
爬取百度贴吧的美图、感觉是时候要和年轻人接触接触了
听说现在00后和10后都特别喜欢玩QQ和百度贴吧,作为一个已经不玩qq很多年的我,感觉是时候要和年轻人接触接触了
于是我打开了百度贴吧......
搜索了几个关键词......
然后就出现......
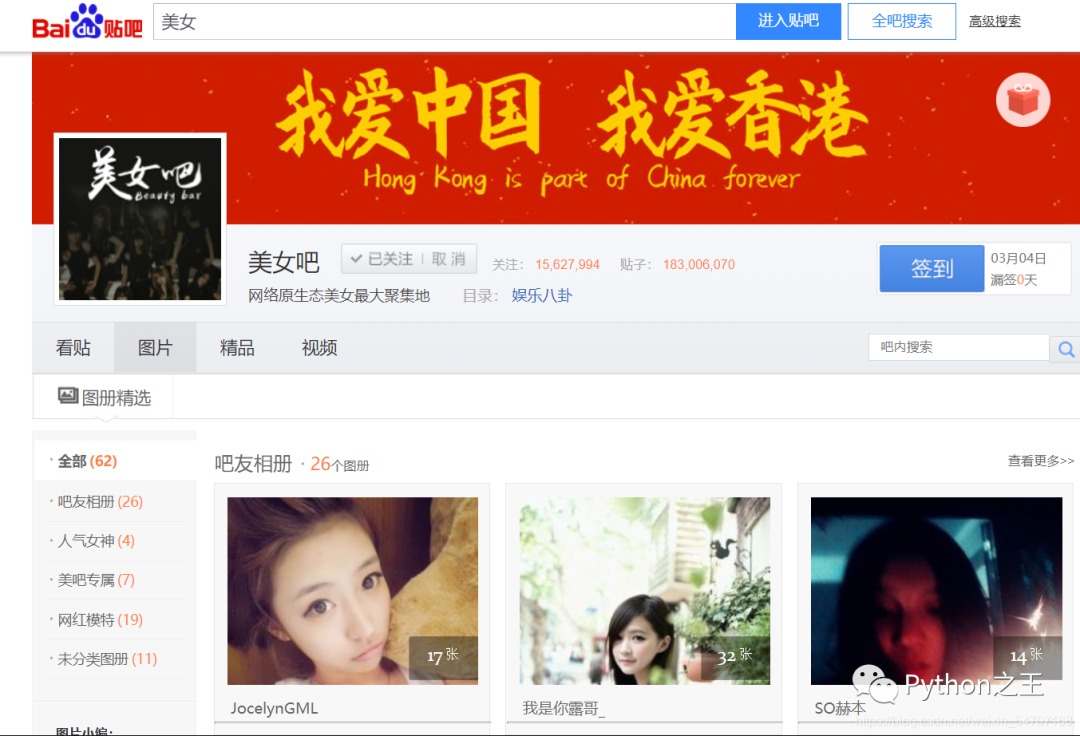
我选择爬取的贴吧为美女,你们可以选择自己想要爬取的贴吧。
首先先观察百度贴吧某个贴吧第一页,第二页,第三页的url链接组成。(请点击最下方第一页,第二页,第三页才会看到以下截图信息)
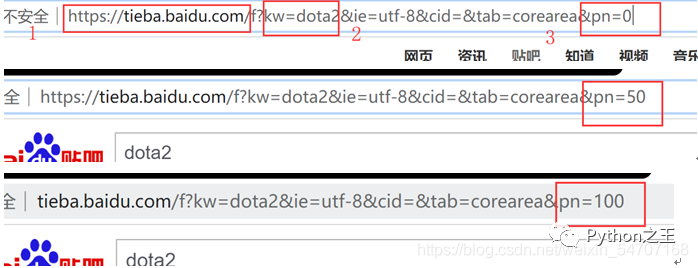
观察三页的信息,可以看到,第一部分为百度贴吧域名,第二部分kw为访问的贴吧的名字dota2,第三部分pn为帖子开始位置。第一页为0,第二页为50,第三页为100,经过计算会发现,百度贴吧每页会显示50个帖子,因此,我们只要以50的倍数跳页,就可以进行翻页了。
下图就是我爬取的美女贴子中的图片


具体代码
import requests
import bs4
import os
def write_file(file_url, file_type):
"""写入文件"""
res = requests.get(file_url)
res.raise_for_status()
# 文件类型分文件夹写入
if file_type == 1:
file_folder = 'nhdz\\jpg'
elif file_type == 2:
file_folder = 'nhdz\\mp4'
else:
file_folder = 'nhdz\\other'
folder = os.path.exists(file_folder)
# 文件夹不存在,则创建文件夹
if not folder:
os.makedirs(file_folder)
# 打开文件资源,并写入
file_name = os.path.basename(file_url)
str_index = file_name.find('?')
if str_index > 0:
file_name = file_name[:str_index]
file_path = os.path.join(file_folder, file_name)
print('正在写入资源文件:', file_path)
image_file = open(file_path, 'wb')
for chunk in res.iter_content(100000):
image_file.write(chunk)
image_file.close()
print('写入完成!')
def download_file(web_url):
"""获取资源的url"""
# 下载网页
print('正在下载网页: %s...' % web_url)
result = requests.get(web_url)
soup = bs4.BeautifulSoup(result.text, "html.parser")
# 查找图片资源
img_list = soup.select('.vpic_wrap img')
if img_list == []:
print('未发现图片资源!')
else:
# 找到资源,开始写入
for img_info in img_list:
file_url = img_info.get('bpic')
write_file(file_url, 1)
# 查找视频资源
video_list = soup.select('.threadlist_video a')
if video_list == []:
print('未发现视频资源!')
else:
# 找到资源,开始写入
for video_info in video_list:
file_url = video_info.get('data-video')
write_file(file_url, 2)
print('下载资源结束:', web_url)
next_link = soup.select('#frs_list_pager .next')
if next_link == []:
print('下载资料结束!')
else:
url = next_link[0].get('href')
download_file('https:' + url)
# 主程序入口
if __name__ == '__main__':
web_url = 'https://tieba.baidu.com/f?ie=utf-8&kw=美女'
download_file(web_url)
各位小伙伴,今天就分享到这里,本次介绍了论坛子帖获取,网页数据爬取与解析,数据保存等内容。有什么建议,比如想了解的知识、内容中的问题、想要的资料、下次分享的内容、学习Python遇到的问题等,请在下方留言。如果喜欢请关注。
评论