
HBase 实践 | 如何跨CDP集群通过HBase快照迁移数据
该文档主要通过使用HBase快照导出历史全量数据并还原到新的HBase集群,然后改造源生的ExportSnapshot类,通过比较变化的文件实现导出增量,并最终实现HBase跨集群的增量备份和还原。
测试环境
1.CDH7.1.4、启用Kerberos、hbase 2.2.3
2.CDP7.1.6 、启用Kerberos、hbase 2.2.3
3.使用ldapuser1用户操作
2.1在cdp7.1.4生成一张测试的表
2.1.1 使用HBase的pe命令生成一个10G的表
hbase org.apache.hadoop.hbase.PerformanceEvaluation --compress=SNAPPY --size=10 sequentialWrite 10
建表权限不够报错
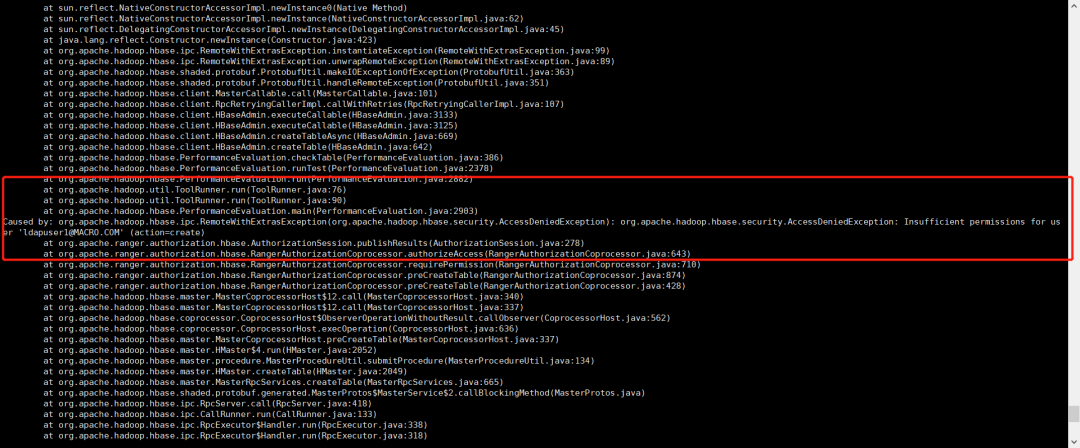
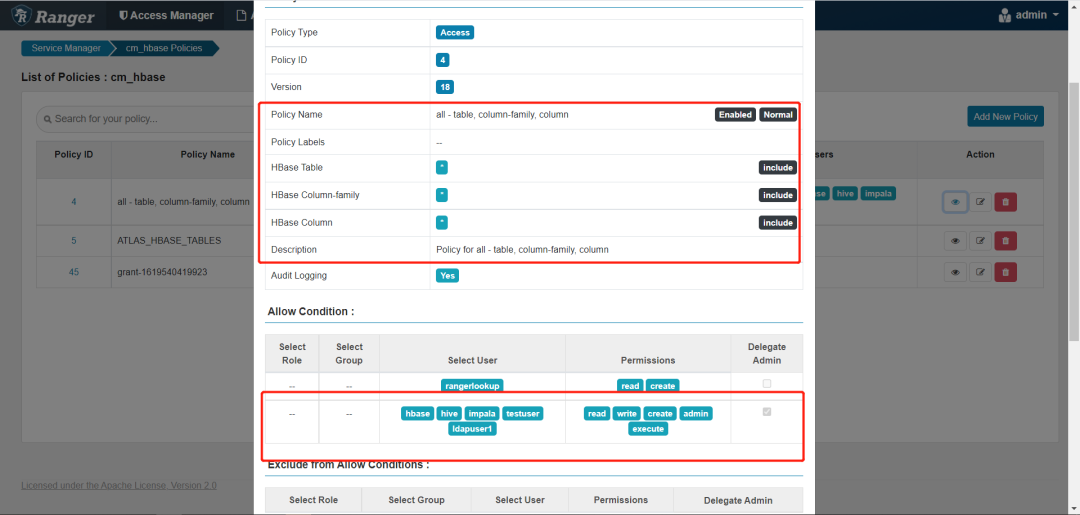
在ranger配置如下
2.1.2 TestTable表HDFS大小
hadoop fs -du -h /hbase/data/default/

此处由于指定了TestTable表的压缩格式为SNAPPY,所以在HDFS上只有2.5GB
2.1.3 TestTable表的总数据量,共10485760条数据
count 'TestTable'
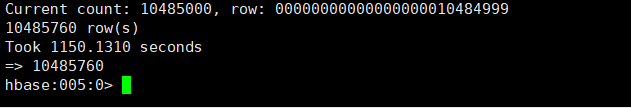
2.2通过快照实现HBase跨集群的全量数据备份和还原
2.2.1生成TestTable表快照
snapshot 'TestTable','TestTable-snapshot1'

2.2.2导出TestTable快照数据
在命令行使用HBase自带的ExportSnapshot导出快照
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot TestTable-snapshot1 -copy-to hdfs://cdp02:8020/tmp/hbasebackup/TestTable-snapshot1
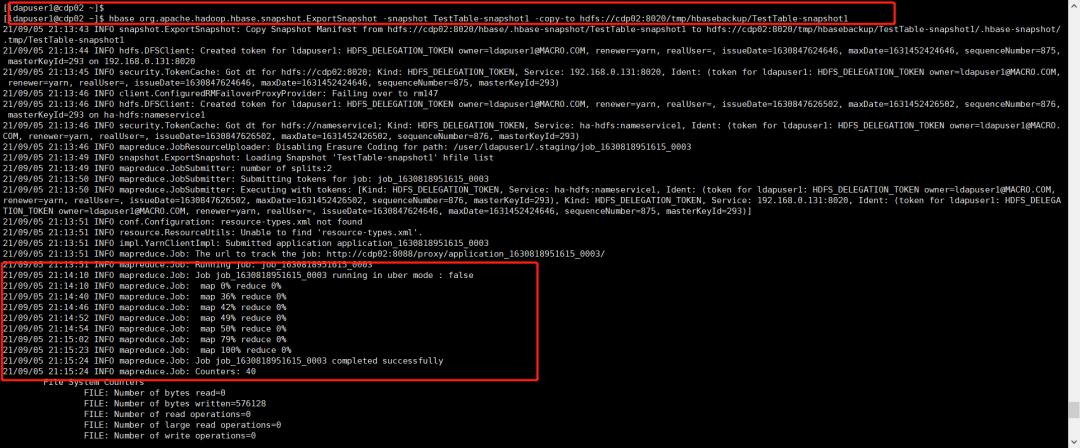
查看导出的快照数据
hadoop fs -ls /tmp/hbasebackup/TestTable-snapshot1

hadoop fs -du -h /tmp/hbasebackup/TestTable-snapshot1

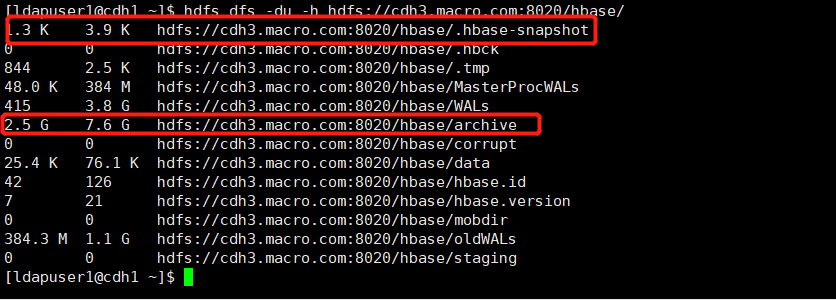
可以看到导出快照实际是把快照的信息及快照记录的所有数据文件分别导出到指定目录下的.hbase-snapshot和archive目录下。
CDSW 产品文档的格式和内容发生了重大变化。
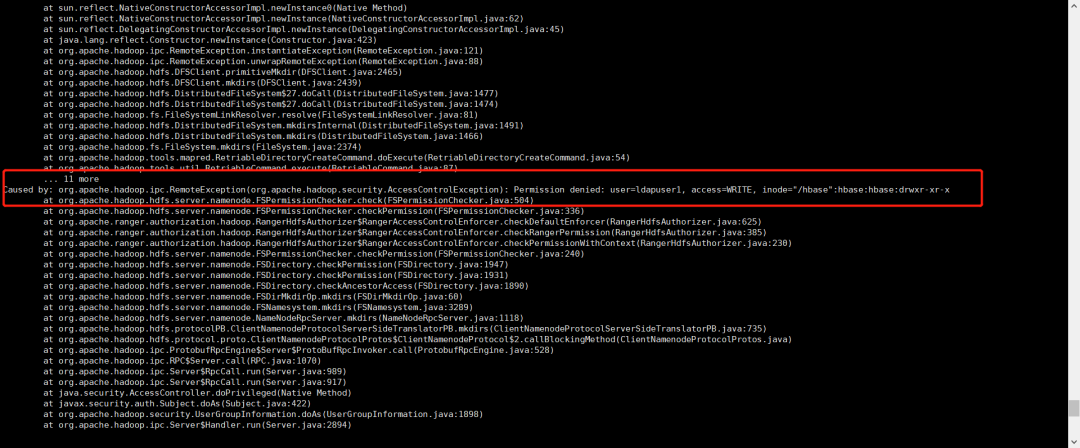
2.2.3将快照数据复制到cdp7.1.6集群
因为两个集群都有Kerberos认证,在用到distcp命令之前,在两集群之间必须做互信(可联系cdh运维人员)
hadoop distcp hdfs://cdp02:8020/tmp/hbasebackup/TestTable-snapshot1/.hbase-snapshot/TestTable-snapshot1 hdfs://cdh3.macro.com:8020/hbase/.hbase-snapshot
hadoop distcp hdfs://cdp02:8020/tmp/hbasebackup/TestTable-snapshot1/archive/data/default/TestTable hdfs://cdh3.macro.com:8020/hbase/archive/data/default
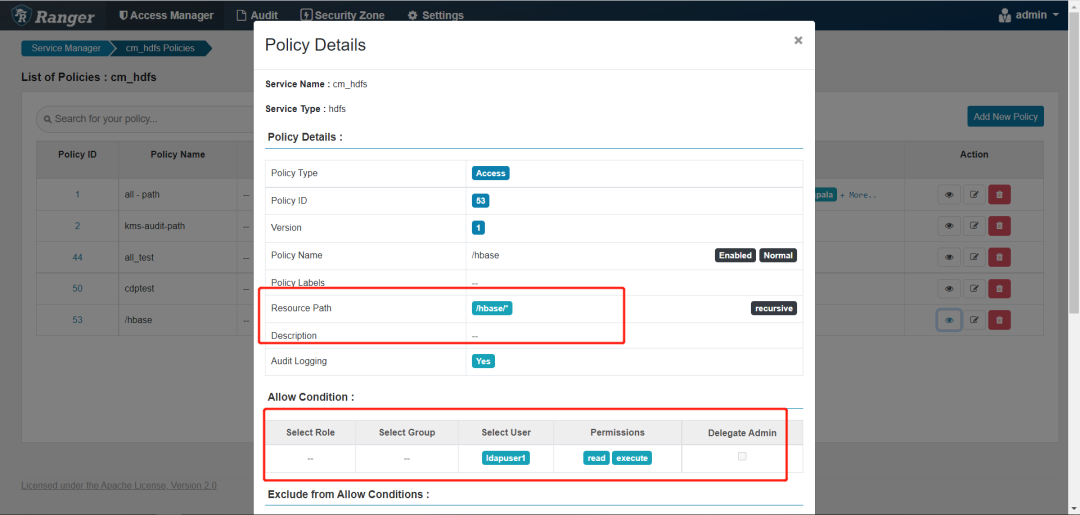
复制报错,权限不足
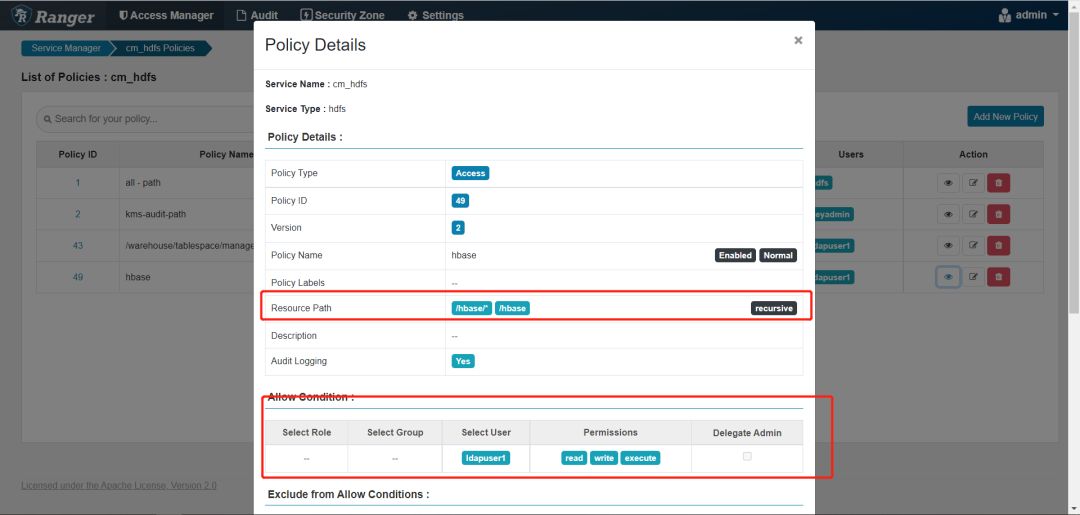
集群cdp7.1.6ranger配置如下
查看复制到cdp7.1.6集群上的快照数据
hdfs dfs -ls hdfs://cdh3.macro.com:8020/hbase/.hbase-snapshot
hdfs dfs -ls hdfs://cdh3.macro.com:8020/hbase/archive/data/default
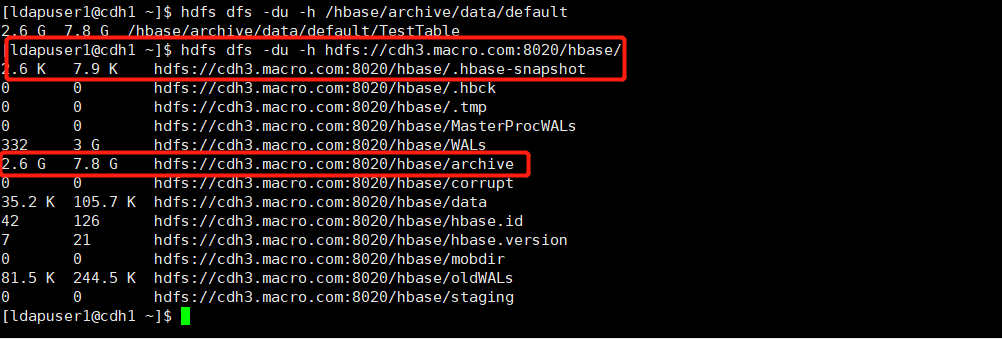
hdfs dfs -du -h hdfs://cdh3.macro.com:8020/hbase/


2.2.4 使用TestTable-snapshot1快照恢复TestTable表
开通以下权限,不然会报权限不足的问题
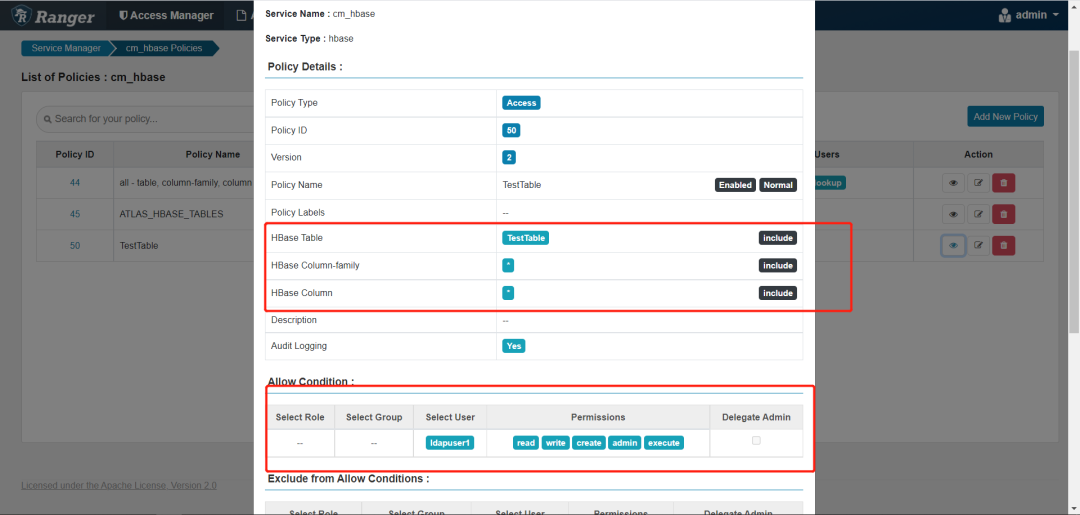
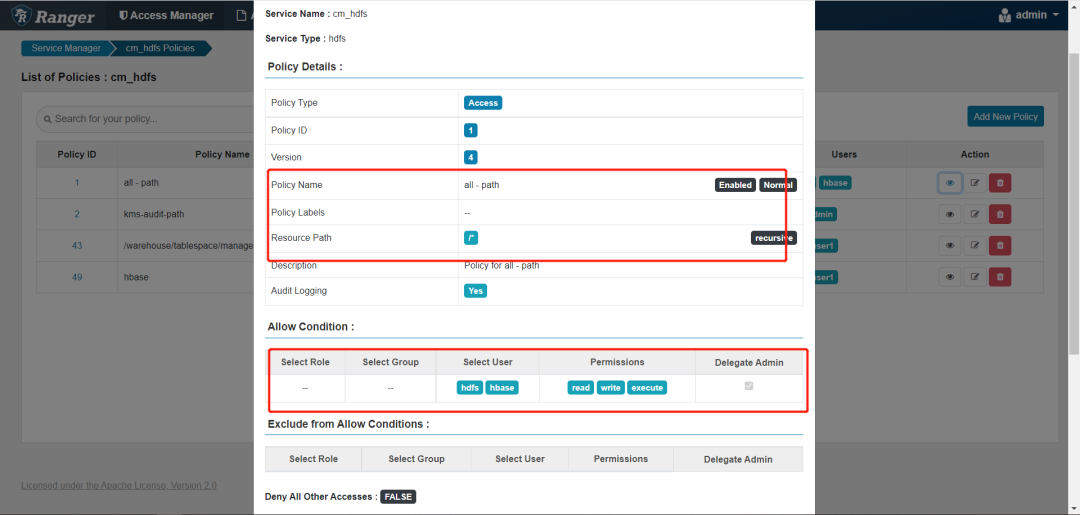
如果不开通会报下面的错误
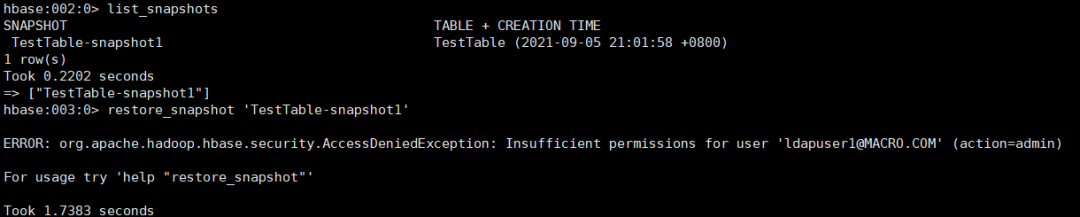

list_snapshots
restore_snapshot 'TestTable-snapshot1'

2.2.5 验证恢复后的表数据是否与快照时数据一致
通过快照恢复的数据与快照时的数据总条数一致,表内容一致。
2.3通过快照实现HBase跨集群的增量数据备份和还原
2.3.1 修改TestTable表数据
通过hbase shell修改一条数据和增加一条数据
put 'TestTable','11111111111111111111111111','info0:AppendTest','1111'
put 'TestTable','00000000000000000000000000','info0:AppendTest','00000'

TestTable表的数据总量为10485761
count 'TestTable'

2.3.2 再次创建TestTable表快照
snapshot 'TestTable','TestTable-snapshot2'

2.3.3 导出第二次快照的增量数据
这一步主要是将TestTable-snapshot2与TestTable-snapshot1两次快照之间的增量数据导出,HBase默认的ExportSnapshot方法是没有增量快照导出的方法,这里在原有快照导出的基础上对源码进行修改,来完成两个快照之间增量数据的导出。
github源码地址:https://github.com/javaxsky/hbaseexport 有编译好的jar包,下载即可,将里面的balancer.jar和hbase-export-1.0-SNAPSHOT.jar放在目录“/opt/cloudera/parcels/CDH/lib/hbase/lib”
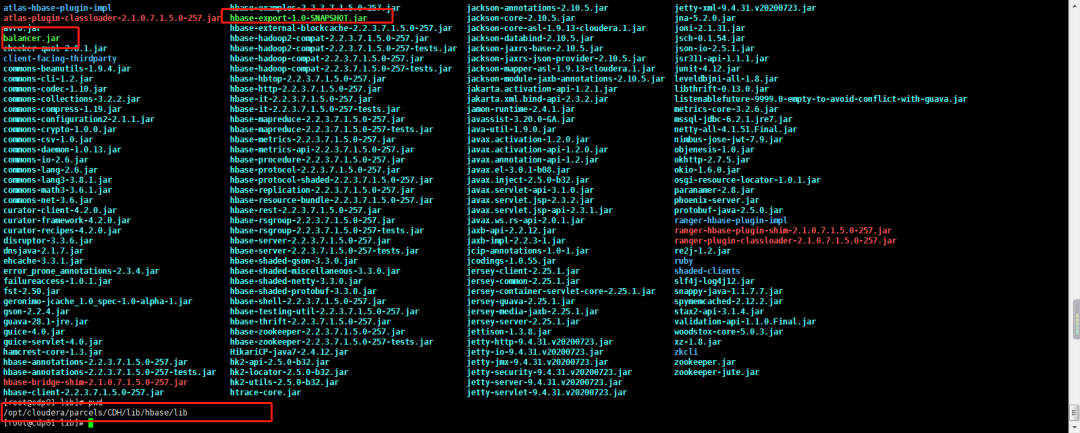
在命令行执行如下命令将两次快照的增量数据导出到HDFS
hbase org.hadoop.hbase.dataExport.ExportSnapshot -snapshot TestTable-snapshot2 -copy-to hdfs://cdp02:8020/tmp/hbasebackup/snapshot2-snapshot1/ -snapshot-old TestTable-snapshot1
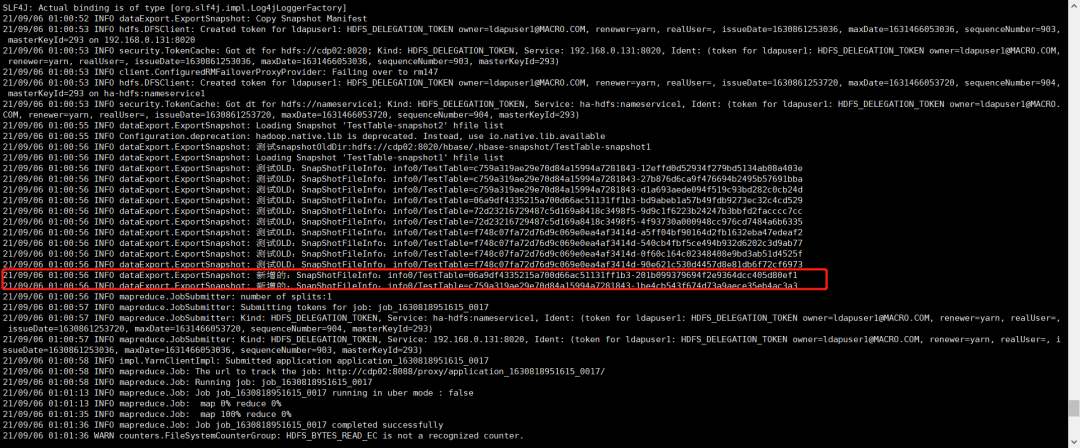
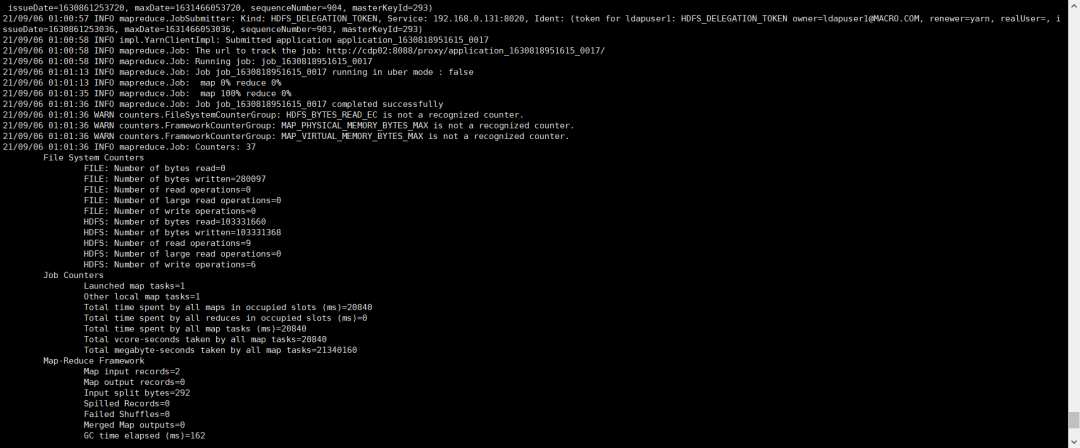
导出的数据目录
hadoop fs -du -h /tmp/hbasebackup/snapshot2-snapshot1

2.3.4 将导出的快照文件复制到CDP7.1.6集群
hadoop distcp hdfs://cdp02:8020/tmp/hbasebackup/snapshot2-snapshot1/.hbase-snapshot/TestTable-snapshot2 hdfs://cdh3.macro.com:8020/hbase/.hbase-snapshot
hadoop distcp hdfs://cdp02:8020/tmp/hbasebackup/snapshot2-snapshot1/archive/data/default/TestTable hdfs://cdh3.macro.com:8020/hbase/archive/data/default
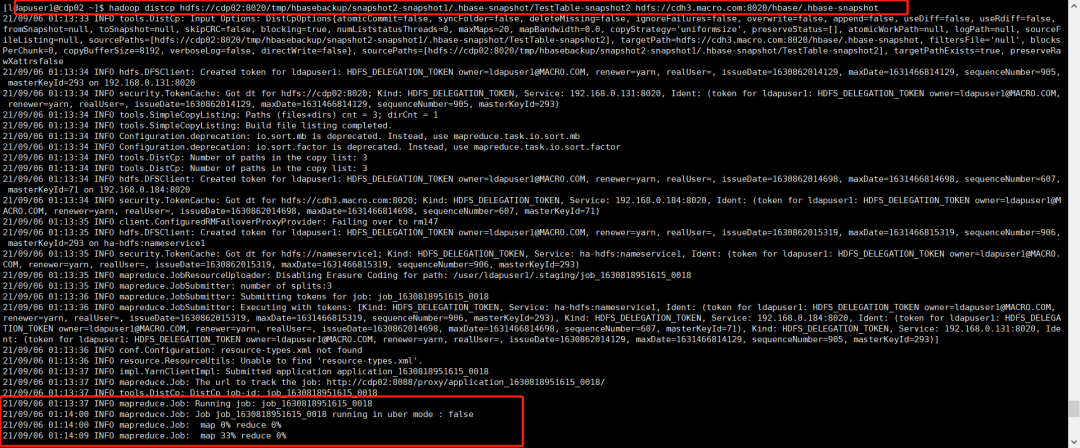
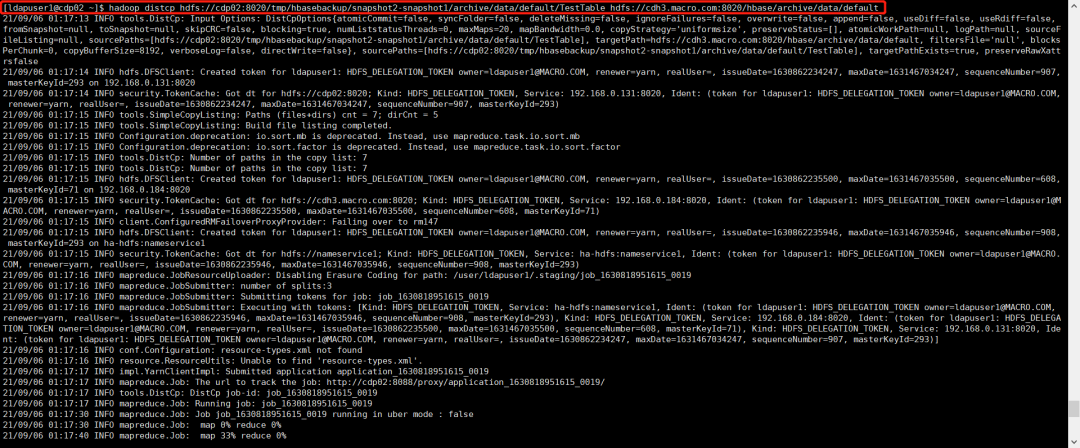
导入增量数据后数据目录
hdfs dfs -du -h hdfs://cdh3.macro.com:8020/hbase/
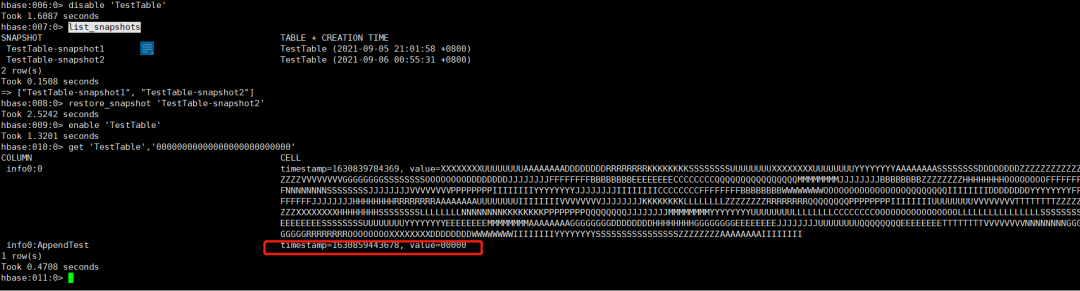
2.3.5 命令行使用快照恢复TestTable表数据并校验数据
disable 'TestTable'
list_snapshots
restore_snapshot 'TestTable-snapshot2'
enable 'TestTable'
get 'TestTable','00000000000000000000000000'
count 'TestTable'
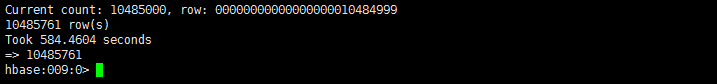
HBase的Snapshot仅涉及metadata的记录,不会涉及数据的拷贝
HBase的ExportSnapshot导出快照操作时在HDFS层级进行的,不会对HBase的Master和RegionServer服务造成额外的负担。
重写的ExportSnapshot增量快照导出是通过两个快照文件列表的差异实现,只需要将有差异的文件导出即可。
使用ExportSnapshot导出快照数据时未造成导出数据膨胀,与原始启用了Snappy压缩的HBase表大小基本一致。
在修改HBase自带的ExportSnapshot,需要根据对应的HBase版本获取源码进行修改,不同版本的ExportSnapshot的Packages路径有改动。
在跨集群传输SnapShot文件时推荐使用Cloudera企业版功能BDR,实现跨集群的文件拷贝传输。