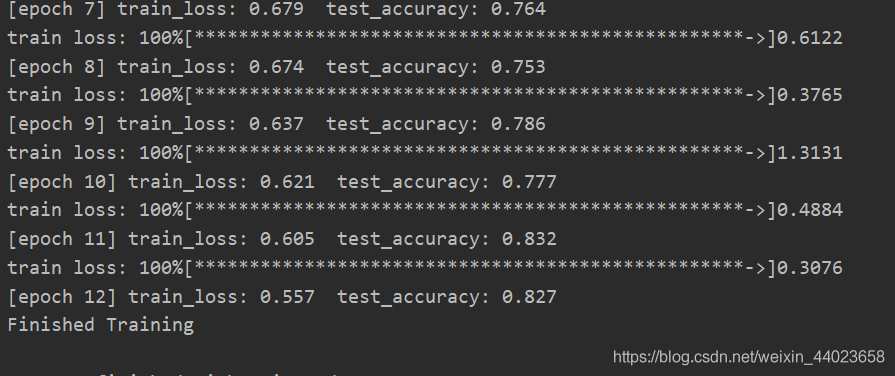
注:部分图片来自于莫凡python
往期精彩回顾
获取一折本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/662nyZF
本站qq群1003271085。
加入微信群请扫码进群(如果是博士或者准备读博士请说明):