
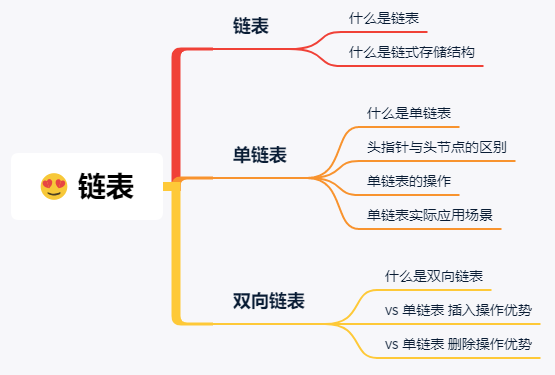
什么是链表?
数据结构连载往期回顾:
在 什么是数组? 中给臭宝们说过,连续的内存使得数组在进行插入和删除时需要移动大量元素,这就意味着要耗费时间。
在数据结构与算法中,快男才是大家的最爱,像插入和删除这么持久的蓝孩子显然不受待见。
后来,大家就想方设法帮助它们变快。
那么有没有这么一种数据结构可以达成这一目的呢?
链表就这么被整出来了。

相比于数组,链表是稍微复杂一些的数据结构,但是不难,只要跟着本蛋就能学会。
链表
首先什么是链表?
线性表的链式存储结构生成的表,叫做链表。
那么什么是链式存储结构咧?
链式存储结构是指用一组任意的存储单元存储线性表的数据元素,通过指针连接串联起来。
这里的“任意”指的就是,存储单元可以连续也可以不连续,这就意味着它们可以是内存中任何未被占用的地方。有味儿点讲就是只要内存这个厕所里空着的茅坑,你就随便蹲。

链表中的存储单元叫做节点。它和数组中只存数据信息不同,每个节点分为两部分:数据域和指针域。数据域存储的数据,指针域存储着同一个表里下一个节点的位置。
因为链表家族里的兄弟姐妹太多,在这里咧我只讲常见的几种链表结构:单链表、双向链表。
毕竟再多,我写的就累死了。。
单链表
n 个节点可以链接成一个链表,如果链表中的每个节点只包含一个指针域,这个链表就叫做单链表。
单链表的指针域指向的是下一个节点的地址,我们把指向下个节点地址的指针叫做后继指针。

单链表的第一个节点的存储位置叫做头指针,最后一个节点的后继指针为空,一般用 NULL 或者 “^” 表示。

除了上面的,有时候为了操作方便,会在单链表的第一个节点前面加一个节点,称之为头节点。这个头节点一般不存储任何内容,它的指针域指向单链表的第一个节点。


头指针与头节点的区别
头指针,顾名思义,是指向链表第一个结点的指针,如果有头结点的话,那么就是指向头结点的指针。
它是链表的必备元素且无论链表是否为空,头指针都不能为空,因为在访问链表的时候你总得知道它在什么位置,这样才能通过它的指针域找到下一个结点的位置,也就是说知道了头指针,整个链表的元素我们都是可以访问的。
所以头指针必须要存在,这也就是我们常说的标识,这也就是为什么我们一般用头指针来表示链表。
头结点,是放在第一个元素的节点之前,它的数据域一般没有意义,并且它本身也不是链表必须要带的。
它的设立是单纯是为了操作的统一和方便,其实就是为了在某些时候可以更方便的对链表进行操作,有了头结点,我们在对第一个元素前插入或者删除结点的时候,它的操作与其它结点的操作就统一了。

除此以外,还有一种啥也没有,空空空空~空链表。
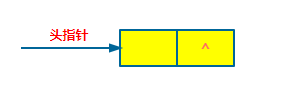
不知道臭宝们发现了没,不管是带头节点,还是不带头节点,或者是空的链表,它们都是有头指针的,这正印证了我在上面提到过的“头指针是链表的必备元素,无论链表是否为空,头指针都不能为空”。
别说话,夸我~
单链表的操作
和数组一样,单链表也有查找、插入和删除等操作。因为链表的存储空间是不连续的,所以链表的插入和删除操作是很快速的。
插入操作
假设我们要完成一个插入操作:在节点 p 后面插入节点 s。
正确的做法是,只需要将节点 s 插入到节点 p 和节点 p.next 之间就可以,说起来很简单,具体操作请看下图。
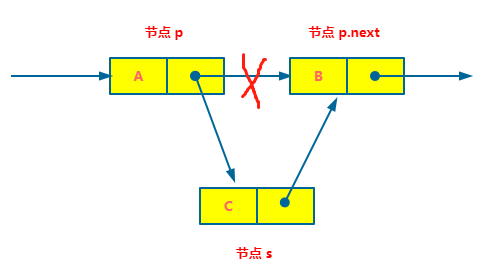
从上图中可以看出,单链表的插入其实根本不需要惊动其它的节点,只需要让 s.next 的指针和 p.next 的指针稍作改变。让节点 s 的后继指针指向 p 的后继节点,然后 p 的后继指针指向节点 s,这里切记,插入操作的顺序一定不能改变。
可以看出插入操作的时间复杂度是 O(1)。
删除操作
假设我们要完成一个删除操作:删除节点 p 的后继节点 q。
其实也简单,就是将 p 的后继指针绕过 q,直接指向 q 的后继节点即可,具体操作如下图。

由上图看出,同样只需要一步就可以实现删除操作,直接让 p.next 指向 q.next 即可,所以删除操作的时间复杂度为 O(1)。
查找操作
当然啦,有快的地方就有慢的地方,元素的查找就是链表美中不足的地方。
数组在内存中排排坐不同,链表的在内存中的地址是分散的,只能通过前一个节点的 next 才知道当前节点的位置,所以在链表中想要找第 i 个元素,只能傻傻的从头开始找,直到找到第 i 个元素位置。
从这可以看出,链表中查找操作的时间复杂度是 O(n)。
单链表实际应用场景
单链表说了这么多也差不多了,辣么有个问题,我学了这个玩意能用在哪呢?
easy!
单链表的应用的话一般能用在 2 种场景下:
(1) 第 1 种基操。 在你应用的场景中,插入和删除的操作特别多,你不想因为这俩操作浪费你太多的时间,此时用单链表,可以改善插入和删除操作浪费的时间。
(2) 第 2 种骚操。在你应用的场景种,不知道有多少个元素,那这个时候你用单链表,每来一个新的元素你就链在表里,这种情况是用链表处理的绝佳方式。也是很容易被大家忽略的。

双向链表
双向链表,顾名思义,两个方向向的链表。相比起单链表来说,它多了一个前驱指针 prev,指向前驱节点。这样双向链表既可以往前走,也可以往后走。


从上面两张图看,双向链表多了一个前驱指针,使得在内存上比单链表占用更多的空间,但是双向链表在查询链表元素的时候会更加方便,比如可以在 O(1) 的时间内超找到当前节点的前驱节点,这是典型的用空间换时间。
空间换时间,在内存够用的情况下,为了追求更快的执行速度,选择空间复杂度较高,时间复杂度较低的数据结构或者算法。
既然用了时间换空间,那双向链表比单链表快在哪个地方呢?那这个还是从插入、删除操作说起。
可能在这臭宝们拿起键盘会说,单链表的插入和删除都已经是 O(1) 了,还要怎么快?
其实准确点来说,插入和删除是 O(1),更多的是针对插入或删除这单个动作来说的,在实际情况下,一切都有前置条件。在某些前置条件下的实际应用场景,双向链表比单链表更快。
下面开始表演。
插入操作优势
插入操作,无非就是 2 种情况:
在 “data域等于某个特定值”的节点前或者后插入一个新的节点。
在给定的节点前或者后插入一个新的节点。
针对第 1 种,这俩时间复杂度都差不多。都是分两个步骤:
第一步找到 data 域等于某个特定值的节点,无论单链表还是双向链表都需要从头开始一个一个的遍历,这一步的时间复杂度都是 O(n)。
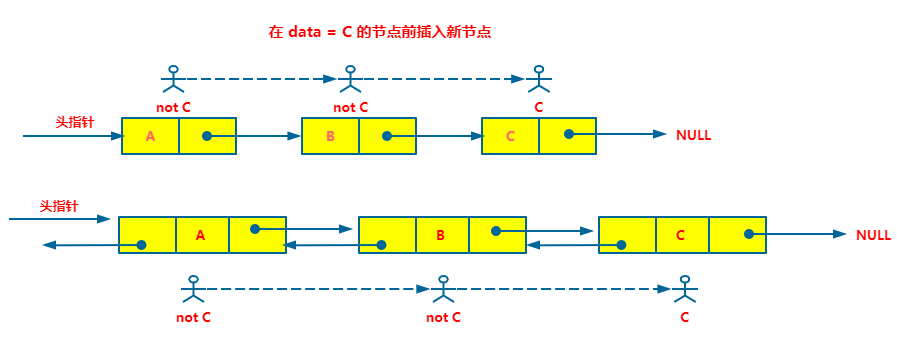
第二步就是插入操作。如果都是向后插入的话,那时间复杂度都是 O(1),如果是向前插入的话,那单链表慢一些,它需要再重新找到特定值节点的前驱节点,这个时间又花费 O(n),而双向链表不用,因为它有前驱节点,直接就能找到特定值节点的前驱节点,这个时间花费的是 O(1) 。
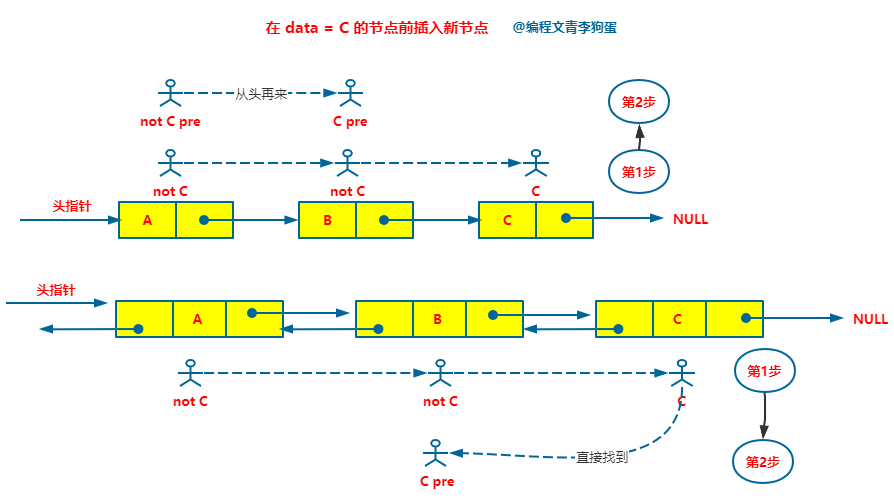
针对第 2 种情况,其实他就是第 1 种情况中的第二步,已经找到了要插入的节点,如果都是向后插入的话,单链表和双链表的时间复杂度都一样,都是 O(1)。差别就差向前插入,向前插入的话就需要知道当前节点的前驱节点,单链表需要重新遍历到当前节点的前驱节点,总的时间复杂度是 O(n),而双向链表一下子就能找到它的前驱节点,时间复杂度是 O(1)。
这就是双向链表优势于单链表的地方。
删除操作优势
删除操作,和插入操作差不多,也基本上是 2 种情况:
删除 “data域等于某个特定值”的节点。
删除给定的节点。
第 1 种情况就不说了,单链表和双向链表都一样,都是从头开始一个个的遍历,时间复杂度都是 O(n)。
第 2 种情况,删除给定的节点,这就要求需要知道这个节点的前驱节点。单链表需要从头开始找,直到“node.next = 当前节点”的适合,才是找到了当前节点的前驱节点 node,这个过程的时间复杂度是 O(n)。而双向链表直接就知道它的前驱节点,只需要时间复杂度是 O(1) 就可以搞定。

常见的链表到这就讲完啦,当然在这基础上衍生出来的像循环链表、循环双向链表都还没说,一次整太多怕你们消化不良。
我会在之后的刷题环节中慢慢给大家都整明白,保证把臭宝们伺候的明明白白~
链表这东西呢,不要怕,虽然看起来有些复杂,但其实就那几板斧,学链表的时候多在纸上画画,各种关系无所遁形,啥都就整明白了,不信你试试。

我是蛋蛋,我们下次见!
