
谈谈注册中心 zookeeper 和 eureka中的CP和 AP
点击上方「蓝字」关注我们

前言
在分布式架构中往往伴随CAP的理论。因为分布式的架构,不再使用传统的单机架构,多机为了提供可靠服务所以需要冗余数据因而会存在分区容忍性P。
冗余数据的同时会在复制数据的同时伴随着可用性A 和强一致性C的问题。是选择停止可用性达到强一致性还是保留可用性选择最终一致性。通常选择后者。
其中 zookeeper 和 eureka分别是注册中心CP AP 的两种的实践。他们都提供服务注册中心的功能。建议使用AP。不强求数据的强一致性,达成数据的最终一致性。
服务注册中心的数据也就是返回的可用服务节点(ip+端口号) 服务A开了0-9十个服务节点,服务B需要调用服务A,两次查询返回0-8,1-9 不一致的数据。产生的影响就是0 和9 节点的负载不均衡
只要注册中心在 SLA 承诺的时间内(例如 1s 内)将数据收敛到一致状态(即满足最终一致),流量将很快趋于统计学意义上的一致,所以注册中心以最终一致的模型设计在生产实践中完全可以接受。
1 eureka AP
eureka 保证了可用性,实现最终一致性。
Eureka各个节点都是平等的,几个节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务。而Eureka的客户端在向某个Eureka注册或时如果发现连接失败,则会自动切换至其它节点,只要有一台Eureka还在,就能保证注册服务可用(保证可用性),只不过查到的信息可能不是最新的(不保证强一致性),其中说明了,eureka是不满足强一致性,但还是会保证最终一致性
2 zookeeper CP
zookeeper在选举leader时,会停止服务,直到选举成功之后才会再次对外提供服务,这个时候就说明了服务不可用,但是在选举成功之后,因为一主多从的结构,zookeeper在这时还是一个高可用注册中心,只是在优先保证一致性的前提下,zookeeper才会顾及到可用性
2.1 zookeeper 应用场景
感知消息队列异步操作后的结果
分布式锁
元数据 或者配置中心 如 dubbo 和Kafka 都需要zookeeper
dubbo 也可以不使用zookeeper 采用直连提供的方式,但限制了分布式的拓展性。
HA高可用
主备切换 (两个服务分别为主备,备用平时不提供服务,当主的挂掉后,备用顶上作为新主。当原来的主恢复后作为新备)
选型依据:
在粗粒度分布式锁,分布式选主,主备高可用切换等不需要高 TPS 支持的场景下有不可替代的作用,而这些需求往往多集中在大数据、离线任务等相关的业务领域,因为大数据领域,讲究分割数据集,并且大部分时间分任务多进程 / 线程并行处理这些数据集,但是总是有一些点上需要将这些任务和进程统一协调,这时候就是 ZooKeeper 发挥巨大作用的用武之地。
但是在交易场景交易链路上,在主业务数据存取,大规模服务发现、大规模健康监测等方面有天然的短板,应该竭力避免在这些场景下引入 ZooKeeper,在阿里巴巴的生产实践中,应用对 ZooKeeper 申请使用的时候要进行严格的场景、容量、SLA 需求的评估。
所以可以使用 ZooKeeper,但是大数据请向左,而交易则向右,分布式协调向左,服务发现向右。
2.2 不建议使用zookeeper 的场景和原因
不建议使用zookeeper 的原因是当它没满足A带来的影响。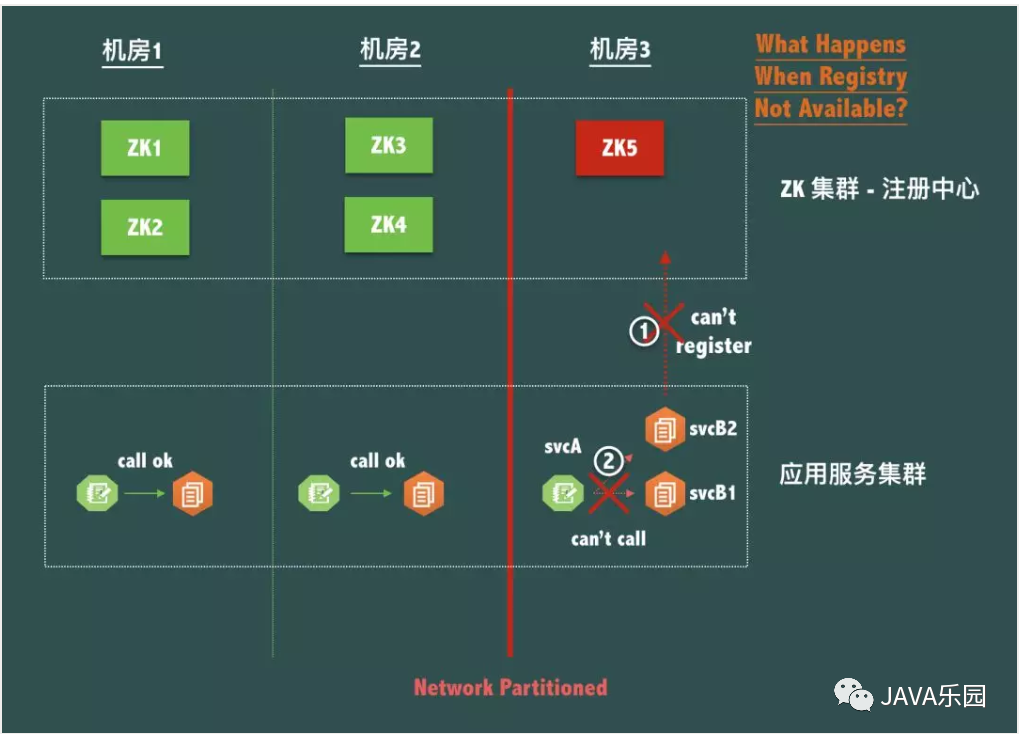
当机房 3 出现网络分区 (Network Partitioned) 的时候,即机房 3 在网络上成了孤岛,我们知道虽然整体 ZooKeeper 服务是可用的,但是节点 ZK5 是不可写的,因为联系不上 Leader。
也就是说,这时候机房 3 的应用服务 svcB 是不可以新部署,重新启动,扩容或者缩容的,但是站在网络和服务调用的角度看,机房 3 的 svcA 虽然无法调用机房 1 和机房 2 的 svcB, 但是与机房 3 的 svcB 之间的网络明明是 OK 的啊,为什么不让我调用本机房的服务?
现在因为注册中心自身为了保脑裂 (P) 下的数据一致性(C)而放弃了可用性,导致了同机房的服务之间出现了无法调用,这是绝对不允许的!可以说在实践中,注册中心不能因为自身的任何原因破坏服务之间本身的可连通性,这是注册中心设计应该遵循的铁律
2.3 zookeeper 的拓展
ZooKeeper 的写并不是可扩展的,不可以通过加节点解决水平扩展性问题。
要想在 ZooKeeper 基础上硬着头皮解决服务规模的增长问题,一个实践中可以考虑的方法是想办法梳理业务,垂直划分业务域,将其划分到多个 ZooKeeper 注册中心,但是作为提供通用服务的平台机构组,因自己提供的服务能力不足要业务按照技术的指挥棒配合划分治理业务,真的可行么?
而且这又违反了因为注册中心自身的原因(能力不足)破坏了服务的可连通性,举个简单的例子,1 个搜索业务,1 个地图业务,1 个大文娱业务,1 个游戏业务,他们之间的服务就应该老死不相往来么?也许今天是肯定的,那么明天呢,1 年后呢,10 年后呢?谁知道未来会要打通几个业务域去做什么奇葩的业务创新?注册中心作为基础服务,无法预料未来的时候当然不能妨碍业务服务对未来固有联通性的需求。
2.4 zookeeper 的持久化存储
ZooKeeper 的 ZAB 协议对每一个写请求,会在每个 ZooKeeper 节点上保持写一个事务日志,同时再加上定期的将内存数据镜像(Snapshot)到磁盘来保证数据的一致性和持久性,以及宕机之后的数据可恢复,这是非常好的特性,但是我们要问,在服务发现场景中,其最核心的数据 - 实时的健康的服务的地址列表是不需要数据持久化的
需要持久化存储的地方在于一个完整的生产可用的注册中心,除了服务的实时地址列表以及实时的健康状态之外,还会存储一些服务的元数据信息,例如服务的版本,分组,所在的数据中心,权重,鉴权策略信息,service label 等元信息,这些数据需要持久化存储,并且注册中心应该提供对这些元信息的检索的能力。
2.5 容灾能力
如果注册中心(Registry)本身完全宕机了,服务A 调用 服务B 链路应该受到影响么?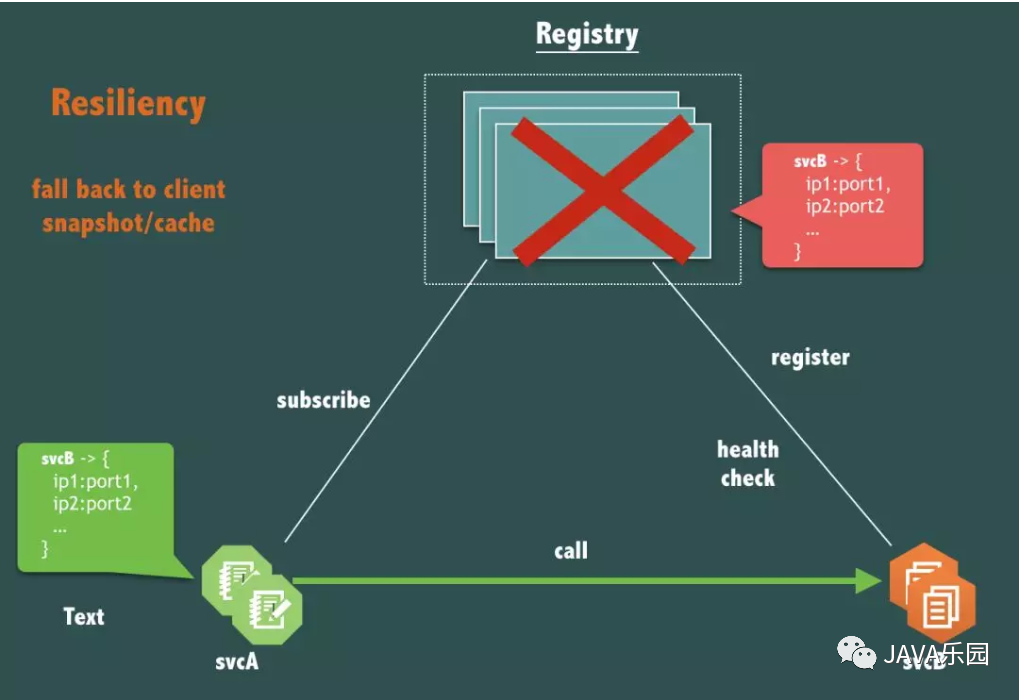
是的,不应该受到影响。
服务调用(请求响应流)链路应该是弱依赖注册中心,必须仅在服务发布,机器上下线,服务扩缩容等必要时才依赖注册中心。
这需要注册中心仔细的设计自己提供的客户端,客户端中应该有针对注册中心服务完全不可用时做容灾的手段,例如设计客户端缓存数据机制(我们称之为 client snapshot)就是行之有效的手段。另外,注册中心的 health check 机制也要仔细设计以便在这种情况不会出现诸如推空等情况的出现。
ZooKeeper 的原生客户端并没有这种能力,所以利用 ZooKeeper 实现注册中心的时候我们一定要问自己,如果把 ZooKeeper 所有节点全干掉,你生产上的所有服务调用链路能不受任何影响么?而且应该定期就这一点做故障演练。
zookeeper 的健康检查
使用 ZooKeeper 作为服务注册中心时,服务的健康检测常利用 ZooKeeper 的 Session 活性 Track 机制 以及结合 Ephemeral ZNode 的机制,简单而言,就是将服务的健康监测绑定在了 ZooKeeper 对于 Session 的健康监测上,或者说绑定在 TCP 长链接活性探测上了。
这在很多时候也会造成致命的问题,ZK 与服务提供者机器之间的 TCP 长链接活性探测正常的时候,该服务就是健康的么?答案当然是否定的!注册中心应该提供更丰富的健康监测方案,服务的健康与否的逻辑应该开放给服务提供方自己定义,而不是一刀切搞成了 TCP 活性检测!
健康检测的一大基本设计原则就是尽可能真实的反馈服务本身的真实健康状态,否则一个不敢被服务调用者相信的健康状态判定结果还不如没有健康检测。
source:https://www.cnblogs.com/wei57960/p/12260228.html

扫码二维码
获取更多精彩
Java乐园
