
AAAI 2022 | Diaformer: 采用症状序列生成的方式做自动诊断

本文约5000字,建议阅读10分钟
本文为你介绍在智能医学应用领域 AI Drive 分享了他们的工作“Diaformer”。

论文标题:
Diaformer: Automatic Diagnosis via Symptoms Sequence Generation
论文链接:
https://arxiv.org/abs/2112.10433
代码链接:
https://github.com/zxlzr/Diaformer

Introduction Motivation Methodology Experiments Summary






03 研究方法



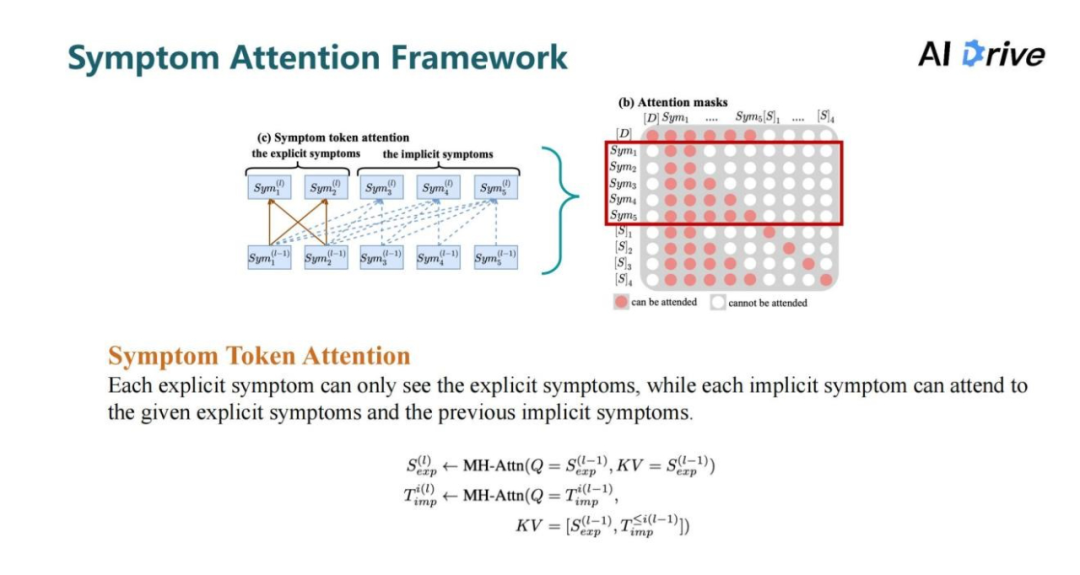
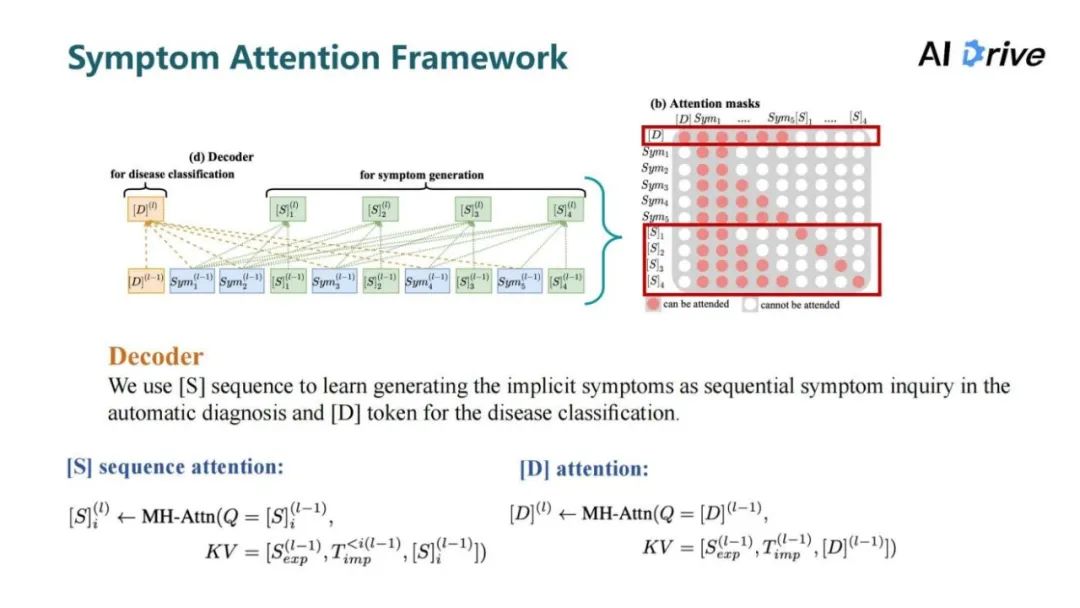

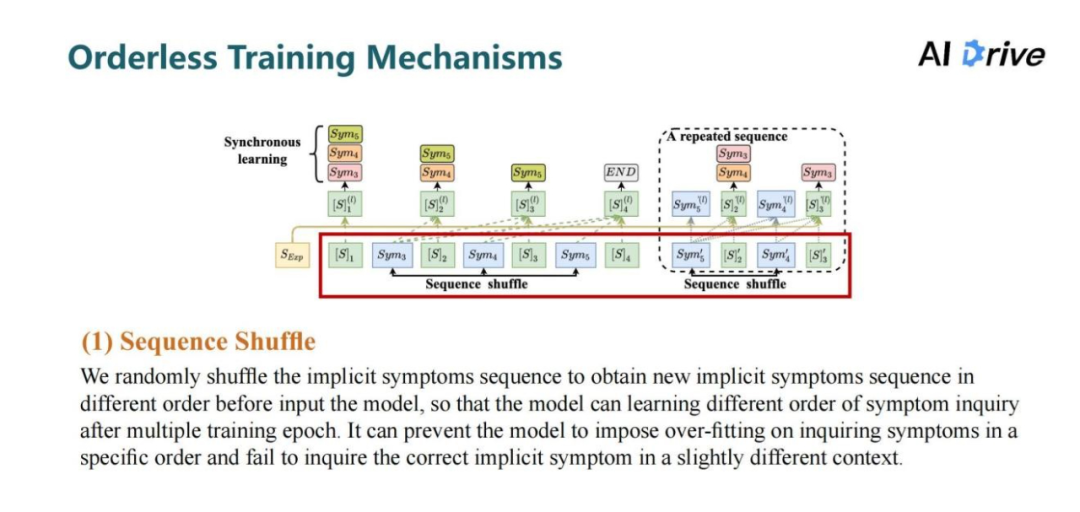
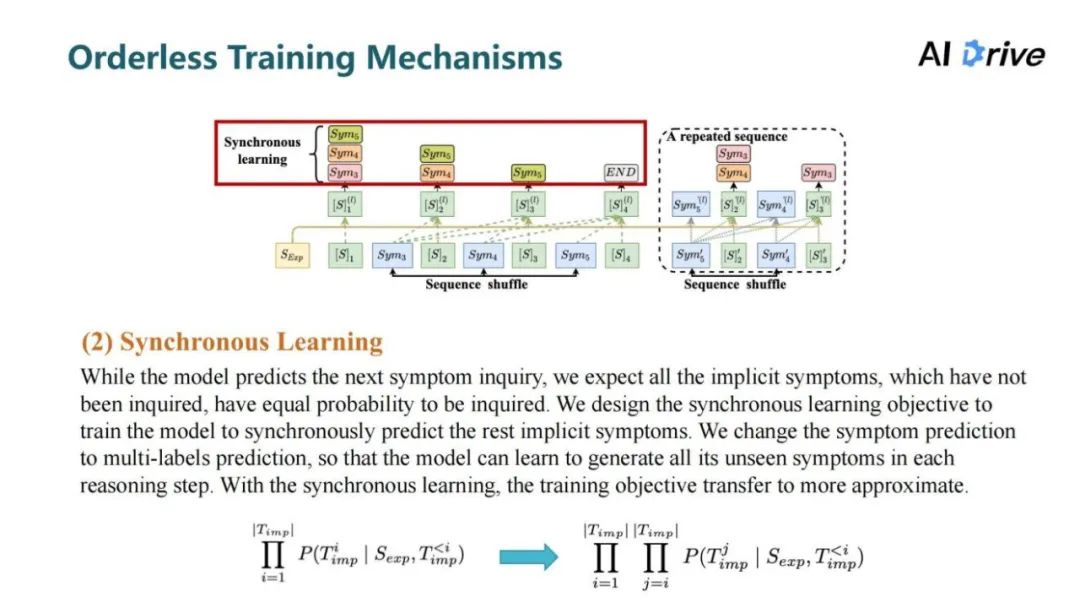
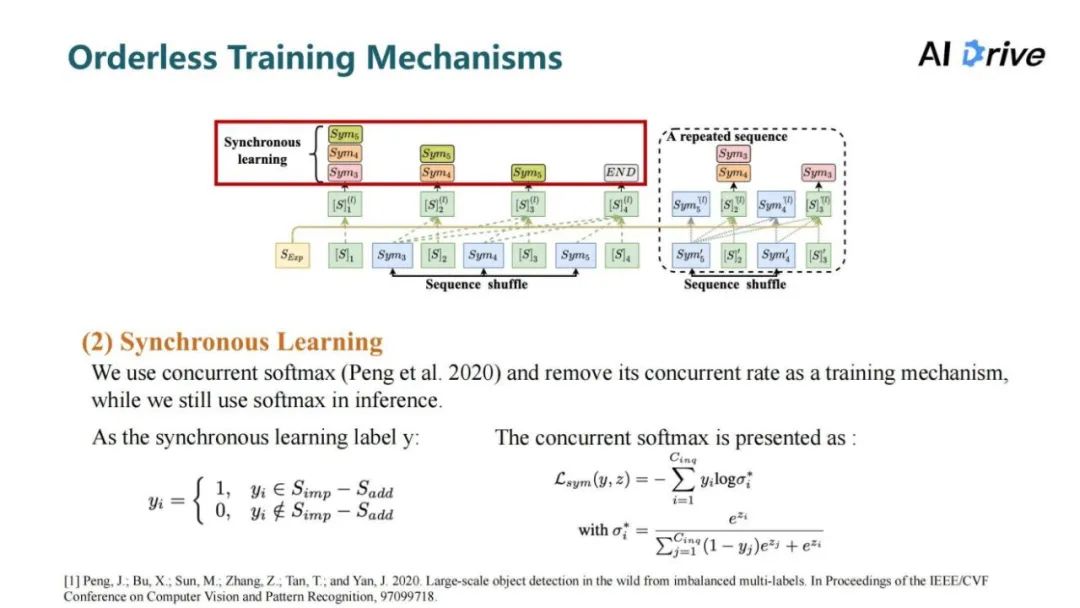
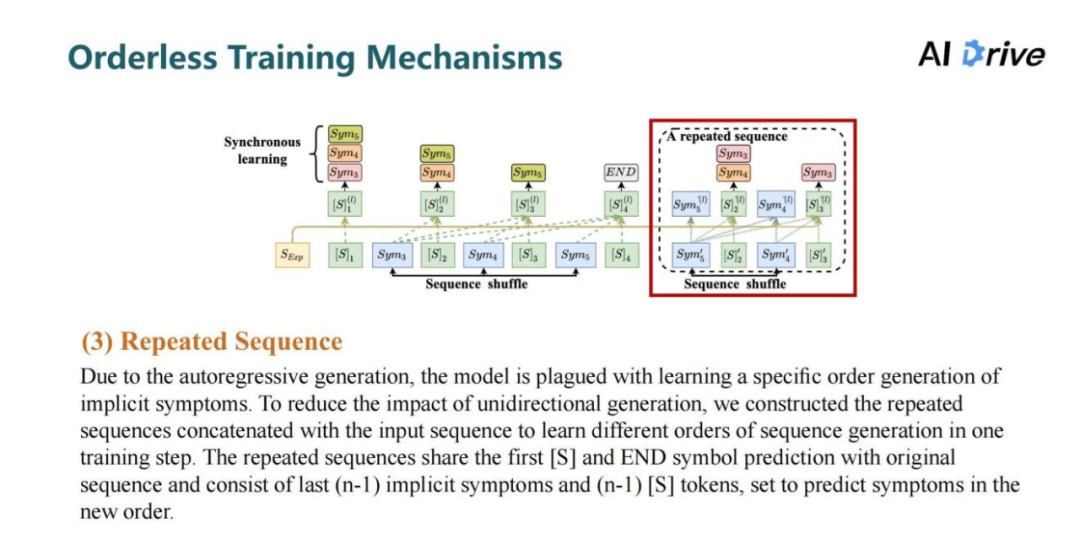
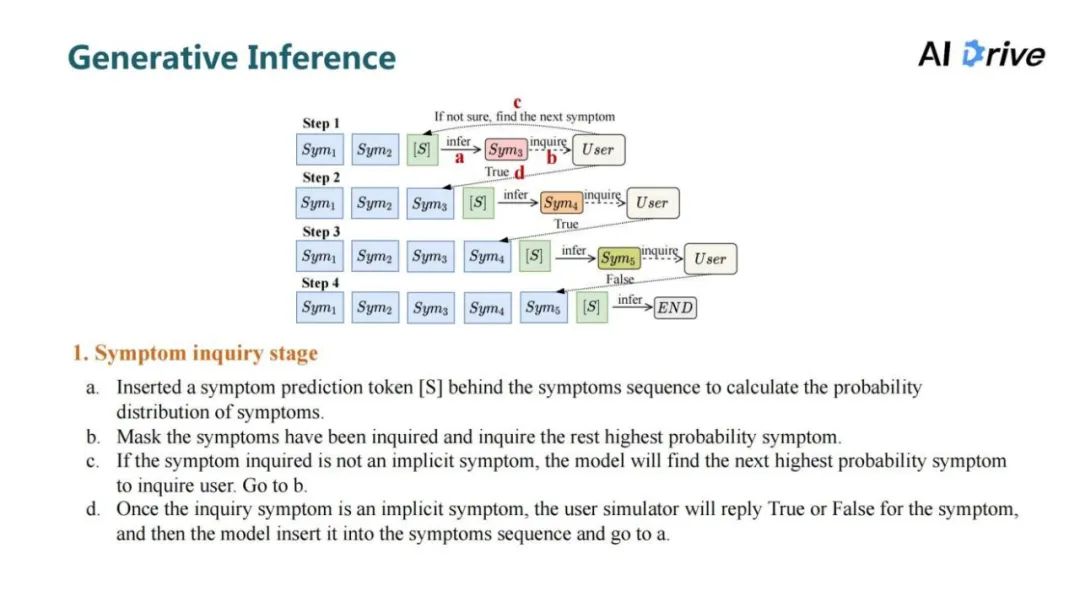
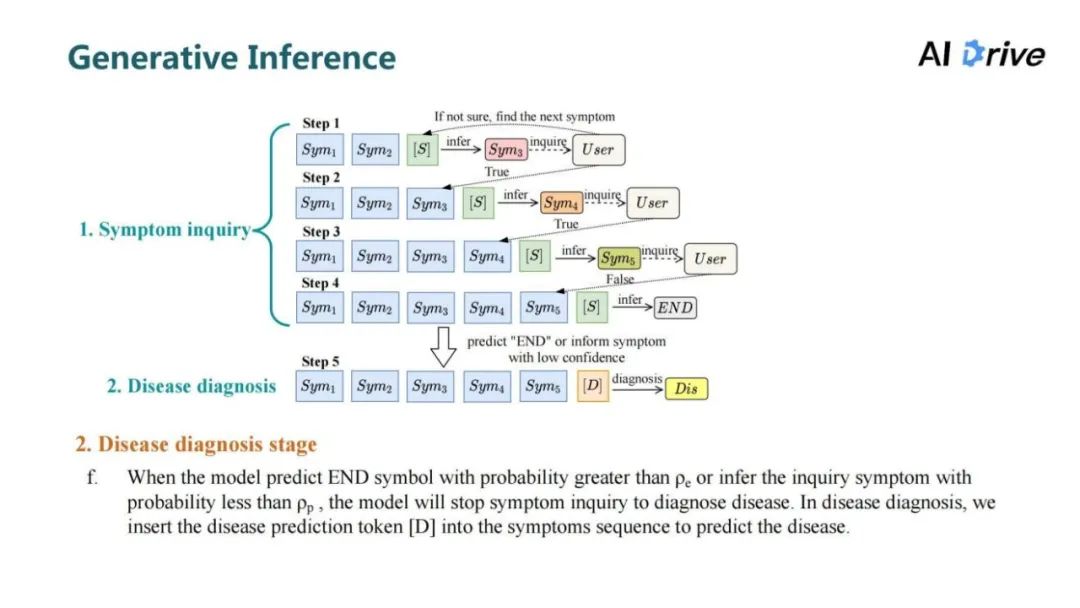
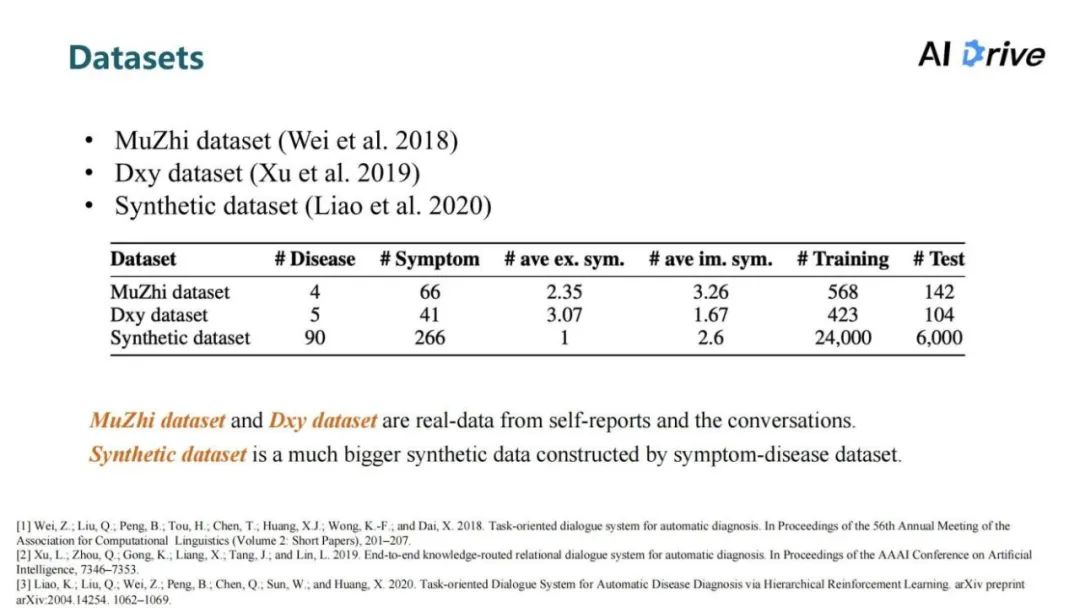



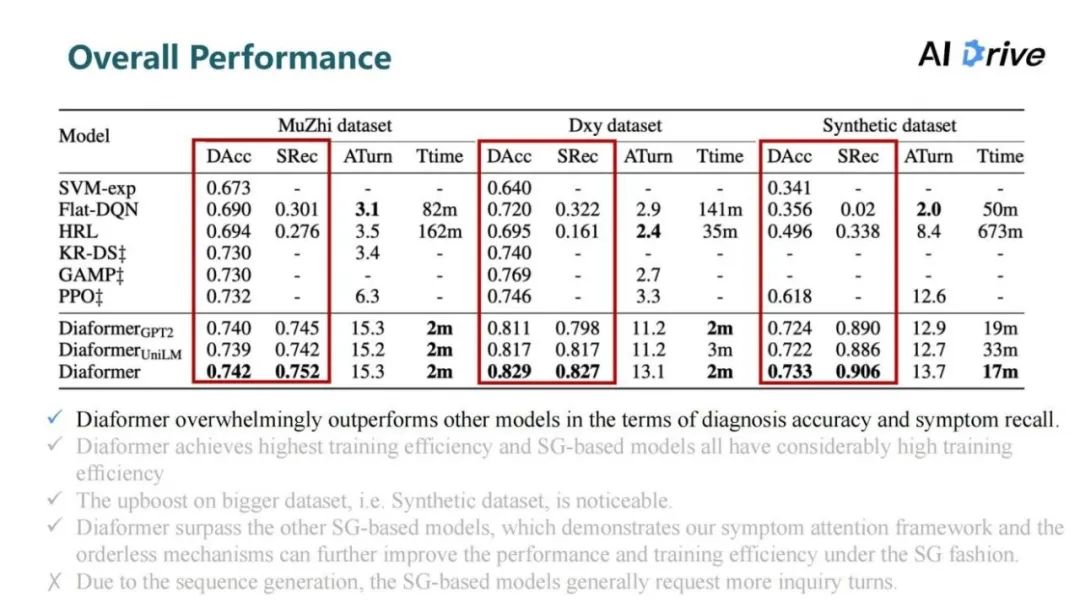
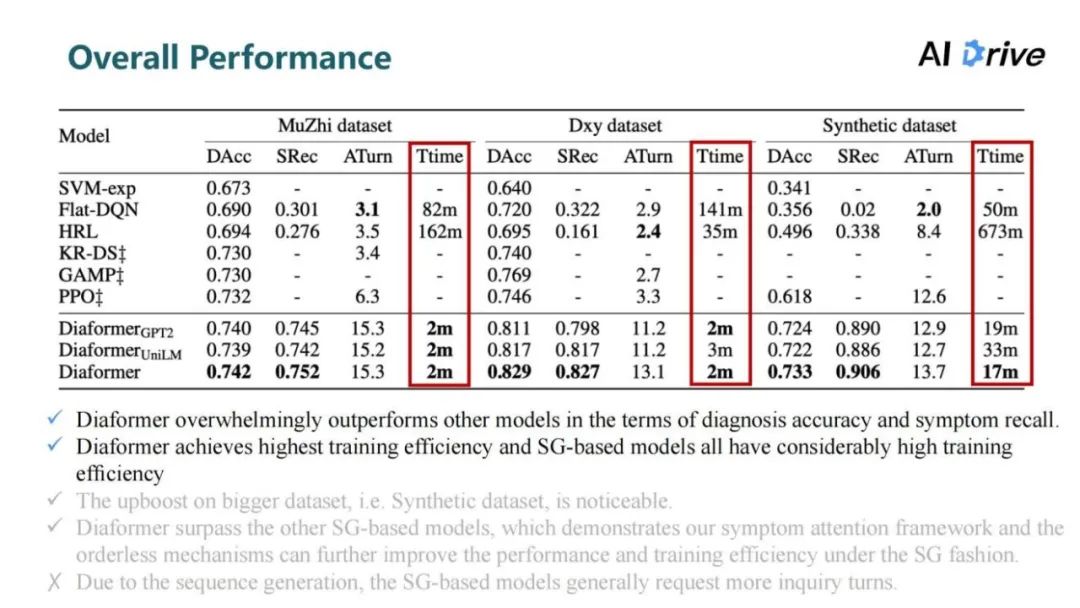
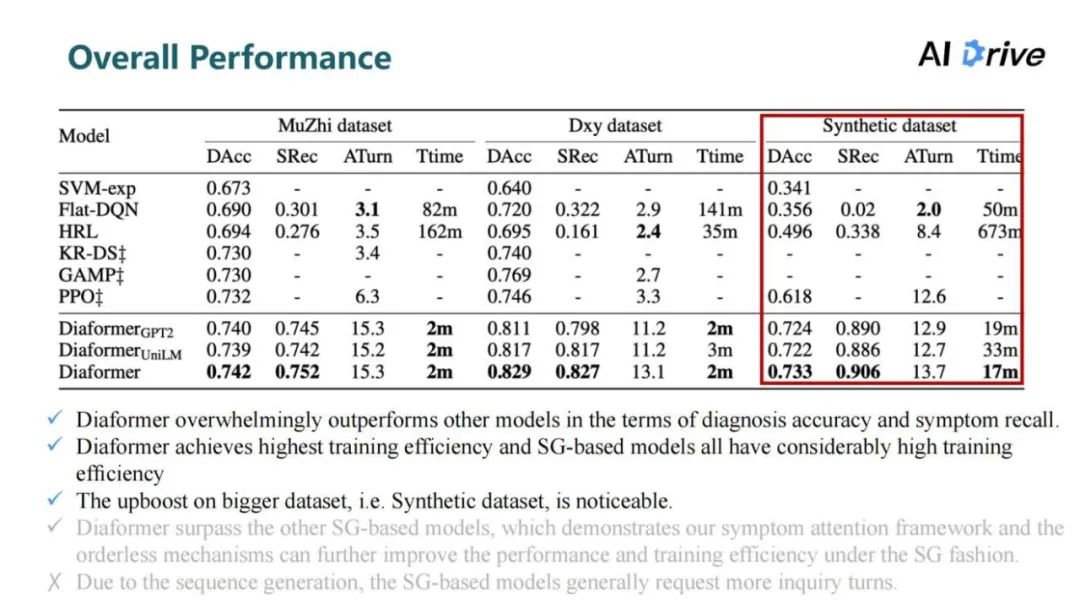


评论